 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Daily High-resolution Inundation Observations using Deep Learning and EO
Aug 10, 2022
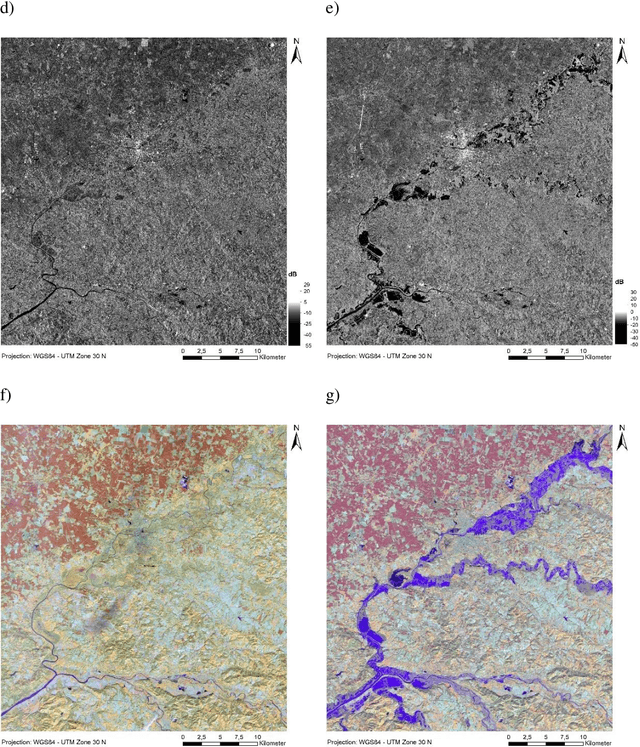

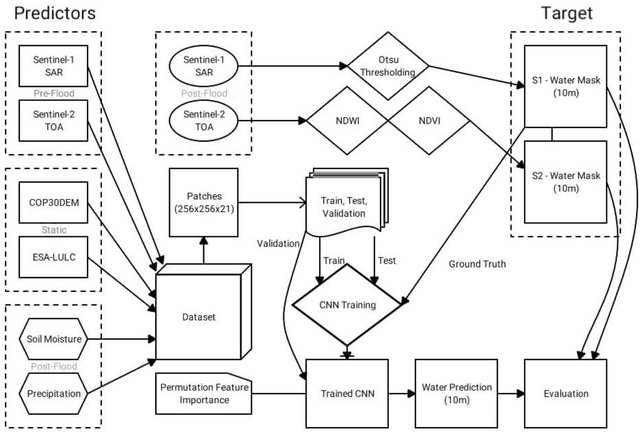
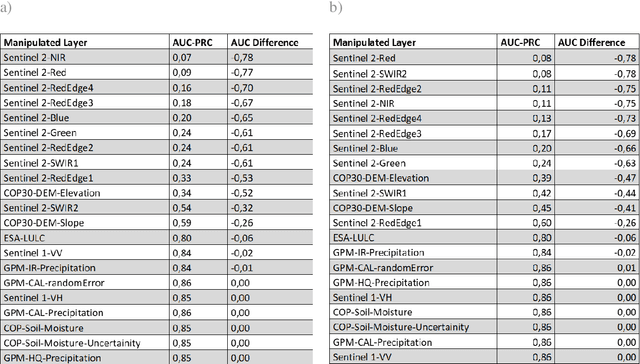
Satellite remote sensing presents a cost-effective solution for synoptic flood monitoring, and satellite-derived flood maps provide a computationally efficient alternative to numerical flood inundation models traditionally used. While satellites do offer timely inundation information when they happen to cover an ongoing flood event, they are limited by their spatiotemporal resolution in terms of their ability to dynamically monitor flood evolution at various scales. Constantly improving access to new satellite data sources as well as big data processing capabilities has unlocked an unprecedented number of possibilities in terms of data-driven solutions to this problem. Specifically, the fusion of data from satellites, such as the Copernicus Sentinels, which have high spatial and low temporal resolution, with data from NASA SMAP and GPM missions, which have low spatial but high temporal resolutions could yield high-resolution flood inundation at a daily scale. Here a Convolutional-Neural-Network is trained using flood inundation maps derived from Sentinel-1 Synthetic Aperture Radar and various hydrological, topographical, and land-use based predictors for the first time, to predict high-resolution probabilistic maps of flood inundation. The performance of UNet and SegNet model architectures for this task is evaluated, using flood masks derived from Sentinel-1 and Sentinel-2, separately with 95 percent-confidence intervals. The Area under the Curve (AUC) of the Precision Recall Curve (PR-AUC) is used as the main evaluation metric, due to the inherently imbalanced nature of classes in a binary flood mapping problem, with the best model delivering a PR-AUC of 0.85.
