 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A deep local attention network for pre-operative lymph node metastasis prediction in pancreatic cancer via multiphase CT imaging
Jan 04, 2023
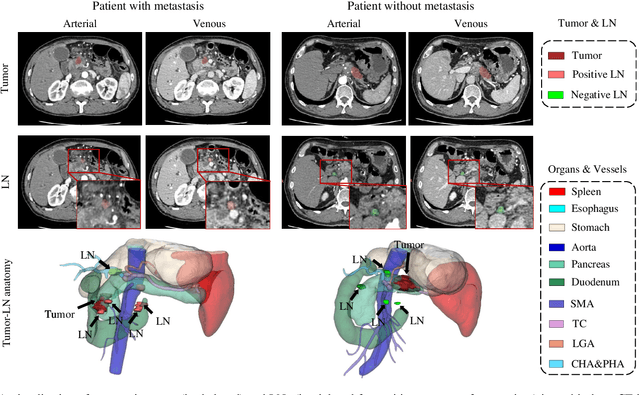
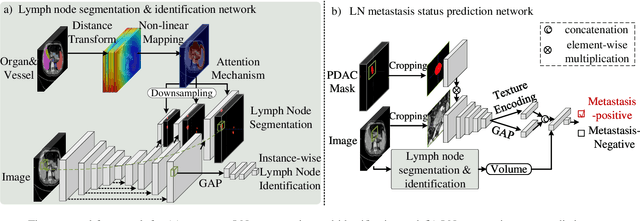
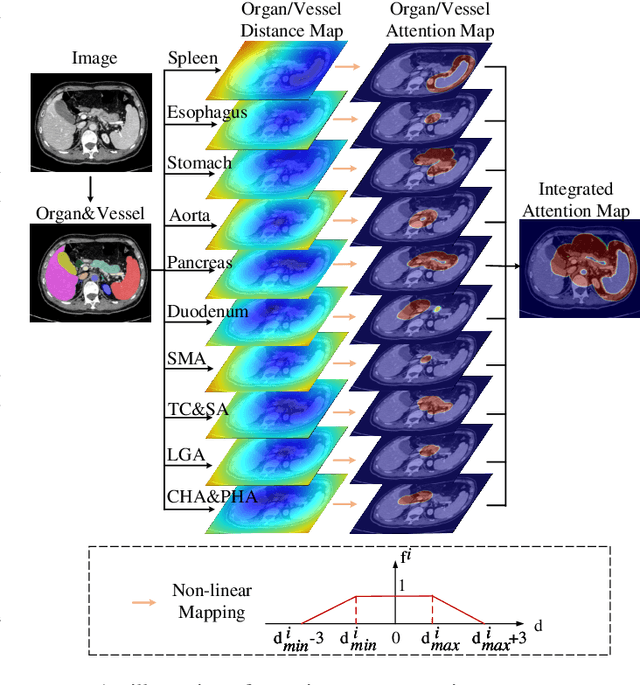
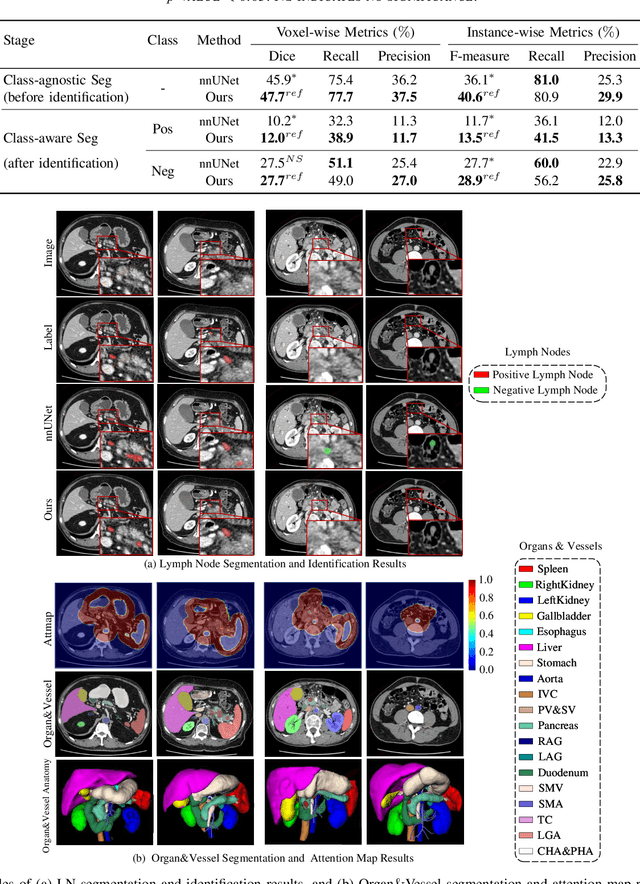
Lymph node (LN) metastasis status is one of the most critical prognostic and cancer staging factors for patients with resectable pancreatic ductal adenocarcinoma (PDAC), or in general, for any types of solid malignant tumors. Preoperative prediction of LN metastasis from non-invasive CT imaging is highly desired, as it might be straightforwardly used to guide the following neoadjuvant treatment decision and surgical planning. Most studies only capture the tumor characteristics in CT imaging to implicitly infer LN metastasis and very few work exploit direct LN's CT imaging information. To the best of our knowledge, this is the first work to propose a fully-automated LN segmentation and identification network to directly facilitate the LN metastasis status prediction task. Nevertheless LN segmentation/detection is very challenging since LN can be easily confused with other hard negative anatomic structures (e.g., vessels) from radiological images. We explore the anatomical spatial context priors of pancreatic LN locations by generating a guiding attention map from related organs and vessels to assist segmentation and infer LN status. As such, LN segmentation is impelled to focus on regions that are anatomically adjacent or plausible with respect to the specific organs and vessels. The metastasized LN identification network is trained to classify the segmented LN instances into positives or negatives by reusing the segmentation network as a pre-trained backbone and padding a new classification head. More importantly, we develop a LN metastasis status prediction network that combines the patient-wise aggregation results of LN segmentation/identification and deep imaging features extracted from the tumor region. Extensive quantitative nested five-fold cross-validation is conducted on a discovery dataset of 749 patients with PDAC.
