 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Metadata-enhanced contrastive learning from retinal optical coherence tomography images
Aug 04, 2022
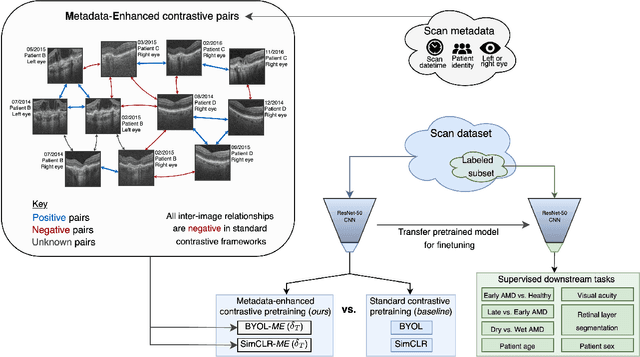
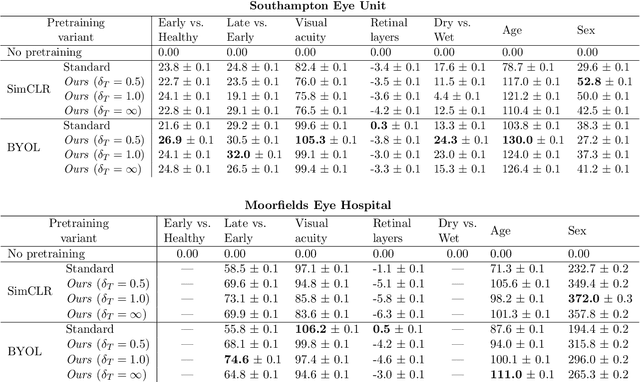
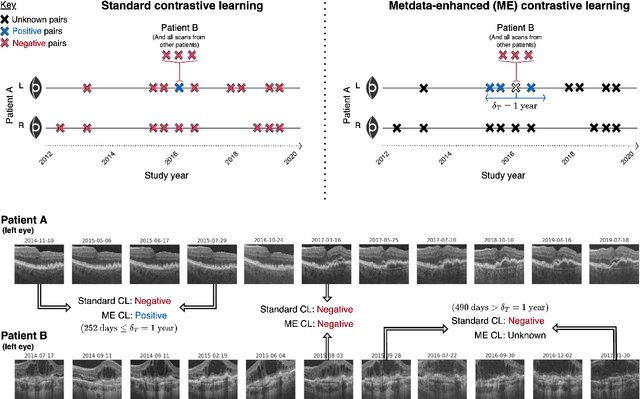
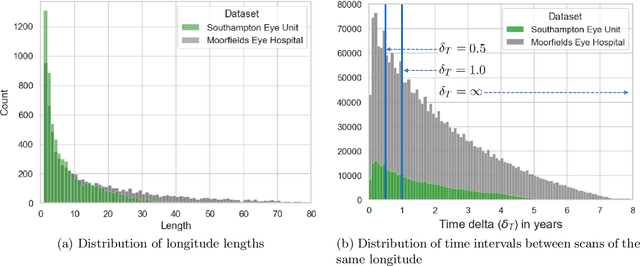
Supervised deep learning algorithms hold great potential to automate screening, monitoring and grading of medical images. However, training performant models has typically required vast quantities of labelled data, which is scarcely available in the medical domain. Self-supervised contrastive frameworks relax this dependency by first learning from unlabelled images. In this work we show that pretraining with two contrastive methods, SimCLR and BYOL, improves the utility of deep learning with regard to the clinical assessment of age-related macular degeneration (AMD). In experiments using two large clinical datasets containing 170,427 optical coherence tomography (OCT) images of 7,912 patients, we evaluate benefits attributed to pretraining across seven downstream tasks ranging from AMD stage and type classification to prediction of functional endpoints to segmentation of retinal layers, finding performance significantly increased in six out of seven tasks with fewer labels. However, standard contrastive frameworks have two known weaknesses that are detrimental to pretraining in the medical domain. Several of the image transformations used to create positive contrastive pairs are not applicable to greyscale medical scans. Furthermore, medical images often depict the same anatomical region and disease severity, resulting in numerous misleading negative pairs. To address these issues we develop a novel metadata-enhanced approach that exploits the rich set of inherently available patient information. To this end we employ records for patient identity, eye position (i.e. left or right) and time series data to indicate the typically unknowable set of inter-image contrastive relationships. By leveraging this often neglected information our metadata-enhanced contrastive pretraining leads to further benefits and outperforms conventional contrastive methods in five out of seven downstream tasks.