LViT: Language meets Vision Transformer in Medical Image Segmentation
Jun 29, 2022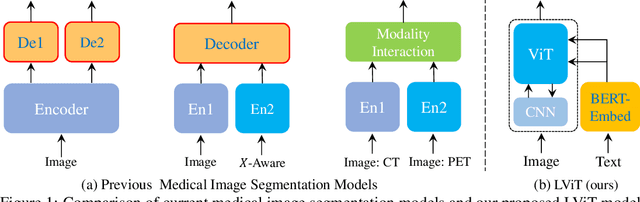
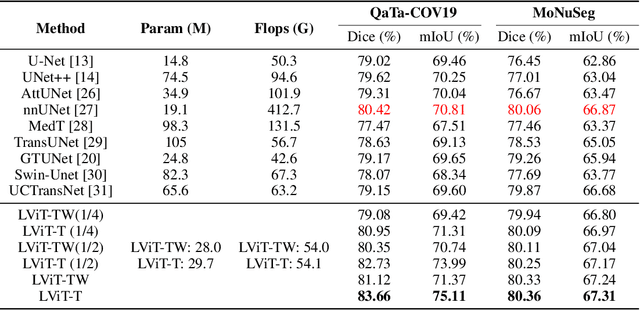
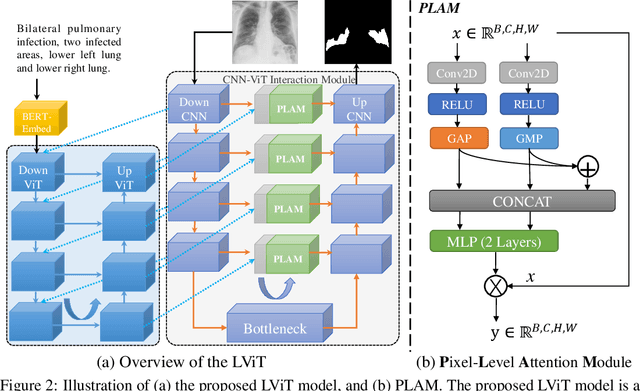
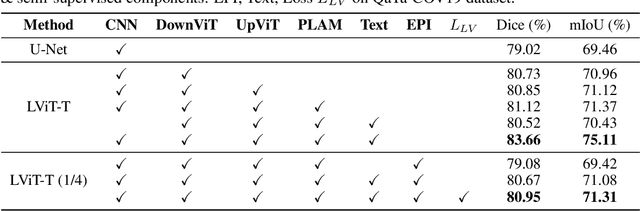
Deep learning has been widely used in medical image segmentation and other aspects. However, the performance of existing medical image segmentation models has been limited by the challenge of obtaining sufficient number of high-quality data with the high cost of data annotation. To overcome the limitation, we propose a new vision-language medical image segmentation model LViT (Language meets Vision Transformer). In our model, medical text annotation is introduced to compensate for the quality deficiency in image data. In addition, the text information can guide the generation of pseudo labels to a certain extent and further guarantee the quality of pseudo labels in semi-supervised learning. We also propose the Exponential Pseudo label Iteration mechanism (EPI) to help extend the semi-supervised version of LViT and the Pixel-Level Attention Module (PLAM) to preserve local features of images. In our model, LV (Language-Vision) loss is designed to supervise the training of unlabeled images using text information directly. To validate the performance of LViT, we construct multimodal medical segmentation datasets (image + text) containing pathological images, X-rays,etc. Experimental results show that our proposed LViT has better segmentation performance in both fully and semi-supervised conditions. Code and datasets are available at https://github.com/HUANGLIZI/LViT.
