 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Gradient-free neural topology optimization
Mar 07, 2024
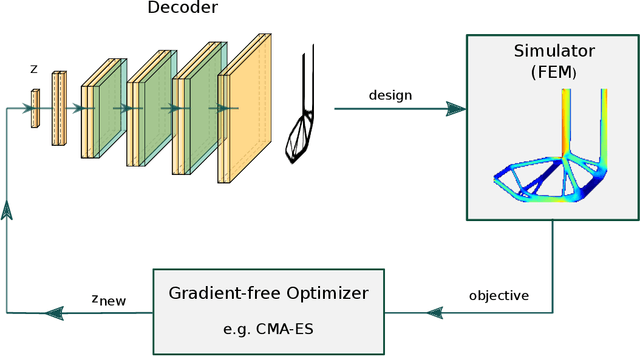
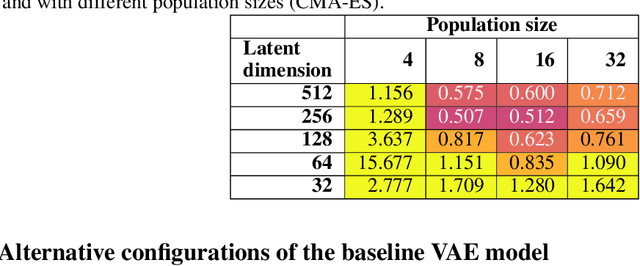
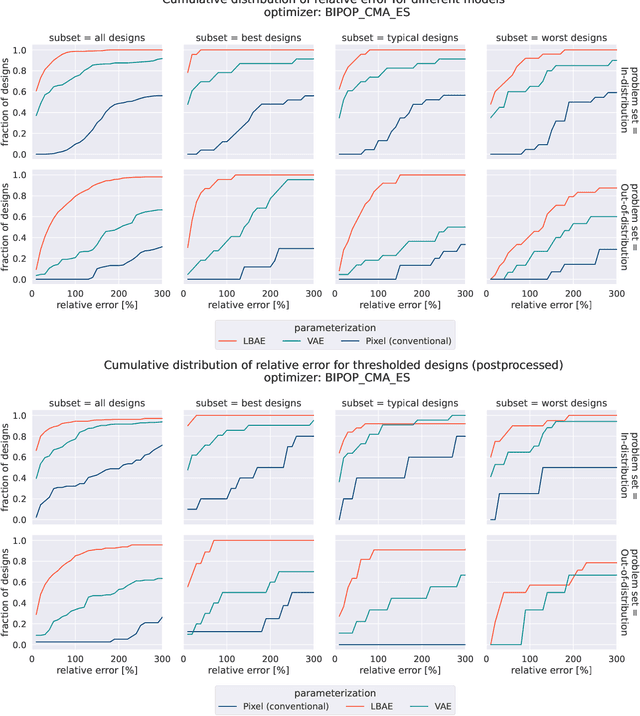
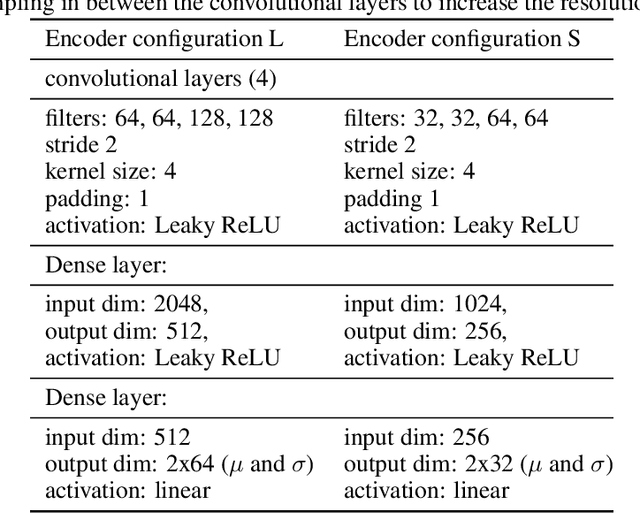
Gradient-free optimizers allow for tackling problems regardless of the smoothness or differentiability of their objective function, but they require many more iterations to converge when compared to gradient-based algorithms. This has made them unviable for topology optimization due to the high computational cost per iteration and high dimensionality of these problems. We propose a pre-trained neural reparameterization strategy that leads to at least one order of magnitude decrease in iteration count when optimizing the designs in latent space, as opposed to the conventional approach without latent reparameterization. We demonstrate this via extensive computational experiments in- and out-of-distribution with the training data. Although gradient-based topology optimization is still more efficient for differentiable problems, such as compliance optimization of structures, we believe this work will open up a new path for problems where gradient information is not readily available (e.g. fracture).
