 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Generalizable Adaptation of 3D Vision-Language Models via Regularized Fine-Tuning
Jun 16, 2026Domain adaptation remains a central challenge in 3D vision, especially for multimodal foundation models that align 3D point clouds with visual and textual data. While these models demonstrate strong general capabilities, adapting them to downstream domains with limited data often leads to overfitting and catastrophic forgetting. To address this, we introduce ReFine3D, a regularized fine-tuning framework designed for domain-generalizable tuning of 3D large multimodal models (LMMs). ReFine3D combines selective layer tuning with two targeted regularization strategies: multi-view consistency across augmented point clouds and text diversity through synonym-based prompts generated by large language models. Additionally, we incorporate point-rendered vision supervision and a test-time augmentation mechanism with confidence-based aggregation to further enhance robustness. Extensive experiments across different 3D domain generalization benchmarks show that ReFine3D improves base-to-novel class generalization by 1.36%, cross-dataset transfer by 2.43%, robustness to corruption by 1.80%, and few-shot accuracy by up to 3.11%, outperforming prior state-of-the-art methods with minimal added computational overhead.
An Adapter-free Fine-tuning Approach for Tuning 3D Foundation Models
Mar 24, 2026Point cloud foundation models demonstrate strong generalization, yet adapting them to downstream tasks remains challenging in low-data regimes. Full fine-tuning often leads to overfitting and significant drift from pre-trained representations, while existing parameter-efficient fine-tuning (PEFT) methods mitigate this issue by introducing additional trainable components at the cost of increased inference-time latency. We propose Momentum-Consistency Fine-Tuning (MCFT), an adapter-free approach that bridges the gap between full and parameter-efficient fine-tuning. MCFT selectively fine-tunes a portion of the pre-trained encoder while enforcing a momentum-based consistency constraint to preserve task-agnostic representations. Unlike PEFT methods, MCFT introduces no additional representation learning parameters beyond a standard task head, maintaining the original model's parameter count and inference efficiency. We further extend MCFT with two variants: a semi-supervised framework that leverages abundant unlabeled data to enhance few-shot performance, and a pruning-based variant that improves computational efficiency through structured layer removal. Extensive experiments on object recognition and part segmentation benchmarks demonstrate that MCFT consistently outperforms prior methods, achieving a 3.30% gain in 5-shot settings and up to a 6.13% improvement with semi-supervised learning, while remaining well-suited for resource-constrained deployment.
Point Cloud as a Foreign Language for Multi-modal Large Language Model
Mar 10, 2026Multi-modal large language models (MLLMs) have shown remarkable progress in integrating visual and linguistic understanding. Recent efforts have extended these capabilities to 3D understanding through encoder-based architectures that rely on pre-trained 3D encoders to extract geometric features. However, such approaches suffer from semantic misalignment between geometric and linguistic spaces, resolution sensitivity, and substantial computational overhead. In this work, we present SAGE, the first end-to-end 3D MLLM that directly processes raw point clouds without relying on a pre-trained 3D encoder. Our approach introduces a lightweight 3D tokenizer that combines geometric sampling and neighbourhood aggregation with vector quantization to convert point clouds into discrete tokens--treating 3D data as a foreign language that naturally extends the LLM's vocabulary. Furthermore, to enhance the model's reasoning capability on complex 3D tasks, we propose a preference optimization training strategy with a semantic alignment-based reward, specifically designed for open-ended 3D question answering where responses are descriptive. Extensive experiments across diverse 3D understanding benchmarks demonstrate that our end-to-end approach outperforms existing encoder-based methods while offering significant advantages in computational efficiency, generalization across LLM backbones, and robustness to input resolution variations. Code is available at: github.com/snehaputul/SAGE3D.