Leveraging Dynamic Objects for Relative Localization COrrection in a Connected Autonomous Vehicle Network
May 19, 2022



High-accurate localization is crucial for the safety and reliability of autonomous driving, especially for the information fusion of collective perception that aims to further improve road safety by sharing information in a communication network of ConnectedAutonomous Vehicles (CAV). In this scenario, small localization errors can impose additional difficulty on fusing the information from different CAVs. In this paper, we propose a RANSAC-based (RANdom SAmple Consensus) method to correct the relative localization errors between two CAVs in order to ease the information fusion among the CAVs. Different from previous LiDAR-based localization algorithms that only take the static environmental information into consideration, this method also leverages the dynamic objects for localization thanks to the real-time data sharing between CAVs. Specifically, in addition to the static objects like poles, fences, and facades, the object centers of the detected dynamic vehicles are also used as keypoints for the matching of two point sets. The experiments on the synthetic dataset COMAP show that the proposed method can greatly decrease the relative localization error between two CAVs to less than 20cmas far as there are enough vehicles and poles are correctly detected by bothCAVs. Besides, our proposed method is also highly efficient in runtime and can be used in real-time scenarios of autonomous driving.
Introducing Information Retrieval for Biomedical Informatics Students
May 06, 2021Introducing biomedical informatics (BMI) students to natural language processing (NLP) requires balancing technical depth with practical know-how to address application-focused needs. We developed a set of three activities introducing introductory BMI students to information retrieval with NLP, covering document representation strategies and language models from TF-IDF to BERT. These activities provide students with hands-on experience targeted towards common use cases, and introduce fundamental components of NLP workflows for a wide variety of applications.
CropMix: Sampling a Rich Input Distribution via Multi-Scale Cropping
May 31, 2022
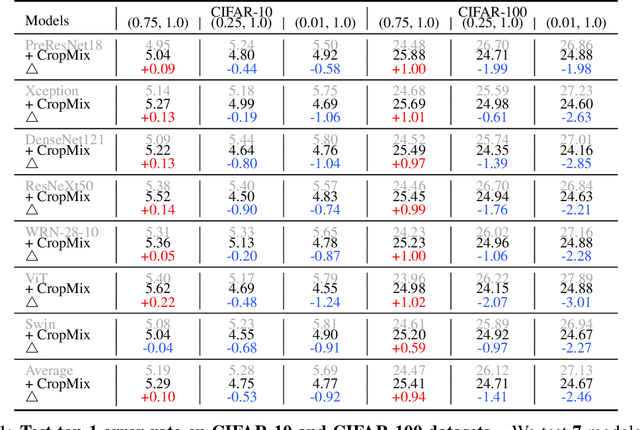

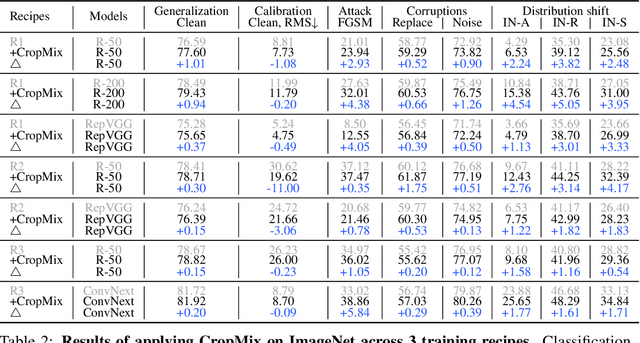
We present a simple method, CropMix, for the purpose of producing a rich input distribution from the original dataset distribution. Unlike single random cropping, which may inadvertently capture only limited information, or irrelevant information, like pure background, unrelated objects, etc, we crop an image multiple times using distinct crop scales, thereby ensuring that multi-scale information is captured. The new input distribution, serving as training data, useful for a number of vision tasks, is then formed by simply mixing multiple cropped views. We first demonstrate that CropMix can be seamlessly applied to virtually any training recipe and neural network architecture performing classification tasks. CropMix is shown to improve the performance of image classifiers on several benchmark tasks across-the-board without sacrificing computational simplicity and efficiency. Moreover, we show that CropMix is of benefit to both contrastive learning and masked image modeling towards more powerful representations, where preferable results are achieved when learned representations are transferred to downstream tasks. Code is available at GitHub.
