 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Boundary-aware Information Maximization for Self-supervised Medical Image Segmentation
Feb 04, 2022
Unsupervised pre-training has been proven as an effective approach to boost various downstream tasks given limited labeled data. Among various methods, contrastive learning learns a discriminative representation by constructing positive and negative pairs. However, it is not trivial to build reasonable pairs for a segmentation task in an unsupervised way. In this work, we propose a novel unsupervised pre-training framework that avoids the drawback of contrastive learning. Our framework consists of two principles: unsupervised over-segmentation as a pre-train task using mutual information maximization and boundary-aware preserving learning. Experimental results on two benchmark medical segmentation datasets reveal our method's effectiveness in improving segmentation performance when few annotated images are available.
Detect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering
Oct 04, 2022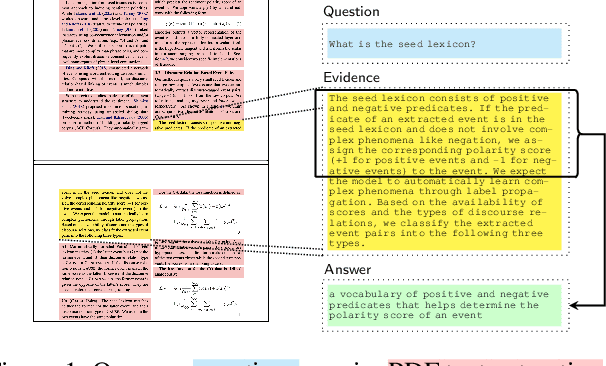
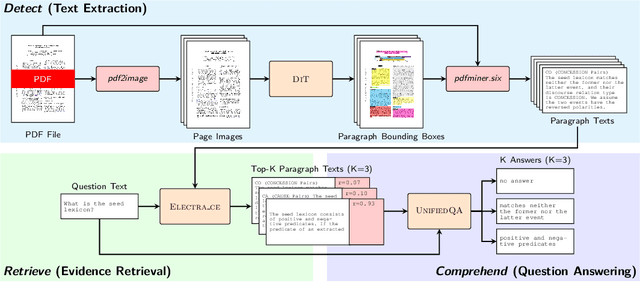

Businesses generate thousands of documents that communicate their strategic vision and provide details of key products, services, entities, and processes. Knowledge workers then face the laborious task of reading these documents to identify, extract, and synthesize information relevant to their organizational goals. To automate information gathering, question answering (QA) offers a flexible framework where human-posed questions can be adapted to extract diverse knowledge. Finetuning QA systems requires access to labeled data (tuples of context, question, and answer). However, data curation for document QA is uniquely challenging because the context (i.e., answer evidence passage) needs to be retrieved from potentially long, ill-formatted documents. Existing QA datasets sidestep this challenge by providing short, well-defined contexts that are unrealistic in real-world applications. We present a three-stage document QA approach: (1) text extraction from PDF; (2) evidence retrieval from extracted texts to form well-posed contexts; (3) QA to extract knowledge from contexts to return high-quality answers - extractive, abstractive, or Boolean. Using QASPER as a surrogate to our proprietary data, our detect-retrieve-comprehend (DRC) system achieves a +6.25 improvement in Answer-F1 over existing baselines while delivering superior context selection. Our results demonstrate that DRC holds tremendous promise as a flexible framework for practical document QA.
