 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHead-steered channel selection method for hearing aid applications using remote microphones
Aug 09, 2025We propose a channel selection method for hearing aid applications using remote microphones, in the presence of multiple competing talkers. The proposed channel selection method uses the hearing aid user's head-steering direction to identify the remote channel originating from the frontal direction of the hearing aid user, which captures the target talker signal. We pose the channel selection task as a multiple hypothesis testing problem, and derive a maximum likelihood solution. Under realistic, simplifying assumptions, the solution selects the remote channel which has the highest weighted squared absolute correlation coefficient with the output of the head-steered hearing aid beamformer. We analyze the performance of the proposed channel selection method using close-talking remote microphones and table microphone arrays. Through simulations using realistic acoustic scenes, we show that the proposed channel selection method consistently outperforms existing methods in accurately finding the remote channel that captures the target talker signal, in the presence of multiple competing talkers, without the use of any additional sensors.
Binaural Localization Model for Speech in Noise
Jul 26, 2025
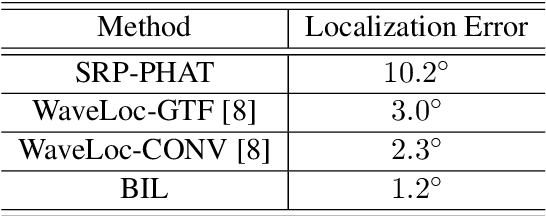

Binaural acoustic source localization is important to human listeners for spatial awareness, communication and safety. In this paper, an end-to-end binaural localization model for speech in noise is presented. A lightweight convolutional recurrent network that localizes sound in the frontal azimuthal plane for noisy reverberant binaural signals is introduced. The model incorporates additive internal ear noise to represent the frequency-dependent hearing threshold of a typical listener. The localization performance of the model is compared with the steered response power algorithm, and the use of the model as a measure of interaural cue preservation for binaural speech enhancement methods is studied. A listening test was performed to compare the performance of the model with human localization of speech in noisy conditions.
Steered Response Power for Sound Source Localization: A Tutorial Review
May 05, 2024In the last three decades, the Steered Response Power (SRP) method has been widely used for the task of Sound Source Localization (SSL), due to its satisfactory localization performance on moderately reverberant and noisy scenarios. Many works have analyzed and extended the original SRP method to reduce its computational cost, to allow it to locate multiple sources, or to improve its performance in adverse environments. In this work, we review over 200 papers on the SRP method and its variants, with emphasis on the SRP-PHAT method. We also present eXtensible-SRP, or X-SRP, a generalized and modularized version of the SRP algorithm which allows the reviewed extensions to be implemented. We provide a Python implementation of the algorithm which includes selected extensions from the literature.
The Neural-SRP method for positional sound source localization
Mar 14, 2024



Steered Response Power (SRP) is a widely used method for the task of sound source localization using microphone arrays, showing satisfactory localization performance on many practical scenarios. However, its performance is diminished under highly reverberant environments. Although Deep Neural Networks (DNNs) have been previously proposed to overcome this limitation, most are trained for a specific number of microphones with fixed spatial coordinates. This restricts their practical application on scenarios frequently observed in wireless acoustic sensor networks, where each application has an ad-hoc microphone topology. We propose Neural-SRP, a DNN which combines the flexibility of SRP with the performance gains of DNNs. We train our network using simulated data and transfer learning, and evaluate our approach on recorded and simulated data. Results verify that Neural-SRP's localization performance significantly outperforms the baselines.
Binaural Speech Enhancement Using Deep Complex Convolutional Transformer Networks
Mar 08, 2024



Studies have shown that in noisy acoustic environments, providing binaural signals to the user of an assistive listening device may improve speech intelligibility and spatial awareness. This paper presents a binaural speech enhancement method using a complex convolutional neural network with an encoder-decoder architecture and a complex multi-head attention transformer. The model is trained to estimate individual complex ratio masks in the time-frequency domain for the left and right-ear channels of binaural hearing devices. The model is trained using a novel loss function that incorporates the preservation of spatial information along with speech intelligibility improvement and noise reduction. Simulation results for acoustic scenarios with a single target speaker and isotropic noise of various types show that the proposed method improves the estimated binaural speech intelligibility and preserves the binaural cues better in comparison with several baseline algorithms.
Graph neural networks for sound source localization on distributed microphone networks
Jun 28, 2023Distributed Microphone Arrays (DMAs) present many challenges with respect to centralized microphone arrays. An important requirement of applications on these arrays is handling a variable number of input channels. We consider the use of Graph Neural Networks (GNNs) as a solution to this challenge. We present a localization method using the Relation Network GNN, which we show shares many similarities to classical signal processing algorithms for Sound Source Localization (SSL). We apply our method for the task of SSL and validate it experimentally using an unseen number of microphones. We test different feature extractors and show that our approach significantly outperforms classical baselines.
Binaural Speech Enhancement Using STOI-Optimal Masks
Sep 30, 2022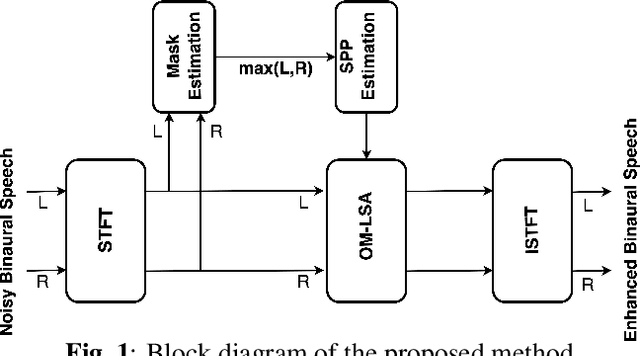
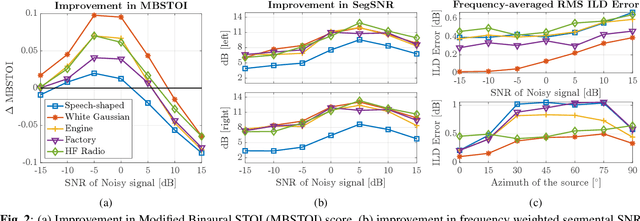
STOI-optimal masking has been previously proposed and developed for single-channel speech enhancement. In this paper, we consider the extension to the task of binaural speech enhancement in which spatial information is known to be important to speech understanding and therefore should be preserved by the enhancement processing. Masks are estimated for each of the binaural channels individually and a `better-ear listening' mask is computed by choosing the maximum of the two masks. The estimated mask is used to supply probability information about the speech presence in each time-frequency bin to an Optimally-modified Log Spectral Amplitude (OM-LSA) enhancer. We show that using the proposed method for binaural signals with a directional noise not only improves the SNR of the noisy signal but also preserves the binaural cues and intelligibility.