 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hybridization of filter and wrapper approaches for the dimensionality reduction and classification of hyperspectral images
Oct 29, 2022

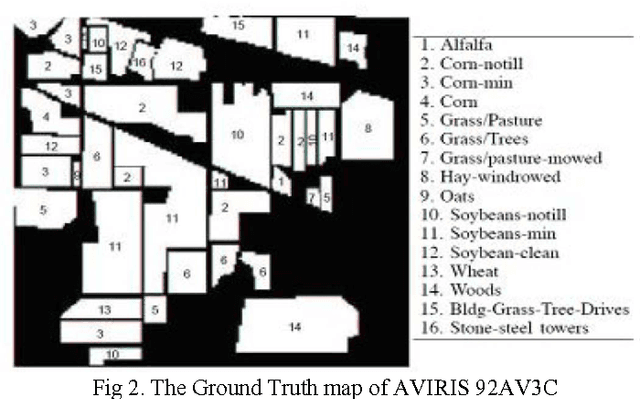
The high dimensionality of hyperspectral images often imposes a heavy computational burden for image processing. Therefore, dimensionality reduction is often an essential step in order to remove the irrelevant, noisy and redundant bands. And consequently, increase the classification accuracy. However, identification of useful bands from hundreds or even thousands of related bands is a nontrivial task. This paper aims at identifying a small set of bands, for improving computational speed and prediction accuracy. Hence, we have proposed a hybrid algorithm through band selection for dimensionality reduction of hyperspectral images. The proposed approach combines mutual information gain (MIG), Minimum Redundancy Maximum Relevance (mRMR) and Error probability of Fano with Support Vector Machine Bands Elimination (SVM-PF). The proposed approach is compared to an effective reproduced filters approach based on mutual information. Experimental results on HSI AVIRIS 92AV3C have shown that the proposed approach outperforms the reproduced filters. Keywords - Hyperspectral images, Classification, band Selection, filter, wrapper, mutual information, information gain.
Multimodal Transformer for Parallel Concatenated Variational Autoencoders
Oct 28, 2022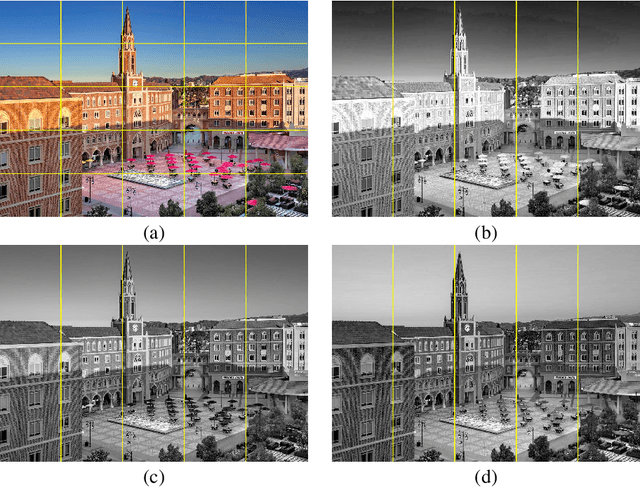
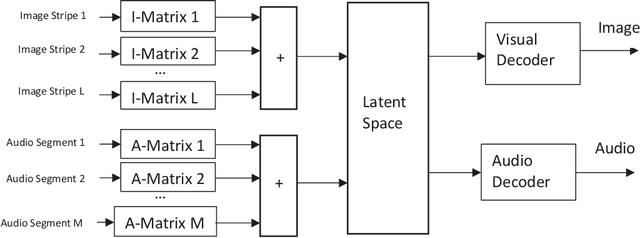
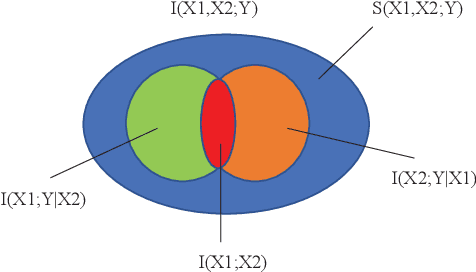

In this paper, we propose a multimodal transformer using parallel concatenated architecture. Instead of using patches, we use column stripes for images in R, G, B channels as the transformer input. The column stripes keep the spatial relations of original image. We incorporate the multimodal transformer with variational autoencoder for synthetic cross-modal data generation. The multimodal transformer is designed using multiple compression matrices, and it serves as encoders for Parallel Concatenated Variational AutoEncoders (PC-VAE). The PC-VAE consists of multiple encoders, one latent space, and two decoders. The encoders are based on random Gaussian matrices and don't need any training. We propose a new loss function based on the interaction information from partial information decomposition. The interaction information evaluates the input cross-modal information and decoder output. The PC-VAE are trained via minimizing the loss function. Experiments are performed to validate the proposed multimodal transformer for PC-VAE.