FinReport: Explainable Stock Earnings Forecasting via News Factor Analyzing Model
Mar 05, 2024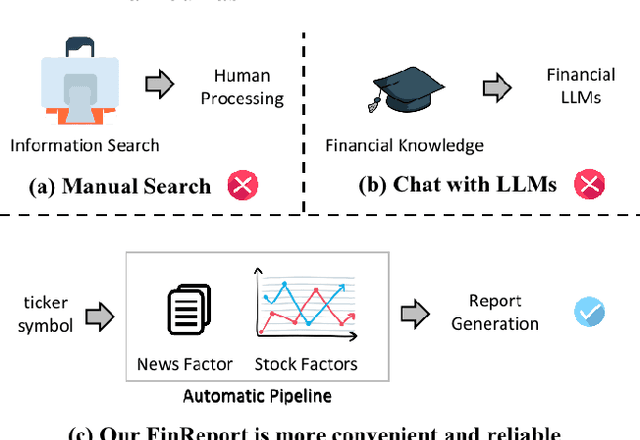
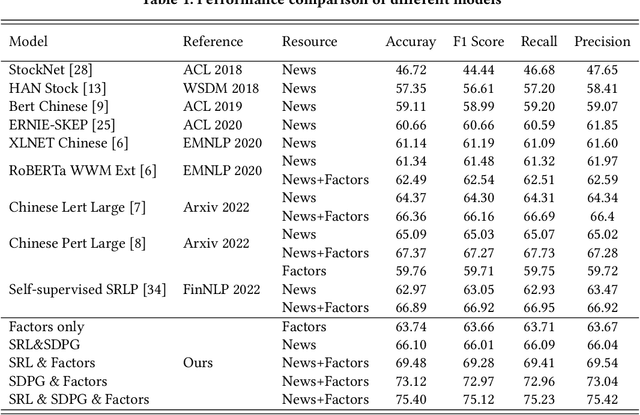
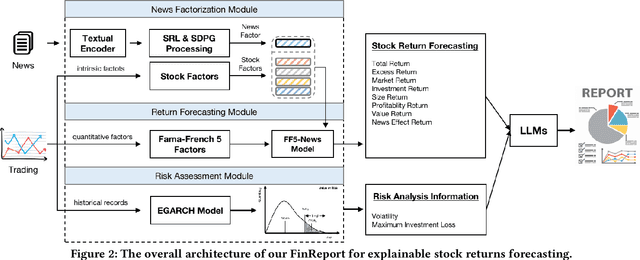
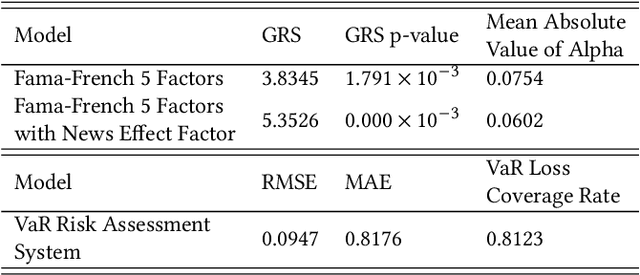
The task of stock earnings forecasting has received considerable attention due to the demand investors in real-world scenarios. However, compared with financial institutions, it is not easy for ordinary investors to mine factors and analyze news. On the other hand, although large language models in the financial field can serve users in the form of dialogue robots, it still requires users to have financial knowledge to ask reasonable questions. To serve the user experience, we aim to build an automatic system, FinReport, for ordinary investors to collect information, analyze it, and generate reports after summarizing. Specifically, our FinReport is based on financial news announcements and a multi-factor model to ensure the professionalism of the report. The FinReport consists of three modules: news factorization module, return forecasting module, risk assessment module. The news factorization module involves understanding news information and combining it with stock factors, the return forecasting module aim to analysis the impact of news on market sentiment, and the risk assessment module is adopted to control investment risk. Extensive experiments on real-world datasets have well verified the effectiveness and explainability of our proposed FinReport. Our codes and datasets are available at https://github.com/frinkleko/FinReport.