Enhancing Diversity and Feasibility: Joint Population Synthesis from Multi-source Data Using Generative Models
Feb 17, 2026Generating realistic synthetic populations is essential for agent-based models (ABM) in transportation and urban planning. Current methods face two major limitations. First, many rely on a single dataset or follow a sequential data fusion and generation process, which means they fail to capture the complex interplay between features. Second, these approaches struggle with sampling zeros (valid but unobserved attribute combinations) and structural zeros (infeasible combinations due to logical constraints), which reduce the diversity and feasibility of the generated data. This study proposes a novel method to simultaneously integrate and synthesize multi-source datasets using a Wasserstein Generative Adversarial Network (WGAN) with gradient penalty. This joint learning method improves both the diversity and feasibility of synthetic data by defining a regularization term (inverse gradient penalty) for the generator loss function. For the evaluation, we implement a unified evaluation metric for similarity, and place special emphasis on measuring diversity and feasibility through recall, precision, and the F1 score. Results show that the proposed joint approach outperforms the sequential baseline, with recall increasing by 7\% and precision by 15\%. Additionally, the regularization term further improves diversity and feasibility, reflected in a 10\% increase in recall and 1\% in precision. We assess similarity distributions using a five-metric score. The joint approach performs better overall, and reaches a score of 88.1 compared to 84.6 for the sequential method. Since synthetic populations serve as a key input for ABM, this multi-source generative approach has the potential to significantly enhance the accuracy and reliability of ABM.
Improving 3D Semi-supervised Learning by Effectively Utilizing All Unlabelled Data
Sep 21, 2024Semi-supervised learning (SSL) has shown its effectiveness in learning effective 3D representation from a small amount of labelled data while utilizing large unlabelled data. Traditional semi-supervised approaches rely on the fundamental concept of predicting pseudo-labels for unlabelled data and incorporating them into the learning process. However, we identify that the existing methods do not fully utilize all the unlabelled samples and consequently limit their potential performance. To address this issue, we propose AllMatch, a novel SSL-based 3D classification framework that effectively utilizes all the unlabelled samples. AllMatch comprises three modules: (1) an adaptive hard augmentation module that applies relatively hard augmentations to the high-confident unlabelled samples with lower loss values, thereby enhancing the contribution of such samples, (2) an inverse learning module that further improves the utilization of unlabelled data by learning what not to learn, and (3) a contrastive learning module that ensures learning from all the samples in both supervised and unsupervised settings. Comprehensive experiments on two popular 3D datasets demonstrate a performance improvement of up to 11.2% with 1% labelled data, surpassing the SOTA by a significant margin. Furthermore, AllMatch exhibits its efficiency in effectively leveraging all the unlabelled data, demonstrated by the fact that only 10% of labelled data reaches nearly the same performance as fully-supervised learning with all labelled data. The code of our work is available at: https://github.com/snehaputul/AllMatch.
TransGlow: Attention-augmented Transduction model based on Graph Neural Networks for Water Flow Forecasting
Dec 10, 2023



The hydrometric prediction of water quantity is useful for a variety of applications, including water management, flood forecasting, and flood control. However, the task is difficult due to the dynamic nature and limited data of water systems. Highly interconnected water systems can significantly affect hydrometric forecasting. Consequently, it is crucial to develop models that represent the relationships between other system components. In recent years, numerous hydrological applications have been studied, including streamflow prediction, flood forecasting, and water quality prediction. Existing methods are unable to model the influence of adjacent regions between pairs of variables. In this paper, we propose a spatiotemporal forecasting model that augments the hidden state in Graph Convolution Recurrent Neural Network (GCRN) encoder-decoder using an efficient version of the attention mechanism. The attention layer allows the decoder to access different parts of the input sequence selectively. Since water systems are interconnected and the connectivity information between the stations is implicit, the proposed model leverages a graph learning module to extract a sparse graph adjacency matrix adaptively based on the data. Spatiotemporal forecasting relies on historical data. In some regions, however, historical data may be limited or incomplete, making it difficult to accurately predict future water conditions. Further, we present a new benchmark dataset of water flow from a network of Canadian stations on rivers, streams, and lakes. Experimental results demonstrate that our proposed model TransGlow significantly outperforms baseline methods by a wide margin.