Conflict-free joint sampling for preference satisfaction through quantum interference
Aug 05, 2022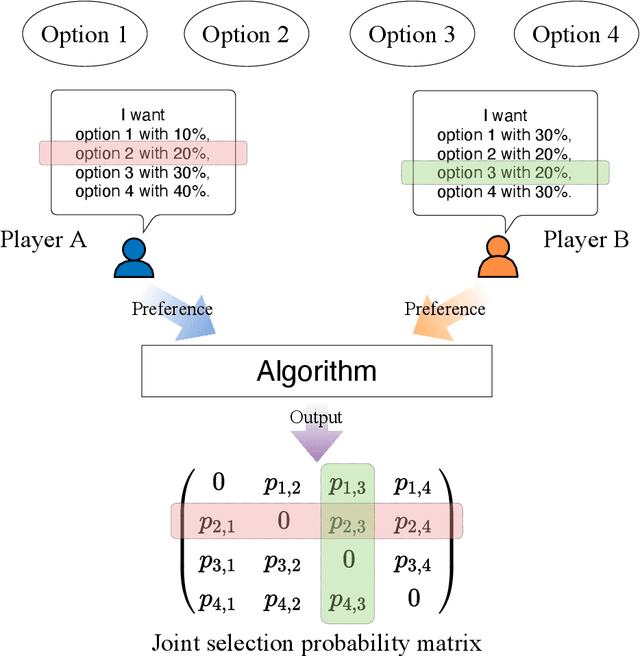
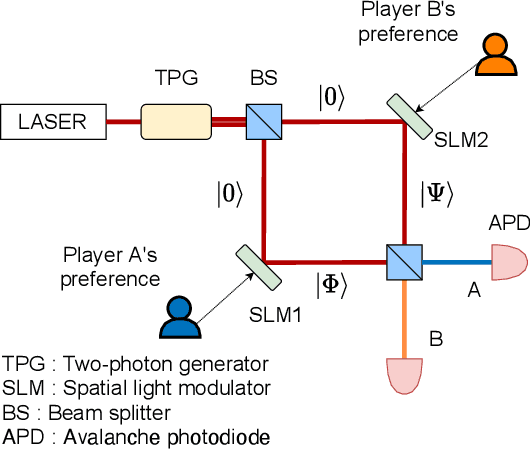
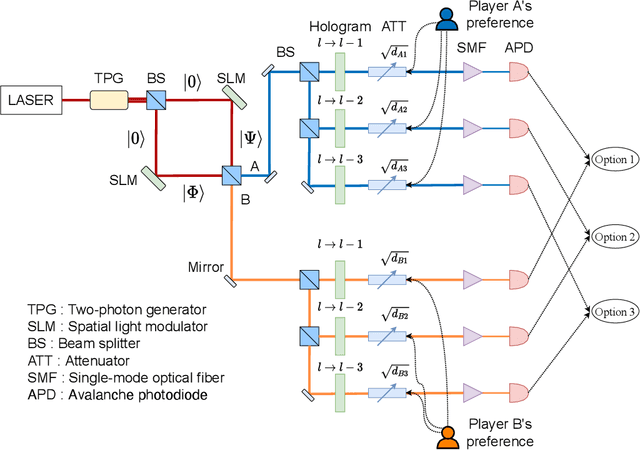
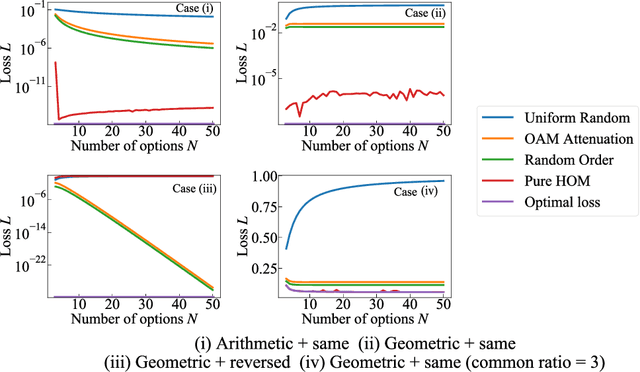
Collective decision-making is vital for recent information and communications technologies. In our previous research, we mathematically derived conflict-free joint decision-making that optimally satisfies players' probabilistic preference profiles. However, two problems exist regarding the optimal joint decision-making method. First, as the number of choices increases, the computational cost of calculating the optimal joint selection probability matrix explodes. Second, to derive the optimal joint selection probability matrix, all players must disclose their probabilistic preferences. Now, it is noteworthy that explicit calculation of the joint probability distribution is not necessarily needed; what is necessary for collective decisions is sampling. This study examines several