 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Nonparametric Contextual Bandit with Arm-level Eligibility Control for Customer Service Routing
Sep 08, 2022
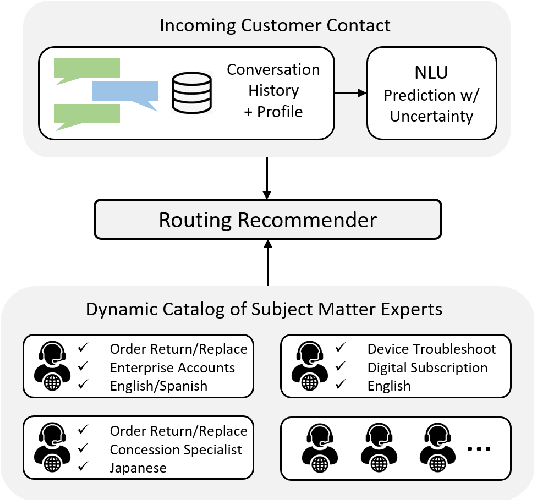
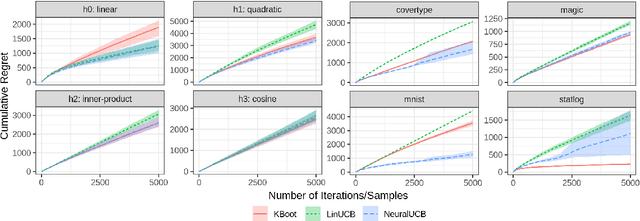
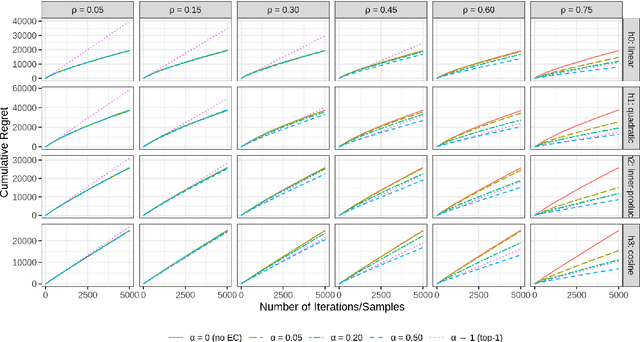
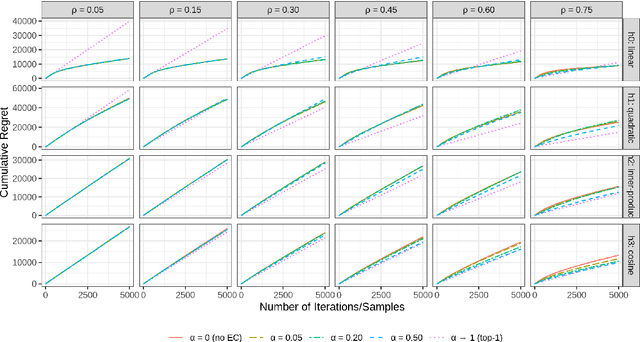
Amazon Customer Service provides real-time support for millions of customer contacts every year. While bot-resolver helps automate some traffic, we still see high demand for human agents, also called subject matter experts (SMEs). Customers outreach with questions in different domains (return policy, device troubleshooting, etc.). Depending on their training, not all SMEs are eligible to handle all contacts. Routing contacts to eligible SMEs turns out to be a non-trivial problem because SMEs' domain eligibility is subject to training quality and can change over time. To optimally recommend SMEs while simultaneously learning the true eligibility status, we propose to formulate the routing problem with a nonparametric contextual bandit algorithm (K-Boot) plus an eligibility control (EC) algorithm. K-Boot models reward with a kernel smoother on similar past samples selected by $k$-NN, and Bootstrap Thompson Sampling for exploration. EC filters arms (SMEs) by the initially system-claimed eligibility and dynamically validates the reliability of this information. The proposed K-Boot is a general bandit algorithm, and EC is applicable to other bandits. Our simulation studies show that K-Boot performs on par with state-of-the-art Bandit models, and EC boosts K-Boot performance when stochastic eligibility signal exists.