MatSciBERT: A Materials Domain Language Model for Text Mining and Information Extraction
Sep 30, 2021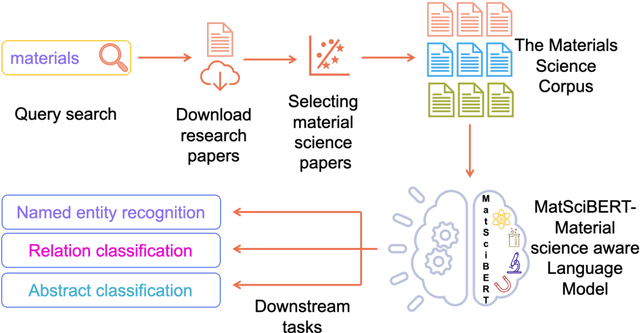
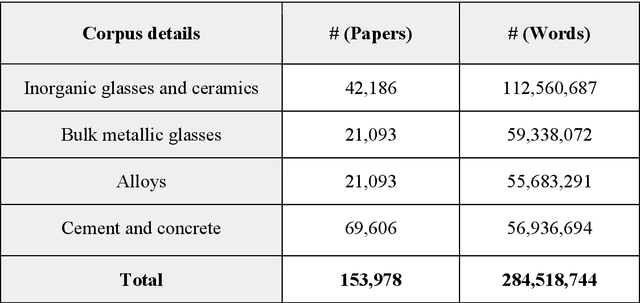
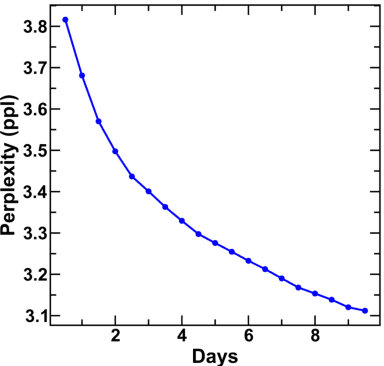
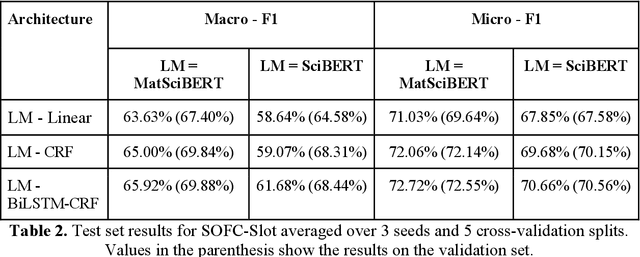
An overwhelmingly large amount of knowledge in the materials domain is generated and stored as text published in peer-reviewed scientific literature. Recent developments in natural language processing, such as bidirectional encoder representations from transformers (BERT) models, provide promising tools to extract information from these texts. However, direct application of these models in the materials domain may yield suboptimal results as the models themselves may not be trained on notations and jargon that are specific to the domain. Here, we present a materials-aware language model, namely, MatSciBERT, which is trained on a large corpus of scientific literature published in the materials domain. We further evaluate the performance of MatSciBERT on three downstream tasks, namely, abstract classification, named entity recognition, and relation extraction, on different materials datasets. We show that MatSciBERT outperforms SciBERT, a language model trained on science corpus, on all the tasks. Further, we discuss some of the applications of MatSciBERT in the materials domain for extracting information, which can, in turn, contribute to materials discovery or optimization. Finally, to make the work accessible to the larger materials community, we make the pretrained and finetuned weights and the models of MatSciBERT freely accessible.
