 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMamba-Driven Topology Fusion for Monocular 3-D Human Pose Estimation
May 27, 2025Transformer-based methods for 3-D human pose estimation face significant computational challenges due to the quadratic growth of self-attention mechanism complexity with sequence length. Recently, the Mamba model has substantially reduced computational overhead and demonstrated outstanding performance in modeling long sequences by leveraging state space model (SSM). However, the ability of SSM to process sequential data is not suitable for 3-D joint sequences with topological structures, and the causal convolution structure in Mamba also lacks insight into local joint relationships. To address these issues, we propose the Mamba-Driven Topology Fusion framework in this paper. Specifically, the proposed Bone Aware Module infers the direction and length of bone vectors in the spherical coordinate system, providing effective topological guidance for the Mamba model in processing joint sequences. Furthermore, we enhance the convolutional structure within the Mamba model by integrating forward and backward graph convolutional network, enabling it to better capture local joint dependencies. Finally, we design a Spatiotemporal Refinement Module to model both temporal and spatial relationships within the sequence. Through the incorporation of skeletal topology, our approach effectively alleviates Mamba's limitations in capturing human structural relationships. We conduct extensive experiments on the Human3.6M and MPI-INF-3DHP datasets for testing and comparison, and the results show that the proposed method greatly reduces computational cost while achieving higher accuracy. Ablation studies further demonstrate the effectiveness of each proposed module. The code and models will be released.
Spectral Compression Transformer with Line Pose Graph for Monocular 3D Human Pose Estimation
May 27, 2025Transformer-based 3D human pose estimation methods suffer from high computational costs due to the quadratic complexity of self-attention with respect to sequence length. Additionally, pose sequences often contain significant redundancy between frames. However, recent methods typically fail to improve model capacity while effectively eliminating sequence redundancy. In this work, we introduce the Spectral Compression Transformer (SCT) to reduce sequence length and accelerate computation. The SCT encoder treats hidden features between blocks as Temporal Feature Signals (TFS) and applies the Discrete Cosine Transform, a Fourier transform-based technique, to determine the spectral components to be retained. By filtering out certain high-frequency noise components, SCT compresses the sequence length and reduces redundancy. To further enrich the input sequence with prior structural information, we propose the Line Pose Graph (LPG) based on line graph theory. The LPG generates skeletal position information that complements the input 2D joint positions, thereby improving the model's performance. Finally, we design a dual-stream network architecture to effectively model spatial joint relationships and the compressed motion trajectory within the pose sequence. Extensive experiments on two benchmark datasets (i.e., Human3.6M and MPI-INF-3DHP) demonstrate that our model achieves state-of-the-art performance with improved computational efficiency. For example, on the Human3.6M dataset, our method achieves an MPJPE of 37.7mm while maintaining a low computational cost. Furthermore, we perform ablation studies on each module to assess its effectiveness. The code and models will be released.
Dual-stream Transformer-GCN Model with Contextualized Representations Learning for Monocular 3D Human Pose Estimation
Apr 02, 2025



This paper introduces a novel approach to monocular 3D human pose estimation using contextualized representation learning with the Transformer-GCN dual-stream model. Monocular 3D human pose estimation is challenged by depth ambiguity, limited 3D-labeled training data, imbalanced modeling, and restricted model generalization. To address these limitations, our work introduces a groundbreaking motion pre-training method based on contextualized representation learning. Specifically, our method involves masking 2D pose features and utilizing a Transformer-GCN dual-stream model to learn high-dimensional representations through a self-distillation setup. By focusing on contextualized representation learning and spatial-temporal modeling, our approach enhances the model's ability to understand spatial-temporal relationships between postures, resulting in superior generalization. Furthermore, leveraging the Transformer-GCN dual-stream model, our approach effectively balances global and local interactions in video pose estimation. The model adaptively integrates information from both the Transformer and GCN streams, where the GCN stream effectively learns local relationships between adjacent key points and frames, while the Transformer stream captures comprehensive global spatial and temporal features. Our model achieves state-of-the-art performance on two benchmark datasets, with an MPJPE of 38.0mm and P-MPJPE of 31.9mm on Human3.6M, and an MPJPE of 15.9mm on MPI-INF-3DHP. Furthermore, visual experiments on public datasets and in-the-wild videos demonstrate the robustness and generalization capabilities of our approach.
