 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Framework for Threat Mitigation and Resilience in AI-Based Systems
Dec 29, 2025Machine learning (ML) underpins foundation models in finance, healthcare, and critical infrastructure, making them targets for data poisoning, model extraction, prompt injection, automated jailbreaking, and preference-guided black-box attacks that exploit model comparisons. Larger models can be more vulnerable to introspection-driven jailbreaks and cross-modal manipulation. Traditional cybersecurity lacks ML-specific threat modeling for foundation, multimodal, and RAG systems. Objective: Characterize ML security risks by identifying dominant TTPs, vulnerabilities, and targeted lifecycle stages. Methods: We extract 93 threats from MITRE ATLAS (26), AI Incident Database (12), and literature (55), and analyze 854 GitHub/Python repositories. A multi-agent RAG system (ChatGPT-4o, temp 0.4) mines 300+ articles to build an ontology-driven threat graph linking TTPs, vulnerabilities, and stages. Results: We identify unreported threats including commercial LLM API model stealing, parameter memorization leakage, and preference-guided text-only jailbreaks. Dominant TTPs include MASTERKEY-style jailbreaking, federated poisoning, diffusion backdoors, and preference optimization leakage, mainly impacting pre-training and inference. Graph analysis reveals dense vulnerability clusters in libraries with poor patch propagation. Conclusion: Adaptive, ML-specific security frameworks, combining dependency hygiene, threat intelligence, and monitoring, are essential to mitigate supply-chain and inference risks across the ML lifecycle.
Responsible Design Patterns for Machine Learning Pipelines
Jun 07, 2023Integrating ethical practices into the AI development process for artificial intelligence (AI) is essential to ensure safe, fair, and responsible operation. AI ethics involves applying ethical principles to the entire life cycle of AI systems. This is essential to mitigate potential risks and harms associated with AI, such as algorithm biases. To achieve this goal, responsible design patterns (RDPs) are critical for Machine Learning (ML) pipelines to guarantee ethical and fair outcomes. In this paper, we propose a comprehensive framework incorporating RDPs into ML pipelines to mitigate risks and ensure the ethical development of AI systems. Our framework comprises new responsible AI design patterns for ML pipelines identified through a survey of AI ethics and data management experts and validated through real-world scenarios with expert feedback. The framework guides AI developers, data scientists, and policy-makers to implement ethical practices in AI development and deploy responsible AI systems in production.
An Empirical Study of Library Usage and Dependency in Deep Learning Frameworks
Nov 28, 2022Recent advances in deep learning (dl) have led to the release of several dl software libraries such as pytorch, Caffe, and TensorFlow, in order to assist machine learning (ml) practitioners in developing and deploying state-of-the-art deep neural networks (DNN), but they are not able to properly cope with limitations in the dl libraries such as testing or data processing. In this paper, we present a qualitative and quantitative analysis of the most frequent dl libraries combination, the distribution of dl library dependencies across the ml workflow, and formulate a set of recommendations to (i) hardware builders for more optimized accelerators and (ii) library builder for more refined future releases. Our study is based on 1,484 open-source dl projects with 46,110 contributors selected based on their reputation. First, we found an increasing trend in the usage of deep learning libraries. Second, we highlight several usage patterns of deep learning libraries. In addition, we identify dependencies between dl libraries and the most frequent combination where we discover that pytorch and Scikit-learn and, Keras and TensorFlow are the most frequent combination in 18% and 14% of the projects. The developer uses two or three dl libraries in the same projects and tends to use different multiple dl libraries in both the same function and the same files. The developer shows patterns in using various deep-learning libraries and prefers simple functions with fewer arguments and straightforward goals. Finally, we present the implications of our findings for researchers, library maintainers, and hardware vendors.