Invariant Information Bottleneck for Domain Generalization
Jun 11, 2021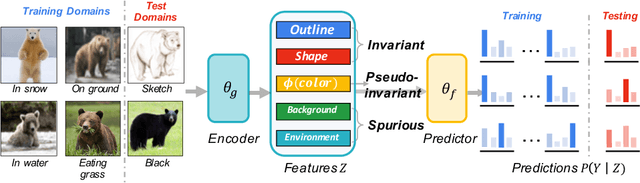
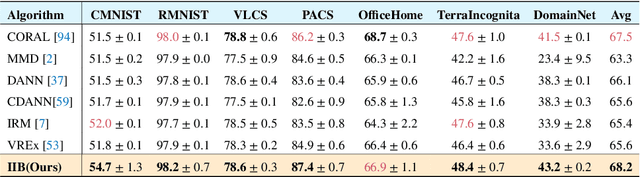
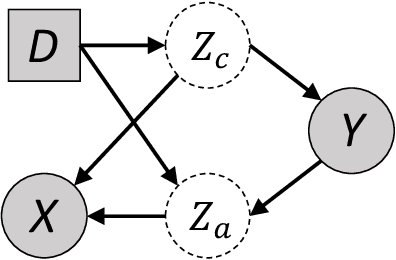
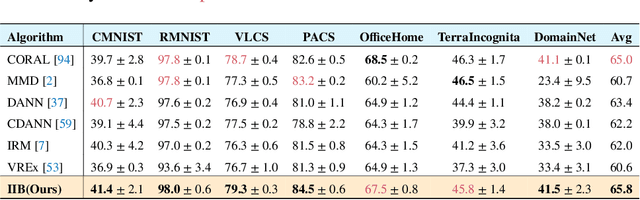
The main challenge for domain generalization (DG) is to overcome the potential distributional shift between multiple training domains and unseen test domains. One popular class of DG algorithms aims to learn representations that have an invariant causal relation across the training domains. However, certain features, called \emph{pseudo-invariant features}, may be invariant in the training domain but not the test domain and can substantially decreases the performance of existing algorithms. To address this issue, we propose a novel algorithm, called Invariant Information Bottleneck (IIB), that learns a minimally sufficient representation that is invariant across training and testing domains. By minimizing the mutual information between the representation and inputs, IIB alleviates its reliance on pseudo-invariant features, which is desirable for DG. To verify the effectiveness of the IIB principle, we conduct extensive experiments on large-scale DG benchmarks. The results show that IIB outperforms invariant learning baseline (e.g. IRM) by an average of 2.8\% and 3.8\% accuracy over two evaluation metrics.
UDC-UNet: Under-Display Camera Image Restoration via U-Shape Dynamic Network
Sep 11, 2022
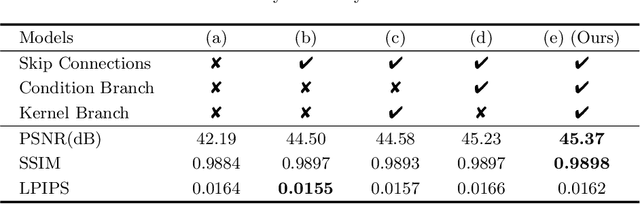
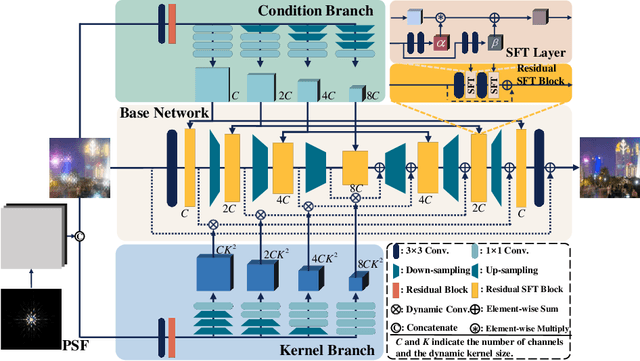

Under-Display Camera (UDC) has been widely exploited to help smartphones realize full screen display. However, as the screen could inevitably affect the light propagation process, the images captured by the UDC system usually contain flare, haze, blur, and noise. Particularly, flare and blur in UDC images could severely deteriorate the user experience in high dynamic range (HDR) scenes. In this paper, we propose a new deep model, namely UDC-UNet, to address the UDC image restoration problem with the known Point Spread Function (PSF) in HDR scenes. On the premise that Point Spread Function (PSF) of the UDC system is known, we treat UDC image restoration as a non-blind image restoration problem and propose a novel learning-based approach. Our network consists of three parts, including a U-shape base network to utilize multi-scale information, a condition branch to perform spatially variant modulation, and a kernel branch to provide the prior knowledge of the given PSF. According to the characteristics of HDR data, we additionally design a tone mapping loss to stabilize network optimization and achieve better visual quality. Experimental results show that the proposed UDC-UNet outperforms the state-of-the-art methods in quantitative and qualitative comparisons. Our approach won the second place in the UDC image restoration track of MIPI challenge. Codes will be publicly available.