Deep 3D Vessel Segmentation based on Cross Transformer Network
Aug 23, 2022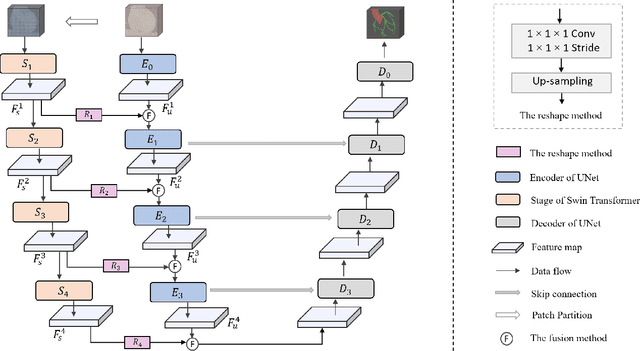
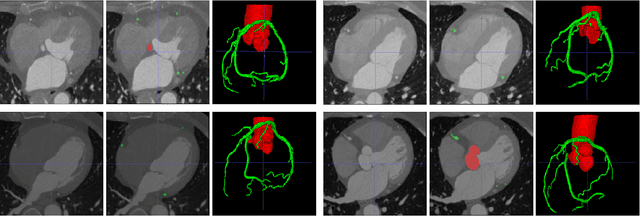
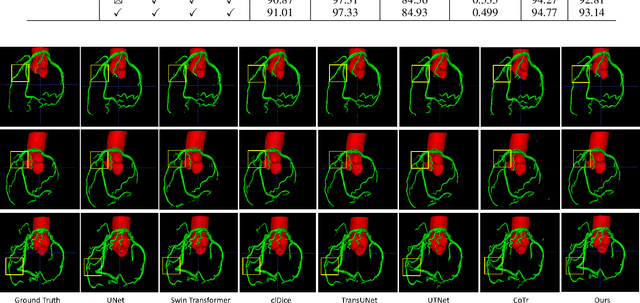
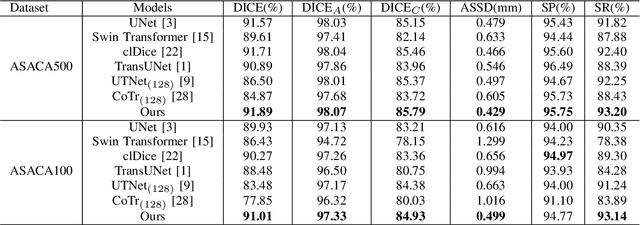
The coronary microvascular disease poses a great threat to human health. Computer-aided analysis/diagnosis systems help physicians intervene in the disease at early stages, where 3D vessel segmentation is a fundamental step. However, there is a lack of carefully annotated dataset to support algorithm development and evaluation. On the other hand, the commonly-used U-Net structures often yield disconnected and inaccurate segmentation results, especially for small vessel structures. In this paper, motivated by the data scarcity, we first construct two large-scale vessel segmentation datasets consisting of 100 and 500 computed tomography (CT) volumes with pixel-level annotations by experienced radiologists. To enhance the U-Net, we further propose the cross transformer network (CTN) for fine-grained vessel segmentation. In CTN, a transformer module is constructed in parallel to a U-Net to learn long-distance dependencies between different anatomical regions; and these dependencies are communicated to the U-Net at multiple stages to endow it with global awareness. Experimental results on the two in-house datasets indicate that this hybrid model alleviates unexpected disconnections by considering topological information across regions. Our codes, together with the trained models are made publicly available at https://github.com/qibaolian/ctn.
