 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Approach for Thyroid Nodule Analysis Using Thermographic Images
May 28, 2026Thyroid cancer is said to be the second most common type of cancer in female individuals and the third in males by 2030, according to projections. In general, detecting cancer in its early stages improves the chance of survival of the individual. Thermography is a diagnostic tool that has been increasingly used to detect cancer and abnormalities, including that of thyroid. Various methods to segment and detect hot regions in thermograms and, consequently, to detect suspicious tissues present in these images have been proposed. It is well known that medical diagnosis yields a great deal of information. Thus, physicians have to comprehensively analyse and evaluate this information in a short period of time, which is infeasible in most cases. In this work, we perform a general review of thermography , focusing on the thyroid analysis. We propose protocols for image acquisiton and an autonomous registration for thyroid images. We also perform analyses of the image data, which include feature extraction, image processing, and a possible approach for classification of healthy or unhealthy patients. In summary, this work presents a pilot project for detection of tumors in our university hospital, which is part of an effort to support preventive medical actions in our endocrinology department. Under some future adjustments, this project will be submitted for approval by the ethics and research committee of Hospital Universitário Antonio Pedro at Universidade Federal Fluminense (HUAP-UFF) and to the Brazilian Ministry of Health Ethical committee under the name: Evaluation of the importance of thermography to aid diagnosis of thyroid nodules of patients in HUAP-UFF (in Portuguese: Avaliação da importância da termografia no auxílio à investigação diagnóstica de nódulos tireoidianos em pacientes acompanhados no HUAP-UFF).
Towards the automated segmentation of epicardial and mediastinal fats: A multi-manufacturer approach using intersubject registration and random forest
May 28, 2026The amount of fat on the surroundings of the heart is correlated to several health risk factors such as carotid stiffness, coronary artery calcification, atrial fibrillation, atherosclerosis, cancer incidence and others. Furthermore, the cardiac fat varies unrelated to the overall fat of the subject, and, therefore, it reinforces the quantitative analysis of these adipose tissues as being essential. Clinical decision support systems are computer programs capable of evaluating information and providing a corresponding diagnosis or data to complement the physicists' analyses. The aim of this work is to propose a method capable of fully automatically segmenting two types of cardiac adipose tissues that stand apart from each other by the pericardium on CT images obtained by the standard acquisition protocol used for coronary calcium scoring. Much effort was devoted to promote minimal user intervention and ease of reproducibility. The methodology proposed in this work consists of a registration, which will roughly adjust input images to a standard, an extraction of features related to pixels and their surrounding area and a segmentation step based on data mining classification algorithms that define if an incoming pixel is of a certain type. Experimentations showed that the achieved mean accuracy for the epicardial and mediastinal fats was 98.4% with a mean true positive rate of 96.2%. In average, the Dice similarity index was equal to 96.8%.
Proposal and study of statistical features for string similarity computation and classification
May 14, 2026Adaptations of features commonly applied in the field of visual computing, co-occurrence matrix (COM) and run-length matrix (RLM), are proposed for the similarity computation of strings in general (words, phrases, codes and texts). The proposed features are not sensitive to language related information. These are purely statistical and can be used in any context with any language or grammatical structure. Other statistical measures that are commonly employed in the field such as longest common subsequence, maximal consecutive longest common subsequence, mutual information and edit distances are evaluated and compared. In the first synthetic set of experiments, the COM and RLM features outperform the remaining state-of-the-art statistical features. In 3 out of 4 cases, the RLM and COM features were statistically more significant than the second best group based on distances (P-value < 0.001). When it comes to a real text plagiarism dataset, the RLM features obtained the best results.