Non-parallel Accent Conversion using Pseudo Siamese Disentanglement Network
Dec 12, 2022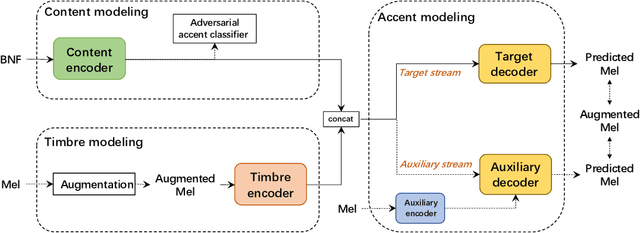
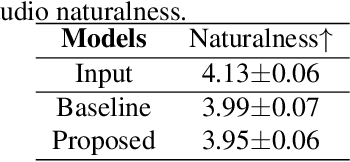
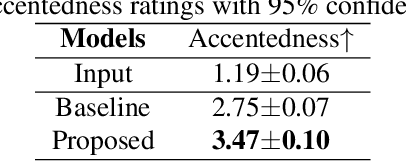
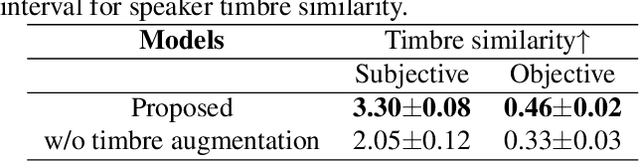
The main goal of accent conversion (AC) is to convert the accent of speech into the target accent while preserving the content and timbre. Previous reference-based methods rely on reference utterances in the inference phase, which limits their practical application. What's more, previous reference-free methods mostly require parallel data in the training phase. In this paper, we propose a reference-free method based on non-parallel data from the perspective of feature disentanglement. Pseudo Siamese Disentanglement Network (PSDN) is proposed to disentangle the accent information from the content representation and model the target accent. Besides, a timbre augmentation method is proposed to enhance the ability of timbre retaining for speakers without target-accent data. Experimental results show that the proposed system can convert the accent of native American English speech into Indian accent with higher accentedness (3.47) than the baseline (2.75) and input (1.19). The naturalness of converted speech is also comparable to that of the input.
Earthquake Impact Analysis Based on Text Mining and Social Media Analytics
Dec 12, 2022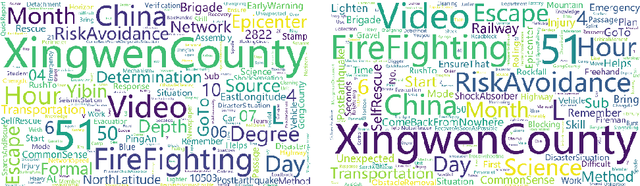
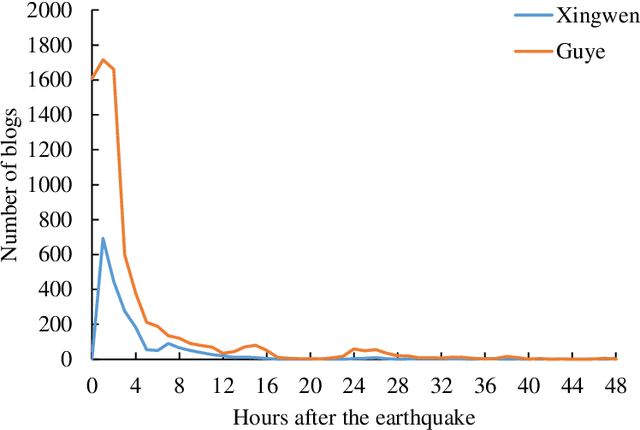
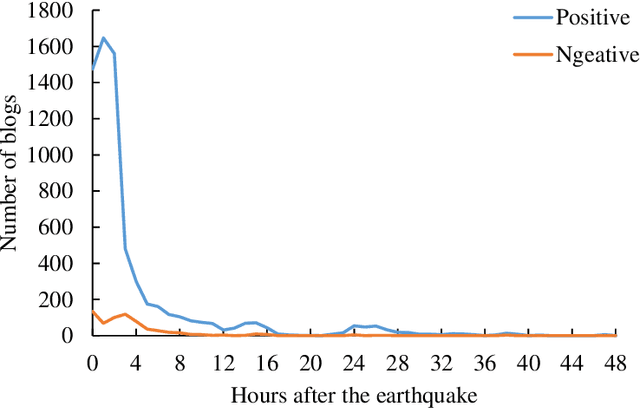
Earthquakes have a deep impact on wide areas, and emergency rescue operations may benefit from social media information about the scope and extent of the disaster. Therefore, this work presents a text miningbased approach to collect and analyze social media data for early earthquake impact analysis. First, disasterrelated microblogs are collected from the Sina microblog based on crawler technology. Then, after data cleaning a series of analyses are conducted