Learning to diagnose common thorax diseases on chest radiographs from radiology reports in Vietnamese
Sep 11, 2022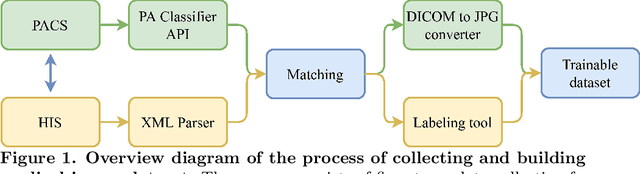
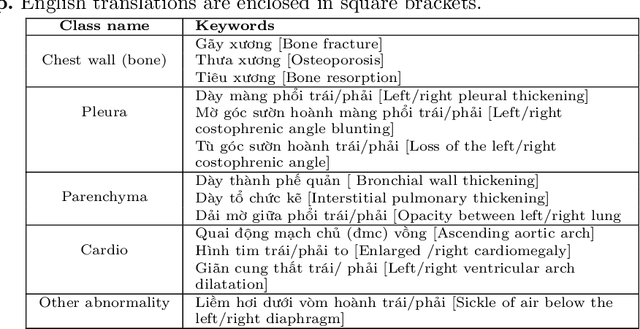

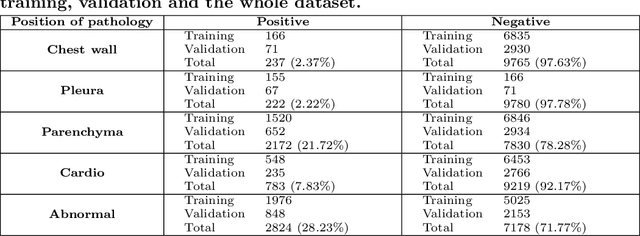
We propose a data collecting and annotation pipeline that extracts information from Vietnamese radiology reports to provide accurate labels for chest X-ray (CXR) images. This can benefit Vietnamese radiologists and clinicians by annotating data that closely match their endemic diagnosis categories which may vary from country to country. To assess the efficacy of the proposed labeling technique, we built a CXR dataset containing 9,752 studies and evaluated our pipeline using a subset of this dataset. With an F1-score of at least 0.9923, the evaluation demonstrates that our labeling tool performs precisely and consistently across all classes. After building the dataset, we train deep learning models that leverage knowledge transferred from large public CXR datasets. We employ a variety of loss functions to overcome the curse of imbalanced multi-label datasets and conduct experiments with various model architectures to select the one that delivers the best performance. Our best model (CheXpert-pretrained EfficientNet-B2) yields an F1-score of 0.6989 (95% CI 0.6740, 0.7240), AUC of 0.7912, sensitivity of 0.7064 and specificity of 0.8760 for the abnormal diagnosis in general. Finally, we demonstrate that our coarse classification (based on five specific locations of abnormalities) yields comparable results to fine classification (twelve pathologies) on the benchmark CheXpert dataset for general anomaly detection while delivering better performance in terms of the average performance of all classes.
