 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Mapping Extended Landmarks for Radar SLAM
Oct 31, 2022
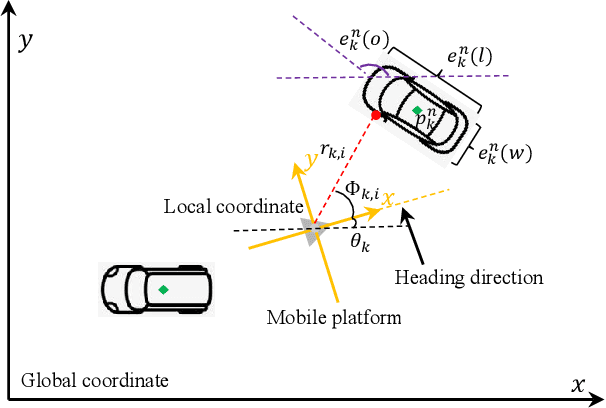

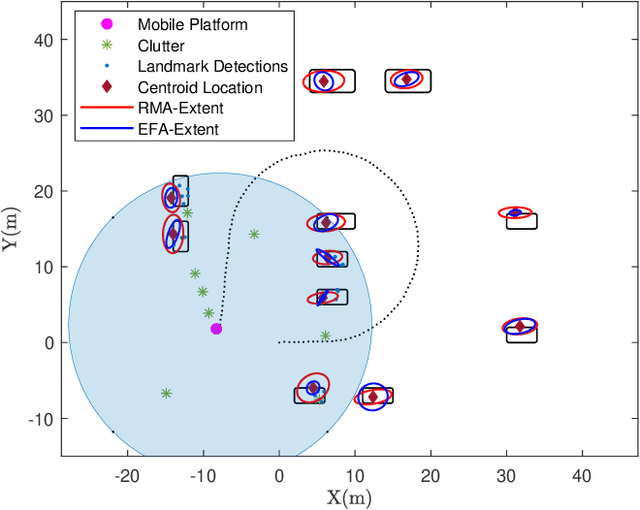
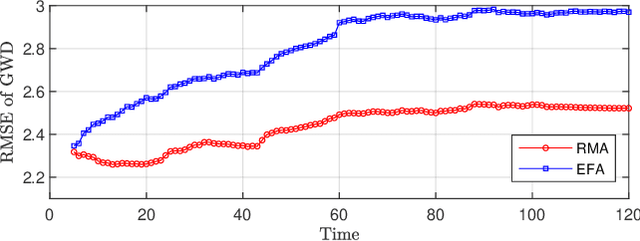
Simultaneous localization and mapping (SLAM) using automotive radar sensors can provide enhanced sensing capabilities for autonomous systems. In SLAM applications, with a greater requirement for the environment map, information on the extent of landmarks is vital for precise navigation and path planning. Although object extent estimation has been successfully applied in target tracking, its adaption to SLAM remains unaddressed due to the additional uncertainty of the sensor platform, bias in the odometer reading, as well as the measurement non-linearity. In this paper, we propose to incorporate the Bayesian random matrix approach to estimate the extent of landmarks in radar SLAM. We describe the details for implementation of landmark extent initialization, prediction and update. To validate the performance of our proposed approach we compare with the model-free ellipse fitting algorithm with results showing more consistent extent estimation. We also demonstrate that exploiting the landmark extent in the state update can improve localization accuracy.