Simpler is better: Multilevel Abstraction with Graph Convolutional Recurrent Neural Network Cells for Traffic Prediction
Sep 08, 2022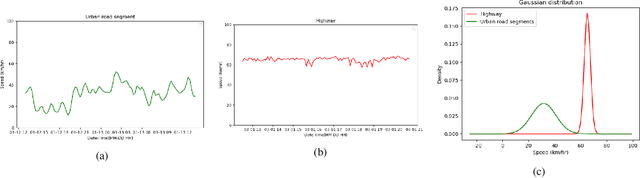
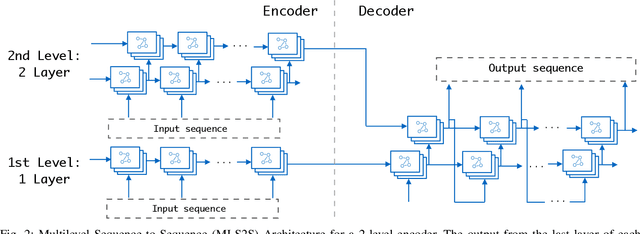
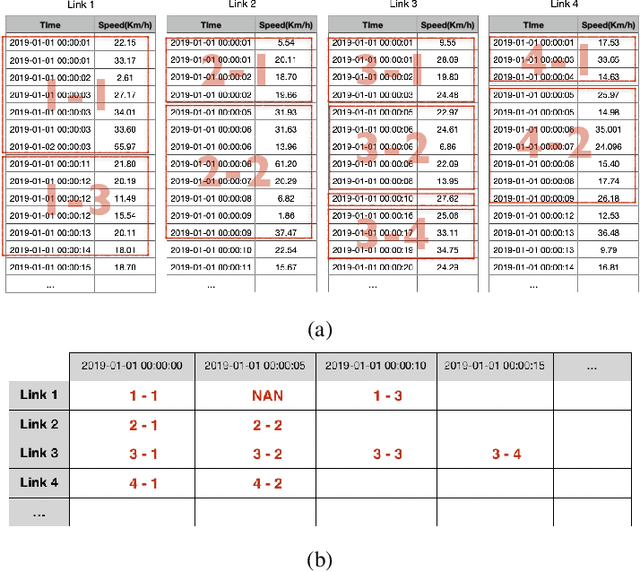
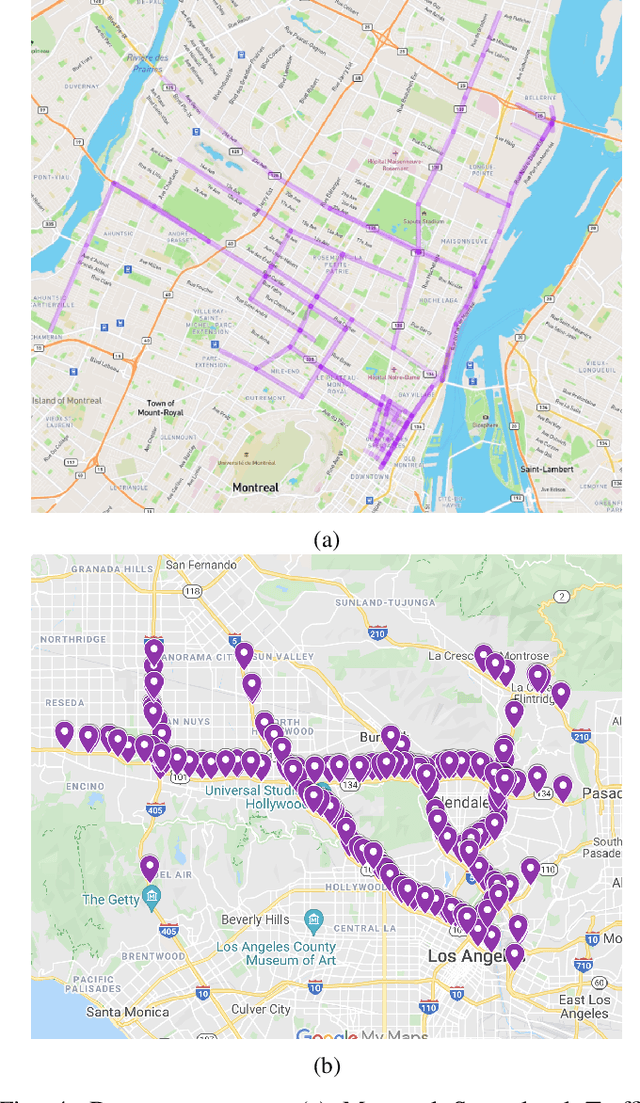
In recent years, graph neural networks (GNNs) combined with variants of recurrent neural networks (RNNs) have reached state-of-the-art performance in spatiotemporal forecasting tasks. This is particularly the case for traffic forecasting, where GNN models use the graph structure of road networks to account for spatial correlation between links and nodes. Recent solutions are either based on complex graph operations or avoiding predefined graphs. This paper proposes a new sequence-to-sequence architecture to extract the spatiotemporal correlation at multiple levels of abstraction using GNN-RNN cells with sparse architecture to decrease training time compared to more complex designs. Encoding the same input sequence through multiple encoders, with an incremental increase in encoder layers, enables the network to learn general and detailed information through multilevel abstraction. We further present a new benchmark dataset of street-level segment traffic data from Montreal, Canada. Unlike highways, urban road segments are cyclic and characterized by complicated spatial dependencies. Experimental results on the METR-LA benchmark highway and our MSLTD street-level segment datasets demonstrate that our model improves performance by more than 7% for one-hour prediction compared to the baseline methods while reducing computing resource requirements by more than half compared to other competing methods.