Camera Alignment and Weighted Contrastive Learning for Domain Adaptation in Video Person ReID
Nov 07, 2022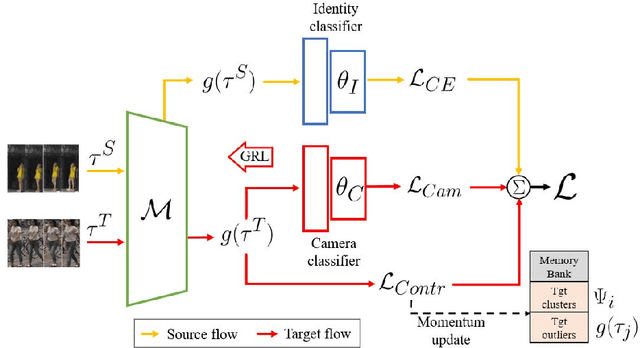
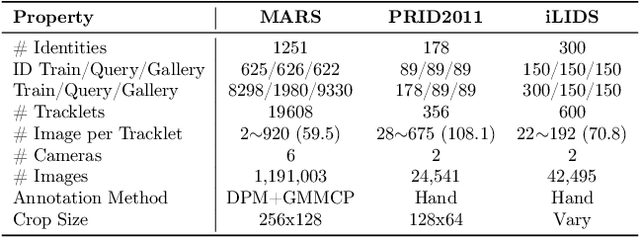
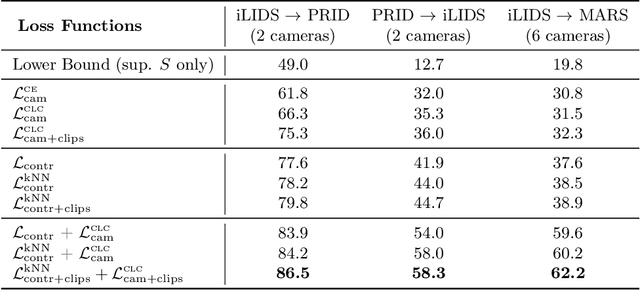
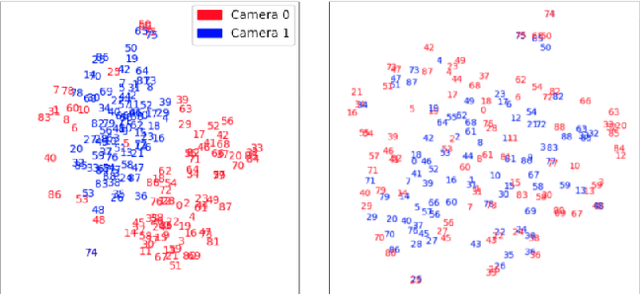
Systems for person re-identification (ReID) can achieve a high accuracy when trained on large fully-labeled image datasets. However, the domain shift typically associated with diverse operational capture conditions (e.g., camera viewpoints and lighting) may translate to a significant decline in performance. This paper focuses on unsupervised domain adaptation (UDA) for video-based ReID - a relevant scenario that is less explored in the literature. In this scenario, the ReID model must adapt to a complex target domain defined by a network of diverse video cameras based on tracklet information. State-of-art methods cluster unlabeled target data, yet domain shifts across target cameras (sub-domains) can lead to poor initialization of clustering methods that propagates noise across epochs, thus preventing the ReID model to accurately associate samples of same identity. In this paper, an UDA method is introduced for video person ReID that leverages knowledge on video tracklets, and on the distribution of frames captured over target cameras to improve the performance of CNN backbones trained using pseudo-labels. Our method relies on an adversarial approach, where a camera-discriminator network is introduced to extract discriminant camera-independent representations, facilitating the subsequent clustering. In addition, a weighted contrastive loss is proposed to leverage the confidence of clusters, and mitigate the risk of incorrect identity associations. Experimental results obtained on three challenging video-based person ReID datasets - PRID2011, iLIDS-VID, and MARS - indicate that our proposed method can outperform related state-of-the-art methods. Our code is available at: \url{https://github.com/dmekhazni/CAWCL-ReID}
BuildMapper: A Fully Learnable Framework for Vectorized Building Contour Extraction
Nov 07, 2022
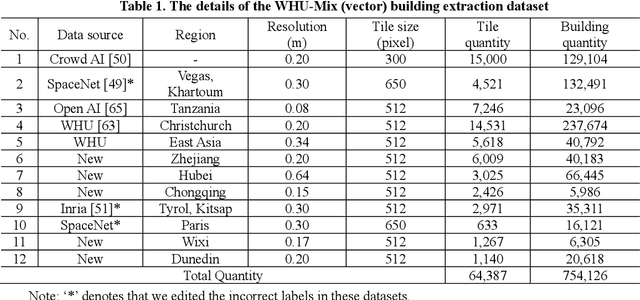
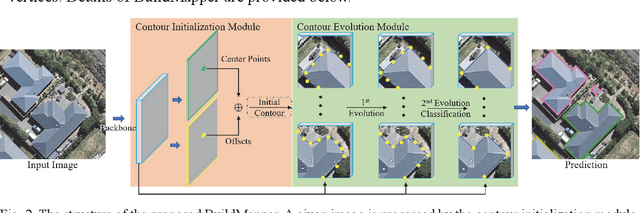