Inducing Character-level Structure in Subword-based Language Models with Type-level Interchange Intervention Training
Dec 19, 2022

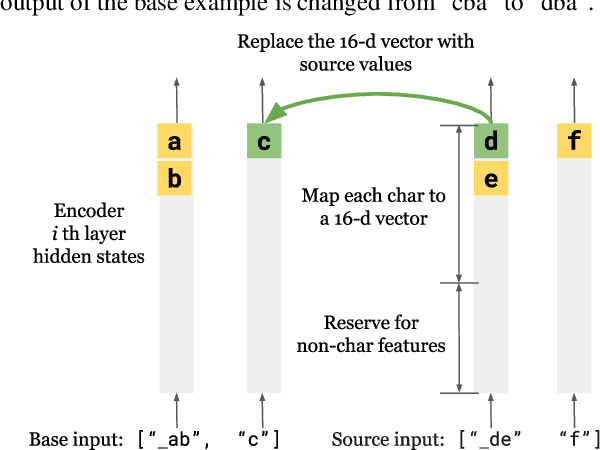

Language tasks involving character-level manipulations (e.g., spelling correction, many word games) are challenging for models based in subword tokenization. To address this, we adapt the interchange intervention training method of Geiger et al. (2021) to operate on type-level variables over characters. This allows us to encode robust, position-independent character-level information in the internal representations of subword-based models. We additionally introduce a suite of character-level tasks that systematically vary in their dependence on meaning and sequence-level context. While simple character-level tokenization approaches still perform best on purely form-based tasks like string reversal, our method is superior for more complex tasks that blend form, meaning, and context, such as spelling correction in context and word search games. Our approach also leads to subword-based models with human-intepretable internal representations of characters.
Positive-incentive Noise
Dec 19, 2022

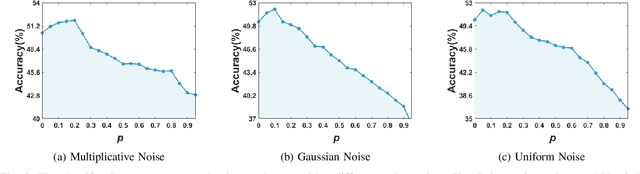

Noise is conventionally viewed as a severe problem in diverse fields, e.g., engineering, learning systems. However, this paper aims to investigate whether the conventional proposition always holds. It begins with the definition of task entropy, which extends from the information entropy and measures the complexity of the task. After introducing the task entropy, the noise can be classified into two kinds, Positive-incentive noise (Pi-noise or $\pi$-noise) and pure noise, according to whether the noise can reduce the complexity of the task. Interestingly, as shown theoretically and empirically, even the simple random noise can be the $\pi$-noise that simplifies the task. $\pi$-noise offers new explanations for some models and provides a new principle for some fields, such as multi-task learning, adversarial training, etc. Moreover, it reminds us to rethink the investigation of noises.