sampling methods that converge to heuristic joint selection probability matrices that satisfy players' preferences. We show that they can significantly reduce the above problems of computational cost and confidentiality. We analyze the probability distribution each of the sampling methods converges to, as well as the computational cost required and the confidentiality secured. In particular, we introduce two conflict-free joint sampling methods through quantum interference of photons. The first system allows the players to hide their choices while satisfying the players' preferences almost perfectly when they have the same preferences. The second system, where the physical nature of light replaces the expensive computational cost, also conceals their choices under the assumption that they have a trusted third party.
One-Trimap Video Matting
Jul 27, 2022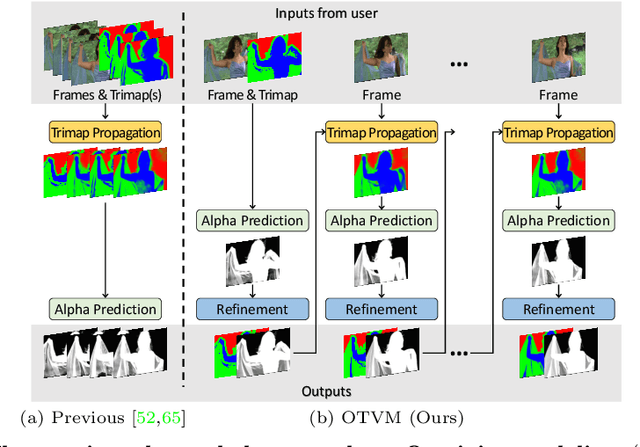
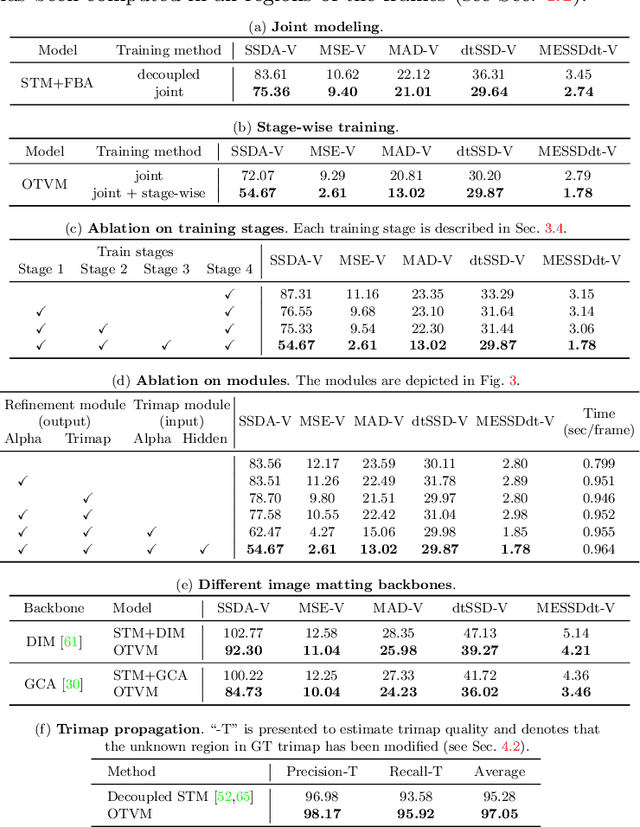
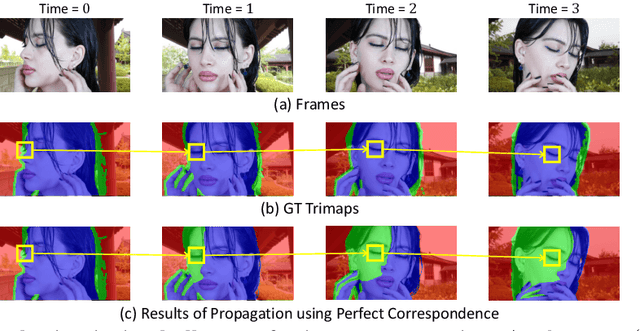
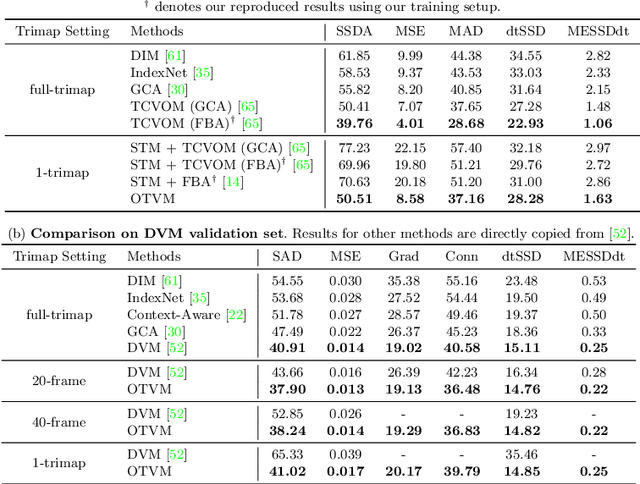
Recent studies made great progress in video matting by extending the success of trimap-based image matting to the video domain. In this paper, we push this task toward a more practical setting and propose One-Trimap Video Matting network (OTVM) that performs video matting robustly using only one user-annotated trimap. A key of OTVM is the joint modeling of trimap propagation and alpha prediction. Starting from baseline trimap propagation and alpha prediction networks, our OTVM combines the two networks with an alpha-trimap refinement module to facilitate information flow. We also present an end-to-end training strategy to take full advantage of the joint model. Our joint modeling greatly improves the temporal stability of trimap propagation compared to the previous decoupled methods. We evaluate our model on two latest video matting benchmarks, Deep Video Matting and VideoMatting108, and outperform state-of-the-art by significant margins (MSE improvements of 56.4% and 56.7%, respectively). The source code and model are available online: https://github.com/Hongje/OTVM.