Comparing Results of Thermographic Images Based Diagnosis for Breast Diseases
Aug 30, 2022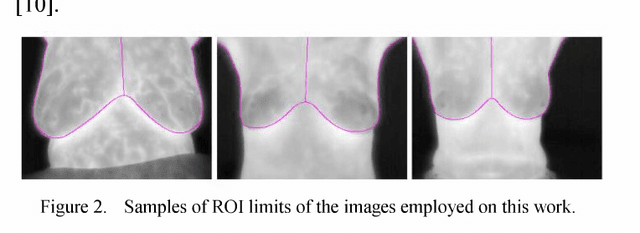
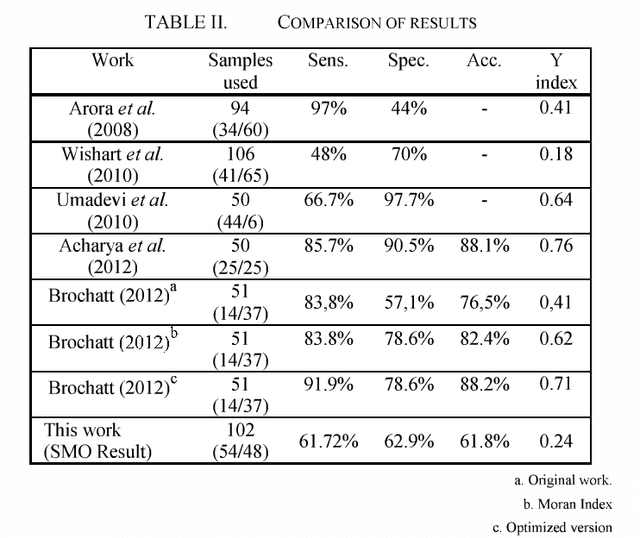
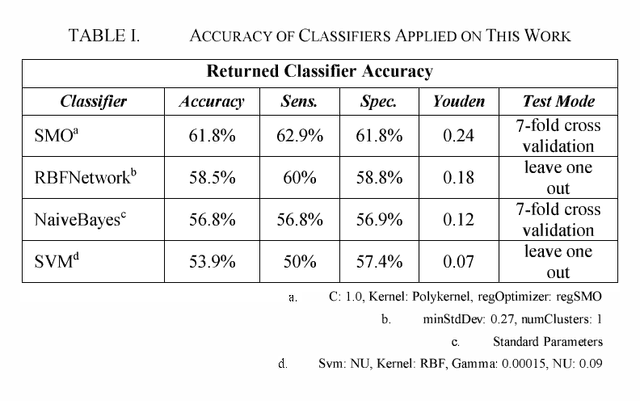
This paper examines the potential contribution of infrared (IR) imaging in breast diseases detection. It compares obtained results using some algorithms for detection of malignant breast conditions such as Support Vector Machine (SVM) regarding the consistency of different approaches when applied to public data. Moreover, in order to avail the actual IR imaging's capability as a complement on clinical trials and to promote researches using high-resolution IR imaging we deemed the use of a public database revised by confidently trained breast physicians as essential. Only the static acquisition protocol is regarded in our work. We used lO2 IR single breast images from the Pro Engenharia (PROENG) public database (54 normal and 48 with some finding). These images were collected from Universidade Federal de Pernambuco (UFPE) University's Hospital. We employed the same features proposed by the authors of the work that presented the best results and achieved an accuracy of 61.7 % and Youden index of 0.24 using the Sequential Minimal Optimization (SMO) classifier.