Learning to Navigate Wikipedia by Taking Random Walks
Oct 31, 2022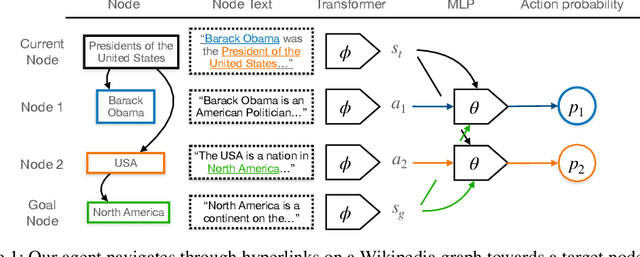

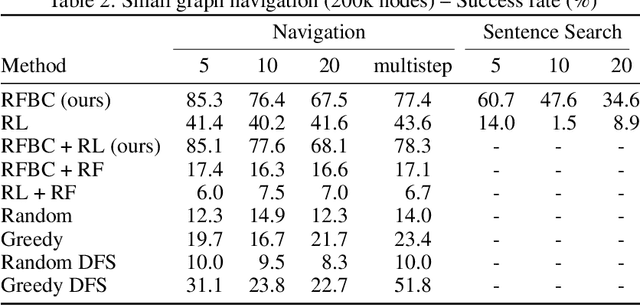
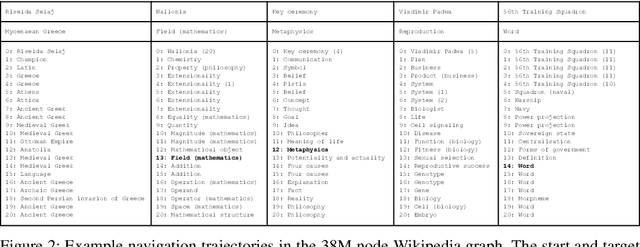
A fundamental ability of an intelligent web-based agent is seeking out and acquiring new information. Internet search engines reliably find the correct vicinity but the top results may be a few links away from the desired target. A complementary approach is navigation via hyperlinks, employing a policy that comprehends local content and selects a link that moves it closer to the target. In this paper, we show that behavioral cloning of randomly sampled trajectories is sufficient to learn an effective link selection policy. We demonstrate the approach on a graph version of Wikipedia with 38M nodes and 387M edges. The model is able to efficiently navigate between nodes 5 and 20 steps apart 96% and 92% of the time, respectively. We then use the resulting embeddings and policy in downstream fact verification and question answering tasks where, in combination with basic TF-IDF search and ranking methods, they are competitive results to the state-of-the-art methods.
Convolution-Based Channel-Frequency Attention for Text-Independent Speaker Verification
Oct 31, 2022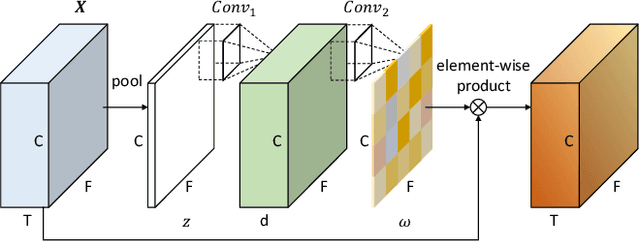
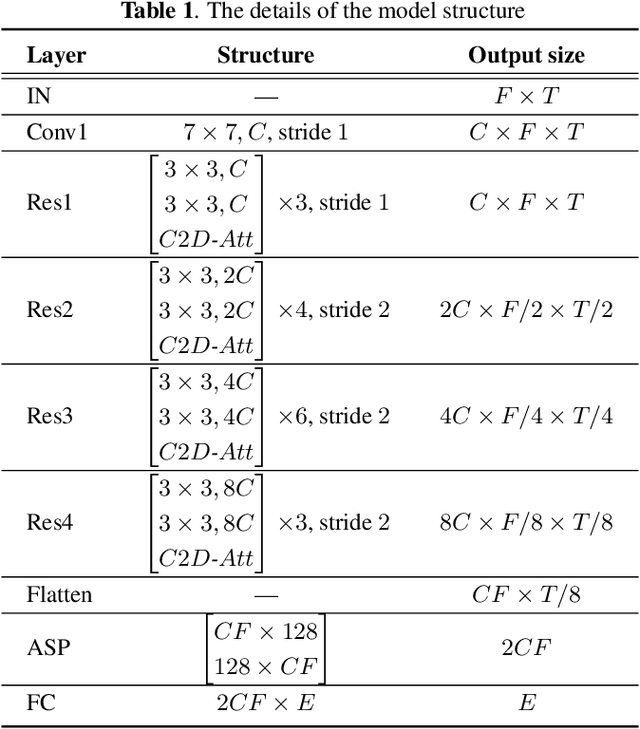
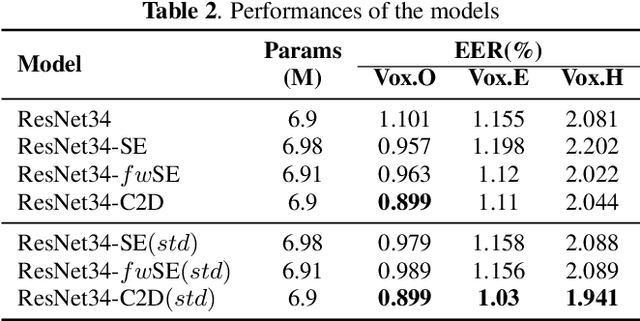
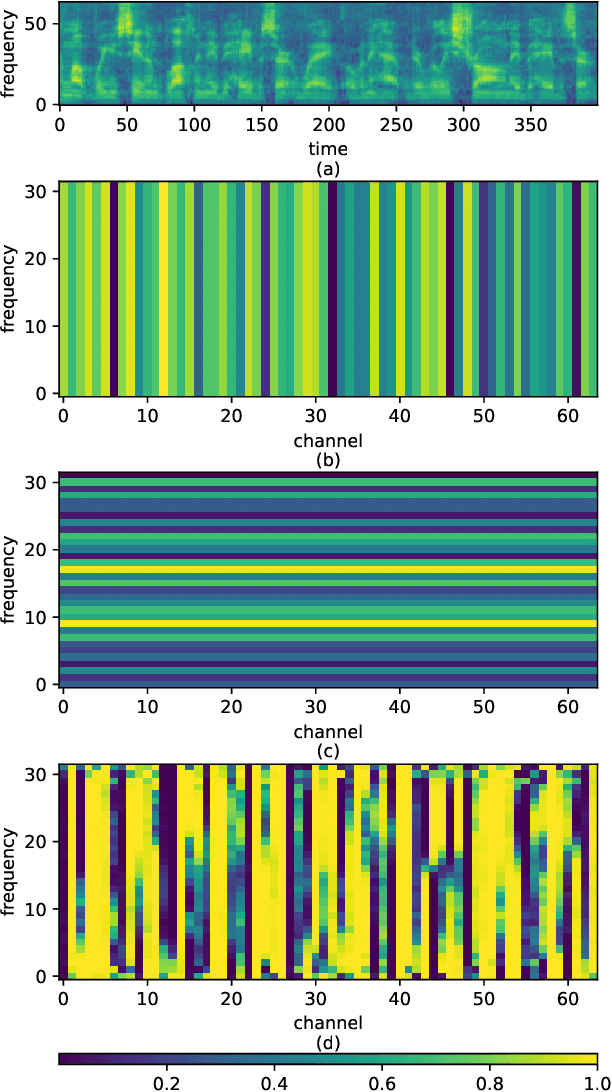
Deep convolutional neural networks (CNNs) have been applied to extracting speaker embeddings with significant success in speaker verification. Incorporating the attention mechanism has shown to be effective in improving the model performance. This paper presents an efficient two-dimensional convolution-based attention module, namely C2D-Att. The interaction between the convolution channel and frequency is involved in the attention calculation by lightweight convolution layers. This requires only a small number of