Learning Multiscale Transformer Models for Sequence Generation
Jun 19, 2022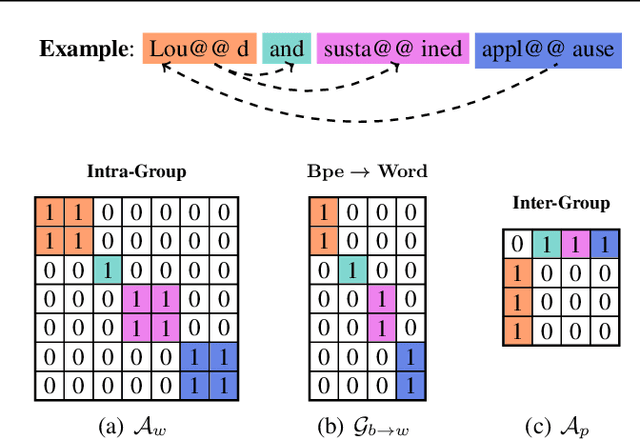

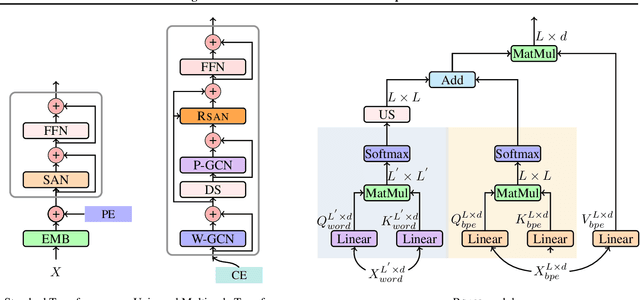
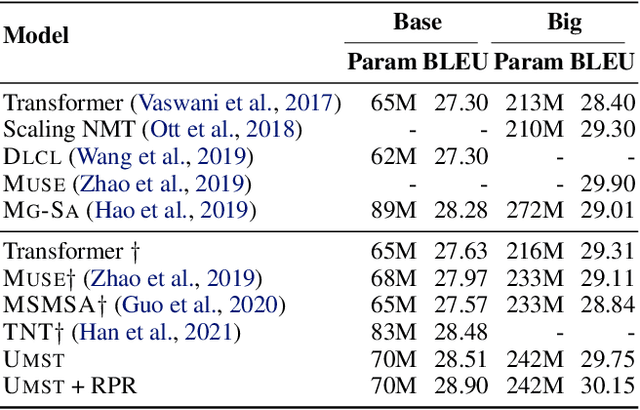
Multiscale feature hierarchies have been witnessed the success in the computer vision area. This further motivates researchers to design multiscale Transformer for natural language processing, mostly based on the self-attention mechanism. For example, restricting the receptive field across heads or extracting local fine-grained features via convolutions. However, most of existing works directly modeled local features but ignored the word-boundary information. This results in redundant and ambiguous attention distributions, which lacks of interpretability. In this work, we define those scales in different linguistic units, including sub-words, words and phrases. We built a multiscale Transformer model by establishing relationships among scales based on word-boundary information and phrase-level prior knowledge. The proposed \textbf{U}niversal \textbf{M}ulti\textbf{S}cale \textbf{T}ransformer, namely \textsc{Umst}, was evaluated on two sequence generation tasks. Notably, it yielded consistent performance gains over the strong baseline on several test sets without sacrificing the efficiency.
