 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecoder Design in Multi-User FDD Systems with VQ-VAE and GNN
Oct 10, 2025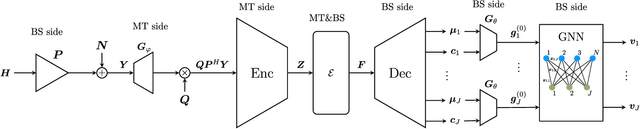
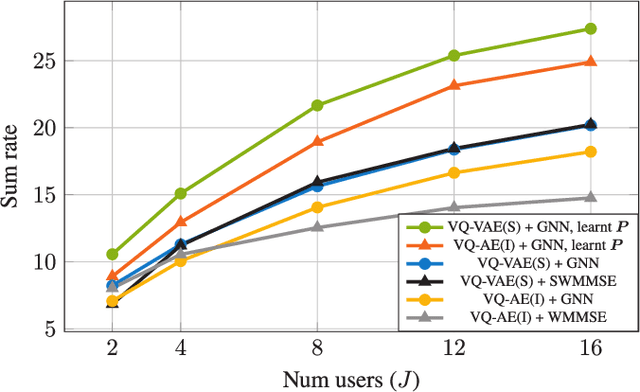
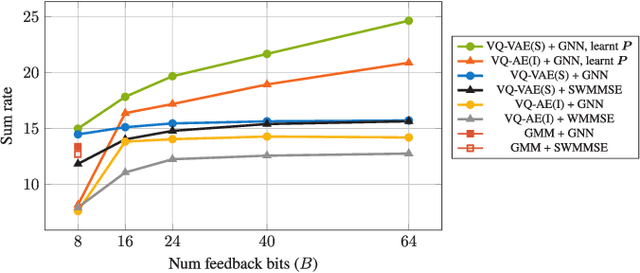
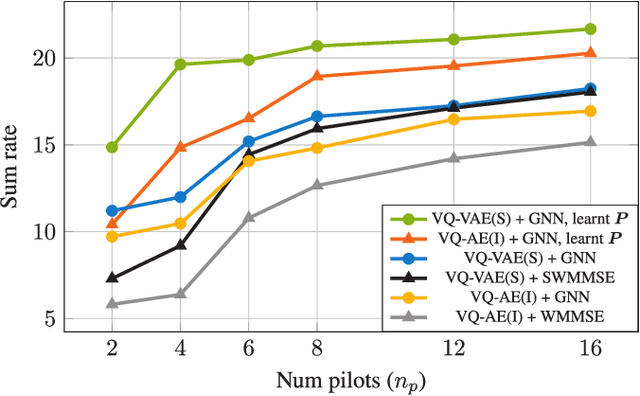
Robust precoding is efficiently feasible in frequency division duplex (FDD) systems by incorporating the learnt statistics of the propagation environment through a generative model. We build on previous work that successfully designed site-specific precoders based on a combination of Gaussian mixture models (GMMs) and graph neural networks (GNNs). In this paper, by utilizing a vector quantized-variational autoencoder (VQ-VAE), we circumvent one of the key drawbacks of GMMs, i.e., the number of GMM components scales exponentially to the feedback bits. In addition, the deep learning architecture of the VQ-VAE allows us to jointly train the GNN together with VQ-VAE along with pilot optimization forming an end-to-end (E2E) model, resulting in considerable performance gains in sum rate for multi-user wireless systems. Simulations demonstrate the superiority of the proposed frameworks over the conventional methods involving the sub-discrete Fourier transform (DFT) pilot matrix and iterative precoder algorithms enabling the deployment of systems characterized by fewer pilots or feedback bits.
Sparse Bayesian Generative Modeling for Joint Parameter and Channel Estimation
Feb 25, 2025


Leveraging the inherent connection between sensing systems and wireless communications can improve their overall performance and is the core objective of joint communications and sensing. For effective communications, one has to frequently estimate the channel. Sensing, on the other hand, infers properties of the environment mostly based on estimated physical channel parameters, such as directions of arrival or delays. This work presents a low-complexity generative modeling approach that simultaneously estimates the wireless channel and its physical parameters without additional computational overhead. To this end, we leverage a recently proposed physics-informed generative model for wireless channels based on sparse Bayesian generative modeling and exploit the feature of conditionally Gaussian generative models to approximate the conditional mean estimator.
Addressing Pilot Contamination in Channel Estimation with Variational Autoencoders
Sep 11, 2024


Pilot contamination (PC) is a well-known problem that affects massive multiple-input multiple-output (MIMO) systems. When frequency and pilots are reused between different cells, PC constitutes one of the main bottlenecks of the system's performance. In this paper, we propose a method based on the variational autoencoder (VAE), capable of reducing the impact of PC-related interference during channel estimation (CE). We obtain the first and second-order statistics of the conditionally Gaussian (CG) channels for both the user equipments (UEs) in a cell of interest and those in interfering cells, and we then use these moments to compute conditional linear minimum mean square error estimates. We show that the proposed estimator is capable of exploiting the interferers' additional statistical knowledge, outperforming other classical approaches. Moreover, we highlight how the achievable performance is tied to the chosen setup, making the setup selection crucial in the study of multi-cell CE.
Feedback Design with VQ-VAE for Robust Precoding in Multi-User FDD Systems
Aug 08, 2024



