 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multiscale Transformer Models for Sequence Generation
Paper and Code
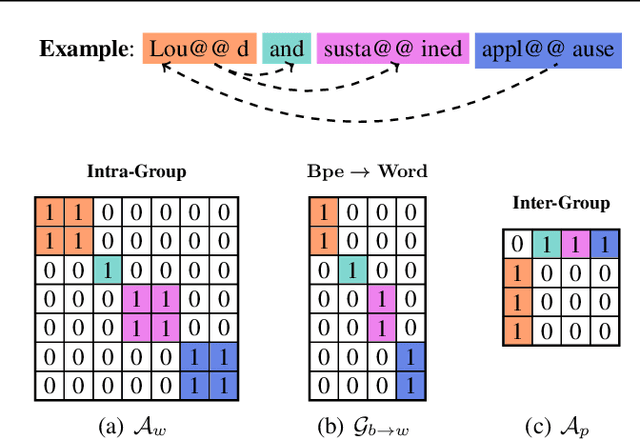

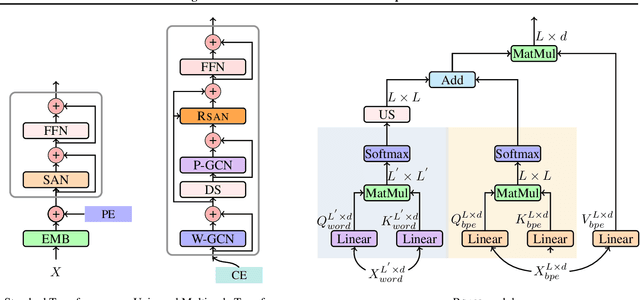
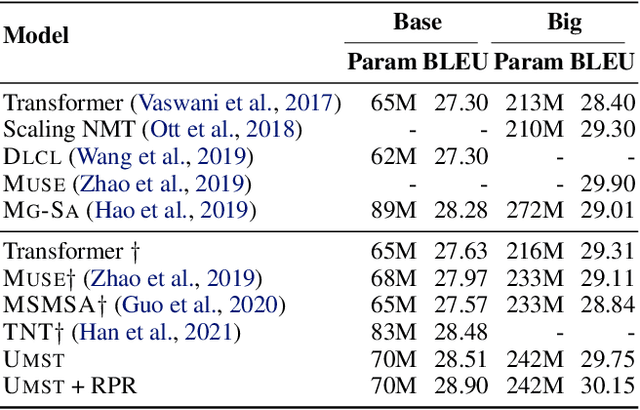
Multiscale feature hierarchies have been witnessed the success in the computer vision area. This further motivates researchers to design multiscale Transformer for natural language processing, mostly based on the self-attention mechanism. For example, restricting the receptive field across heads or extracting local fine-grained features via convolutions. However, most of existing works directly modeled local features but ignored the word-boundary information. This results in redundant and ambiguous attention distributions, which lacks of interpretability. In this work, we define those scales in different linguistic units, including sub-words, words and phrases. We built a multiscale Transformer model by establishing relationships among scales based on word-boundary information and phrase-level prior knowledge. The proposed \textbf{U}niversal \textbf{M}ulti\textbf{S}cale \textbf{T}ransformer, namely \textsc{Umst}, was evaluated on two sequence generation tasks. Notably, it yielded consistent performance gains over the strong baseline on several test sets without sacrificing the efficiency.