Audio-Visual Activity Guided Cross-Modal Identity Association for Active Speaker Detection
Dec 01, 2022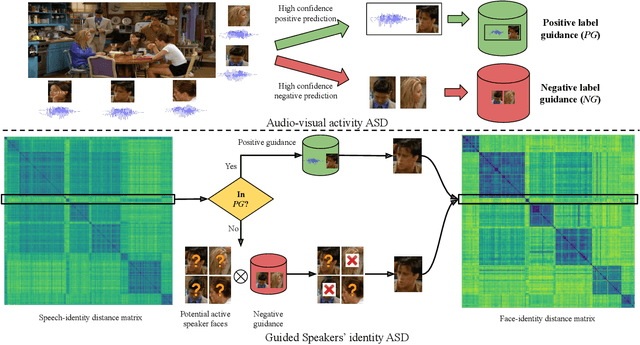
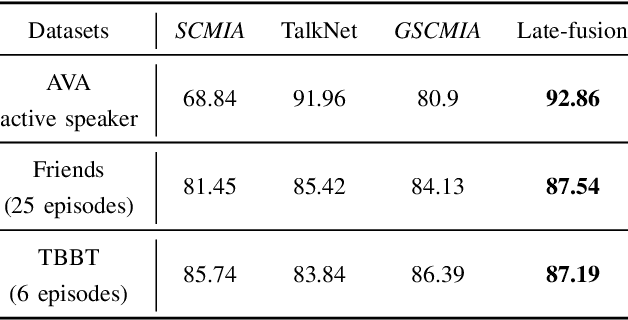
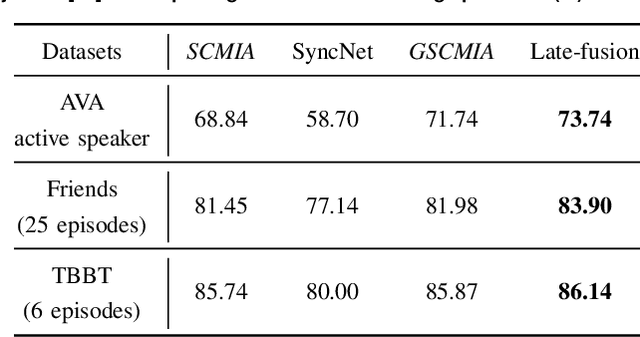
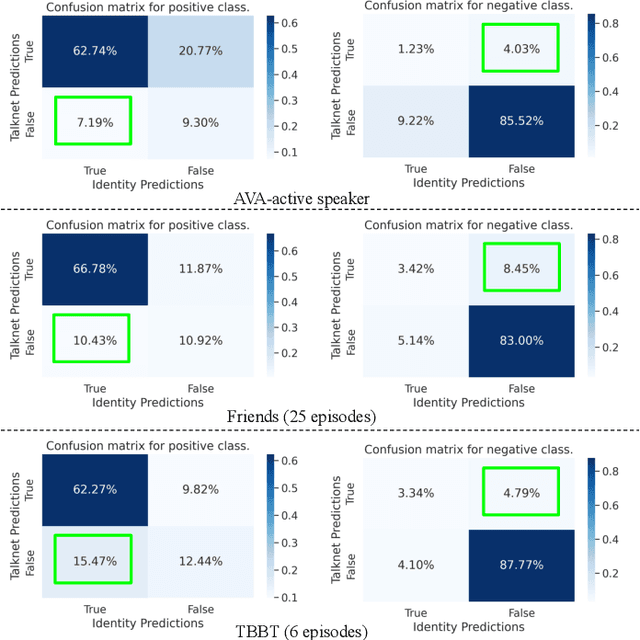
Active speaker detection in videos addresses associating a source face, visible in the video frames, with the underlying speech in the audio modality. The two primary sources of information to derive such a speech-face relationship are i) visual activity and its interaction with the speech signal and ii) co-occurrences of speakers' identities across modalities in the form of face and speech. The two approaches have their limitations: the audio-visual activity models get confused with other frequently occurring vocal activities, such as laughing and chewing, while the speakers' identity-based methods are limited to videos having enough disambiguating information to establish a speech-face association. Since the two approaches are independent, we investigate their complementary nature in this work. We propose a novel unsupervised framework to guide the speakers' cross-modal identity association with the audio-visual activity for active speaker detection. Through experiments on entertainment media videos from two benchmark datasets, the AVA active speaker (movies) and Visual Person Clustering Dataset (TV shows), we show that a simple late fusion of the two approaches enhances the active speaker detection performance.