parameters. Fine-grained attention weights are produced to represent channel and frequency-specific information. The weights are imposed on the input features to improve the representation ability for speaker modeling. The C2D-Att is integrated into a modified version of ResNet for speaker embedding extraction. Experiments are conducted on VoxCeleb datasets. The results show that C2DAtt is effective in generating discriminative attention maps and outperforms other attention methods. The proposed model shows robust performance with different scales of model size and achieves state-of-the-art results.
Diffusion models for missing value imputation in tabular data
Oct 31, 2022
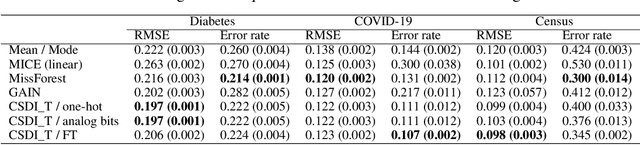
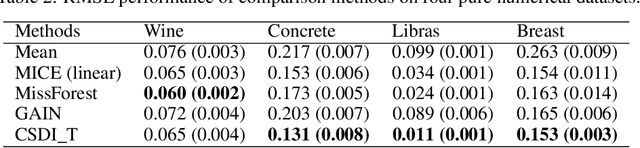
Missing value imputation in machine learning is the task of estimating the missing values in the dataset accurately using available information. In this task, several deep generative modeling methods have been proposed and demonstrated their usefulness, e.g., generative adversarial imputation networks. Recently, diffusion models have gained popularity because of their effectiveness in the generative modeling task in images, texts, audio, etc. To our knowledge, less attention has been paid to the investigation of the effectiveness of diffusion models for missing value imputation in tabular data. Based on recent development of diffusion models for time-series data imputation, we propose a diffusion model approach called "Conditional Score-based Diffusion Models for Tabular data" (CSDI_T). To effectively handle categorical variables and numerical variables simultaneously, we investigate three techniques: one-hot encoding, analog bits encoding, and feature tokenization. Experimental results on benchmark datasets demonstrated the effectiveness of CSDI_T compared with well-known existing methods, and also emphasized the importance of the categorical embedding techniques.