Multi-task Recurrent Neural Networks to Simultaneously Infer Mode and Purpose in GPS Trajectories
Oct 23, 2021
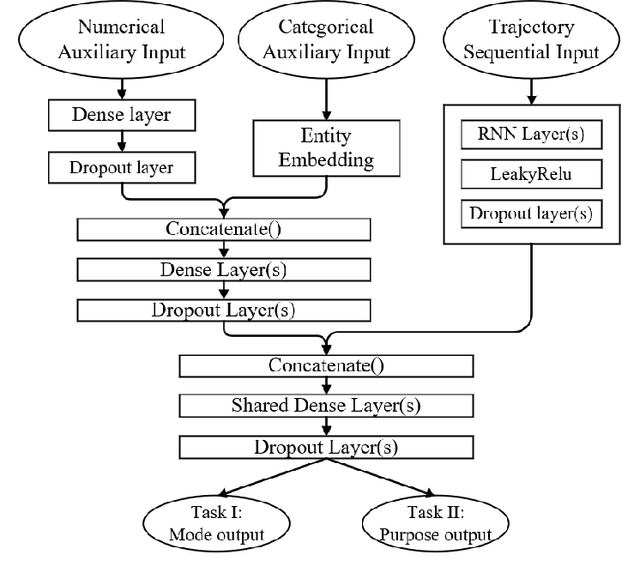
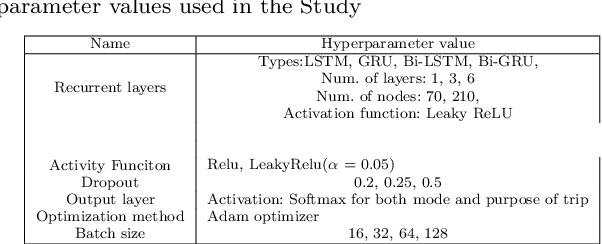
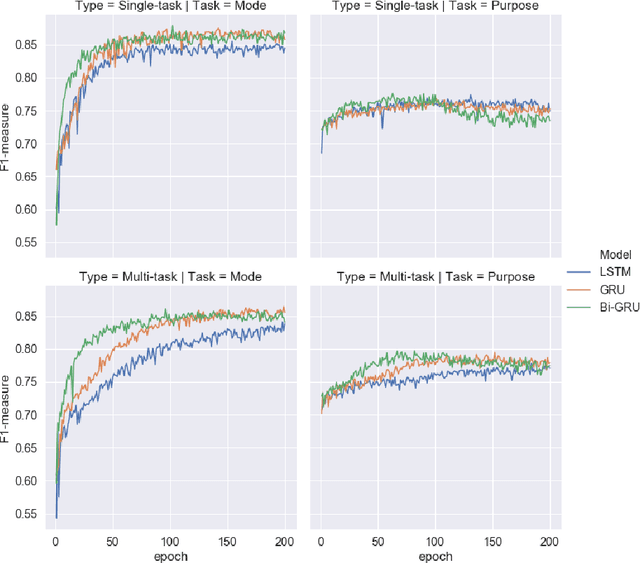
Multi-task learning is assumed as a powerful inference method, specifically, where there is a considerable correlation between multiple tasks, predicting them in an unique framework may enhance prediction results. This research challenges this assumption by developing several single-task models to compare their results against multi-task learners to infer mode and purpose of trip from smartphone travel survey data collected as part of a smartphone-based travel survey. GPS trajectory data along with socio-demographics and destination-related characteristics are fed into a multi-input neural network framework to predict two outputs; mode and purpose. We deployed Recurrent Neural Networks (RNN) that are fed by sequential GPS trajectories. To process the socio-demographics and destination-related characteristics, another neural network, with different embedding and dense layers is used in parallel with RNN layers in a multi-input multi-output framework. The results are compared against the single-task learners that classify mode and purpose independently. We also investigate different RNN approaches such as Long-Short Term Memory (LSTM), Gated Recurrent Units (GRU) and Bi-directional Gated Recurrent Units (Bi-GRU). The best multi-task learner was a Bi-GRU