Multi-Scale Subgraph Contrastive Learning
Mar 05, 2024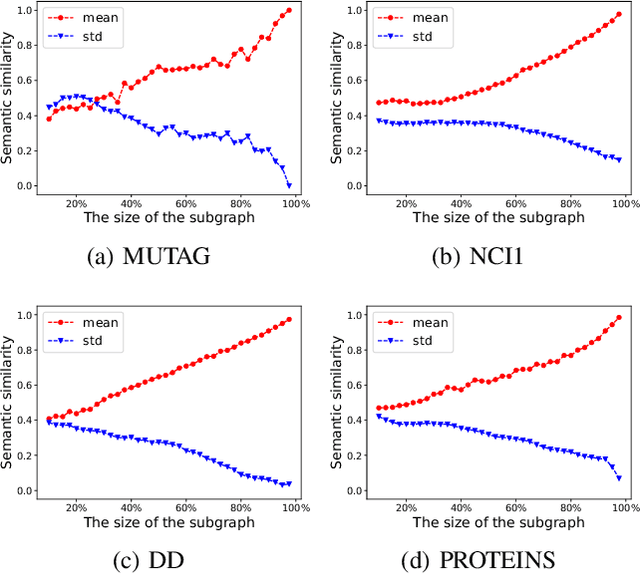
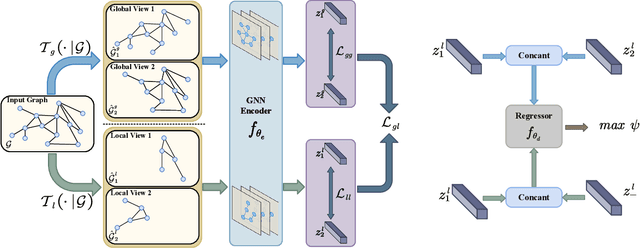
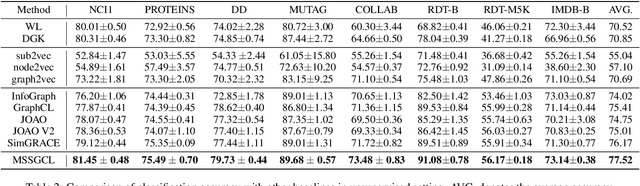
Graph-level contrastive learning, aiming to learn the representations for each graph by contrasting two augmented graphs, has attracted considerable attention. Previous studies usually simply assume that a graph and its augmented graph as a positive pair, otherwise as a negative pair. However, it is well known that graph structure is always complex and multi-scale, which gives rise to a fundamental question: after graph augmentation, will the previous assumption still hold in reality? By an experimental analysis, we discover the semantic information of an augmented graph structure may be not consistent as original graph structure, and whether two augmented graphs are positive or negative pairs is highly related with the multi-scale structures. Based on this finding, we propose a multi-scale subgraph contrastive learning method which is able to characterize the fine-grained semantic information. Specifically, we generate global and local views at different scales based on subgraph sampling, and construct multiple contrastive relationships according to their semantic associations to provide richer self-supervised signals. Extensive experiments and parametric analysis on eight graph classification real-world datasets well demonstrate the effectiveness of the proposed method.