including (1) the hot words analysis, (2) the trend of the number of microblogs, (3) the trend of public opinion sentiment, and (4) a keyword and rule-based text classification for earthquake impact analysis. Finally, two recent earthquakes with the same magnitude and focal depth in China are analyzed to compare their impacts. The results show that the public opinion trend analysis and the trend of public opinion sentiment can estimate the earthquake's social impact at an early stage, which will be helpful to decision-making and rescue management.
Cross-view Graph Contrastive Representation Learning on Partially Aligned Multi-view Data
Nov 08, 2022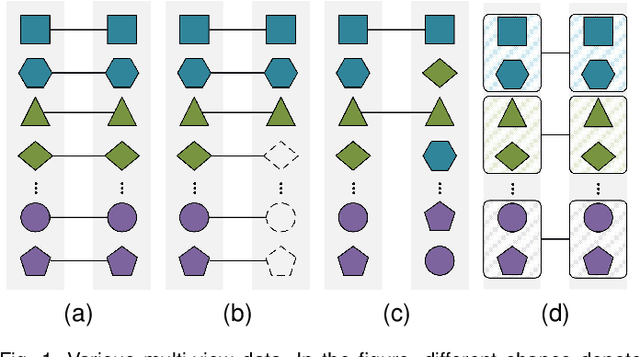

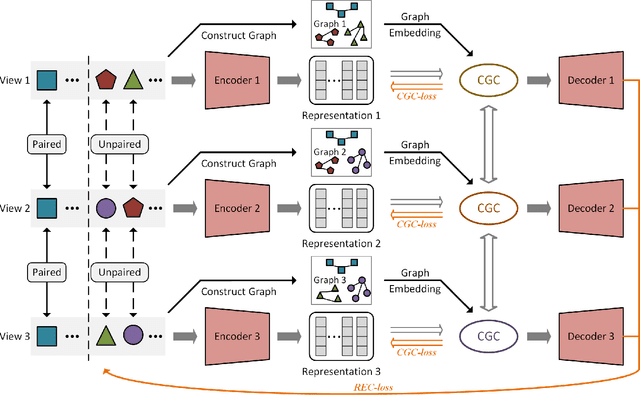
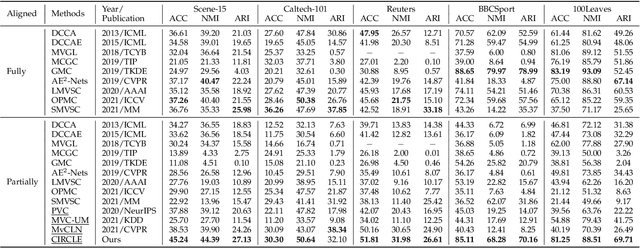
Multi-view representation learning has developed rapidly over the past decades and has been applied in many fields. However, most previous works assumed that each view is complete and aligned. This leads to an inevitable deterioration in their performance when encountering practical problems such as missing or unaligned views. To address the challenge of representation learning on partially aligned multi-view data, we propose a new cross-view graph contrastive learning framework, which integrates multi-view information to align data and learn latent representations. Compared with current approaches, the proposed method has the following merits: (1) our model is an end-to-end framework that simultaneously performs view-specific representation learning via view-specific autoencoders and cluster-level data aligning by combining multi-view information with the cross-view graph contrastive learning; (2) it is easy to apply our model to explore information from three or more modalities/sources as the cross-view graph contrastive learning is devised. Extensive experiments conducted on several real datasets demonstrate the effectiveness of the proposed method on the clustering and classification tasks.