Active Learning for Non-Parametric Choice Models
Aug 05, 2022


We study the problem of actively learning a non-parametric choice model based on consumers' decisions. We present a negative result showing that such choice models may not be identifiable. To overcome the identifiability problem, we introduce a directed acyclic graph (DAG) representation of the choice model, which in a sense captures as much information about the choice model as could information-theoretically be identified. We then consider the problem of learning an approximation to this DAG representation in an active-learning setting. We design an efficient active-learning algorithm to estimate the DAG representation of the non-parametric choice model, which runs in polynomial time when the set of frequent rankings is drawn uniformly at random. Our algorithm learns the distribution over the most popular items of frequent preferences by actively and repeatedly offering assortments of items and observing the item chosen. We show that our algorithm can better recover a set of frequent preferences on both a synthetic and publicly available dataset on consumers' preferences, compared to the corresponding non-active learning estimation algorithms. This demonstrates the value of our algorithm and active-learning approaches more generally.
Expert Opinion Elicitation for Assisting Deep Learning based Lyme Disease Classifier with Patient Data
Aug 30, 2022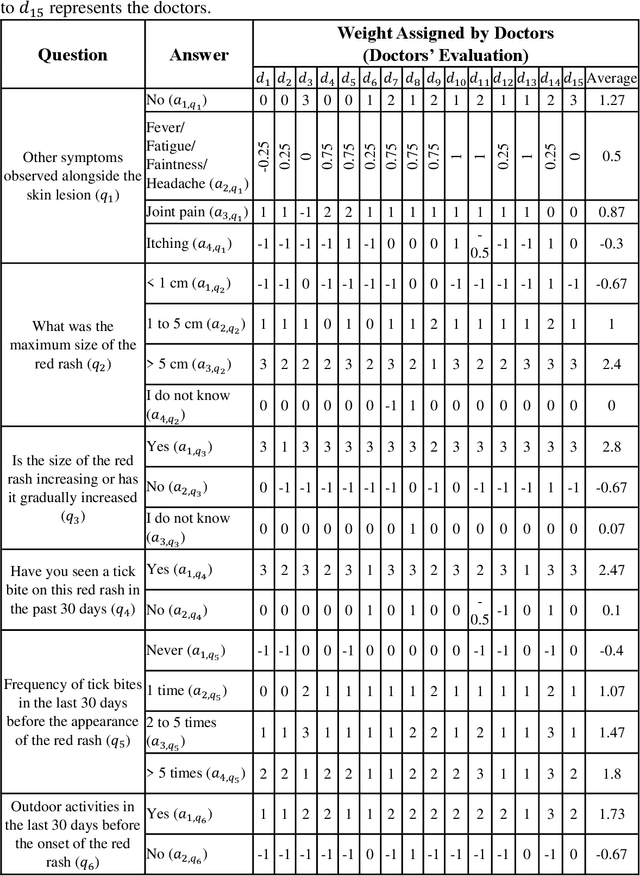
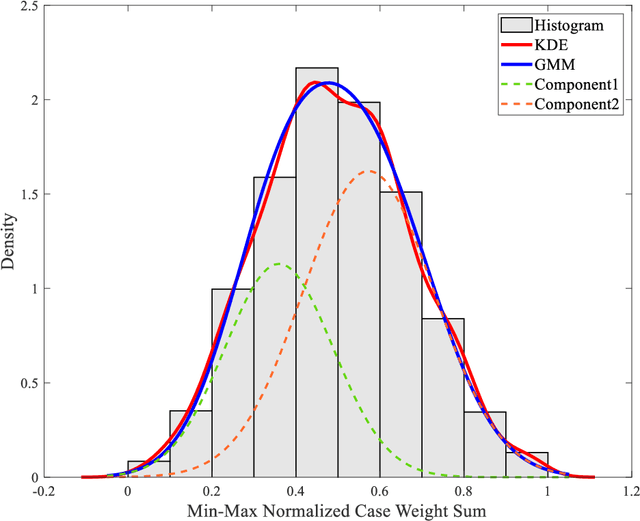
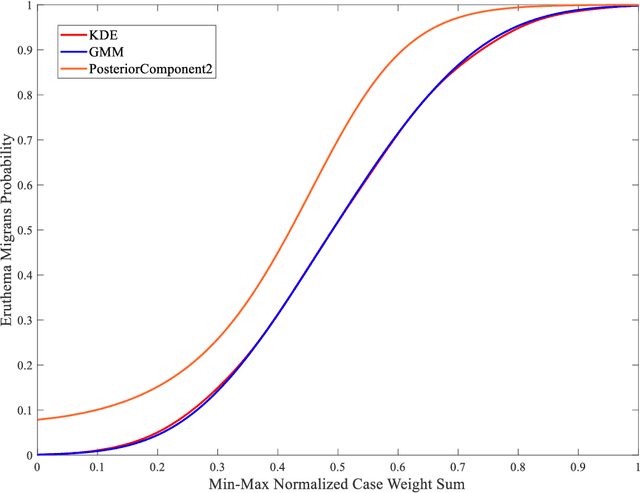
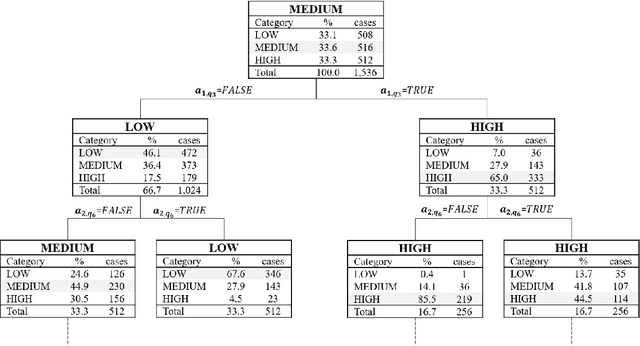
Diagnosing erythema migrans (EM) skin lesion, the most common early symptom of Lyme disease using deep learning techniques can be effective to prevent long-term complications. Existing works on deep learning based EM recognition only utilizes lesion image due to the lack of a dataset of Lyme disease related images with associated patient data. Physicians rely on patient information