Found in the Middle: How Language Models Use Long Contexts Better via Plug-and-Play Positional Encoding
Mar 05, 2024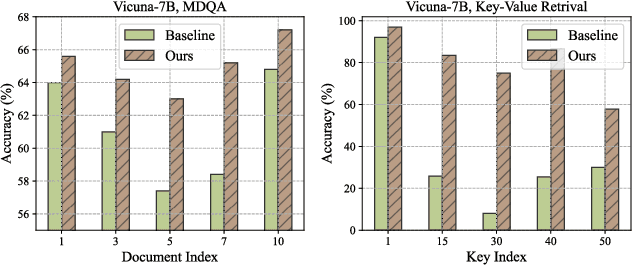
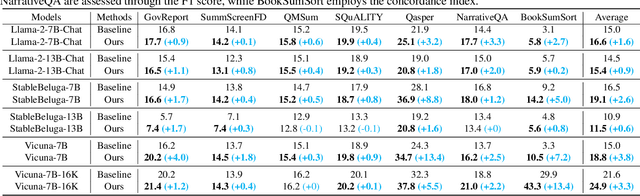
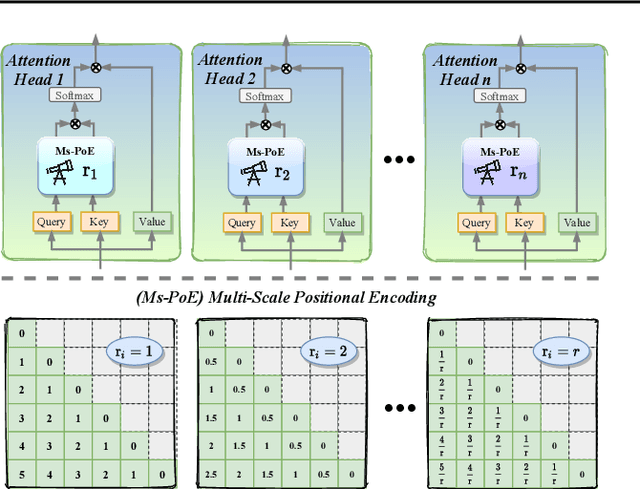
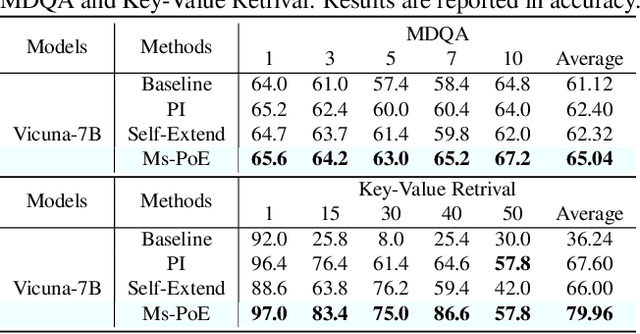
This paper aims to overcome the "lost-in-the-middle" challenge of large language models (LLMs). While recent advancements have successfully enabled LLMs to perform stable language modeling with up to 4 million tokens, the persistent difficulty faced by most LLMs in identifying relevant information situated in the middle of the context has not been adequately tackled. To address this problem, this paper introduces Multi-scale Positional Encoding (Ms-PoE) which is a simple yet effective plug-and-play approach to enhance the capacity of LLMs to handle the relevant information located in the middle of the context, without fine-tuning or introducing any additional overhead. Ms-PoE leverages the position indice rescaling to relieve the long-term decay effect introduced by RoPE, while meticulously assigning distinct scaling ratios to different attention heads to preserve essential knowledge learned during the pre-training step, forming a multi-scale context fusion from short to long distance. Extensive experiments with a wide range of LLMs demonstrate the efficacy of our approach. Notably, Ms-PoE achieves an average accuracy gain of up to 3.8 on the Zero-SCROLLS benchmark over the original LLMs. Code are available at https://github.com/VITA-Group/Ms-PoE.
Attention Guidance Mechanism for Handwritten Mathematical Expression Recognition
Mar 05, 2024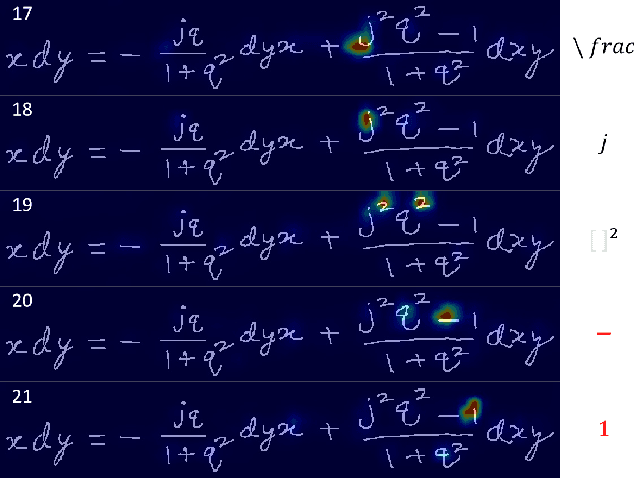
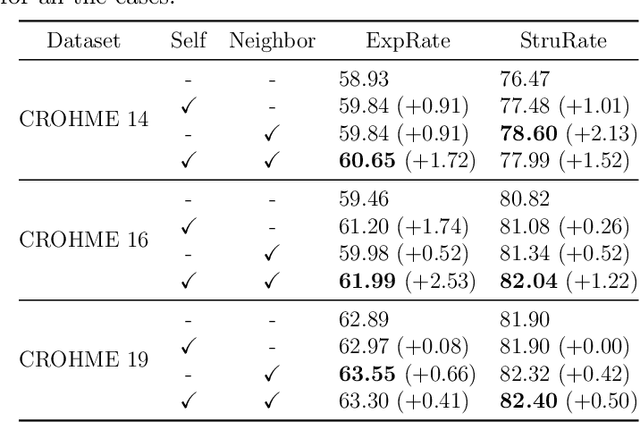
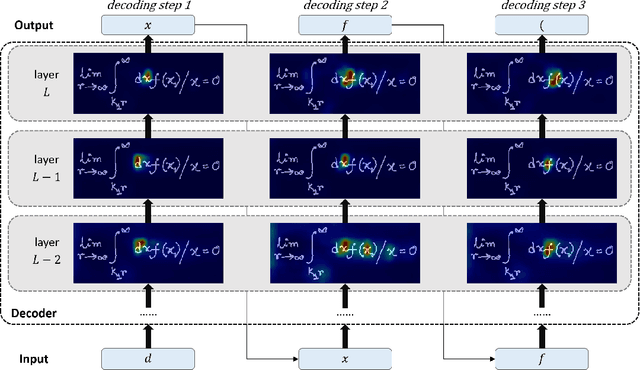
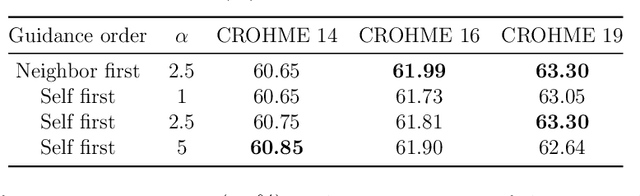
Handwritten mathematical expression recognition (HMER) is challenging in image-to-text tasks due to the complex layouts of mathematical expressions and suffers from problems including over-parsing and under-parsing. To solve these, previous HMER methods improve the attention mechanism by utilizing historical alignment information. However, this approach has limitations in addressing under-parsing since it cannot correct the erroneous attention on image areas that should be parsed at subsequent decoding