MSLKANet: A Multi-Scale Large Kernel Attention Network for Scene Text Removal
Nov 12, 2022
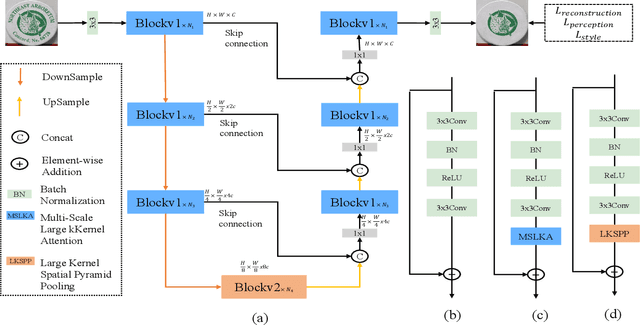
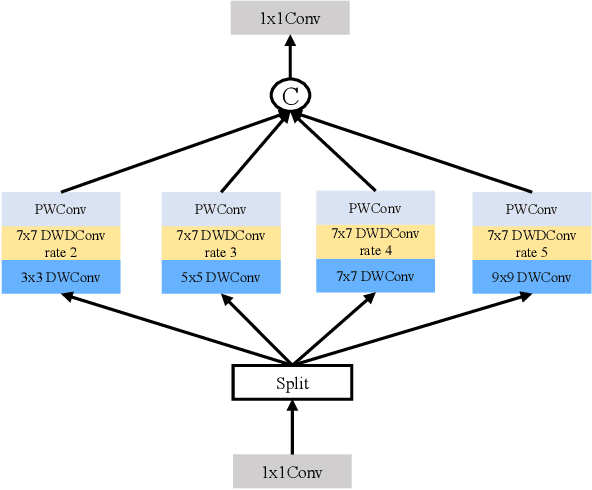

Scene text removal aims to remove the text and fill the regions with perceptually plausible background information in natural images. It has attracted increasing attention due to its various applications in privacy protection, scene text retrieval, and text editing. With the development of deep learning, the previous methods have achieved significant improvements. However, most of the existing methods seem to ignore the large perceptive fields and global information. The pioneer method can get significant improvements by only changing training data from the cropped image to the full image. In this paper, we present a single-stage multi-scale network MSLKANet for scene text removal in full images. For obtaining large perceptive fields and global information, we propose multi-scale large kernel attention (MSLKA) to obtain long-range dependencies between the text regions and the backgrounds at various granularity levels. Furthermore, we combine the large kernel decomposition mechanism and atrous spatial pyramid pooling to build a large kernel spatial pyramid pooling (LKSPP), which can perceive more valid pixels in the spatial dimension while maintaining large receptive fields and low cost of computation. Extensive experimental results indicate that the proposed method achieves state-of-the-art performance on both synthetic and real-world datasets and the effectiveness of the proposed components MSLKA and LKSPP.