about the background of the skin lesion to confirm their diagnosis. In order to assist the deep learning model with a probability score calculated from patient data, this study elicited opinion from fifteen doctors. For the elicitation process, a questionnaire with questions and possible answers related to EM was prepared. Doctors provided relative weights to different answers to the questions. We converted doctors evaluations to probability scores using Gaussian mixture based density estimation. For elicited probability model validation, we exploited formal concept analysis and decision tree. The elicited probability scores can be utilized to make image based deep learning Lyme disease pre-scanners robust.
Automated recognition of the pericardium contour on processed CT images using genetic algorithms
Aug 30, 2022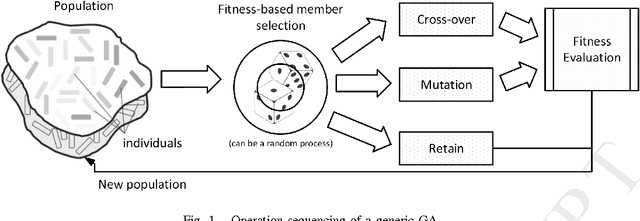

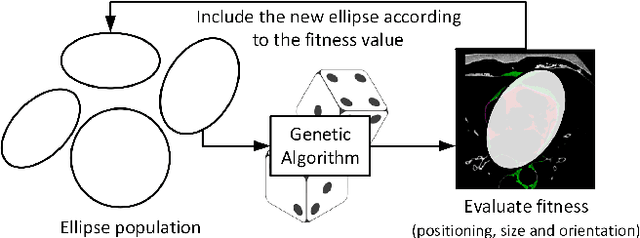

This work proposes the use of Genetic Algorithms (GA) in tracing and recognizing the pericardium contour of the human heart using Computed Tomography (CT) images. We assume that each slice of the pericardium can be modelled by an ellipse, the parameters of which need to be optimally determined. An optimal ellipse would be one that closely follows the pericardium contour and, consequently, separates appropriately the epicardial and mediastinal fats of the human heart. Tracing and automatically identifying the pericardium contour aids in medical diagnosis. Usually, this process is done manually or not done at all due to the effort required. Besides, detecting the pericardium may improve previously proposed automated methodologies that separate the two types of fat associated to the human heart. Quantification of these fats provides important health risk marker information, as they are associated with the development of certain cardiovascular pathologies. Finally, we conclude that GA offers satisfiable solutions in a feasible amount of processing time.