In this letter, we propose a vector quantized-variational autoencoder (VQ-VAE)-based feedback scheme for robust precoder design in multi-user frequency division duplex (FDD) systems. We demonstrate how the VQ-VAE can be tailored to specific propagation environments, focusing on systems with low pilot overhead, which is crucial in massive multiple-input multiple-output (MIMO). Extensive simulations with real-world measurement data show that our proposed feedback scheme outperforms state-of-the-art autoencoder (AE)-based compression schemes and conventional Discrete Fourier transform (DFT) codebook-based schemes. These improvements enable the deployment of systems with fewer feedback bits or pilots.
Evaluation Metrics and Methods for Generative Models in the Wireless PHY Layer
Aug 01, 2024Generative models are typically evaluated by direct inspection of their generated samples, e.g., by visual inspection in the case of images. Further evaluation metrics like the Fr\'echet inception distance or maximum mean discrepancy are intricate to interpret and lack physical motivation. These observations make evaluating generative models in the wireless PHY layer non-trivial. This work establishes a framework consisting of evaluation metrics and methods for generative models applied to the wireless PHY layer. The proposed metrics and methods are motivated by wireless applications, facilitating interpretation and understandability for the wireless community. In particular, we propose a spectral efficiency analysis for validating the generated channel norms and a codebook fingerprinting method to validate the generated channel directions. Moreover, we propose an application cross-check to evaluate the generative model's samples for training machine learning-based models in relevant downstream tasks. Our analysis is based on real-world measurement data and includes the Gaussian mixture model, variational autoencoder, diffusion model, and generative adversarial network as generative models. Our results under a fair comparison in terms of model architecture indicate that solely relying on metrics like the maximum mean discrepancy produces insufficient evaluation outcomes. In contrast, the proposed metrics and methods exhibit consistent and explainable behavior.
A Statistical Characterization of Wireless Channels Conditioned on Side Information
Jun 06, 2024Statistical prior channel knowledge, such as the wide-sense-stationary-uncorrelated-scattering (WSSUS) property, and additional side information both can be used to enhance physical layer applications in wireless communication. Generally, the wireless channel's strongly fluctuating path phases and WSSUS property characterize the channel by a zero mean and Toeplitz-structured covariance matrices in different domains. In this work, we derive a framework to comprehensively categorize side information based on whether it preserves or abandons these statistical features conditioned on the given side information. To accomplish this, we combine insights from a generic channel model with the representation of wireless channels as probabilistic graphs. Additionally, we exemplify several applications, ranging from channel modeling to estimation and clustering, which demonstrate how the proposed framework can practically enhance physical layer methods utilizing machine learning (ML).
Diffusion-based Generative Prior for Low-Complexity MIMO Channel Estimation
Mar 06, 2024



This work proposes a novel channel estimator based on diffusion models (DMs), one of the currently top-rated generative models. Contrary to related works utilizing generative priors, a lightweight convolutional neural network (CNN) with positional embedding of the signal-to-noise ratio (SNR) information is designed by learning the channel distribution in the sparse angular domain. Combined with an estimation strategy that avoids stochastic resampling and truncates reverse diffusion steps that account for lower SNR than the given pilot observation, the resulting DM estimator has both low complexity and memory overhead. Numerical results exhibit better performance than state-of-the-art channel estimators utilizing generative priors.
On the Asymptotic Mean Square Error Optimality of Diffusion Probabilistic Models
Mar 05, 2024Diffusion probabilistic models (DPMs) have recently shown great potential for denoising tasks. Despite their practical utility, there is a notable gap in their theoretical understanding. This paper contributes novel theoretical insights by rigorously proving the asymptotic convergence of a specific DPM denoising strategy to the mean square error (MSE)-optimal conditional mean estimator (CME) over a large number of diffusion steps. The studied DPM-based denoiser shares the training procedure of DPMs but distinguishes itself by forwarding only the conditional mean during the reverse inference process after training. We highlight the unique perspective that DPMs are composed of an asymptotically optimal denoiser while simultaneously inheriting a powerful generator by switching re-sampling in the reverse process on and off. The theoretical findings are validated by numerical results.
Variational Autoencoder for Channel Estimation: Real-World Measurement Insights
Dec 06, 2023This work utilizes a variational autoencoder for channel estimation and evaluates it on real-world measurements. The estimator is trained solely on noisy channel observations and parameterizes an approximation to the mean squared error-optimal estimator by learning observation-dependent conditional first and second moments. The proposed estimator significantly outperforms related state-of-the-art estimators on real-world measurements. We investigate the effect of pre-training with synthetic data and find that the proposed estimator exhibits comparable results to the related estimators if trained on synthetic data and evaluated on the measurement data. Furthermore, pre-training on synthetic data also helps to reduce the required measurement training dataset size.
Gohberg-Semencul Estimation of Toeplitz Structured Covariance Matrices and Their Inverses
Nov 25, 2023



When only few data samples are accessible, utilizing structural prior knowledge is essential for estimating covariance matrices and their inverses. One prominent example is knowing the covariance matrix to be Toeplitz structured, which occurs when dealing with wide sense stationary (WSS) processes. This work introduces a novel class of positive definiteness ensuring likelihood-based estimators for Toeplitz structured covariance matrices (CMs) and their inverses. In order to accomplish this, we derive positive definiteness enforcing constraint sets for the Gohberg-Semencul (GS) parameterization of inverse symmetric Toeplitz matrices. Motivated by the relationship between the GS parameterization and autoregressive (AR) processes, we propose hyperparameter tuning techniques, which enable our estimators to combine advantages from state-of-the-art likelihood and non-parametric estimators. Moreover, we present a computationally cheap closed-form estimator, which is derived by maximizing an approximate likelihood. Due to the ensured positive definiteness, our estimators perform well for both the estimation of the CM and the inverse covariance matrix (ICM). Extensive simulation results validate the proposed estimators' efficacy for several standard Toeplitz structured CMs commonly employed in a wide range of applications.