Inv-SENnet: Invariant Self Expression Network for clustering under biased data
Nov 13, 2022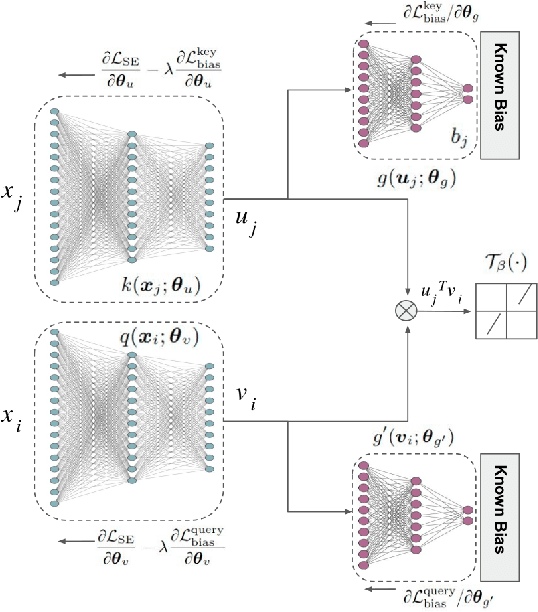
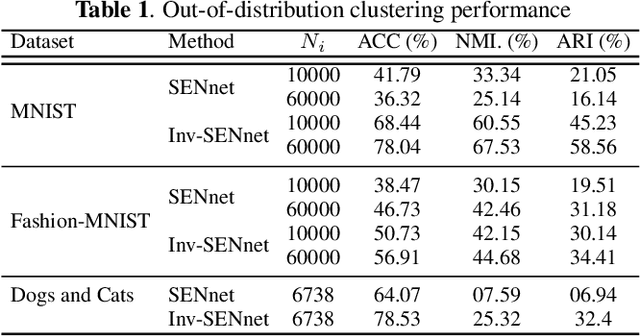

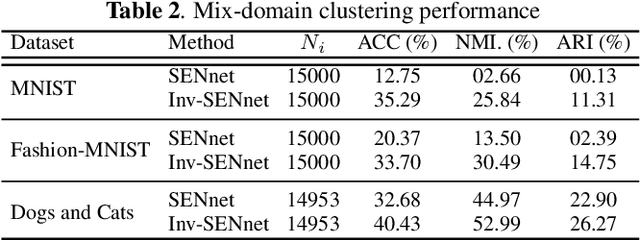
Subspace clustering algorithms are used for understanding the cluster structure that explains the dataset well. These methods are extensively used for data-exploration tasks in various areas of Natural Sciences. However, most of these methods fail to handle unwanted biases in datasets. For datasets where a data sample represents multiple attributes, naively applying any clustering approach can result in undesired output. To this end, we propose a novel framework for jointly removing unwanted attributes (biases) while learning to cluster data points in individual subspaces. Assuming we have information about the bias, we regularize the clustering method by adversarially learning to minimize the mutual information between the data and the unwanted attributes. Our experimental result on synthetic and real-world datasets demonstrate the effectiveness of our approach.
Discriminability-Transferability Trade-Off: An Information-Theoretic Perspective
Mar 08, 2022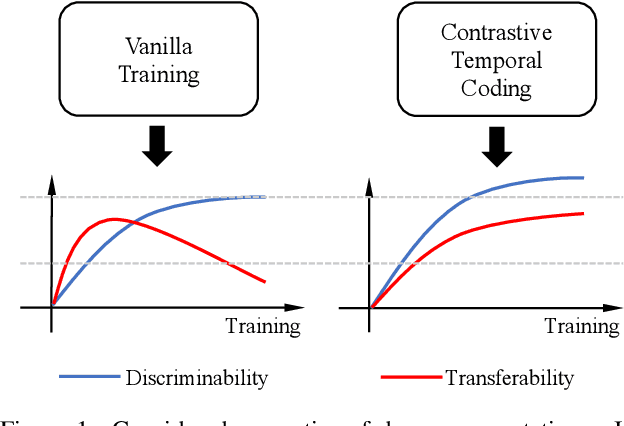

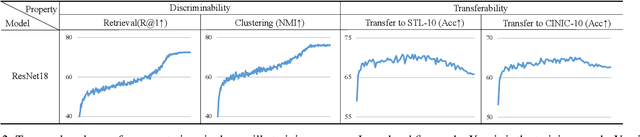

This work simultaneously considers the discriminability and transferability properties of deep representations in the typical supervised learning task, i.e., image classification. By a comprehensive temporal analysis, we observe a trade-off between these two properties. The discriminability keeps increasing with the training progressing while the transferability intensely diminishes in the later training period. From the perspective of information-bottleneck theory, we reveal that the incompatibility between discriminability and transferability is attributed to the over-compression of input information. More importantly, we investigate why and how the InfoNCE loss can alleviate the over-compression, and further present a learning framework, named contrastive temporal coding~(CTC), to counteract the over-compression and alleviate the incompatibility. Extensive experiments validate that CTC successfully mitigates the incompatibility, yielding discriminative and transferable representations. Noticeable improvements are achieved on the image classification task and challenging transfer learning tasks. We hope that this work will raise the significance of the transferability property in the conventional supervised learning setting. Code will be publicly available.