Online Information-Aware Motion Planning with Inertial Parameter Learning for Robotic Free-Flyers
Dec 11, 2021
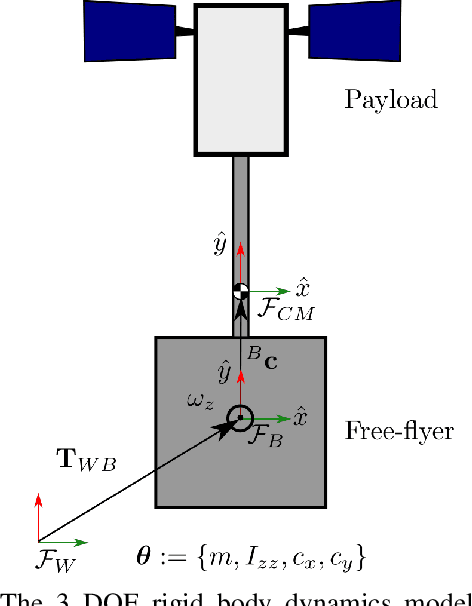
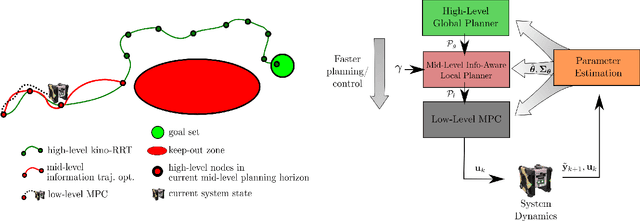

Space free-flyers like the Astrobee robots currently operating aboard the International Space Station must operate with inherent system uncertainties. Parametric uncertainties like mass and moment of inertia are especially important to quantify in these safety-critical space systems and can change in scenarios such as on-orbit cargo movement, where unknown grappled payloads significantly change the system dynamics. Cautiously learning these uncertainties en route can potentially avoid time- and fuel-consuming pure system identification maneuvers. Recognizing this, this work proposes RATTLE, an online information-aware motion planning algorithm that explicitly weights parametric model-learning coupled with real-time replanning capability that can take advantage of improved system models. The method consists of a two-tiered (global and local) planner, a low-level model predictive controller, and an online parameter estimator that produces estimates of the robot's inertial properties for more informed control and replanning on-the-fly; all levels of the planning and control feature online update-able models. Simulation results of RATTLE for the Astrobee free-flyer grappling an uncertain payload are presented alongside results of a hardware demonstration showcasing the ability to explicitly encourage model parametric learning while achieving otherwise useful motion.
Efficient Learning of Pinball TWSVM using Privileged Information and its applications
Jul 14, 2021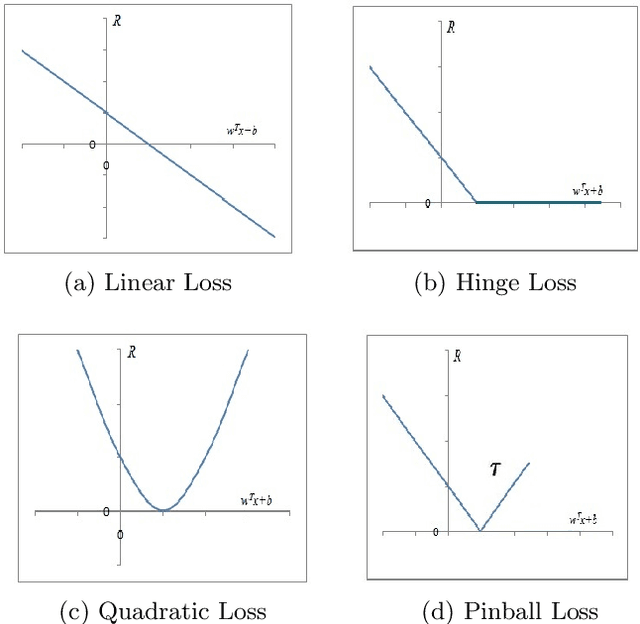

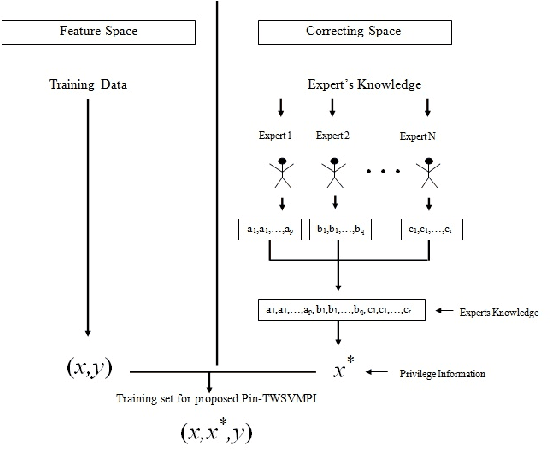

In any learning framework, an expert knowledge always plays a crucial role. But, in the field of machine learning, the knowledge offered by an expert is rarely used. Moreover, machine learning algorithms (SVM based) generally use hinge loss function which is sensitive towards the noise. Thus, in order to get the advantage from an expert knowledge and to reduce the sensitivity towards the noise, in this paper, we propose privileged information based Twin Pinball Support Vector Machine classifier (Pin-TWSVMPI) where expert's knowledge is in the form of privileged information. The proposed Pin-TWSVMPI incorporates privileged information by using correcting function so as to obtain two nonparallel decision hyperplanes. Further, in order to make computations more efficient and fast, we use Sequential Minimal Optimization (SMO) technique for obtaining the classifier and have also shown its application for Pedestrian detection and Handwritten digit recognition. Further, for UCI datasets, we first implement a procedure which extracts privileged information from the features of the dataset which are then further utilized by Pin-TWSVMPI that leads to enhancement in classification accuracy with comparatively lesser computational time.