Reliable Malware Analysis and Detection using Topology Data Analysis
Nov 08, 2022Increasingly, malwares are becoming complex and they are spreading on networks targeting different infrastructures and personal-end devices to collect, modify, and destroy victim information. Malware behaviors are polymorphic, metamorphic, persistent, able to hide to bypass detectors and adapt to new environments, and even leverage machine learning techniques to better damage targets. Thus, it makes them difficult to analyze and detect with traditional endpoint detection and response, intrusion detection and prevention systems. To defend against malwares, recent work has proposed different techniques based on signatures and machine learning. In this paper, we propose to use an algebraic topological approach called topological-based data analysis (TDA) to efficiently analyze and detect complex malware patterns. Next, we compare the different TDA techniques (i.e., persistence homology, tomato, TDA Mapper) and existing techniques (i.e., PCA, UMAP, t-SNE) using different classifiers including random forest, decision tree, xgboost, and lightgbm. We also propose some recommendations to deploy the best-identified models for malware detection at scale. Results show that TDA Mapper (combined with PCA) is better for clustering and for identifying hidden relationships between malware clusters compared to PCA. Persistent diagrams are better to identify overlapping malware clusters with low execution time compared to UMAP and t-SNE. For malware detection, malware analysts can use Random Forest and Decision Tree with t-SNE and Persistent Diagram to achieve better performance and robustness on noised data.
Threat Assessment in Machine Learning based Systems
Jun 30, 2022
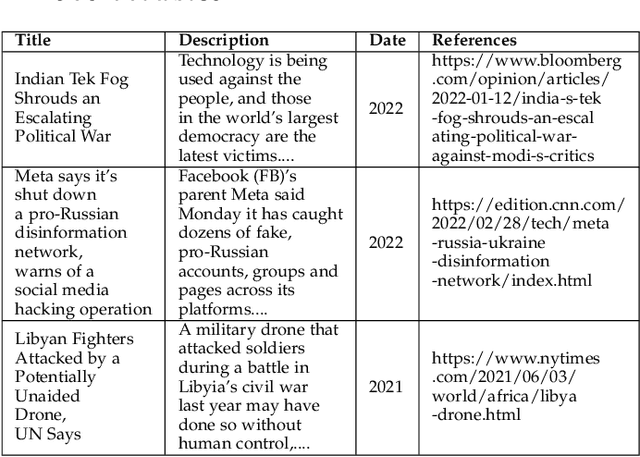
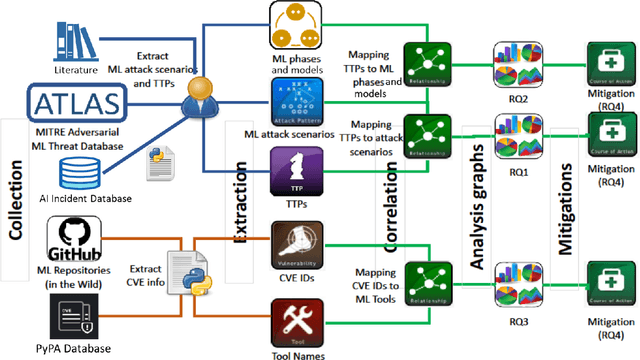
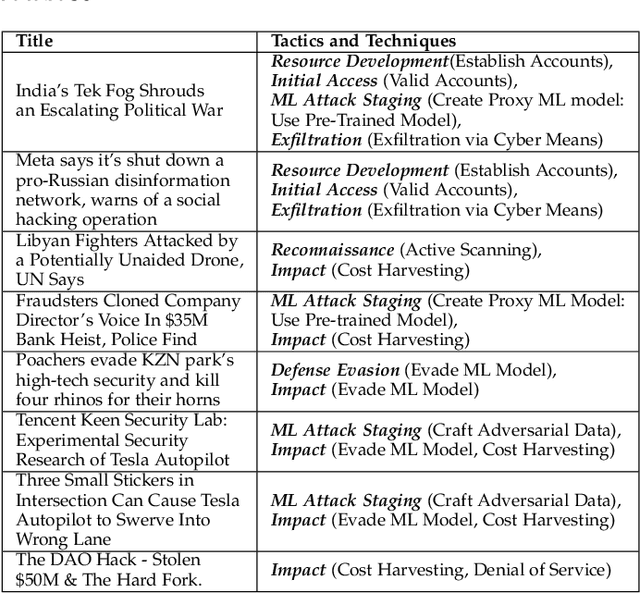