Contrastive Learning for Context-aware Neural Machine TranslationUsing Coreference Information
Sep 13, 2021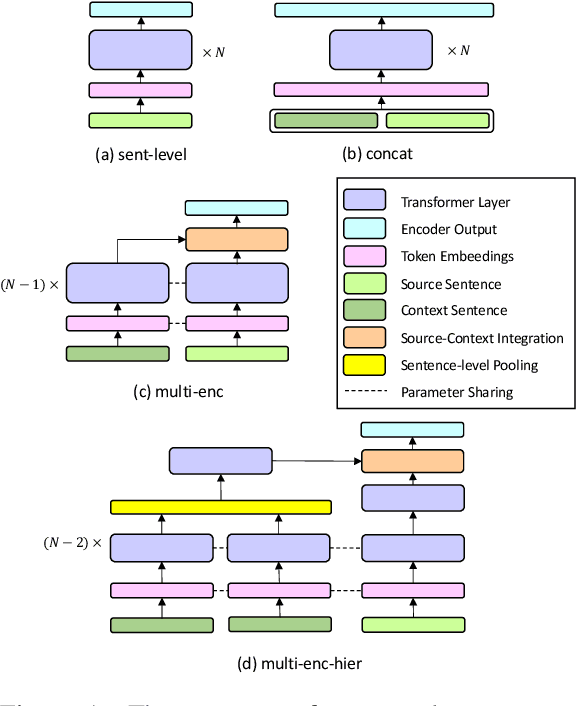
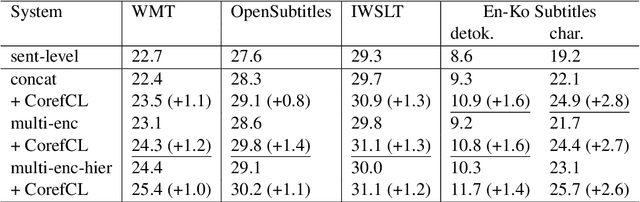

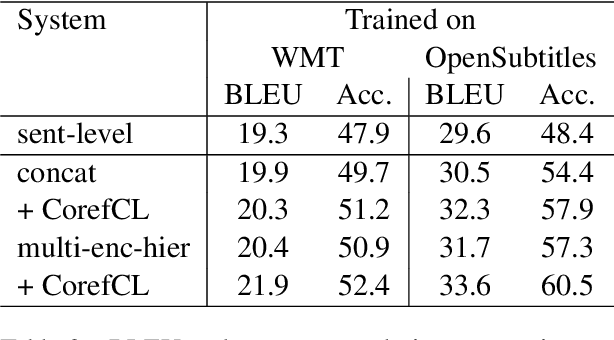
Context-aware neural machine translation (NMT) incorporates contextual information of surrounding texts, that can improve the translation quality of document-level machine translation. Many existing works on context-aware NMT have focused on developing new model architectures for incorporating additional contexts and have shown some promising results. However, most existing works rely on cross-entropy loss, resulting in limited use of contextual information. In this paper, we propose CorefCL, a novel data augmentation and contrastive learning scheme based on coreference between the source and contextual sentences. By corrupting automatically detected coreference mentions in the contextual sentence, CorefCL can train the model to be sensitive to coreference inconsistency. We experimented with our method on common context-aware NMT models and two document-level translation tasks. In the experiments, our method consistently improved BLEU of compared models on English-German and English-Korean tasks. We also show that our method significantly improves coreference resolution in the English-German contrastive test suite.