Deep learning based methods have significantly boosted the study of automatic building extraction from remote sensing images. However, delineating vectorized and regular building contours like a human does remains very challenging, due to the difficulty of the methodology, the diversity of building structures, and the imperfect imaging conditions. In this paper, we propose the first end-to-end learnable building contour extraction framework, named BuildMapper, which can directly and efficiently delineate building polygons just as a human does. BuildMapper consists of two main components: 1) a contour initialization module that generates initial building contours; and 2) a contour evolution module that performs both contour vertex deformation and reduction, which removes the need for complex empirical post-processing used in existing methods. In both components, we provide new ideas, including a learnable contour initialization method to replace the empirical methods, dynamic predicted and ground truth vertex pairing for the static vertex correspondence problem, and a lightweight encoder for vertex information extraction and aggregation, which benefit a general contour-based method; and a well-designed vertex classification head for building corner vertices detection, which casts light on direct structured building contour extraction. We also built a suitable large-scale building dataset, the WHU-Mix (vector) building dataset, to benefit the study of contour-based building extraction methods. The extensive experiments conducted on the WHU-Mix (vector) dataset, the WHU dataset, and the CrowdAI dataset verified that BuildMapper can achieve a state-of-the-art performance, with a higher mask average precision (AP) and boundary AP than both segmentation-based and contour-based methods.
Lipschitz regularized gradient flows and latent generative particles
Nov 07, 2022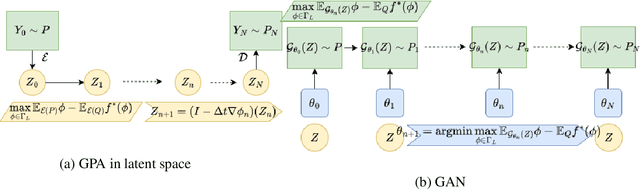

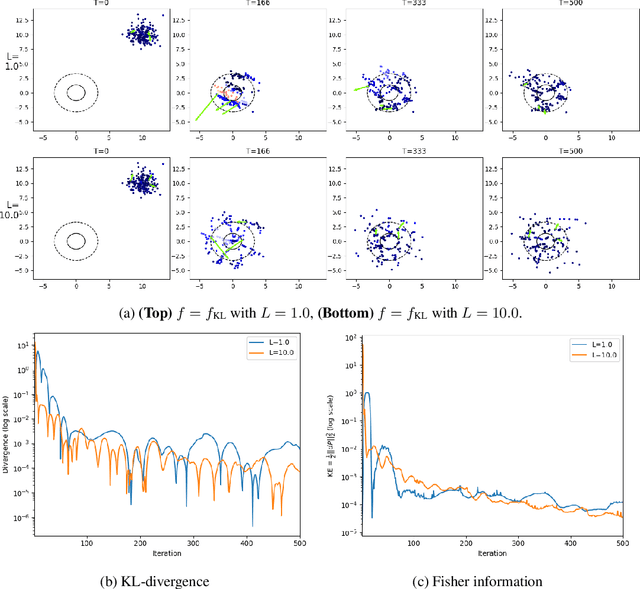
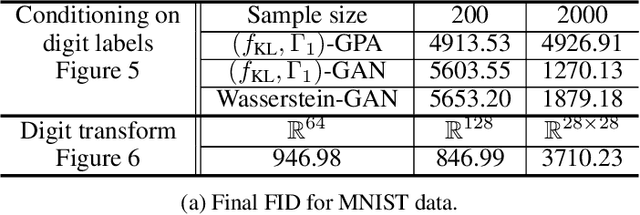
Lipschitz regularized f-divergences are constructed by imposing a bound on the Lipschitz constant of the discriminator in the variational representation. They interpolate between the Wasserstein metric and f-divergences and provide a flexible family of loss functions for non-absolutely continuous (e.g. empirical) distributions, possibly with heavy tails. We construct Lipschitz regularized gradient flows on the space of probability measures based on these divergences. Examples of such gradient flows are Lipschitz regularized Fokker-Planck and porous medium partial differential equations (PDEs) for the Kullback-Leibler and alpha-divergences, respectively. The regularization corresponds to imposing