model able to classify mode and purpose with an F1-measures of 84.33% and 78.28%, while the best single-task learner to infer mode of transport was a GRU model that achieved an F1-measure of 86.50%, and the best single-task Bi-GRU purpose detection model that reached an F1-measure of 77.38%. While there's an assumption of higher performance of multi-task over sing-task learners, the results of this study does not hold such an assumption and shows, in the context of mode and trip purpose inference from GPS trajectory data, a multi-task learning approach does not bring any considerable advantage over single-task learners.
A Differentially Private Multi-Output Deep Generative Networks Approach For Activity Diary Synthesis
Dec 29, 2020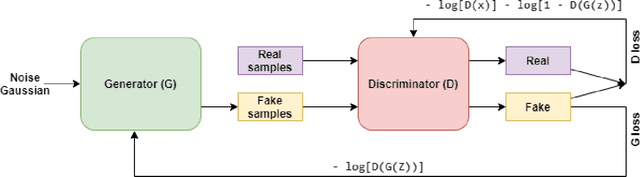

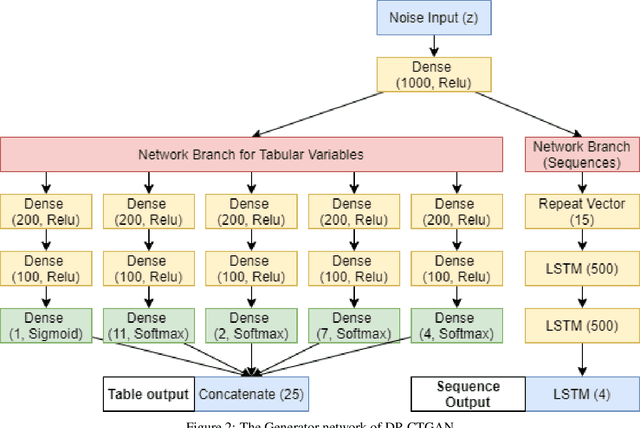
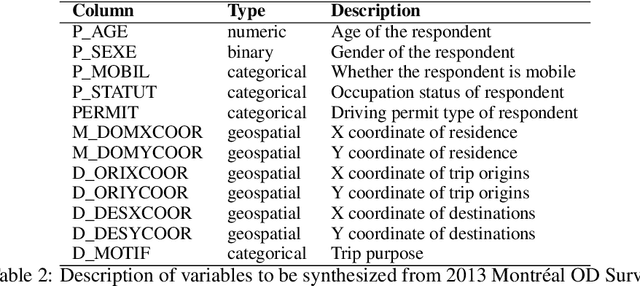
In this work, we develop a privacy-by-design generative model for synthesizing the activity diary of the travel population using state-of-art deep learning approaches. This proposed approach extends literature on population synthesis by contributing novel deep learning to the development and application of synthetic travel data while guaranteeing privacy protection for members of the sample population on which the synthetic populations are based. First, we show a complete de-generalization of activity diaries to simulate the socioeconomic features and longitudinal sequences of geographically and temporally explicit activities. Second, we introduce a differential privacy approach to control the level of resolution disclosing the uniqueness