 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne for all: A novel Dual-space Co-training baseline for Large-scale Multi-View Clustering
Jan 28, 2024In this paper, we propose a novel multi-view clustering model, named Dual-space Co-training Large-scale Multi-view Clustering (DSCMC). The main objective of our approach is to enhance the clustering performance by leveraging co-training in two distinct spaces. In the original space, we learn a projection matrix to obtain latent consistent anchor graphs from different views. This process involves capturing the inherent relationships and structures between data points within each view. Concurrently, we employ a feature transformation matrix to map samples from various views to a shared latent space. This transformation facilitates the alignment of information from multiple views, enabling a comprehensive understanding of the underlying data distribution. We jointly optimize the construction of the latent consistent anchor graph and the feature transformation to generate a discriminative anchor graph. This anchor graph effectively captures the essential characteristics of the multi-view data and serves as a reliable basis for subsequent clustering analysis. Moreover, the element-wise method is proposed to avoid the impact of diverse information between different views. Our algorithm has an approximate linear computational complexity, which guarantees its successful application on large-scale datasets. Through experimental validation, we demonstrate that our method significantly reduces computational complexity while yielding superior clustering performance compared to existing approaches.
Cross-view Graph Contrastive Representation Learning on Partially Aligned Multi-view Data
Nov 08, 2022Multi-view representation learning has developed rapidly over the past decades and has been applied in many fields. However, most previous works assumed that each view is complete and aligned. This leads to an inevitable deterioration in their performance when encountering practical problems such as missing or unaligned views. To address the challenge of representation learning on partially aligned multi-view data, we propose a new cross-view graph contrastive learning framework, which integrates multi-view information to align data and learn latent representations. Compared with current approaches, the proposed method has the following merits: (1) our model is an end-to-end framework that simultaneously performs view-specific representation learning via view-specific autoencoders and cluster-level data aligning by combining multi-view information with the cross-view graph contrastive learning; (2) it is easy to apply our model to explore information from three or more modalities/sources as the cross-view graph contrastive learning is devised. Extensive experiments conducted on several real datasets demonstrate the effectiveness of the proposed method on the clustering and classification tasks.
ACTIVE:Augmentation-Free Graph Contrastive Learning for Partial Multi-View Clustering
Mar 01, 2022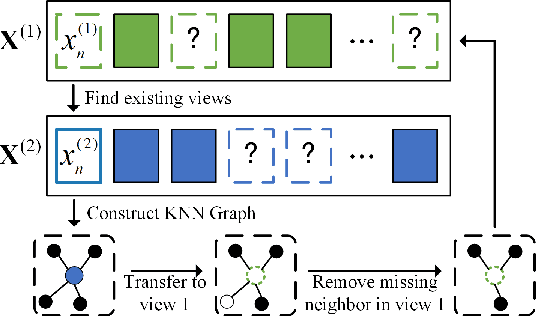
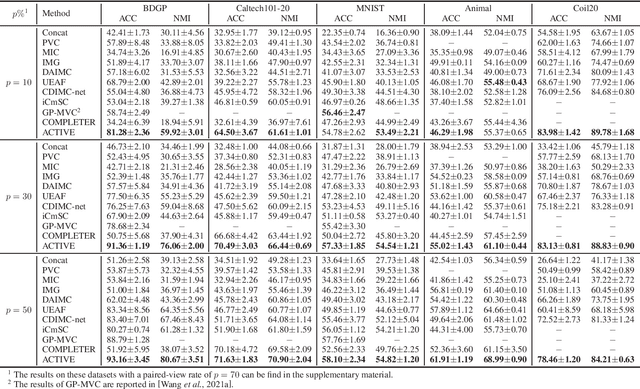
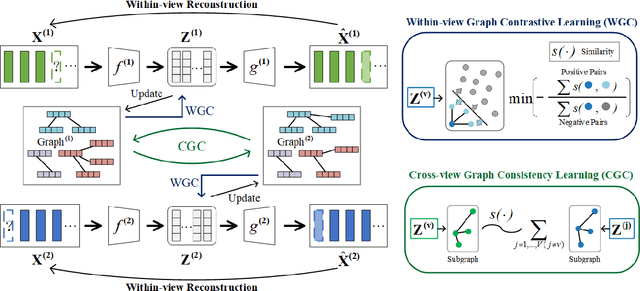
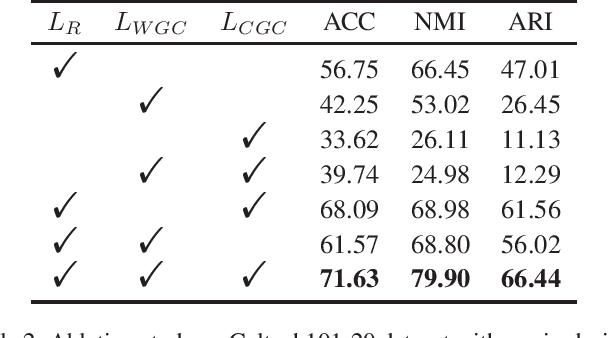
In this paper, we propose an augmentation-free graph contrastive learning framework, namely ACTIVE, to solve the problem of partial multi-view clustering. Notably, we suppose that the representations of similar samples (i.e., belonging to the same cluster) and their multiply views features should be similar. This is distinct from the general unsupervised contrastive learning that assumes an image and its augmentations share a similar representation. Specifically, relation graphs are constructed using the nearest neighbours to identify existing similar samples, then the constructed inter-instance relation graphs are transferred to the missing views to build graphs on the corresponding missing data. Subsequently, two main components, within-view graph contrastive learning (WGC) and cross-view graph consistency learning (CGC), are devised to maximize the mutual information of different views within a cluster. The proposed approach elevates instance-level contrastive learning and missing data inference to the cluster-level, effectively mitigating the impact of individual missing data on clustering. Experiments on several challenging datasets demonstrate the superiority of our proposed methods.