steps. This faulty attention causes the attention module to incorporate future context into the current decoding step, thereby confusing the alignment process. To address this issue, we propose an attention guidance mechanism to explicitly suppress attention weights in irrelevant areas and enhance the appropriate ones, thereby inhibiting access to information outside the intended context. Depending on the type of attention guidance, we devise two complementary approaches to refine attention weights: self-guidance that coordinates attention of multiple heads and neighbor-guidance that integrates attention from adjacent time steps. Experiments show that our method outperforms existing state-of-the-art methods, achieving expression recognition rates of 60.75% / 61.81% / 63.30% on the CROHME 2014/ 2016/ 2019 datasets.
Text classification of column headers with a controlled vocabulary: leveraging LLMs for metadata enrichment
Mar 05, 2024

Traditional dataset retrieval systems index on metadata information rather than on the data values. Thus relying primarily on manual annotations and high-quality metadata, processes known to be labour-intensive and challenging to automate. We propose a method to support metadata enrichment with topic annotations of column headers using three Large Language Models (LLMs): ChatGPT-3.5, GoogleBard and GoogleGemini. We investigate the LLMs ability to classify column headers based on domain-specific topics from a controlled vocabulary. We evaluate our approach by assessing the internal consistency of the LLMs, the inter-machine alignment, and the human-machine agreement for the topic classification task. Additionally, we investigate the impact of contextual information (i.e. dataset description) on the classification outcomes. Our results suggest that ChatGPT and GoogleGemini outperform GoogleBard for internal consistency as well as LLM-human-alignment. Interestingly, we found that context had no impact on the LLMs performances. This work proposes a novel approach that leverages LLMs for text classification using a controlled topic vocabulary, which has the potential to facilitate automated metadata enrichment, thereby enhancing dataset retrieval and the Findability, Accessibility, Interoperability and Reusability (FAIR) of research data on the Web.