of survey participants. Finally, we experiment using the Generative Adversarial Networks (GANs). We evaluate the statistical distributions, pairwise correlations and measure the level of privacy guaranteed on simulated datasets for varying noise. The results of the model show successes in simulating activity diaries composed of multiple outputs including structured socio-economic features and sequential tour activities in a differentially private manner.
Ensemble Convolutional Neural Networks for Mode Inference in Smartphone Travel Survey
Apr 18, 2019
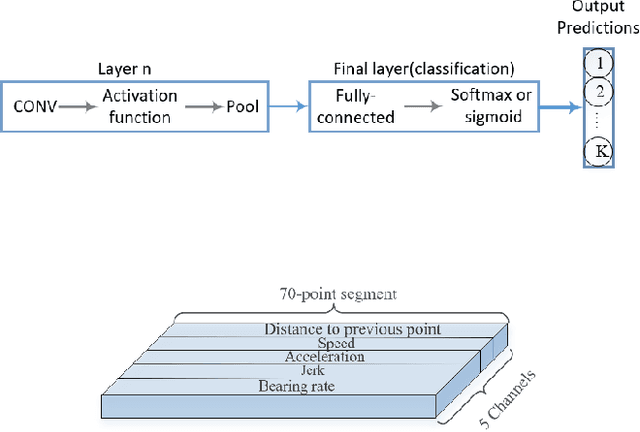
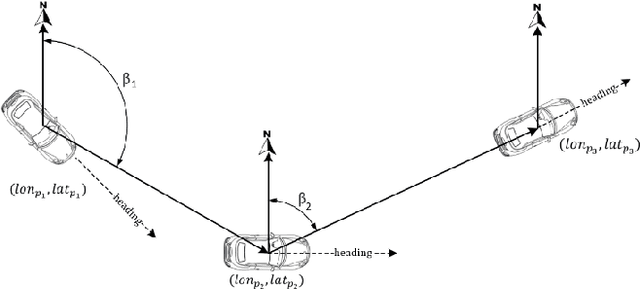
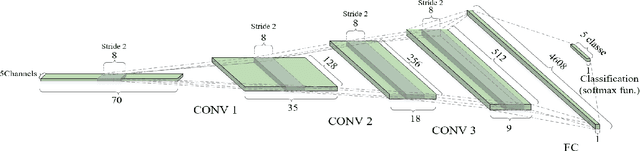
We develop ensemble Convolutional Neural Networks (CNNs) to classify the transportation mode of trip data collected as part of a large-scale smartphone travel survey in Montreal, Canada. Our proposed ensemble library is composed of a series of CNN models with different hyper-parameter values and CNN architectures. In our final model, we combine the output of CNN models using "average voting", "majority voting" and "optimal weights" methods. Furthermore, we exploit the ensemble library by deploying a Random Forest model as a meta-learner. The ensemble method with random forest as meta-learner shows an accuracy of 91.8% which surpasses the other three ensemble combination methods, as well as other comparable models reported in the literature. The "majority voting" and "optimal weights" combination methods result in prediction accuracy rates around 89%, while "average voting" is able to achieve an accuracy of only 85%.