k-MS: A novel clustering algorithm based on morphological reconstruction
Aug 30, 2022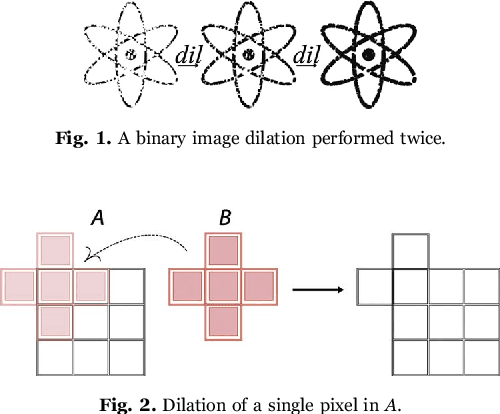
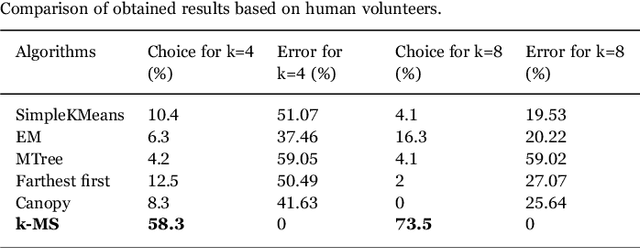
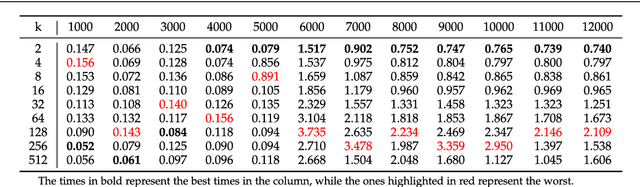

This work proposes a clusterization algorithm called k-Morphological Sets (k-MS), based on morphological reconstruction and heuristics. k-MS is faster than the CPU-parallel k-Means in worst case scenarios and produces enhanced visualizations of the dataset as well as very distinct clusterizations. It is also faster than similar clusterization methods that are sensitive to density and shapes such as Mitosis and TRICLUST. In addition, k-MS is deterministic and has an intrinsic sense of maximal clusters that can be created for a given input sample and input parameters, differing from k-Means and other clusterization algorithms. In other words, given a constant k, a structuring element and a dataset, k-MS produces k or less clusters without using random/ pseudo-random functions. Finally, the proposed algorithm also provides a straightforward means for removing noise from images or datasets in general.
Automated recognition of the pericardium contour on processed CT images using genetic algorithms
Aug 30, 2022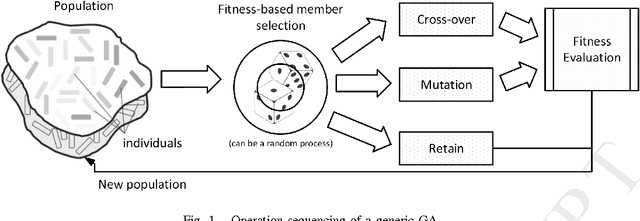

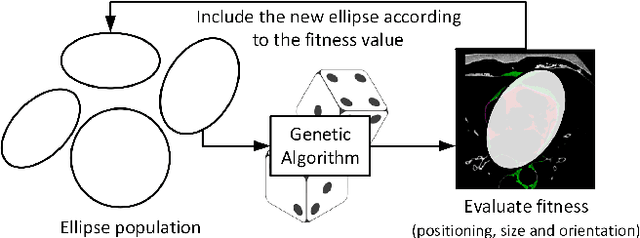

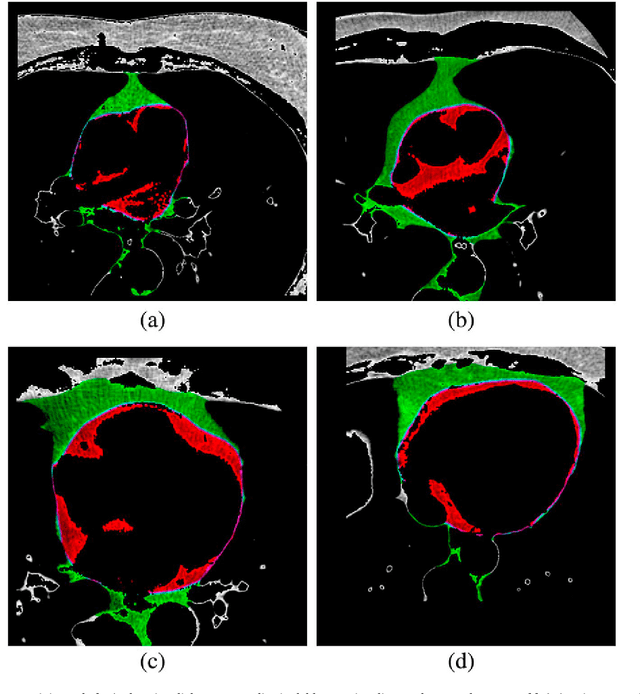
This work proposes the use of Genetic Algorithms (GA) in tracing and recognizing the pericardium contour of the human heart using Computed Tomography (CT) images. We assume that each slice of the pericardium can be modelled by an ellipse, the parameters of which need to be optimally determined. An optimal ellipse would be one that closely follows the pericardium contour and, consequently, separates appropriately the epicardial and mediastinal fats of the human heart. Tracing and automatically identifying the pericardium contour aids in medical diagnosis. Usually, this process is done manually or not done at all due to the effort required. Besides, detecting the pericardium may improve previously proposed automated methodologies that separate the two types of fat associated to the human heart. Quantification of these fats provides important health risk marker information, as they are associated with the development of certain cardiovascular pathologies. Finally, we conclude that GA offers satisfiable solutions in a feasible amount of processing time.