Steps to Knowledge Graphs Quality Assessment
Aug 16, 2022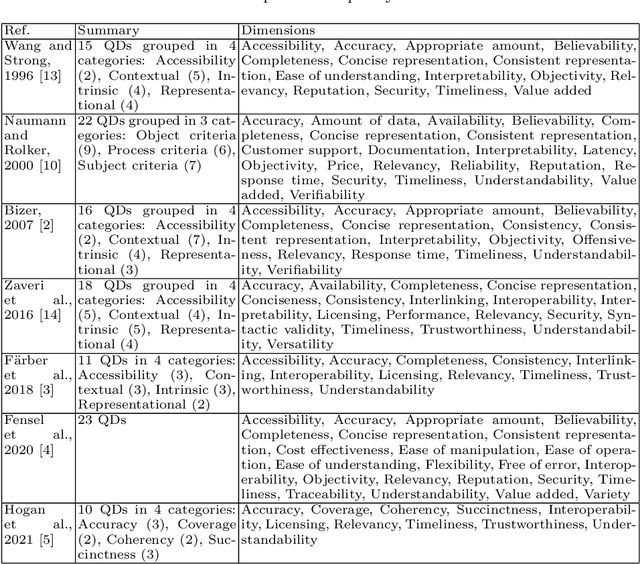
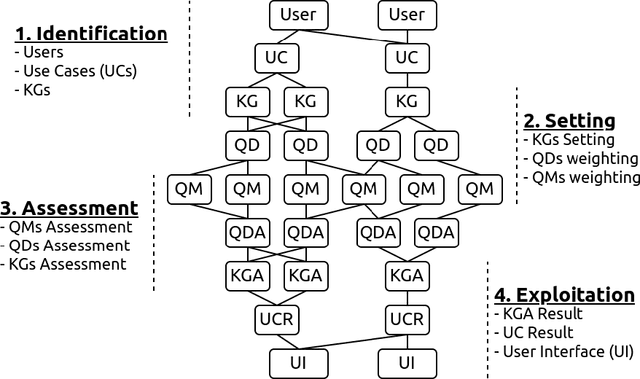
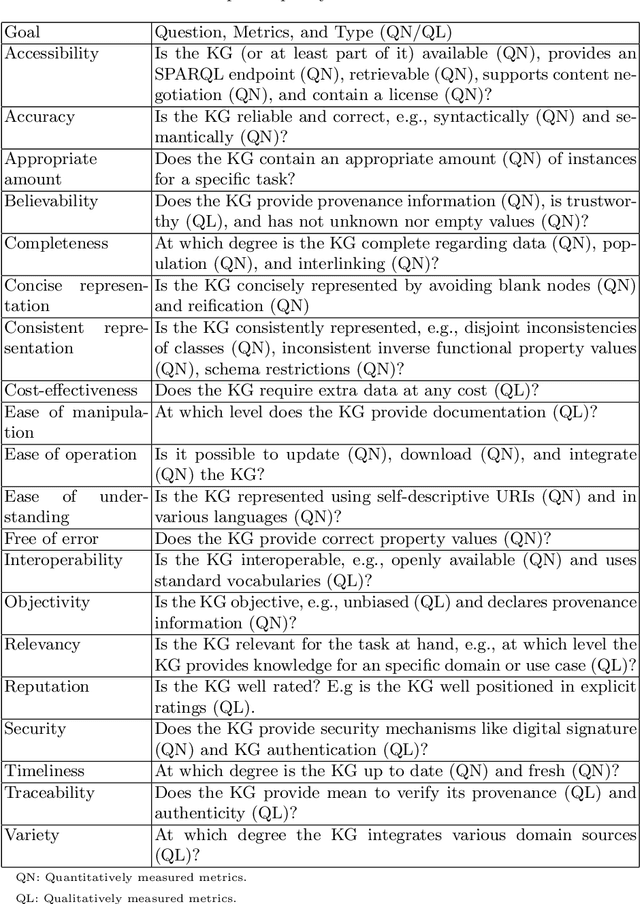
Knowledge Graphs (KGs) have been popularized during the last decade, for instance, they are used widely in the context of the web. In 2012 Google has presented the Google's Knowledge Graph that is used to improve their web search services. The web also hosts different KGs, such as DBpedia and Wikidata, which are used in various applications like personal assistants and question-answering systems. Various web applications rely on KGs to provide concise, complete, accurate, and fresh answer to users. However, what is the quality of those KGs? In which cases should a Knowledge Graph (KG) be used? How might they be evaluated? We reviewed the literature on quality assessment of data, information, linked data, and KGs. We extended the current state-of-the-art frameworks by adding various quality dimensions (QDs) and quality metrics (QMs) that are specific to KGs. Furthermore, we propose a general-purpose, customizable to a domain or task, and practical quality assessment framework for assessing the quality of KGs.