PointCA: Evaluating the Robustness of 3D Point Cloud Completion Models Against Adversarial Examples
Dec 01, 2022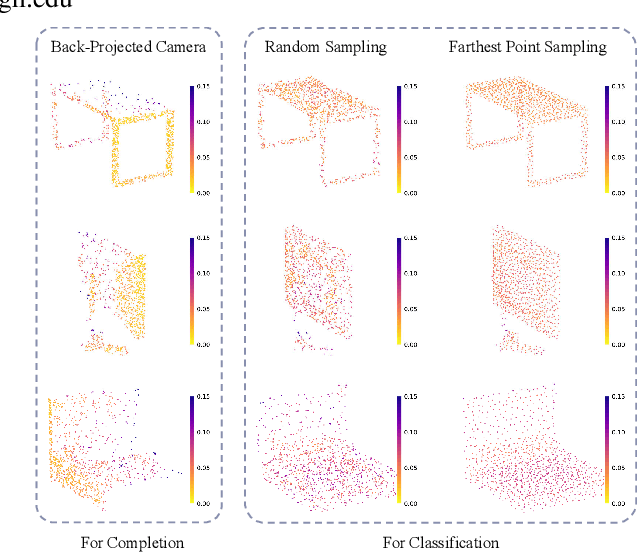
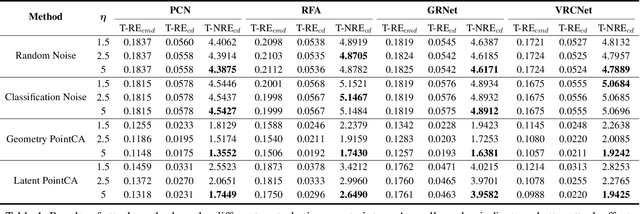


Point cloud completion, as the upstream procedure of 3D recognition and segmentation, has become an essential part of many tasks such as navigation and scene understanding. While various point cloud completion models have demonstrated their powerful capabilities, their robustness against adversarial attacks, which have been proven to be fatally malicious towards deep neural networks, remains unknown. In addition, existing attack approaches towards point cloud classifiers cannot be applied to the completion models due to different output forms and attack purposes. In order to evaluate the robustness of the completion models, we propose PointCA, the first adversarial attack against 3D point cloud completion models. PointCA can generate adversarial point clouds that maintain high similarity with the original ones, while being completed as another object with totally different semantic information. Specifically, we minimize the representation discrepancy between the adversarial example and the target point set to jointly explore the adversarial point clouds in the geometry space and the feature space. Furthermore, to launch a stealthier attack, we innovatively employ the neighbourhood density information to tailor the perturbation constraint, leading to geometry-aware and distribution-adaptive modifications for each point. Extensive experiments against different premier point cloud completion networks show that PointCA can cause a performance degradation from 77.9% to 16.7%, with the structure chamfer distance kept below 0.01. We conclude that existing completion models are severely vulnerable to adversarial examples, and state-of-the-art defenses for point cloud classification will be partially invalid when applied to incomplete and uneven point cloud data.