Machine learning in the prediction of cardiac epicardial and mediastinal fat volumes
Aug 30, 2022
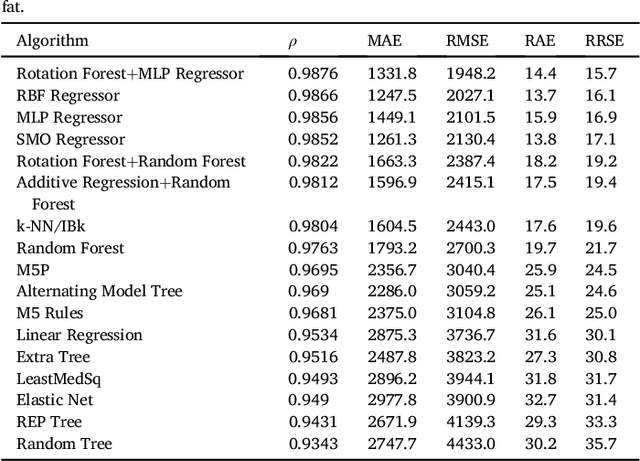
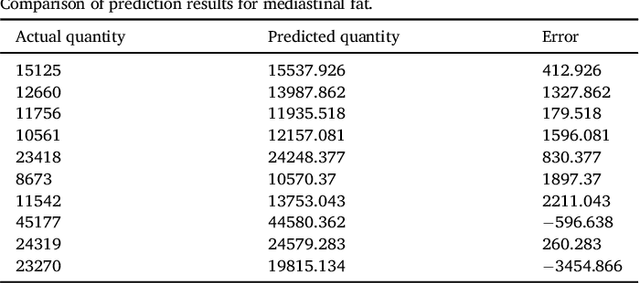
We propose a methodology to predict the cardiac epicardial and mediastinal fat volumes in computed tomography images using regression algorithms. The obtained results indicate that it is feasible to predict these fats with a high degree of correlation, thus alleviating the requirement for manual or automatic segmentation of both fat volumes. Instead, segmenting just one of them suffices, while the volume of the other may be predicted fairly precisely. The correlation coefficient obtained by the Rotation Forest algorithm using MLP Regressor for predicting the mediastinal fat based on the epicardial fat was 0.9876, with a relative absolute error of 14.4% and a root relative squared error of 15.7%. The best correlation coefficient obtained in the prediction of the epicardial fat based on the mediastinal was 0.9683 with a relative absolute error of 19.6% and a relative squared error of 24.9%. Moreover, we analysed the feasibility of using linear regressors, which provide an intuitive interpretation of the underlying approximations. In this case, the obtained correlation coefficient was 0.9534 for predicting the mediastinal fat based on the epicardial, with a relative absolute error of 31.6% and a root relative squared error of 30.1%. On the prediction of the epicardial fat based on the mediastinal fat, the correlation coefficient was 0.8531, with a relative absolute error of 50.43% and a root relative squared error of 52.06%. In summary, it is possible to speed up general medical analyses and some segmentation and quantification methods that are currently employed in the state-of-the-art by using this prediction approach, which consequently reduces costs and therefore enables preventive treatments that may lead to a reduction of health problems.