a Courant-Friedrichs-Lewy numerical stability condition on the PDEs. For empirical measures, the Lipschitz regularization on gradient flows induces a numerically stable transporter/discriminator particle algorithm, where the generative particles are transported along the gradient of the discriminator. The gradient structure leads to a regularized Fisher information (particle kinetic energy) used to track the convergence of the algorithm. The Lipschitz regularized discriminator can be implemented via neural network spectral normalization and the particle algorithm generates approximate samples from possibly high-dimensional distributions known only from data. Notably, our particle algorithm can generate synthetic data even in small sample size regimes. A new data processing inequality for the regularized divergence allows us to combine our particle algorithm with representation learning, e.g. autoencoder architectures. The resulting algorithm yields markedly improved generative properties in terms of efficiency and quality of the synthetic samples. From a statistical mechanics perspective the encoding can be interpreted dynamically as learning a better mobility for the generative particles.
Explaining Translationese: why are Neural Classifiers Better and what do they Learn?
Oct 24, 2022


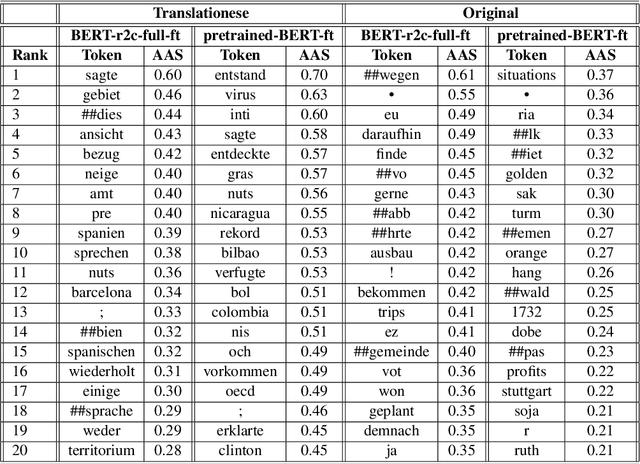
Recent work has shown that neural feature- and representation-learning, e.g. BERT, achieves superior performance over traditional manual feature engineering based approaches, with e.g. SVMs, in translationese classification tasks. Previous research did not show $(i)$ whether the difference is because of the features, the classifiers or both, and $(ii)$ what the neural classifiers actually learn. To address $(i)$, we carefully design experiments that swap features between BERT- and SVM-based classifiers. We show that an SVM fed with BERT representations performs at the level of the best BERT classifiers, while BERT learning and using handcrafted features performs at the level of an SVM using handcrafted features. This shows that the performance differences are due to the features. To address $(ii)$ we use integrated gradients and find that $(a)$ there is indication that information captured by hand-crafted features is only a subset of what BERT learns, and $(b)$ part of BERT's top performance results are due to BERT learning topic differences and spurious correlations with translationese.