Neural Pixel Composition: 3D-4D View Synthesis from Multi-Views
Jul 21, 2022
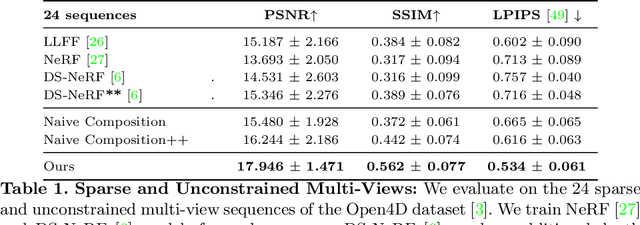
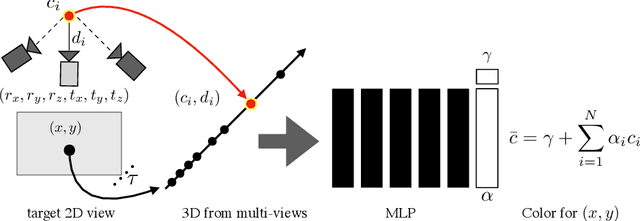
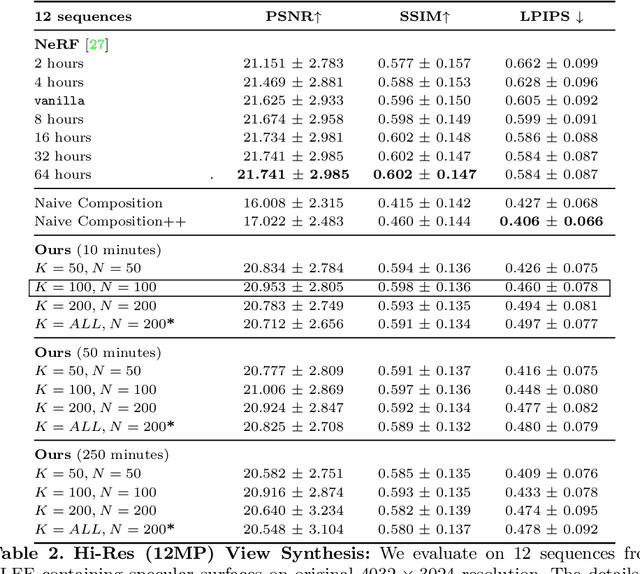
We present Neural Pixel Composition (NPC), a novel approach for continuous 3D-4D view synthesis given only a discrete set of multi-view observations as input. Existing state-of-the-art approaches require dense multi-view supervision and an extensive computational budget. The proposed formulation reliably operates on sparse and wide-baseline multi-view imagery and can be trained efficiently within a few seconds to 10 minutes for hi-res (12MP) content, i.e., 200-400X faster convergence than existing methods. Crucial to our approach are two core novelties: 1) a representation of a pixel that contains color and depth information accumulated from multi-views for a particular location and time along a line of sight, and 2) a multi-layer perceptron (MLP) that enables the composition of this rich information provided for a pixel location to obtain the final color output. We experiment with a large variety of multi-view sequences, compare to existing approaches, and achieve better results in diverse and challenging settings. Finally, our approach enables dense 3D reconstruction from sparse multi-views, where COLMAP, a state-of-the-art 3D reconstruction approach, struggles.
