 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Multimodal LLMs Solve the Basic Perception Problems of Percept-V?
Aug 28, 2025



The reasoning abilities of Multimodal Large Language Models (MLLMs) have garnered a lot of attention in recent times, with advances made in frontiers like coding, mathematics, and science. However, very limited experiments have been done to assess their performance in simple perception tasks performed over uncontaminated, generated images containing basic shapes and structures. To address this issue, the paper introduces a dataset, Percept-V, containing a total of 7200 program-generated images equally divided into 30 categories, each testing a combination of visual perception skills. Unlike previously proposed datasets, Percept-V comprises very basic tasks of varying complexity that test the perception abilities of MLLMs. This dataset is then tested on state-of-the-art MLLMs like GPT-4o, Gemini, and Claude as well as Large Reasoning Models (LRMs) like OpenAI o4-mini and DeepSeek R1 to gauge their performance. Contrary to the evidence that MLLMs excel in many complex tasks, our experiments show a significant drop in the models' performance with increasing problem complexity across all categories. An analysis of the performances also reveals that the tested MLLMs exhibit a similar trend in accuracy across categories, testing a particular cognitive skill and find some skills to be more difficult than others.
Foundational Large Language Models for Materials Research
Dec 12, 2024



Materials discovery and development are critical for addressing global challenges. Yet, the exponential growth in materials science literature comprising vast amounts of textual data has created significant bottlenecks in knowledge extraction, synthesis, and scientific reasoning. Large Language Models (LLMs) offer unprecedented opportunities to accelerate materials research through automated analysis and prediction. Still, their effective deployment requires domain-specific adaptation for understanding and solving domain-relevant tasks. Here, we present LLaMat, a family of foundational models for materials science developed through continued pretraining of LLaMA models on an extensive corpus of materials literature and crystallographic data. Through systematic evaluation, we demonstrate that LLaMat excels in materials-specific NLP and structured information extraction while maintaining general linguistic capabilities. The specialized LLaMat-CIF variant demonstrates unprecedented capabilities in crystal structure generation, predicting stable crystals with high coverage across the periodic table. Intriguingly, despite LLaMA-3's superior performance in comparison to LLaMA-2, we observe that LLaMat-2 demonstrates unexpectedly enhanced domain-specific performance across diverse materials science tasks, including structured information extraction from text and tables, more particularly in crystal structure generation, a potential adaptation rigidity in overtrained LLMs. Altogether, the present work demonstrates the effectiveness of domain adaptation towards developing practically deployable LLM copilots for materials research. Beyond materials science, our findings reveal important considerations for domain adaptation of LLMs, such as model selection, training methodology, and domain-specific performance, which may influence the development of specialized scientific AI systems.
MeasureNet: Measurement Based Celiac Disease Identification
Dec 02, 2024



Celiac disease is an autoimmune disorder triggered by the consumption of gluten. It causes damage to the villi, the finger-like projections in the small intestine that are responsible for nutrient absorption. Additionally, the crypts, which form the base of the villi, are also affected, impairing the regenerative process. The deterioration in villi length, computed as the villi-to-crypt length ratio, indicates the severity of celiac disease. However, manual measurement of villi-crypt length can be both time-consuming and susceptible to inter-observer variability, leading to inconsistencies in diagnosis. While some methods can perform measurement as a post-hoc process, they are prone to errors in the initial stages. This gap underscores the need for pathologically driven solutions that enhance measurement accuracy and reduce human error in celiac disease assessments. Our proposed method, MeasureNet, is a pathologically driven polyline detection framework incorporating polyline localization and object-driven losses specifically designed for measurement tasks. Furthermore, we leverage segmentation model to provide auxiliary guidance about crypt location when crypt are partially visible. To ensure that model is not overdependent on segmentation mask we enhance model robustness through a mask feature mixup technique. Additionally, we introduce a novel dataset for grading celiac disease, consisting of 750 annotated duodenum biopsy images. MeasureNet achieves an 82.66% classification accuracy for binary classification and 81% accuracy for multi-class grading of celiac disease. Code: https://github.com/dair-iitd/MeasureNet
MediTOD: An English Dialogue Dataset for Medical History Taking with Comprehensive Annotations
Oct 18, 2024