E-Valuating Classifier Two-Sample Tests
Oct 24, 2022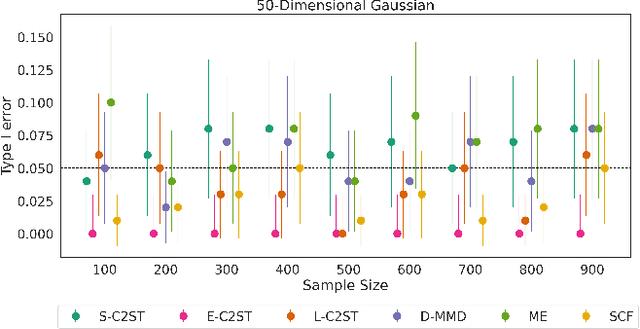
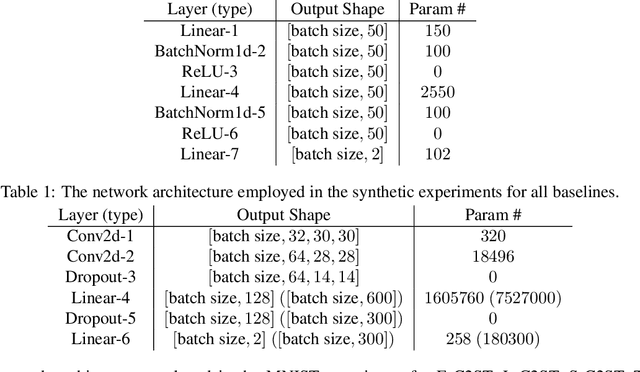
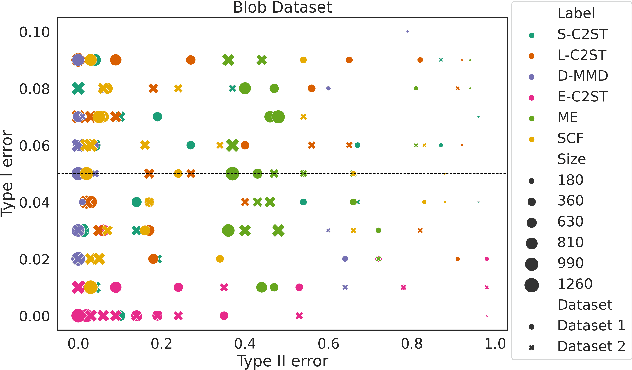
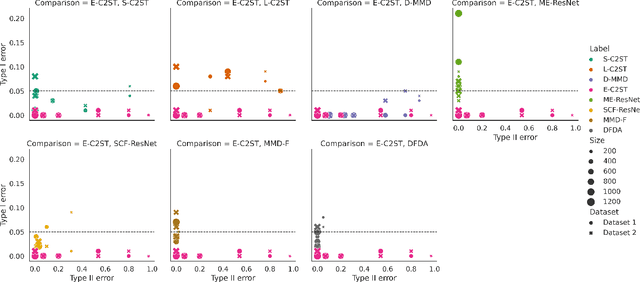
We propose E-C2ST, a classifier two-sample test for high-dimensional data based on E-values. Compared to $p$-values-based tests, tests with E-values have finite sample guarantees for the type I error. E-C2ST combines ideas from existing work on split likelihood ratio tests and predictive independence testing. The resulting E-values incorporate information about the alternative hypothesis. We demonstrate the utility of E-C2ST on simulated and real-life data. In all experiments, we observe that when going from small to large sample sizes, as expected, E-C2ST starts with lower power compared to other methods but eventually converges towards one. Simultaneously, E-C2ST's type I error stays substantially below the chosen significance level, which is not always the case for the baseline methods. Finally, we use an MRI dataset to demonstrate that multiplying E-values from multiple independently conducted studies leads to a combined E-value that retains the finite sample type I error guarantees while increasing the power.