Machine learning is a field of artificial intelligence (AI) that is becoming essential for several critical systems, making it a good target for threat actors. Threat actors exploit different Tactics, Techniques, and Procedures (TTPs) against the confidentiality, integrity, and availability of Machine Learning (ML) systems. During the ML cycle, they exploit adversarial TTPs to poison data and fool ML-based systems. In recent years, multiple security practices have been proposed for traditional systems but they are not enough to cope with the nature of ML-based systems. In this paper, we conduct an empirical study of threats reported against ML-based systems with the aim to understand and characterize the nature of ML threats and identify common mitigation strategies. The study is based on 89 real-world ML attack scenarios from the MITRE's ATLAS database, the AI Incident Database, and the literature; 854 ML repositories from the GitHub search and the Python Packaging Advisory database, selected based on their reputation. Attacks from the AI Incident Database and the literature are used to identify vulnerabilities and new types of threats that were not documented in ATLAS. Results show that convolutional neural networks were one of the most targeted models among the attack scenarios. ML repositories with the largest vulnerability prominence include TensorFlow, OpenCV, and Notebook. In this paper, we also report the most frequent vulnerabilities in the studied ML repositories, the most targeted ML phases and models, the most used TTPs in ML phases and attack scenarios. This information is particularly important for red/blue teams to better conduct attacks/defenses, for practitioners to prevent threats during ML development, and for researchers to develop efficient defense mechanisms.
Never trust, always verify : a roadmap for Trustworthy AI?
Jun 23, 2022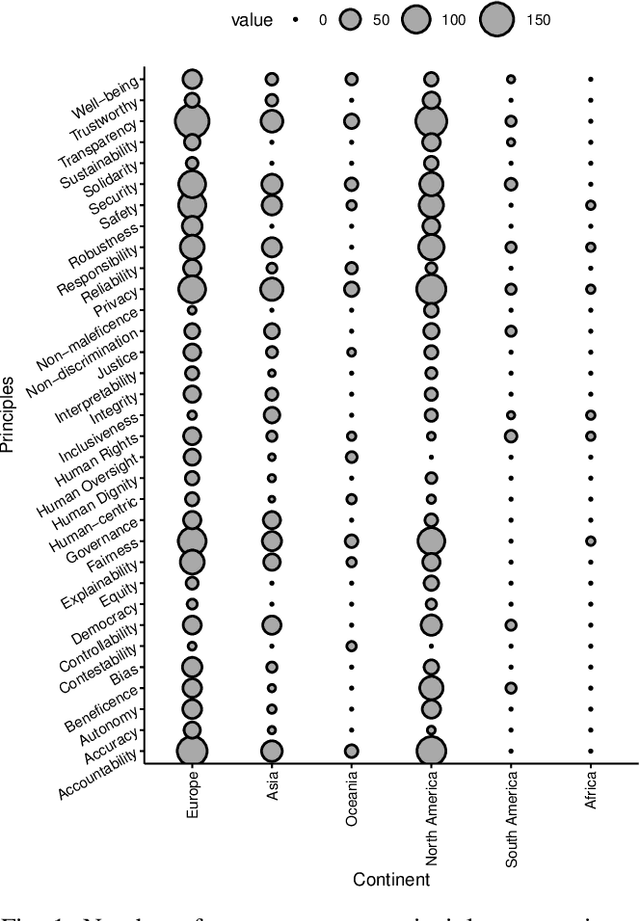