Source-Filter HiFi-GAN: Fast and Pitch Controllable High-Fidelity Neural Vocoder
Oct 31, 2022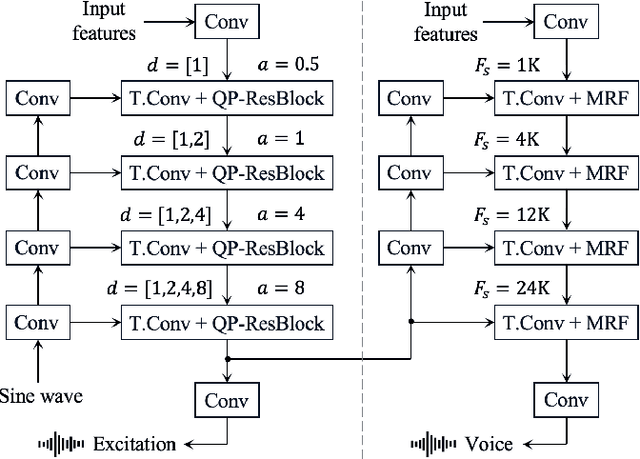
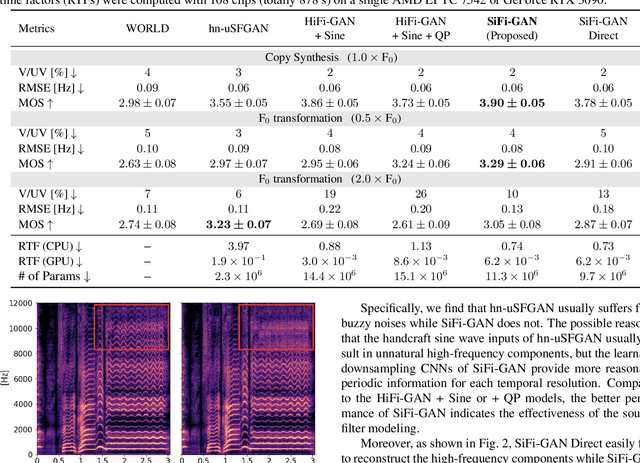
Our previous work, the unified source-filter GAN (uSFGAN) vocoder, introduced a novel architecture based on the source-filter theory into the parallel waveform generative adversarial network to achieve high voice quality and pitch controllability. However, the high temporal resolution inputs result in high computation costs. Although the HiFi-GAN vocoder achieves fast high-fidelity voice generation thanks to the efficient upsampling-based generator architecture, the pitch controllability is severely limited. To realize a fast and pitch-controllable high-fidelity neural vocoder, we introduce the source-filter theory into HiFi-GAN by hierarchically conditioning the resonance filtering network on a well-estimated source excitation information. According to the experimental results, our proposed method outperforms HiFi-GAN and uSFGAN on a singing voice generation in voice quality and synthesis speed on a single CPU. Furthermore, unlike the uSFGAN vocoder, the proposed method can be easily adopted/integrated in real-time applications and end-to-end systems.