Medical task-oriented dialogue systems can assist doctors by collecting patient medical history, aiding in diagnosis, or guiding treatment selection, thereby reducing doctor burnout and expanding access to medical services. However, doctor-patient dialogue datasets are not readily available, primarily due to privacy regulations. Moreover, existing datasets lack comprehensive annotations involving medical slots and their different attributes, such as symptoms and their onset, progression, and severity. These comprehensive annotations are crucial for accurate diagnosis. Finally, most existing datasets are non-English, limiting their utility for the larger research community. In response, we introduce MediTOD, a new dataset of doctor-patient dialogues in English for the medical history-taking task. Collaborating with doctors, we devise a questionnaire-based labeling scheme tailored to the medical domain. Then, medical professionals create the dataset with high-quality comprehensive annotations, capturing medical slots and their attributes. We establish benchmarks in supervised and few-shot settings on MediTOD for natural language understanding, policy learning, and natural language generation subtasks, evaluating models from both TOD and biomedical domains. We make MediTOD publicly available for future research.
Simple Augmentations of Logical Rules for Neuro-Symbolic Knowledge Graph Completion
Jul 02, 2024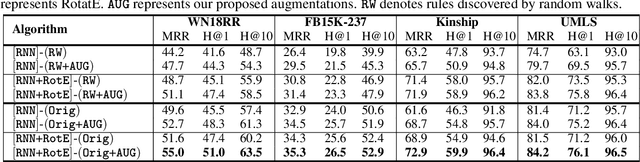
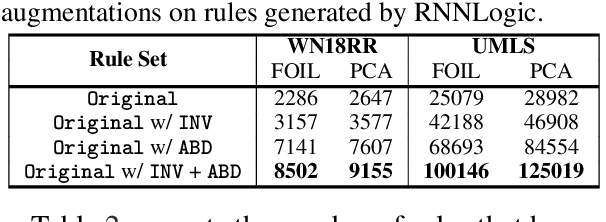
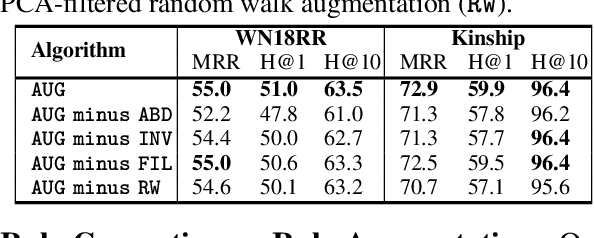
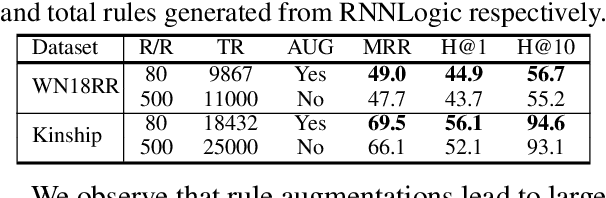
High-quality and high-coverage rule sets are imperative to the success of Neuro-Symbolic Knowledge Graph Completion (NS-KGC) models, because they form the basis of all symbolic inferences. Recent literature builds neural models for generating rule sets, however, preliminary experiments show that they struggle with maintaining high coverage. In this work, we suggest three simple augmentations to existing rule sets: (1) transforming rules to their abductive forms, (2) generating equivalent rules that use inverse forms of constituent relations and (3) random walks that propose new rules. Finally, we prune potentially low quality rules. Experiments over four datasets and five ruleset-baseline settings suggest that these simple augmentations consistently improve results, and obtain up to 7.1 pt MRR and 8.5 pt Hits@1 gains over using rules without augmentations.
SSP: Self-Supervised Prompting for Cross-Lingual Transfer to Low-Resource Languages using Large Language Models
Jun 27, 2024



Recently, very large language models (LLMs) have shown exceptional performance on several English NLP tasks with just in-context learning (ICL), but their utility in other languages is still underexplored. We investigate their effectiveness for NLP tasks in low-resource languages (LRLs), especially in the setting of zero-labelled cross-lingual transfer (0-CLT), where no labelled training data for the target language is available -- however training data from one or more related medium-resource languages (MRLs) is utilized, alongside the available unlabeled test data for a target language. We introduce Self-Supervised Prompting (SSP), a novel ICL approach tailored for the 0-CLT setting. SSP is based on the key observation that LLMs output more accurate labels if in-context exemplars are from the target language (even if their labels are slightly noisy). To operationalize this, since target language training data is not available in 0-CLT, SSP operates in two stages. In Stage I, using source MRL training data, target language's test data is noisily labeled. In Stage II, these noisy test data points are used as exemplars in ICL for further improved labelling. Additionally, our implementation of SSP uses a novel Integer Linear Programming (ILP)-based exemplar selection that balances similarity, prediction confidence (when available) and label coverage. Experiments on three tasks and eleven LRLs (from three regions) demonstrate that SSP strongly outperforms existing SOTA fine-tuned and prompting-based baselines in 0-CLT setup.
Robust Few-shot Transfer Learning for Knowledge Base Question Answering with Unanswerable Questions
Jun 20, 2024