Ten Scientific Challenges for 6G: Rethinking the Foundations of Communications Theory
Jul 05, 2022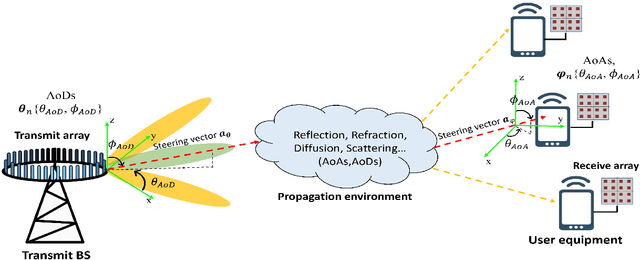

The research in the sixth generation of communication networks needs to tackle new challenges in order to meet the requirements of emerging applications in terms of high data rate, low latency, high reliability, and massive connectivity. To this end, the entire communication chain needs to be optimized, including the channel and the surrounding environment, as it is no longer sufficient to control the transmitter and/or the receiver only. Investigating large intelligent surfaces, ultra massive multiple-input-multiple-output, and smart constructive environments will contribute to this direction. In addition, to allow the exchange of high dimensional sensing data between connected intelligent devices, semantic and goal-oriented communications need to be considered for a more efficient and context-aware information encoding. In particular, for multi-agent systems, where agents are collaborating together to achieve a complex task, emergent communications, instead of hard-coded communications, can be learned for more efficient task execution and communication resources use. Moreover, the interaction between information theory and electromagnetism should be explored to better understand the physical limitations of different technologies, e.g, holographic communications. Another new communication paradigm is to consider the end-to-end approach instead of block-by-block optimization, which requires exploiting machine learning theory, non-linear signal processing theory, and non-coherent communications theory. Within this context, we identify ten scientific challenges for rebuilding the theoretical foundations of communications, and we overview each of the challenges while providing research opportunities and open questions for the research community.
Exploring the Potential of SAR Data for Cloud Removal in Optical Satellite Imagery
Jun 06, 2022
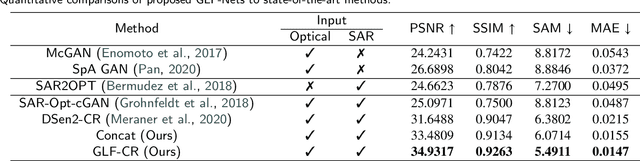
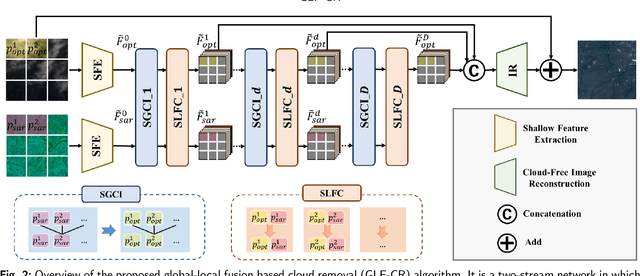
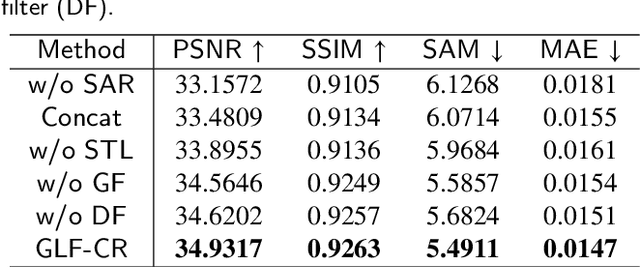
The challenge of the cloud removal task can be alleviated with the aid of Synthetic Aperture Radar (SAR) images that can penetrate cloud cover. However, the large domain gap between optical and SAR images as well as the severe speckle noise of SAR images may cause significant interference in SAR-based cloud removal, resulting in performance degeneration. In this paper, we propose a novel global-local fusion based cloud removal (GLF-CR) algorithm to leverage the complementary information embedded in SAR images. Exploiting the power of SAR information to promote cloud removal entails two aspects. The first, global fusion, guides the relationship among all local optical windows to maintain the structure of the recovered region consistent with the remaining cloud-free regions. The second, local fusion, transfers complementary information embedded in the SAR image that corresponds to cloudy areas to generate reliable texture details of the missing regions, and uses dynamic filtering to alleviate the performance degradation caused by speckle noise. Extensive evaluation demonstrates that the proposed algorithm can yield high quality cloud-free images and performs favorably against state-of-the-art cloud removal algorithms.