Medical Image Captioning via Generative Pretrained Transformers
Sep 28, 2022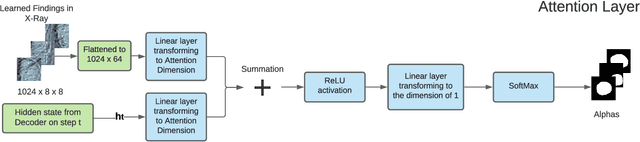
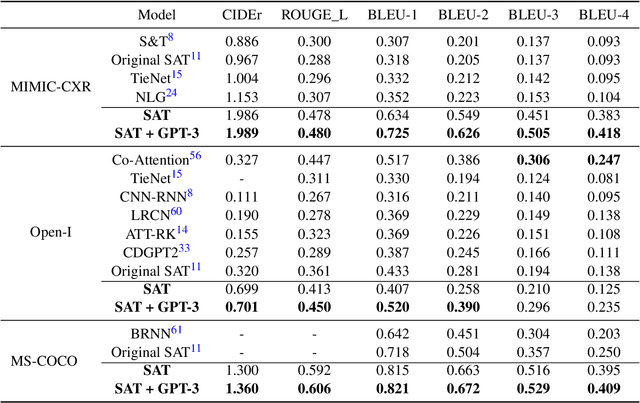
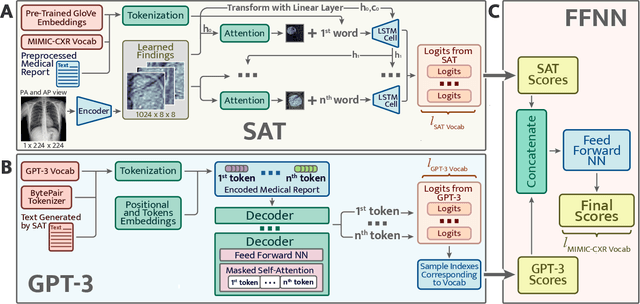
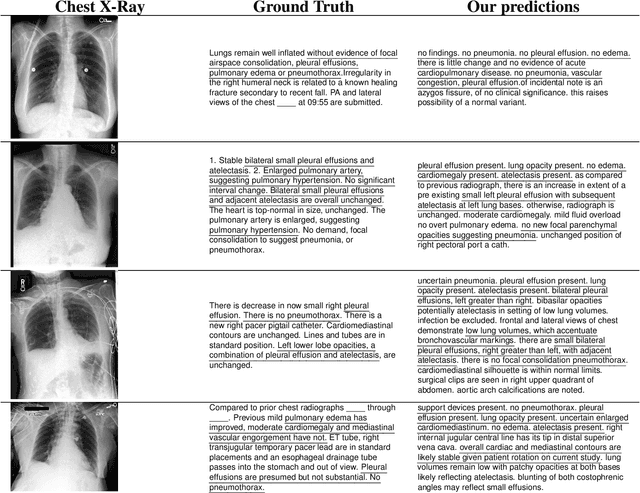
The automatic clinical caption generation problem is referred to as proposed model combining the analysis of frontal chest X-Ray scans with structured patient information from the radiology records. We combine two language models, the Show-Attend-Tell and the GPT-3, to generate comprehensive and descriptive radiology records. The proposed combination of these models generates a textual summary with the essential information about pathologies found, their location, and the 2D heatmaps localizing each pathology on the original X-Ray scans. The proposed model is tested on two medical datasets, the Open-I, MIMIC-CXR, and the general-purpose MS-COCO. The results measured with the natural language assessment metrics prove their efficient applicability to the chest X-Ray image captioning.
Binaural Speech Enhancement Using STOI-Optimal Masks
Sep 30, 2022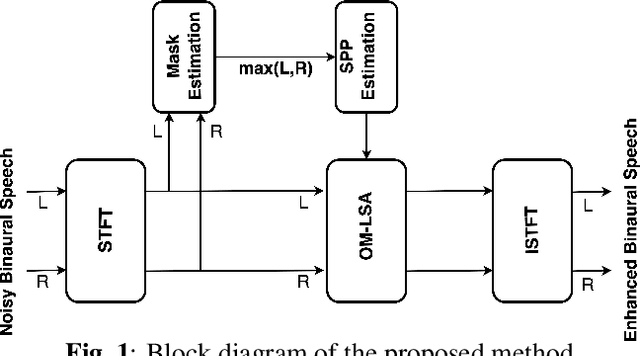
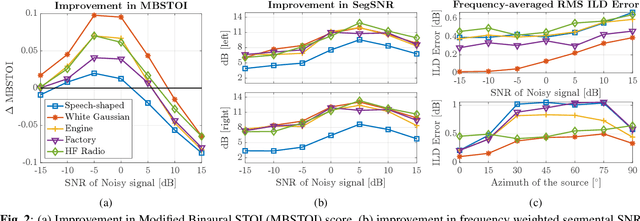
STOI-optimal masking has been previously proposed and developed for single-channel speech enhancement. In this paper, we consider the extension to the task of binaural speech enhancement in which spatial information is known to be important to speech understanding and therefore should be preserved by the enhancement processing. Masks are estimated for each of the binaural channels individually and a `better-ear listening' mask is computed by choosing the maximum of the two masks. The estimated mask is used to supply probability information about the speech presence in each time-frequency bin to an Optimally-modified Log Spectral Amplitude (OM-LSA) enhancer. We show that using the proposed method for binaural signals with a directional noise not only improves the SNR of the noisy signal but also preserves the binaural cues and intelligibility.