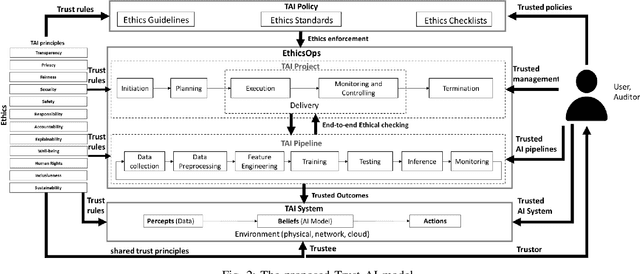
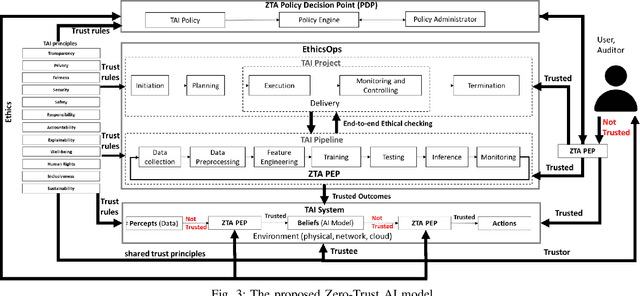
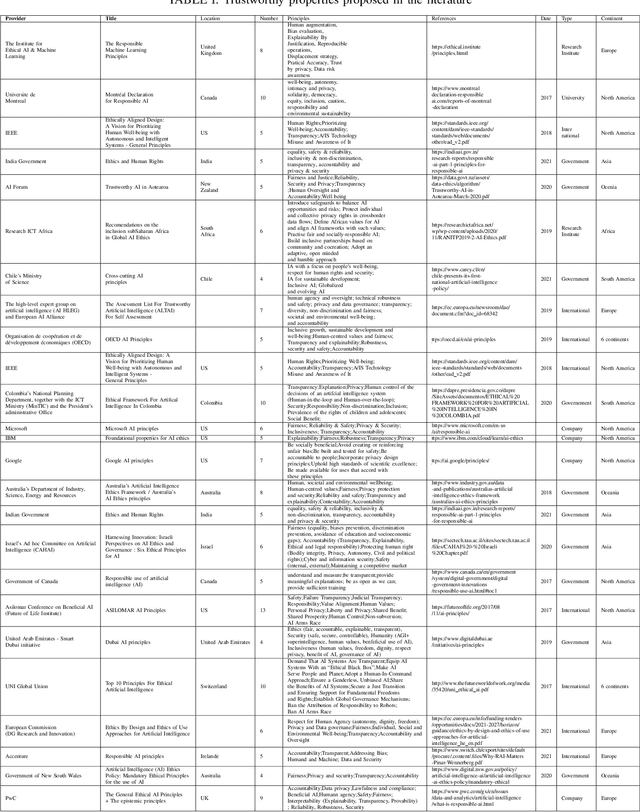
Artificial Intelligence (AI) is becoming the corner stone of many systems used in our daily lives such as autonomous vehicles, healthcare systems, and unmanned aircraft systems. Machine Learning is a field of AI that enables systems to learn from data and make decisions on new data based on models to achieve a given goal. The stochastic nature of AI models makes verification and validation tasks challenging. Moreover, there are intrinsic biaises in AI models such as reproductibility bias, selection bias (e.g., races, genders, color), and reporting bias (i.e., results that do not reflect the reality). Increasingly, there is also a particular attention to the ethical, legal, and societal impacts of AI. AI systems are difficult to audit and certify because of their black-box nature. They also appear to be vulnerable to threats; AI systems can misbehave when untrusted data are given, making them insecure and unsafe. Governments, national and international organizations have proposed several principles to overcome these challenges but their applications in practice are limited and there are different interpretations in the principles that can bias implementations. In this paper, we examine trust in the context of AI-based systems to understand what it means for an AI system to be trustworthy and identify actions that need to be undertaken to ensure that AI systems are trustworthy. To achieve this goal, we first review existing approaches proposed for ensuring the trustworthiness of AI systems, in order to identify potential conceptual gaps in understanding what trustworthy AI is. Then, we suggest a trust (resp. zero-trust) model for AI and suggest a set of properties that should be satisfied to ensure the trustworthiness of AI systems.