MultiStream: A Simple and Fast Multiple Cameras Visual Monitor and Directly Streaming
Jul 13, 2022
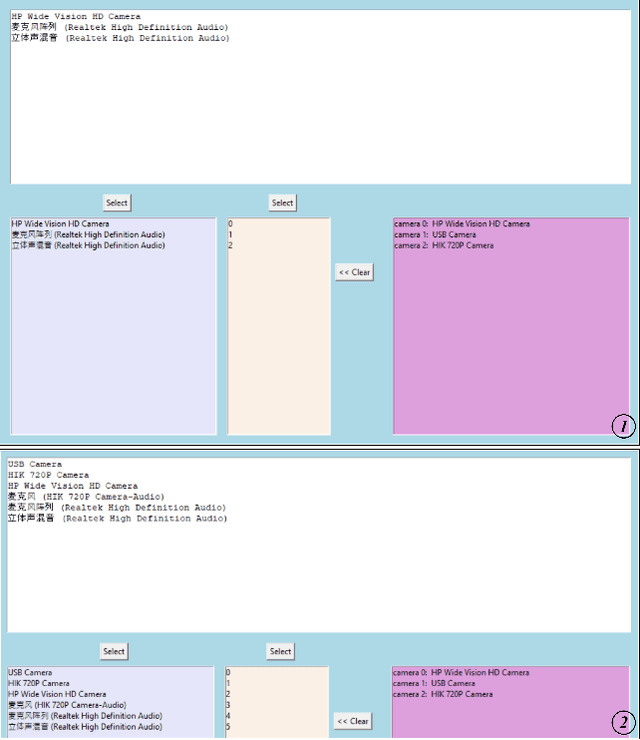
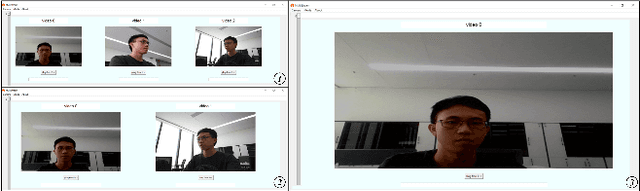
Monitoring and streaming is one of the most important applications for the real time cameras. The research of this has provided a novel design idea that uses the FFmpeg and Tkinter, combining with the libraries: OpenCV and PIL to develop a simple but fast streaming toolkit MultiSteam that can achieve the function of visible monitoring streaming for multiple simultaneously. MultiStream is able to automatically arrange the layout of the displays of multiple camera windows and intelligently analyze the input streaming URL to select the correct corresponding streaming communication protocol. Multiple cameras can be streamed with different communication protocols or the same protocol. Besides, the paper has tested the different streaming speeds for different protocols in camera streaming. MultiStream is able to gain the information of media equipment on the computer. The configuration information for media-id selection and multiple cameras streaming can be saved as json files.