Double Graphs Regularized Multi-view Subspace Clustering
Sep 30, 2022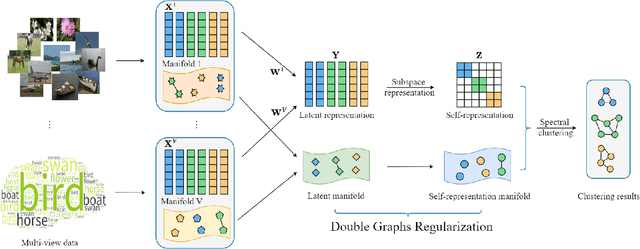

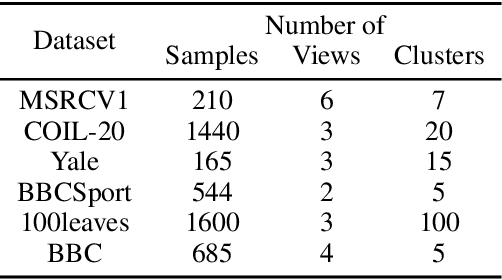
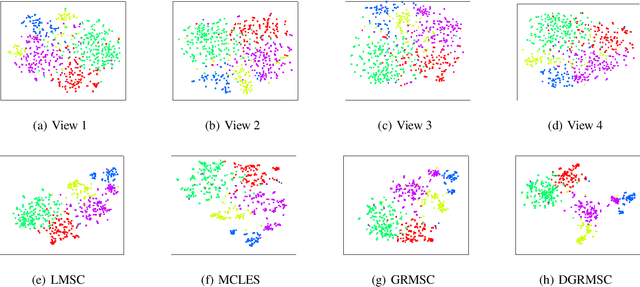
Recent years have witnessed a growing academic interest in multi-view subspace clustering. In this paper, we propose a novel Double Graphs Regularized Multi-view Subspace Clustering (DGRMSC) method, which aims to harness both global and local structural information of multi-view data in a unified framework. Specifically, DGRMSC firstly learns a latent representation to exploit the global complementary information of multiple views. Based on the learned latent representation, we learn a self-representation to explore its global cluster structure. Further, Double Graphs Regularization (DGR) is performed on both latent representation and self-representation to take advantage of their local manifold structures simultaneously. Then, we design an iterative algorithm to solve the optimization problem effectively. Extensive experimental results on real-world datasets demonstrate the effectiveness of the proposed method.
Longitudinal thermal imaging for scalable non-residential HVAC and occupant behaviour characterization
Nov 17, 2022



This work presents a study on the characterization of the air-conditioning (AC) usage pattern of non-residential buildings from thermal images collected from an urban-scale infrared (IR) observatory. To achieve this first, an image processing scheme, for cleaning and extraction of the temperature time series from the thermal images is implemented. To test the accuracy of the thermal measurements using IR camera, the extracted temperature is compared against the ground truth surface temperature measurements. It is observed that the detrended thermal measurements match well with the ground truth surface temperature measurements. Subsequently, the operational pattern of the water-cooled systems and window AC units are extracted from the analysis of the thermal signature. It is observed that for the water-cooled system, the difference between the rate of change of the window and wall can be used to extract the operational pattern. While, in the case of the window AC units, wavelet transform of the AC unit temperature is used to extract the frequency and time domain information of the AC unit operation. The results of the analysis are compared against the indoor temperature sensors installed in the office spaces of the building. It is realized that the accuracy in the prediction of the operational pattern is highest between 8 pm to 10 am, and it reduces during the day because of solar radiation and high daytime temperature. Subsequently, a characterization study is conducted for eight window/split AC units from the thermal image collected during the nighttime. This forms one of the first studies on the operational behavior of HVAC systems for non-residential buildings using the longitudinal thermal imaging technique. The output from this study can be used to better understand the operational and occupant behavior, without requiring to deploy a large array of sensors in the building space.