Cards Against AI: Predicting Humor in a Fill-in-the-blank Party Game
Oct 24, 2022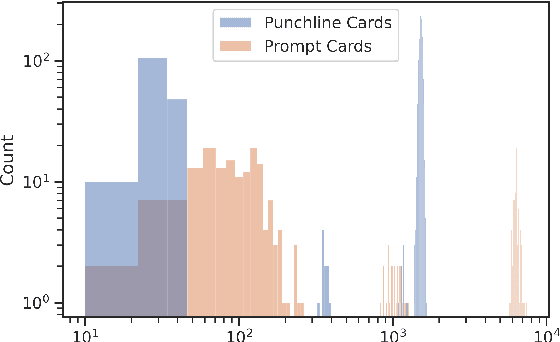
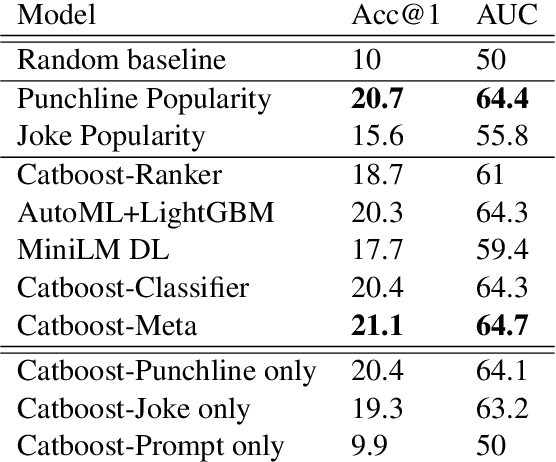
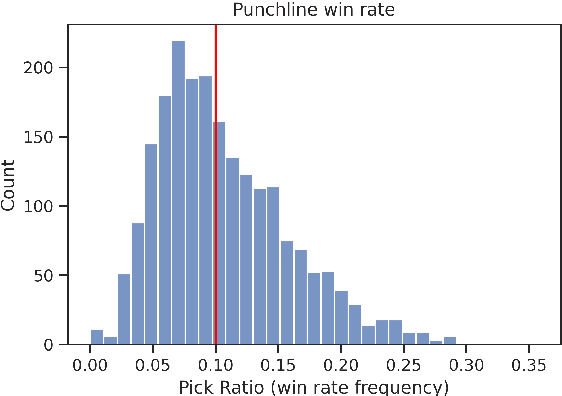
Humor is an inherently social phenomenon, with humorous utterances shaped by what is socially and culturally accepted. Understanding humor is an important NLP challenge, with many applications to human-computer interactions. In this work we explore humor in the context of Cards Against Humanity -- a party game where players complete fill-in-the-blank statements using cards that can be offensive or politically incorrect. We introduce a novel dataset of 300,000 online games of Cards Against Humanity, including 785K unique jokes, analyze it and provide insights. We trained machine learning models to predict the winning joke per game, achieving performance twice as good (20\%) as random, even without any user information. On the more difficult task of judging novel cards, we see the models' ability to generalize is moderate. Interestingly, we find that our models are primarily focused on punchline card, with the context having little impact. Analyzing feature importance, we observe that short, crude, juvenile punchlines tend to win.
