 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetect, Retrieve, Comprehend: A Flexible Framework for Zero-Shot Document-Level Question Answering
Paper and Code
Oct 04, 2022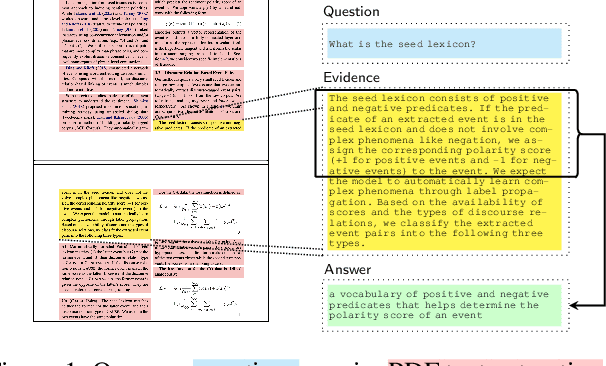
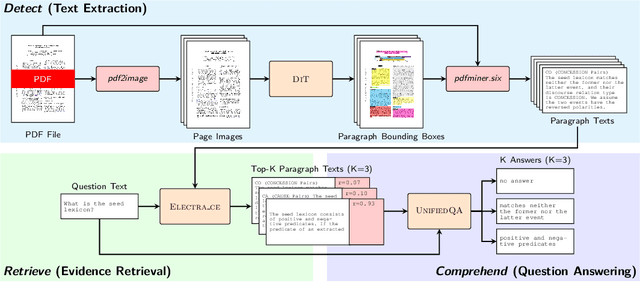

Businesses generate thousands of documents that communicate their strategic vision and provide details of key products, services, entities, and processes. Knowledge workers then face the laborious task of reading these documents to identify, extract, and synthesize information relevant to their organizational goals. To automate information gathering, question answering (QA) offers a flexible framework where human-posed questions can be adapted to extract diverse knowledge. Finetuning QA systems requires access to labeled data (tuples of context, question, and answer). However, data curation for document QA is uniquely challenging because the context (i.e., answer evidence passage) needs to be retrieved from potentially long, ill-formatted documents. Existing QA datasets sidestep this challenge by providing short, well-defined contexts that are unrealistic in real-world applications. We present a three-stage document QA approach: (1) text extraction from PDF; (2) evidence retrieval from extracted texts to form well-posed contexts; (3) QA to extract knowledge from contexts to return high-quality answers - extractive, abstractive, or Boolean. Using QASPER as a surrogate to our proprietary data, our detect-retrieve-comprehend (DRC) system achieves a +6.25 improvement in Answer-F1 over existing baselines while delivering superior context selection. Our results demonstrate that DRC holds tremendous promise as a flexible framework for practical document QA.