Morphological classifiers
Dec 21, 2021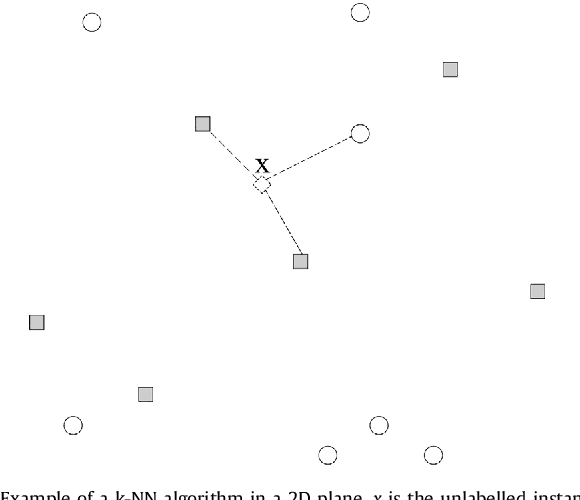

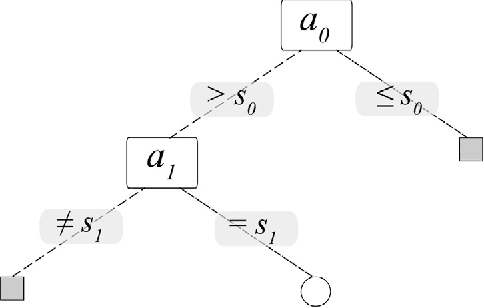
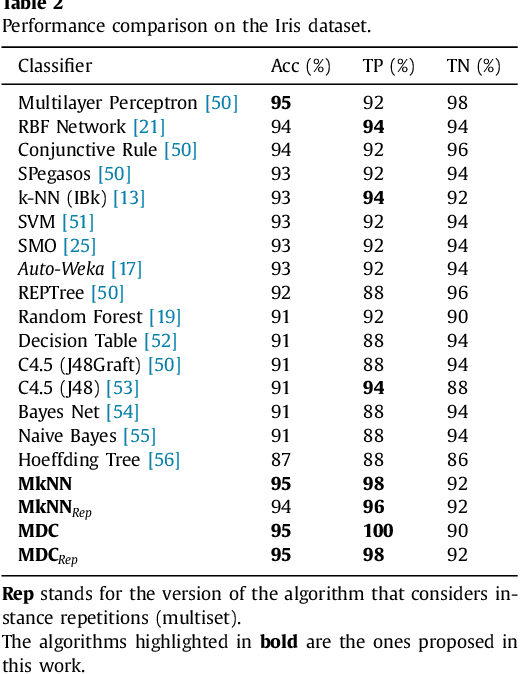
This work proposes a new type of classifier called Morphological Classifier (MC). MCs aggregate concepts from mathematical morphology and supervised learning. The outcomes of this aggregation are classifiers that may preserve shape characteristics of classes, subject to the choice of a stopping criterion and structuring element. MCs are fundamentally based on set theory, and their classification model can be a mathematical set itself. Two types of morphological classifiers are proposed in the current work, namely, Morphological k-NN (MkNN) and Morphological Dilation Classifier (MDC), which demonstrate the feasibility of the approach. This work provides evidence regarding the advantages of MCs, e.g., very fast classification times as well as competitive accuracy rates. The performance of MkNN and MDC was tested using p -dimensional datasets. MCs tied or outperformed 14 well established classifiers in 5 out of 8 datasets. In all occasions, the obtained accuracies were higher than the average accuracy obtained with all classifiers. Moreover, the proposed implementations utilize the power of the Graphics Processing Units (GPUs) to speed up processing.