Seeing Through The Noisy Dark: Toward Real-world Low-Light Image Enhancement and Denoising
Oct 07, 2022
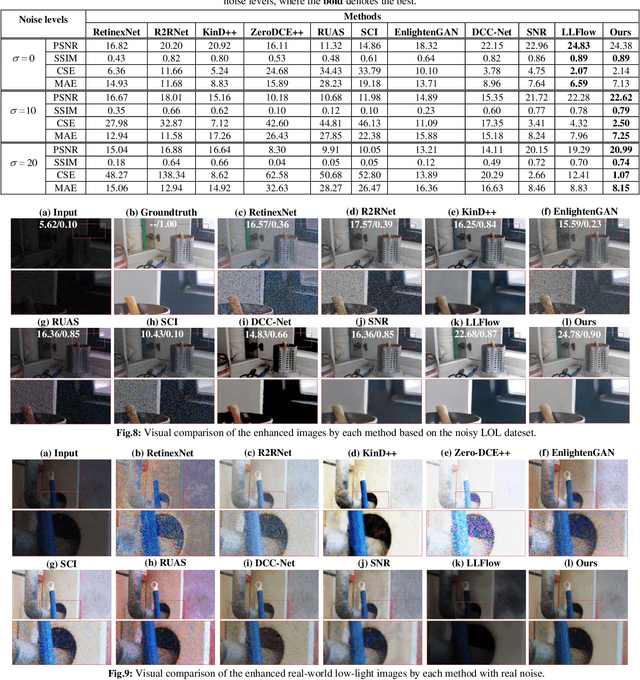
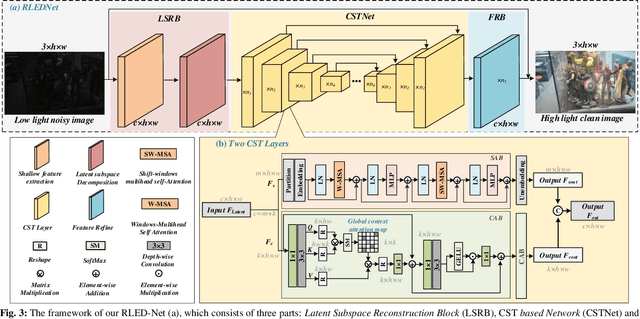
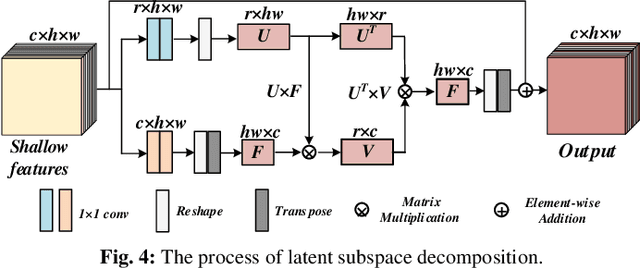
Images collected in real-world low-light environment usually suffer from lower visibility and heavier noise, due to the insufficient light or hardware limitation. While existing low-light image enhancement (LLIE) methods basically ignored the noise interference and mainly focus on refining the illumination of the low-light images based on benchmarked noise-negligible datasets. Such operations will make them inept for the real-world LLIE (RLLIE) with heavy noise, and result in speckle noise and blur in the enhanced images. Although several LLIE methods considered the noise in low-light image, they are trained on the raw data and hence cannot be used for sRGB images, since the domains of data are different and lack of expertise or unknown protocols. In this paper, we clearly consider the task of seeing through the noisy dark in sRGB color space, and propose a novel end-to-end method termed Real-world Low-light Enhancement & Denoising Network (RLED-Net). Since natural images can usually be characterized by low-rank subspaces in which the redundant information and noise can be removed, we design a Latent Subspace Reconstruction Block (LSRB) for feature extraction and denoising. To reduce the loss of global feature (e.g., color/shape information) and extract more accurate local features (e.g., edge/texture information), we also present a basic layer with two branches, called Cross-channel & Shift-window Transformer (CST). Based on the CST, we further present a new backbone to design a U-structure Network (CSTNet) for deep feature recovery, and also design a Feature Refine Block (FRB) to refine the final features. Extensive experiments on real noisy images and public databases verified the effectiveness of our RLED-Net for both RLLIE and denoising.