WiForceSticker: Batteryless, Thin Sticker-like Flexible Force Sensor
Sep 19, 2022
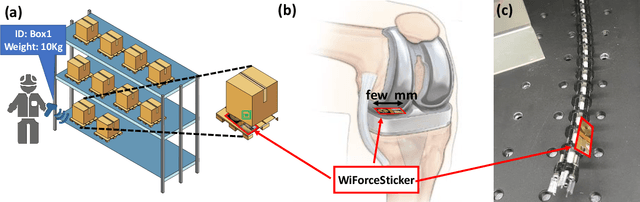
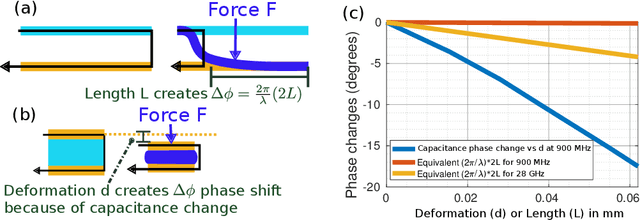

Any two objects in contact with each other exert a force that could be simply due to gravity or mechanical contact, such as a robotic arm gripping an object or even the contact between two bones at our knee joints. The ability to naturally measure and monitor these contact forces allows a plethora of applications from warehouse management (detect faulty packages based on weights) to robotics (making a robotic arms' grip as sensitive as human skin) and healthcare (knee-implants). It is challenging to design a ubiquitous force sensor that can be used naturally for all these applications. First, the sensor should be small enough to fit in narrow spaces. Next, we don't want to lay cumbersome cables to read the force values from the sensors. Finally, we need to have a battery-free design to meet the in-vivo applications. We develop WiForceSticker, a wireless, battery-free, sticker-like force sensor that can be ubiquitously deployed on any surface, such as all warehouse packages, robotic arms, and knee joints. WiForceSticker first designs a tiny $4$~mm~$\times$~$2$~mm~$\times$~$0.4$~mm capacitative sensor design equipped with a $10$~mm~$\times$~$10$~mm antenna designed on a flexible PCB substrate. Secondly, it introduces a new mechanism to transduce the force information on ambient RF radiations that can be read by a remotely located reader wirelessly without requiring any battery or active components at the force sensor, by interfacing the sensors with COTS RFID systems. The sensor can detect forces in the range of $0$-$6$~N with sensing accuracy of $<0.5$~N across multiple testing environments and evaluated with over $10,000$ varying force level presses on the sensor. We also showcase two application case studies with our designed sensors, weighing warehouse packages and sensing forces applied by bone joints.