Real-world KBQA applications require models that are (1) robust -- e.g., can differentiate between answerable and unanswerable questions, and (2) low-resource -- do not require large training data. Towards this goal, we propose the novel task of few-shot transfer for KBQA with unanswerable questions. We present FUn-FuSIC that extends the state-of-the-art (SoTA) few-shot transfer model for answerable-only KBQA to handle unanswerability. It iteratively prompts an LLM to generate logical forms for the question by providing feedback using a diverse suite of syntactic, semantic and execution guided checks, and adapts self-consistency to assess confidence of the LLM to decide answerability. Experiments over newly constructed datasets show that FUn-FuSIC outperforms suitable adaptations of the SoTA model for KBQA with unanswerability, and the SoTA model for answerable-only few-shot-transfer KBQA.
Synergizing In-context Learning with Hints for End-to-end Task-oriented Dialog Systems
May 24, 2024Large language models (LLM) based end-to-end task-oriented dialog (TOD) systems built using few-shot (in-context) learning perform better than supervised models only when the train data is limited. This is due to the inherent ability of LLMs to learn any task with just a few demonstrations. As the number of train dialogs increases, supervised SoTA models surpass in-context learning LLMs as they learn to better align with the style of the system responses in the training data, which LLMs struggle to mimic. In response, we propose SyncTOD, which synergizes LLMs with useful hints about the task for improved alignment. At a high level, SyncTOD trains auxiliary models to provide these hints and select exemplars for the in-context prompts. With ChatGPT, SyncTOD achieves superior performance compared to LLM-based baselines and SoTA models in low-data settings, while retaining competitive performance in full-data settings
GenToC: Leveraging Partially-Labeled Data for Product Attribute-Value Identification
May 17, 2024



In the e-commerce domain, the accurate extraction of attribute-value pairs from product listings (e.g., Brand: Apple) is crucial for enhancing search and recommendation systems. The automation of this extraction process is challenging due to the vast diversity of product categories and their respective attributes, compounded by the lack of extensive, accurately annotated training datasets and the demand for low latency to meet the real-time needs of e-commerce platforms. To address these challenges, we introduce GenToC, a novel two-stage model for extracting attribute-value pairs from product titles. GenToC is designed to train with partially-labeled data, leveraging incomplete attribute-value pairs and obviating the need for a fully annotated dataset. Moreover, we introduce a bootstrapping method that enables GenToC to progressively refine and expand its training dataset. This enhancement substantially improves the quality of data available for training other neural network models that are typically faster but are inherently less capable than GenToC in terms of their capacity to handle partially-labeled data. By supplying an enriched dataset for training, GenToC significantly advances the performance of these alternative models, making them more suitable for real-time deployment. Our results highlight the unique capability of GenToC to learn from a limited set of labeled data and to contribute to the training of more efficient models, marking a significant leap forward in the automated extraction of attribute-value pairs from product titles. GenToC has been successfully integrated into India's largest B2B e-commerce platform, IndiaMART.com, achieving a significant increase of 21.1% in recall over the existing deployed system while maintaining a high precision of 89.5% in this challenging task.
What Can Natural Language Processing Do for Peer Review?
May 10, 2024



The number of scientific articles produced every year is growing rapidly. Providing quality control over them is crucial for scientists and, ultimately, for the public good. In modern science, this process is largely delegated to peer review -- a distributed procedure in which each submission is evaluated by several independent experts in the field. Peer review is widely used, yet it is hard, time-consuming, and prone to error. Since the artifacts involved in peer review -- manuscripts, reviews, discussions -- are largely text-based, Natural Language Processing has great potential to improve reviewing. As the emergence of large language models (LLMs) has enabled NLP assistance for many new tasks, the discussion on machine-assisted peer review is picking up the pace. Yet, where exactly is help needed, where can NLP help, and where should it stand aside? The goal of our paper is to provide a foundation for the future efforts in NLP for peer-reviewing assistance. We discuss peer review as a general process, exemplified by reviewing at AI conferences. We detail each step of the process from manuscript submission to camera-ready revision, and discuss the associated challenges and opportunities for NLP assistance, illustrated by existing work. We then turn to the big challenges in NLP for peer review as a whole, including data acquisition and licensing, operationalization and experimentation, and ethical issues. To help consolidate community efforts, we create a companion repository that aggregates key datasets pertaining to peer review. Finally, we issue a detailed call for action for the scientific community, NLP and AI researchers, policymakers, and funding bodies to help bring the research in NLP for peer review forward. We hope that our work will help set the agenda for research in machine-assisted scientific quality control in the age of AI, within the NLP community and beyond.