LEDCNet: A Lightweight and Efficient Semantic Segmentation Algorithm Using Dual Context Module for Extracting Ground Objects from UAV Aerial Remote Sensing Images
Dec 27, 2022
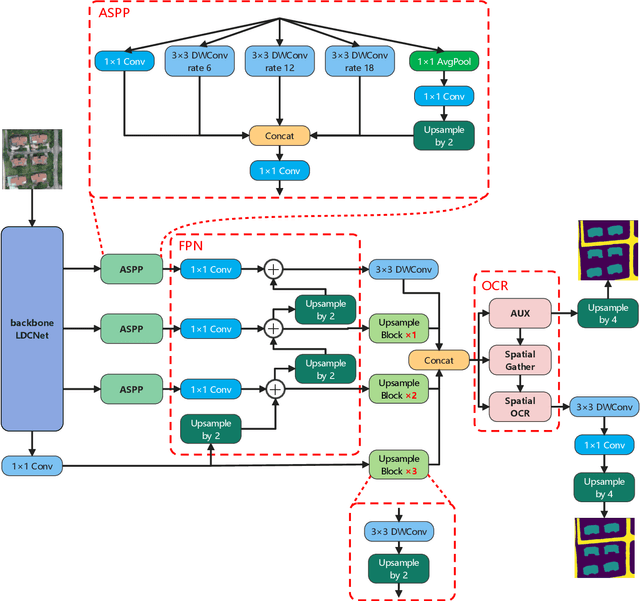
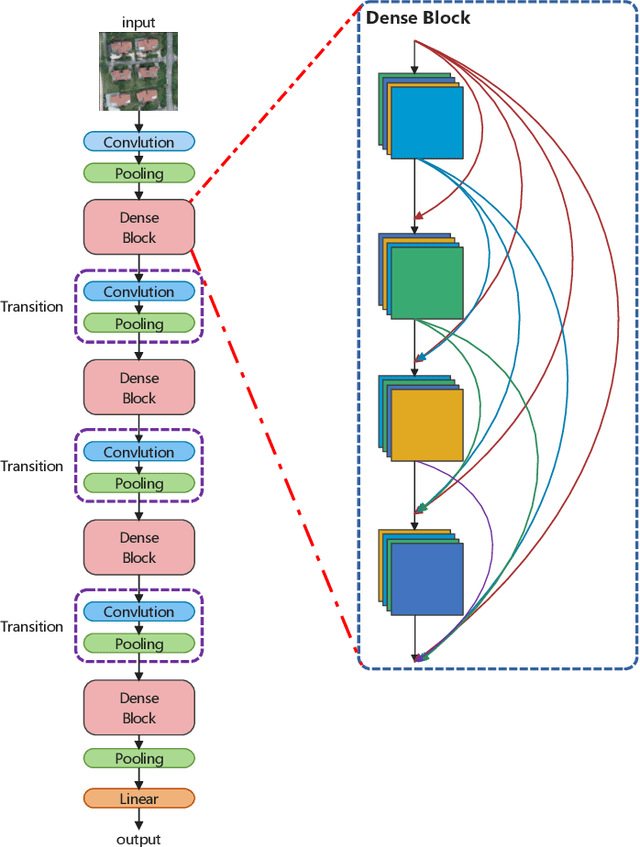
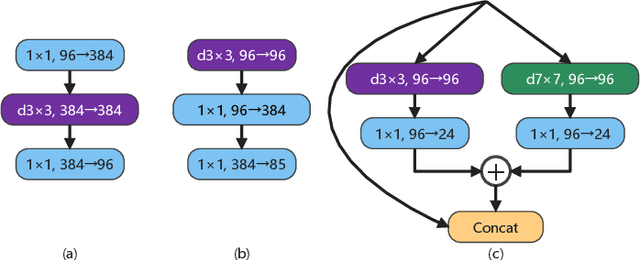
Semantic segmentation for extracting ground objects, such as road and house, from UAV remote sensing images by deep learning becomes a more efficient and convenient method than traditional manual segmentation in surveying and mapping field. In recent years, with the deepening of layers and boosting of complexity, the number of parameters in convolution-based semantic segmentation neural networks considerably increases, which is obviously not conducive to the wide application especially in the industry. In order to make the model lightweight and improve the model accuracy, a new lightweight and efficient network for the extraction of ground objects from UAV remote sensing images, named LEDCNet, is proposed. The proposed network adopts an encoder-decoder architecture in which a powerful lightweight backbone network called LDCNet is developed as the encoder. We would extend the LDCNet become a new generation backbone network of lightweight semantic segmentation algorithms. In the decoder part, the dual multi-scale context modules which consist of the ASPP module and the OCR module are designed to capture more context information from feature maps of UAV remote sensing images. Between ASPP and OCR, a FPN module is used to and fuse multi-scale features extracting from ASPP. A private dataset of remote sensing images taken by UAV which contains 2431 training sets, 945 validation sets, and 475 test sets is constructed. The proposed model performs well on this dataset, with only 1.4M parameters and 5.48G FLOPs, achieving an mIoU of 71.12%. The more extensive experiments on the public LoveDA dataset and CITY-OSM dataset to further verify the effectiveness of the proposed model with excellent results on mIoU of 65.27% and 74.39%, respectively. All the experimental results show the proposed model can not only lighten the network with few parameters but also improve the segmentation performance.