Simpler is better: Multilevel Abstraction with Graph Convolutional Recurrent Neural Network Cells for Traffic Prediction
Sep 08, 2022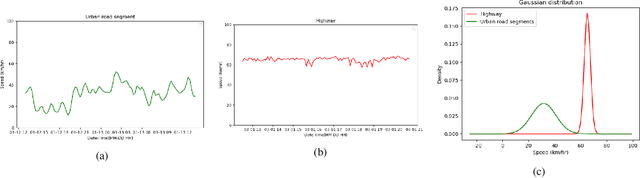
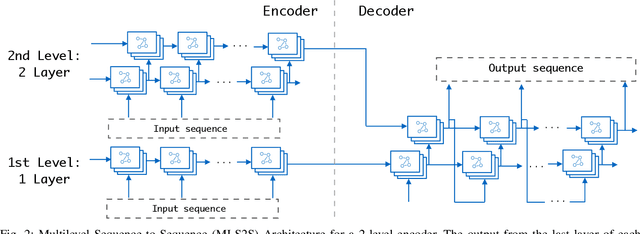
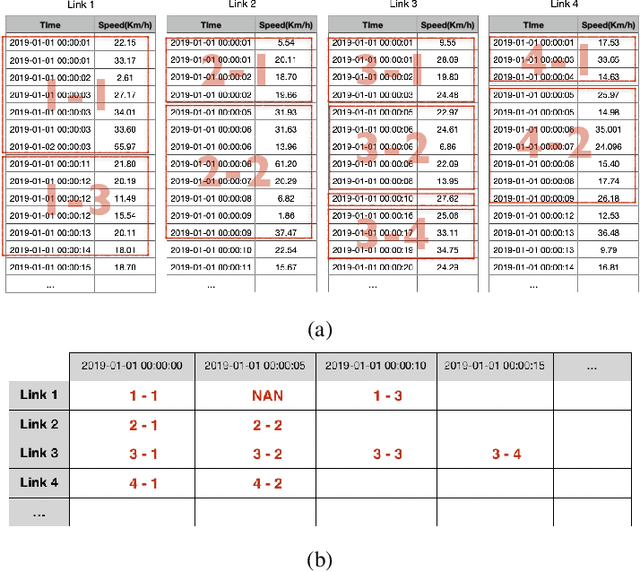
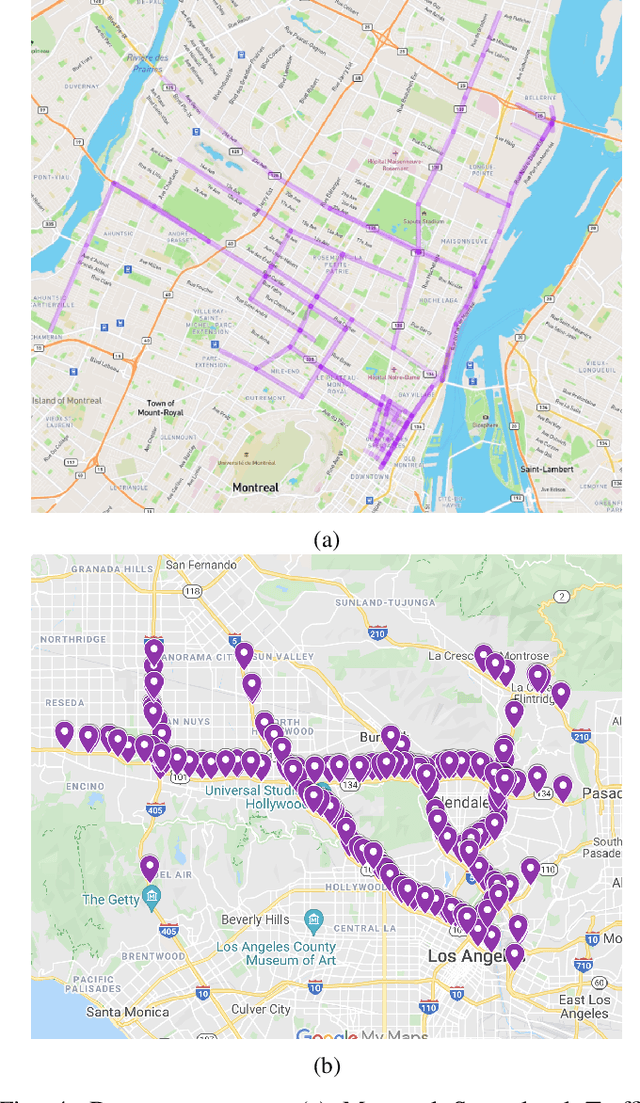
In recent years, graph neural networks (GNNs) combined with variants of recurrent neural networks (RNNs) have reached state-of-the-art performance in spatiotemporal forecasting tasks. This is particularly the case for traffic forecasting, where GNN models use the graph structure of road networks to account for spatial correlation between links and nodes. Recent solutions are either based on complex graph operations or avoiding predefined graphs. This paper proposes a new sequence-to-sequence architecture to extract the spatiotemporal correlation at multiple levels of abstraction using GNN-RNN cells with sparse architecture to decrease training time compared to more complex designs. Encoding the same input sequence through multiple encoders, with an incremental increase in encoder layers, enables the network to learn general and detailed information through multilevel abstraction. We further present a new benchmark dataset of street-level segment traffic data from Montreal, Canada. Unlike highways, urban road segments are cyclic and characterized by complicated spatial dependencies. Experimental results on the METR-LA benchmark highway and our MSLTD street-level segment datasets demonstrate that our model improves performance by more than 7% for one-hour prediction compared to the baseline methods while reducing computing resource requirements by more than half compared to other competing methods.