Self-Supervised Representation Learning with Meta Comprehensive Regularization
Mar 03, 2024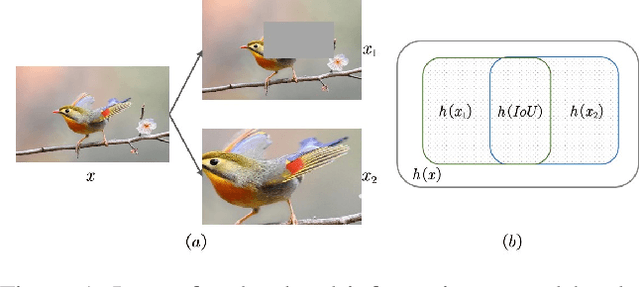
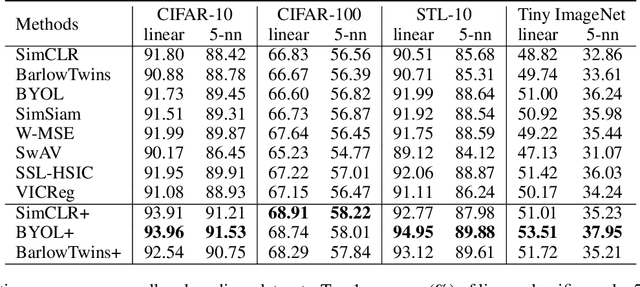
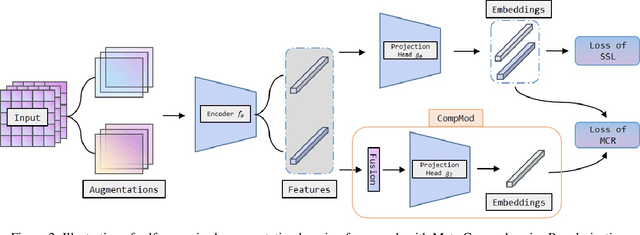
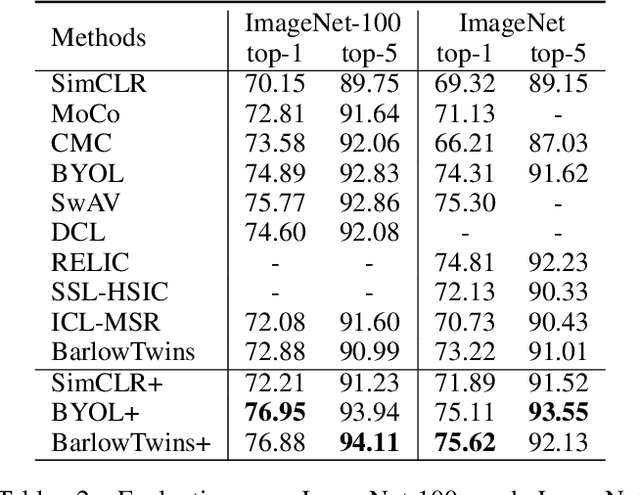
Self-Supervised Learning (SSL) methods harness the concept of semantic invariance by utilizing data augmentation strategies to produce similar representations for different deformations of the same input. Essentially, the model captures the shared information among multiple augmented views of samples, while disregarding the non-shared information that may be beneficial for downstream tasks. To address this issue, we introduce a module called CompMod with Meta Comprehensive Regularization (MCR), embedded into existing self-supervised frameworks, to make the learned representations more comprehensive. Specifically, we update our proposed model through a bi-level optimization mechanism, enabling it to capture comprehensive features. Additionally, guided by the constrained extraction of features using maximum entropy coding, the self-supervised learning model learns more comprehensive features on top of learning consistent features. In addition, we provide theoretical support for our proposed method from information theory and causal counterfactual perspective. Experimental results show that our method achieves significant improvement in classification, object detection and instance segmentation tasks on multiple benchmark datasets.
Can Large Language Models do Analytical Reasoning?
