 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
Apr 15, 2026As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
Detect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering
Oct 04, 2022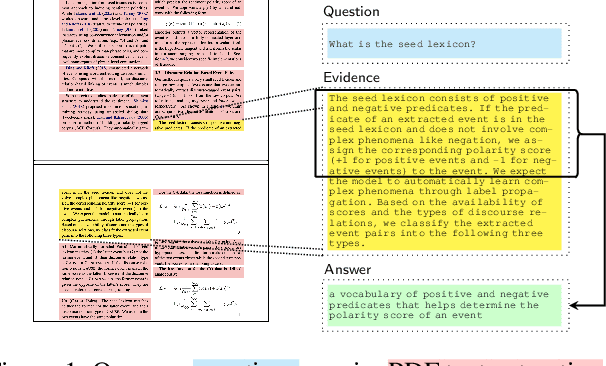
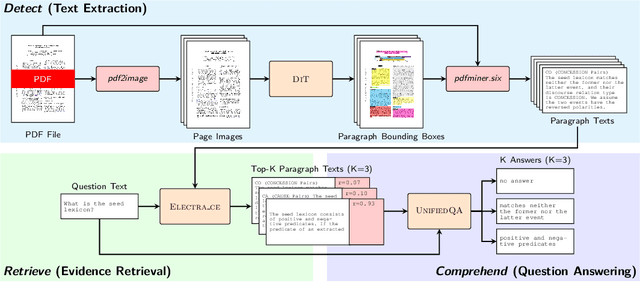

Businesses generate thousands of documents that communicate their strategic vision and provide details of key products, services, entities, and processes. Knowledge workers then face the laborious task of reading these documents to identify, extract, and synthesize information relevant to their organizational goals. To automate information gathering, question answering (QA) offers a flexible framework where human-posed questions can be adapted to extract diverse knowledge. Finetuning QA systems requires access to labeled data (tuples of context, question, and answer). However, data curation for document QA is uniquely challenging because the context (i.e., answer evidence passage) needs to be retrieved from potentially long, ill-formatted documents. Existing QA datasets sidestep this challenge by providing short, well-defined contexts that are unrealistic in real-world applications. We present a three-stage document QA approach: (1) text extraction from PDF; (2) evidence retrieval from extracted texts to form well-posed contexts; (3) QA to extract knowledge from contexts to return high-quality answers - extractive, abstractive, or Boolean. Using QASPER as a surrogate to our proprietary data, our detect-retrieve-comprehend (DRC) system achieves a +6.25 improvement in Answer-F1 over existing baselines while delivering superior context selection. Our results demonstrate that DRC holds tremendous promise as a flexible framework for practical document QA.