A DRL Approach for RIS-Assisted Full-Duplex UL and DL Transmission: Beamforming, Phase Shift and Power Optimization
Dec 28, 2022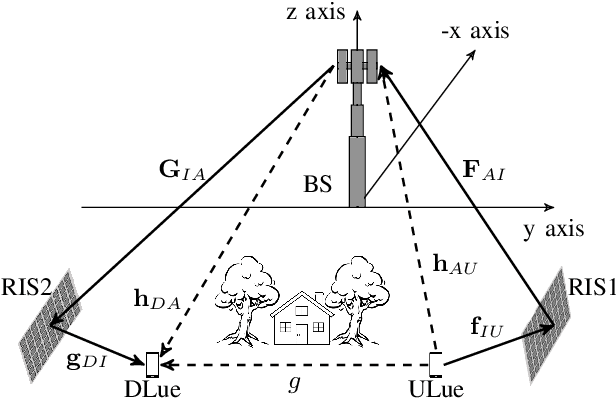
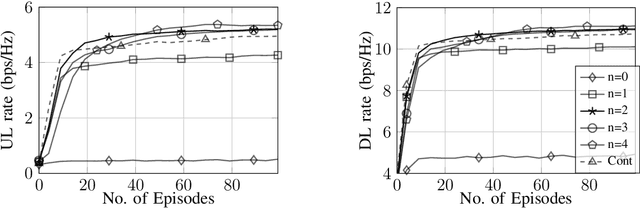
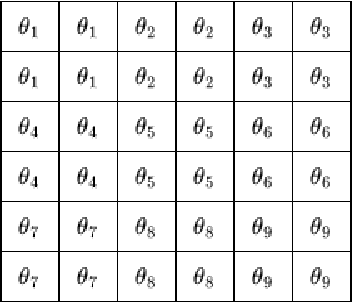
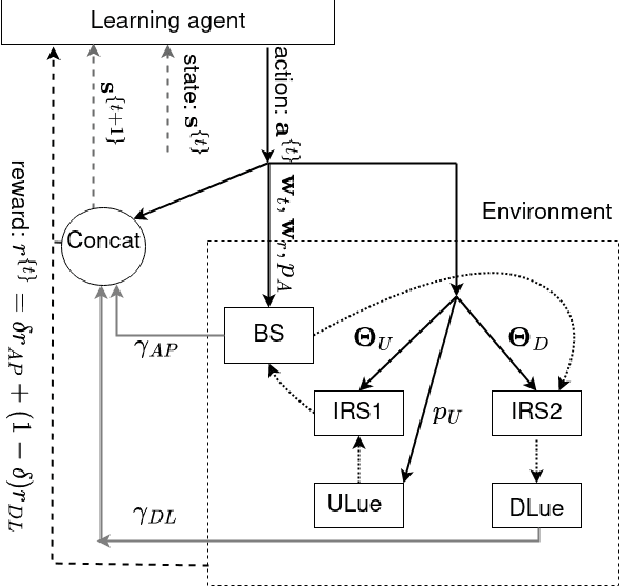
In this work, a two-stage deep reinforcement learning (DRL) approach is presented for a full-duplex (FD) transmission scenario that does not depend on the channel state information (CSI) knowledge to predict the phase-shifts of reconfigurable intelligent surface (RIS), beamformers at the base station (BS), and the transmit powers of BS and uplink users in order to maximize the weighted sum rate of uplink and downlink users. As the self-interference (SI) cancellation and beamformer design are coupled problems, the first stage uses a least squares method to partially cancel self-interference (SI) and initiate learning, while the second stage uses DRL to make predictions and achieve performance close to methods with perfect CSI knowledge. Further, to reduce the signaling from BS to the RISs, a DRL framework is proposed that predicts quantized RIS phase-shifts and beamformers using $32$ times fewer bits than the continuous version. The quantized methods have reduced action space and therefore faster convergence; with sufficient training, the UL and DL rates for the quantized phase method are $8.14\%$ and $2.45\%$ better than the continuous phase method respectively. The RIS elements can be grouped to have similar phase-shifts to further reduce signaling, at the cost of reduced performance.