Mar 06, 2024

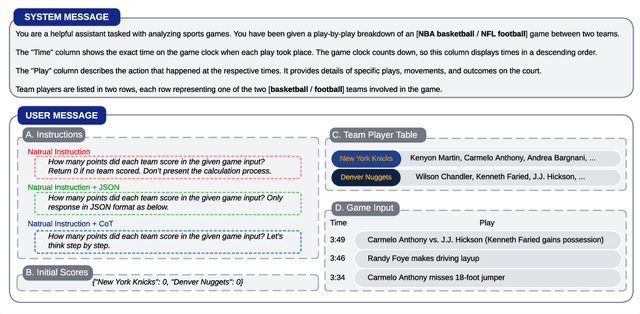
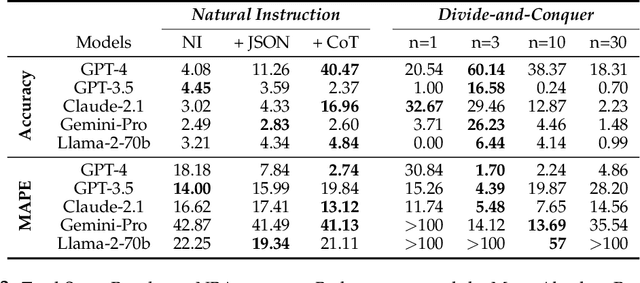
This paper explores the cutting-edge Large Language Model with analytical reasoning on sports. Our analytical reasoning embodies the tasks of letting large language models count how many points each team scores in a quarter in the NBA and NFL games. Our major discoveries are in two folds. Firstly, we find among all the models we employed, GPT-4 stands out in effectiveness, followed by Claude-2.1, with GPT-3.5, Gemini-Pro, and Llama-2-70b lagging behind. Specifically, we compare three different prompting techniques and a divide-and-conquer approach, we find that the latter was the most effective. Our divide-and-conquer approach breaks down play-by-play data into smaller, more manageable segments, solves each piece individually, and then aggregates them together. Besides the divide-and-conquer approach, we also explore the Chain of Thought (CoT) strategy, which markedly improves outcomes for certain models, notably GPT-4 and Claude-2.1, with their accuracy rates increasing significantly. However, the CoT strategy has negligible or even detrimental effects on the performance of other models like GPT-3.5 and Gemini-Pro. Secondly, to our surprise, we observe that most models, including GPT-4, struggle to accurately count the total scores for NBA quarters despite showing strong performance in counting NFL quarter scores. This leads us to further investigate the factors that impact the complexity of analytical reasoning tasks with extensive experiments, through which we conclude that task complexity depends on the length of context, the information density, and the presence of related information. Our research provides valuable insights into the complexity of analytical reasoning tasks and potential directions for developing future large language models.
LDSF: Lightweight Dual-Stream Framework for SAR Target Recognition by Coupling Local Electromagnetic Scattering Features and Global Visual Features
Mar 06, 2024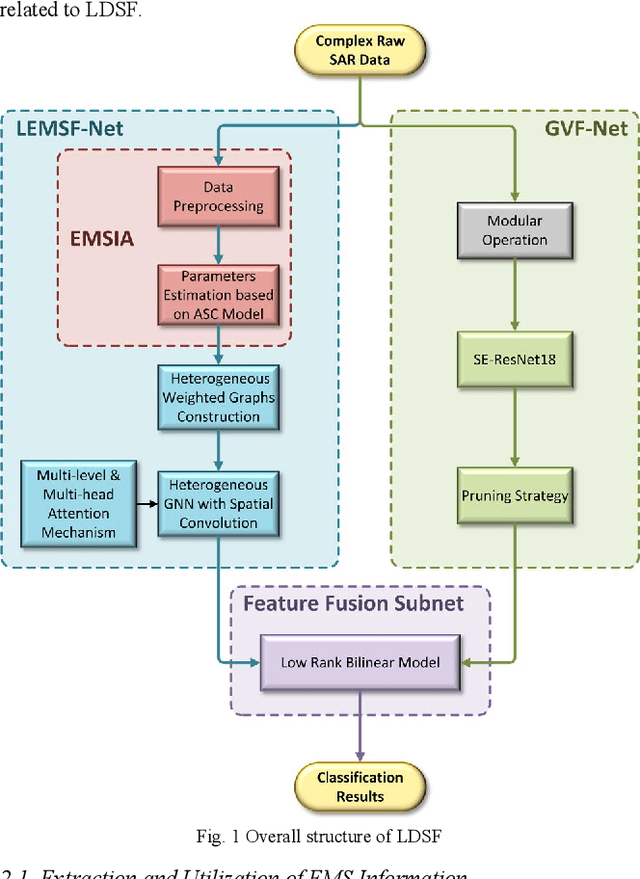

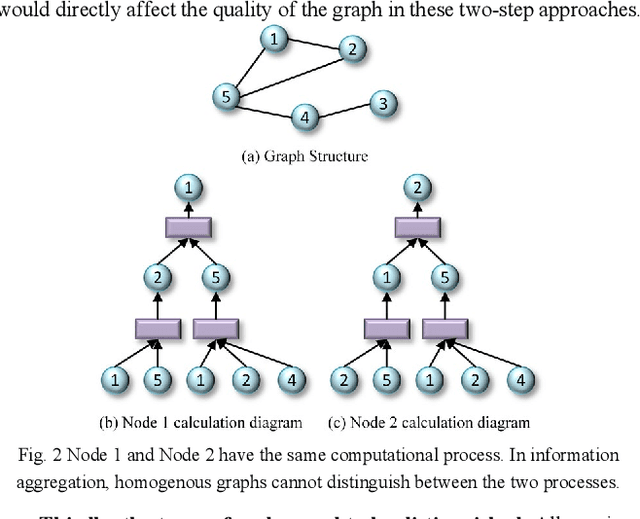