MFSR: Multi-fractal Feature for Super-resolution Reconstruction with Fine Details Recovery
Feb 27, 2025



In the process of performing image super-resolution processing, the processing of complex localized information can have a significant impact on the quality of the image generated. Fractal features can capture the rich details of both micro and macro texture structures in an image. Therefore, we propose a diffusion model-based super-resolution method incorporating fractal features of low-resolution images, named MFSR. MFSR leverages these fractal features as reinforcement conditions in the denoising process of the diffusion model to ensure accurate recovery of texture information. MFSR employs convolution as a soft assignment to approximate the fractal features of low-resolution images. This approach is also used to approximate the density feature maps of these images. By using soft assignment, the spatial layout of the image is described hierarchically, encoding the self-similarity properties of the image at different scales. Different processing methods are applied to various types of features to enrich the information acquired by the model. In addition, a sub-denoiser is integrated in the denoising U-Net to reduce the noise in the feature maps during the up-sampling process in order to improve the quality of the generated images. Experiments conducted on various face and natural image datasets demonstrate that MFSR can generate higher quality images.
InvKA: Gait Recognition via Invertible Koopman Autoencoder
Sep 27, 2023Most current gait recognition methods suffer from poor interpretability and high computational cost. To improve interpretability, we investigate gait features in the embedding space based on Koopman operator theory. The transition matrix in this space captures complex kinematic features of gait cycles, namely the Koopman operator. The diagonal elements of the operator matrix can represent the overall motion trend, providing a physically meaningful descriptor. To reduce the computational cost of our algorithm, we use a reversible autoencoder to reduce the model size and eliminate convolutional layers to compress its depth, resulting in fewer floating-point operations. Experimental results on multiple datasets show that our method reduces computational cost to 1% compared to state-of-the-art methods while achieving competitive recognition accuracy 98% on non-occlusion datasets.
Few-shot Fine-grained Image Classification via Multi-Frequency Neighborhood and Double-cross Modulation
Jul 18, 2022
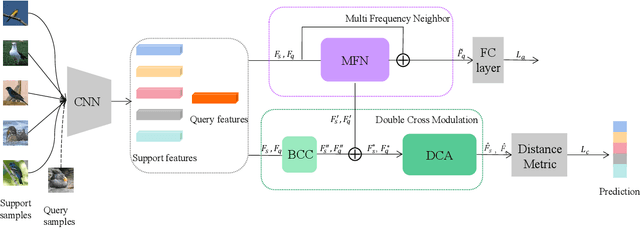
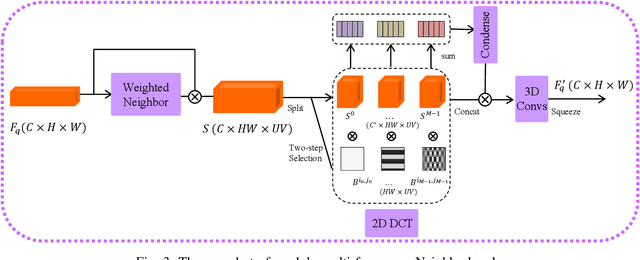
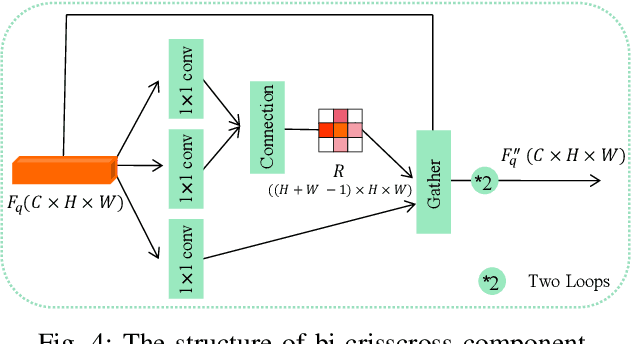
Traditional fine-grained image classification typically relies on large-scale training samples with annotated ground-truth. However, some sub-categories may have few available samples in real-world applications. In this paper, we propose a novel few-shot fine-grained image classification network (FicNet) using multi-frequency Neighborhood (MFN) and double-cross modulation (DCM). Module MFN is adopted to capture the information in spatial domain and frequency domain. Then, the self-similarity and multi-frequency components are extracted to produce multi-frequency structural representation. DCM employs bi-crisscross component and double 3D cross-attention components to modulate the embedding process by considering global context information and subtle relationship between categories, respectively. The comprehensive experiments on three fine-grained benchmark datasets for two few-shot tasks verify that FicNet has excellent performance compared to the state-of-the-art methods. Especially, the experiments on two datasets, "Caltech-UCSD Birds" and "Stanford Cars", can obtain classification accuracy 93.17\% and 95.36\%, respectively. They are even higher than that the general fine-grained image classification methods can achieve.