Reliable Malware Analysis and Detection using Topology Data Analysis
Nov 03, 2022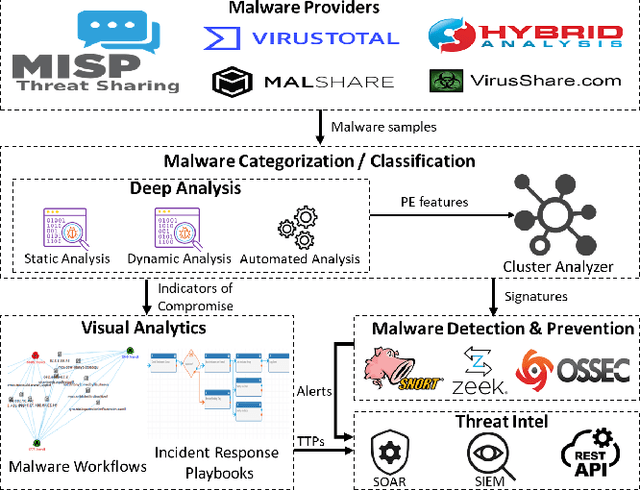
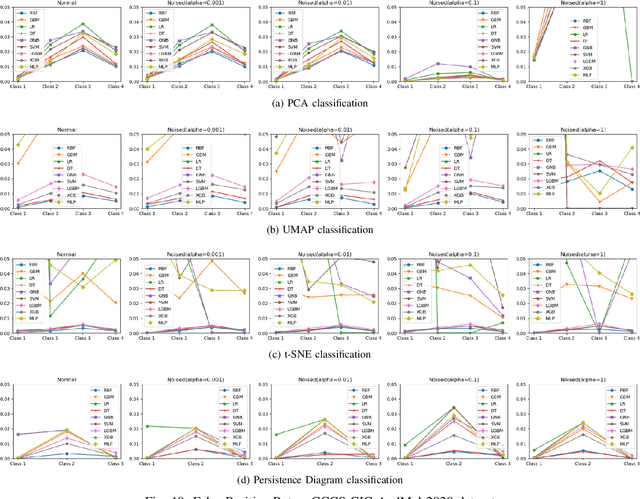
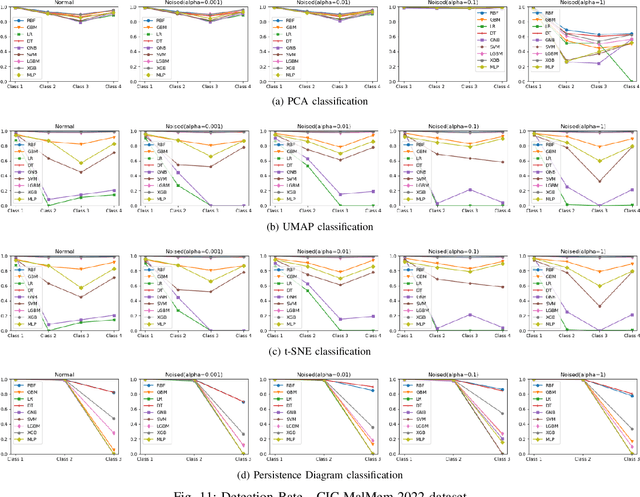
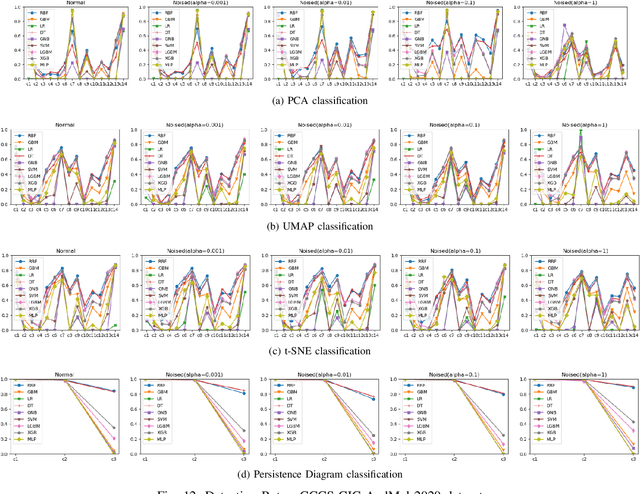
Increasingly, malwares are becoming complex and they are spreading on networks targeting different infrastructures and personal-end devices to collect, modify, and destroy victim information. Malware behaviors are polymorphic, metamorphic, persistent, able to hide to bypass detectors and adapt to new environments, and even leverage machine learning techniques to better damage targets. Thus, it makes them difficult to analyze and detect with traditional endpoint detection and response, intrusion detection and prevention systems. To defend against malwares, recent work has proposed different techniques based on signatures and machine learning. In this paper, we propose to use an algebraic topological approach called topological-based data analysis (TDA) to efficiently analyze and detect complex malware patterns. Next, we compare the different TDA techniques (i.e., persistence homology, tomato, TDA Mapper) and existing techniques (i.e., PCA, UMAP, t-SNE) using different classifiers including random forest, decision tree, xgboost, and lightgbm. We also propose some recommendations to deploy the best-identified models for malware detection at scale. Results show that TDA Mapper (combined with PCA) is better for clustering and for identifying hidden relationships between malware clusters compared to PCA. Persistent diagrams are better to identify overlapping malware clusters with low execution time compared to UMAP and t-SNE. For malware detection, malware analysts can use Random Forest and Decision Tree with t-SNE and Persistent Diagram to achieve better performance and robustness on noised data.