Mainstream DNN-based SAR-ATR methods still face issues such as easy overfitting of a few training data, high computational overhead, and poor interpretability of the black-box model. Integrating physical knowledge into DNNs to improve performance and achieve a higher level of physical interpretability becomes the key to solving the above problems. This paper begins by focusing on the electromagnetic (EM) backscattering mechanism. We extract the EM scattering (EMS) information from the complex SAR data and integrate the physical properties of the target into the network through a dual-stream framework to guide the network to learn physically meaningful and discriminative features. Specifically, one stream is the local EMS feature (LEMSF) extraction net. It is a heterogeneous graph neural network (GNN) guided by a multi-level multi-head attention mechanism. LEMSF uses the EMS information to obtain topological structure features and high-level physical semantic features. The other stream is a CNN-based global visual features (GVF) extraction net that captures the visual features of SAR pictures from the image domain. After obtaining the two-stream features, a feature fusion subnetwork is proposed to adaptively learn the fusion strategy. Thus, the two-stream features can maximize the performance. Furthermore, the loss function is designed based on the graph distance measure to promote intra-class aggregation. We discard overly complex design ideas and effectively control the model size while maintaining algorithm performance. Finally, to better validate the performance and generalizability of the algorithms, two more rigorous evaluation protocols, namely once-for-all (OFA) and less-for-more (LFM), are used to verify the superiority of the proposed algorithm on the MSTAR.
Diffusion-based Generative Prior for Low-Complexity MIMO Channel Estimation
Mar 06, 2024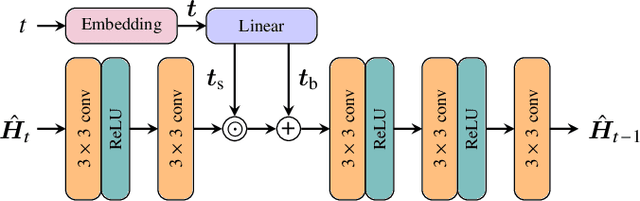
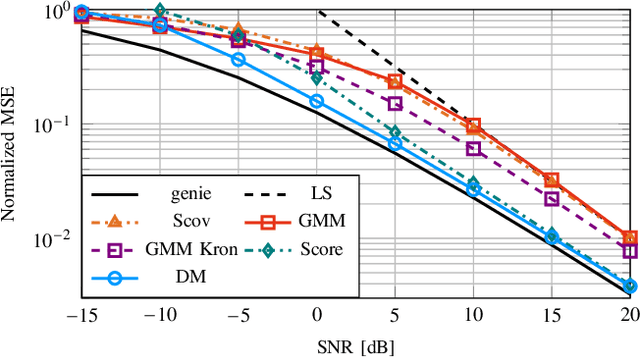
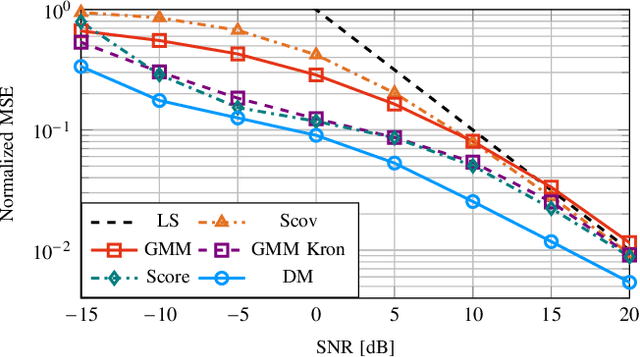
This work proposes a novel channel estimator based on diffusion models (DMs), one of the currently top-rated generative models. Contrary to related works utilizing generative priors, a lightweight convolutional neural network (CNN) with positional embedding of the signal-to-noise ratio (SNR) information is designed by learning the channel distribution in the sparse angular domain. Combined with an estimation strategy that avoids stochastic resampling and truncates reverse diffusion steps that account for lower SNR than the given pilot observation, the resulting DM estimator has both low complexity and memory overhead. Numerical results exhibit better performance than state-of-the-art channel estimators utilizing generative priors.