Incomplete Multi-view Clustering via Cross-view Relation Transfer
Dec 01, 2021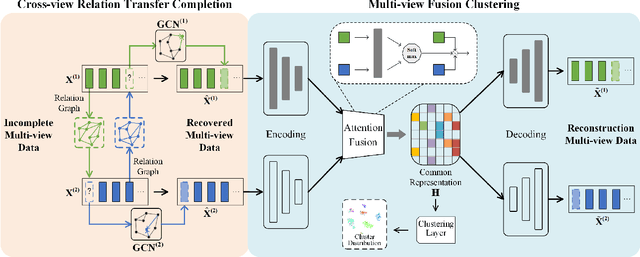
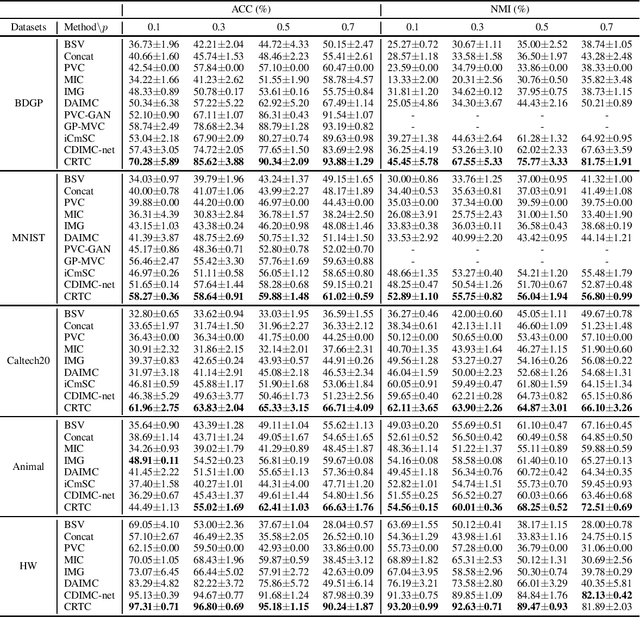
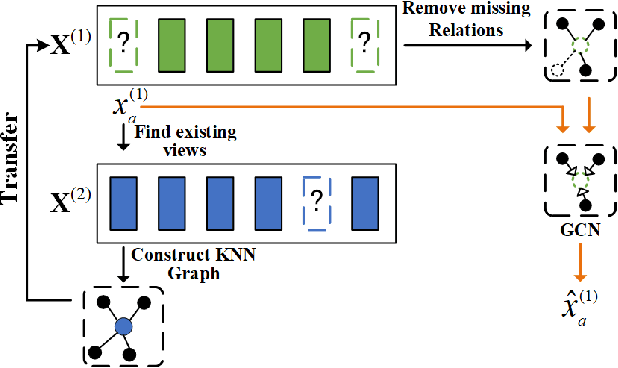

In this paper, we consider the problem of multi-view clustering on incomplete views. Compared with complete multi-view clustering, the view-missing problem increases the difficulty of learning common representations from different views. To address the challenge, we propose a novel incomplete multi-view clustering framework, which incorporates cross-view relation transfer and multi-view fusion learning. Specifically, based on the consistency existing in multi-view data, we devise a cross-view relation transfer-based completion module, which transfers known similar inter-instance relationships to the missing view and recovers the missing data via graph networks based on the transferred relationship graph. Then the view-specific encoders are designed to extract the recovered multi-view data, and an attention-based fusion layer is introduced to obtain the common representation. Moreover, to reduce the impact of the error caused by the inconsistency between views and obtain a better clustering structure, a joint clustering layer is introduced to optimize recovery and clustering simultaneously. Extensive experiments conducted on several real datasets demonstrate the effectiveness of the proposed method.