GRAIMATTER Green Paper: Recommendations for disclosure control of trained Machine Learning (ML) models from Trusted Research Environments (TREs)
Nov 03, 2022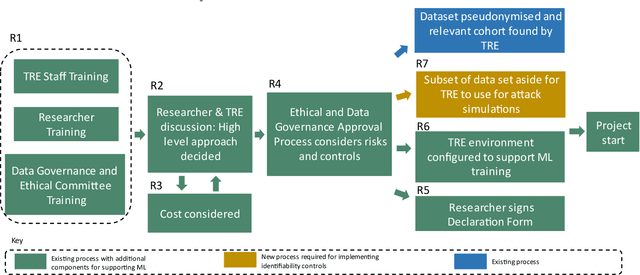
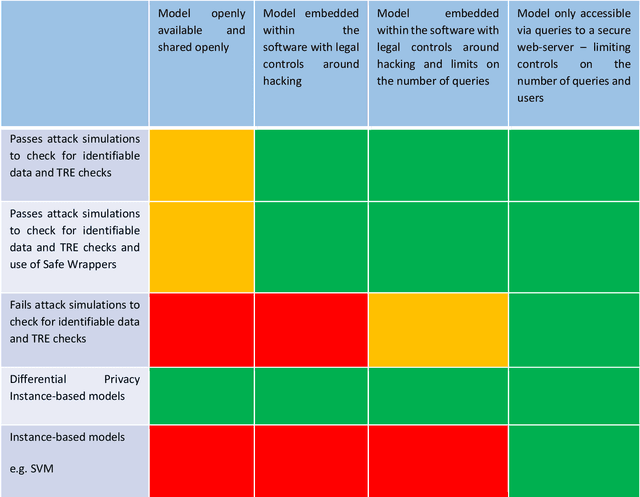
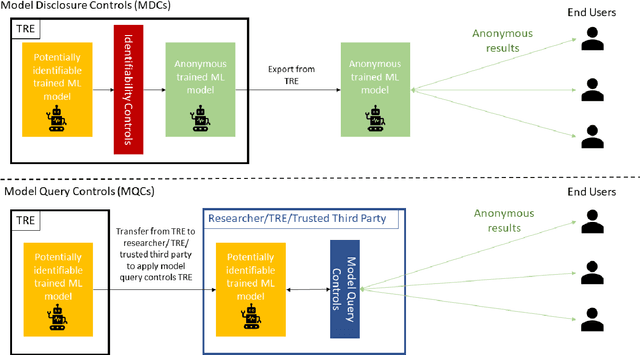

TREs are widely, and increasingly used to support statistical analysis of sensitive data across a range of sectors (e.g., health, police, tax and education) as they enable secure and transparent research whilst protecting data confidentiality. There is an increasing desire from academia and industry to train AI models in TREs. The field of AI is developing quickly with applications including spotting human errors, streamlining processes, task automation and decision support. These complex AI models require more information to describe and reproduce, increasing the possibility that sensitive personal data can be inferred from such descriptions. TREs do not have mature processes and controls against these risks. This is a complex topic, and it is unreasonable to expect all TREs to be aware of all risks or that TRE researchers have addressed these risks in AI-specific training. GRAIMATTER has developed a draft set of usable recommendations for TREs to guard against the additional risks when disclosing trained AI models from TREs. The development of these recommendations has been funded by the GRAIMATTER UKRI DARE UK sprint research project. This version of our recommendations was published at the end of the project in September 2022. During the course of the project, we have identified many areas for future investigations to expand and test these recommendations in practice. Therefore, we expect that this document will evolve over time.