Few-shot Fine-grained Image Classification via Multi-Frequency Neighborhood and Double-cross Modulation
Jul 18, 2022
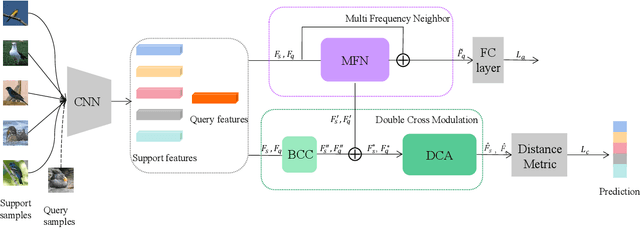
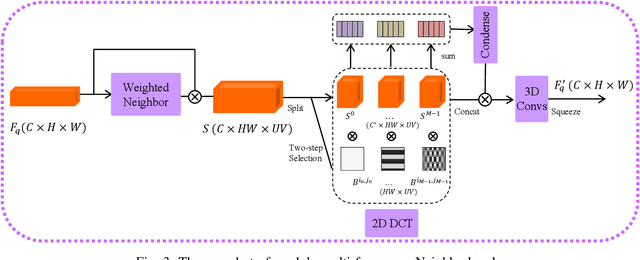
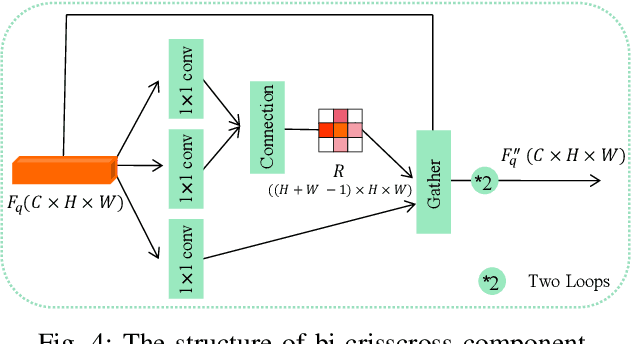
Traditional fine-grained image classification typically relies on large-scale training samples with annotated ground-truth. However, some sub-categories may have few available samples in real-world applications. In this paper, we propose a novel few-shot fine-grained image classification network (FicNet) using multi-frequency Neighborhood (MFN) and double-cross modulation (DCM). Module MFN is adopted to capture the information in spatial domain and frequency domain. Then, the self-similarity and multi-frequency components are extracted to produce multi-frequency structural representation. DCM employs bi-crisscross component and double 3D cross-attention components to modulate the embedding process by considering global context information and subtle relationship between categories, respectively. The comprehensive experiments on three fine-grained benchmark datasets for two few-shot tasks verify that FicNet has excellent performance compared to the state-of-the-art methods. Especially, the experiments on two datasets, "Caltech-UCSD Birds" and "Stanford Cars", can obtain classification accuracy 93.17\% and 95.36\%, respectively. They are even higher than that the general fine-grained image classification methods can achieve.
PASTA-GAN++: A Versatile Framework for High-Resolution Unpaired Virtual Try-on
Jul 27, 2022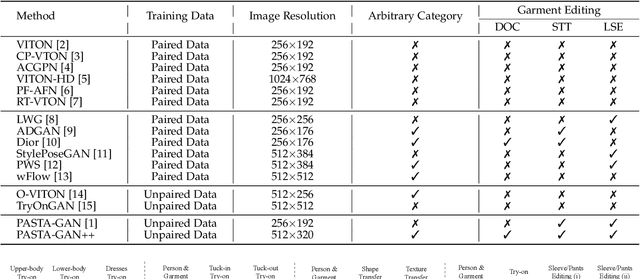

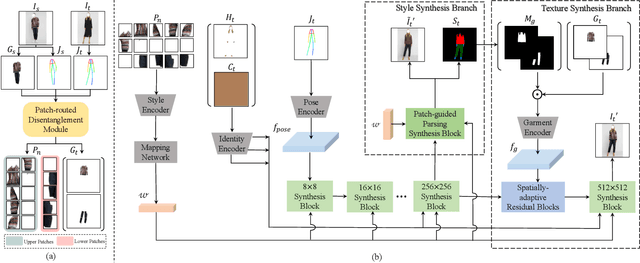

Image-based virtual try-on is one of the most promising applications of human-centric image generation due to its tremendous real-world potential. In this work, we take a step forwards to explore versatile virtual try-on solutions, which we argue should possess three main properties, namely, they should support unsupervised training, arbitrary garment categories, and controllable garment editing. To this end, we propose a characteristic-preserving end-to-end network, the PAtch-routed SpaTially-Adaptive GAN++ (PASTA-GAN++), to achieve a versatile system for high-resolution unpaired virtual try-on. Specifically, our PASTA-GAN++ consists of an innovative patch-routed disentanglement module to decouple the intact garment into normalized patches, which is capable of retaining garment style information while eliminating the garment spatial information, thus alleviating the overfitting issue during unsupervised training. Furthermore, PASTA-GAN++ introduces a patch-based garment representation and a patch-guided parsing synthesis block, allowing it to handle arbitrary garment categories and support local garment editing. Finally, to obtain try-on results with realistic texture details, PASTA-GAN++ incorporates a novel spatially-adaptive residual module to inject the coarse warped garment feature into the generator. Extensive experiments on our newly collected UnPaired virtual Try-on (UPT) dataset demonstrate the superiority of PASTA-GAN++ over existing SOTAs and its ability for controllable garment editing.