Consistent Multiple Graph Embedding for Multi-View Clustering
May 11, 2021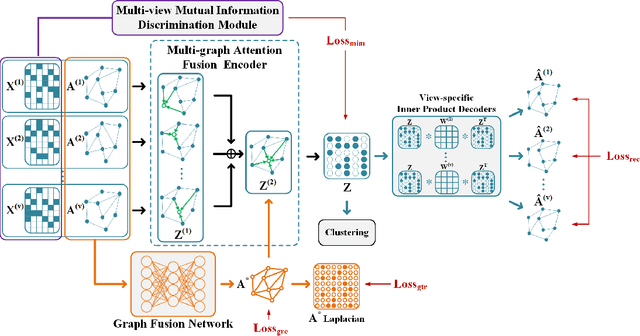
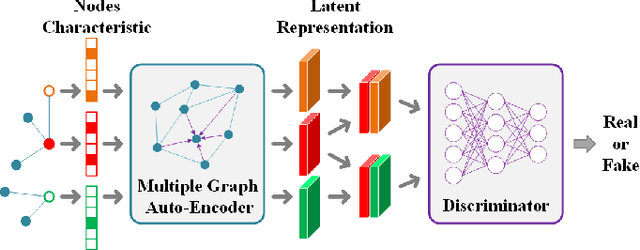

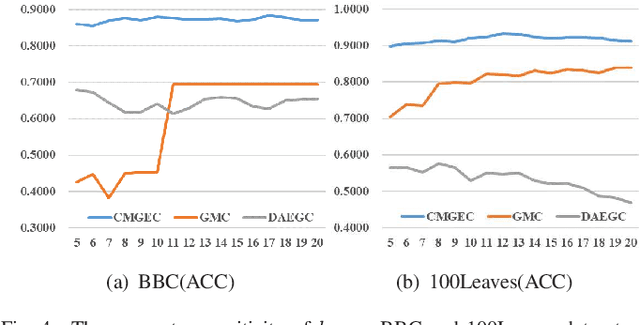
Graph-based multi-view clustering aiming to obtain a partition of data across multiple views, has received considerable attention in recent years. Although great efforts have been made for graph-based multi-view clustering, it remains a challenge to fuse characteristics from various views to learn a common representation for clustering. In this paper, we propose a novel Consistent Multiple Graph Embedding Clustering framework(CMGEC). Specifically, a multiple graph auto-encoder(M-GAE) is designed to flexibly encode the complementary information of multi-view data using a multi-graph attention fusion encoder. To guide the learned common representation maintaining the similarity of the neighboring characteristics in each view, a Multi-view Mutual Information Maximization module(MMIM) is introduced. Furthermore, a graph fusion network(GFN) is devised to explore the relationship among graphs from different views and provide a common consensus graph needed in M-GAE. By jointly training these models, the common latent representation can be obtained which encodes more complementary information from multiple views and depicts data more comprehensively. Experiments on three types of multi-view datasets demonstrate CMGEC outperforms the state-of-the-art clustering methods.
Auto-weighted low-rank representation for clustering
Apr 26, 2021
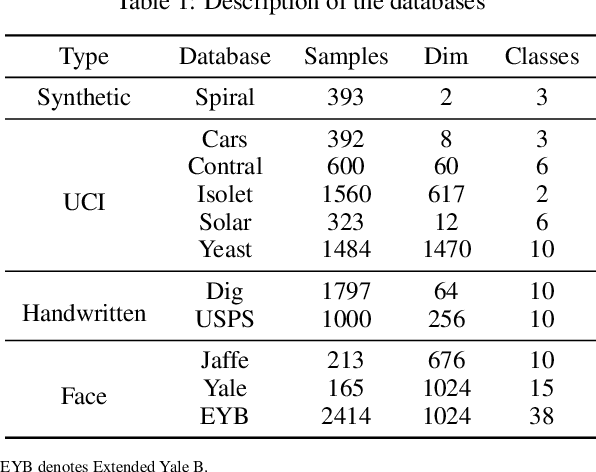

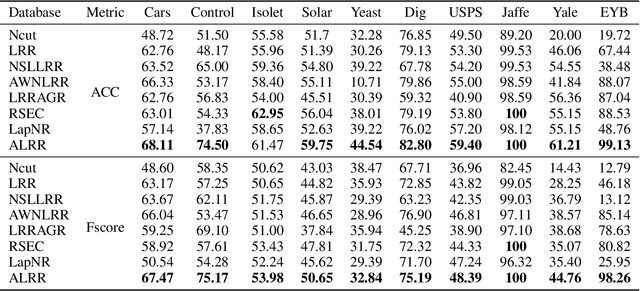
In this paper, a novel unsupervised low-rank representation model, i.e., Auto-weighted Low-Rank Representation (ALRR), is proposed to construct a more favorable similarity graph (SG) for clustering. In particular, ALRR enhances the discriminability of SG by capturing the multi-subspace structure and extracting the salient features simultaneously. Specifically, an auto-weighted penalty is introduced to learn a similarity graph by highlighting the effective features, and meanwhile, overshadowing the disturbed features. Consequently, ALRR obtains a similarity graph that can preserve the intrinsic geometrical structures within the data by enforcing a smaller similarity on two dissimilar samples. Moreover, we employ a block-diagonal regularizer to guarantee the learned graph contains $k$ diagonal blocks. This can facilitate a more discriminative representation learning for clustering tasks. Extensive experimental results on synthetic and real databases demonstrate the superiority of ALRR over other state-of-the-art methods with a margin of 1.8\%$\sim$10.8\%.