Heterogeneous Graph Contrastive Learning with Meta-path Contexts and Weighted Negative Samples
Dec 28, 2022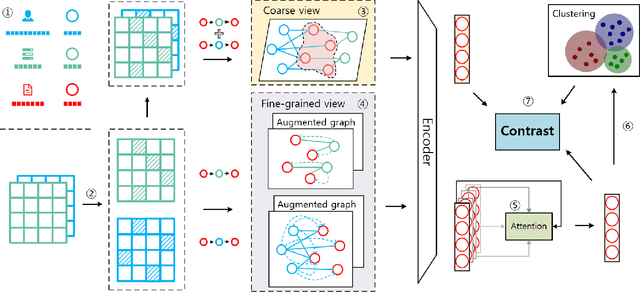
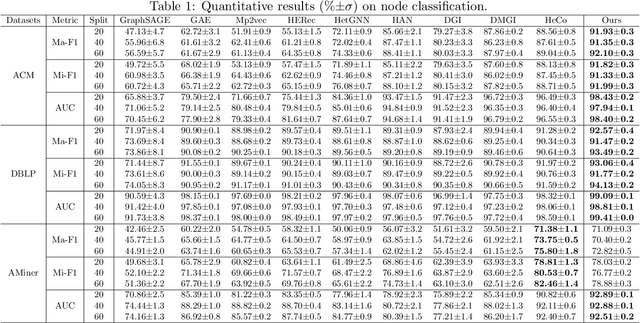
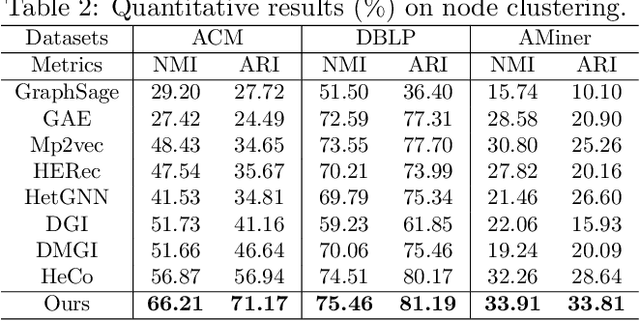
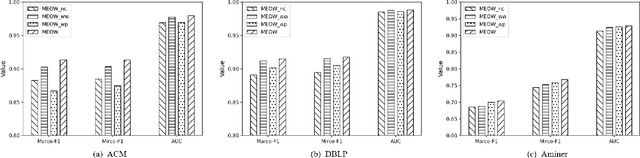
Heterogeneous graph contrastive learning has received wide attention recently. Some existing methods use meta-paths, which are sequences of object types that capture semantic relationships between objects, to construct contrastive views. However, most of them ignore the rich meta-path context information that describes how two objects are connected by meta-paths. On the other hand, they fail to distinguish hard negatives from false negatives, which could adversely affect the model performance. To address the problems, we propose MEOW, a heterogeneous graph contrastive learning model that considers both meta-path contexts and weighted negative samples. Specifically, MEOW constructs a coarse view and a fine-grained view for contrast. The former reflects which objects are connected by meta-paths, while the latter uses meta-path contexts and characterizes the details on how the objects are connected. We take node embeddings in the coarse view as anchors, and construct positive and negative samples from the fine-grained view. Further, to distinguish hard negatives from false negatives, we learn weights of negative samples based on node clustering. We also use prototypical contrastive learning to pull close embeddings of nodes in the same cluster. Finally, we conduct extensive experiments to show the superiority of MEOW against other state-of-the-art methods.
A survey on text generation using generative adversarial networks
Dec 20, 2022

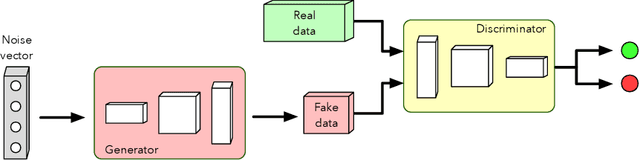
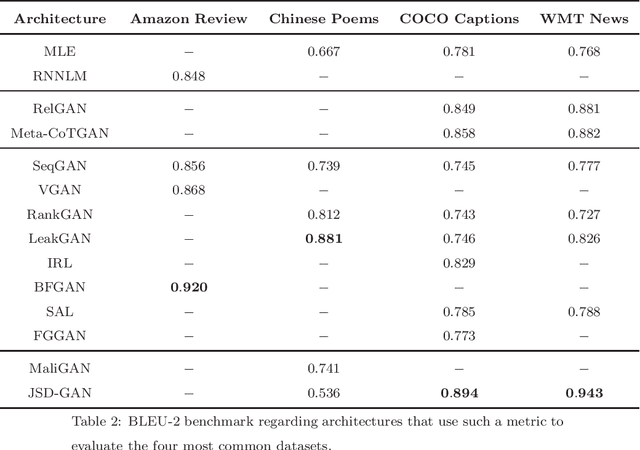
This work presents a thorough review concerning recent studies and text generation advancements using Generative Adversarial Networks. The usage of adversarial learning for text generation is promising as it provides alternatives to generate the so-called "natural" language. Nevertheless, adversarial text generation is not a simple task as its foremost architecture, the Generative Adversarial Networks, were designed to cope with continuous information (image) instead of discrete data (text). Thus, most works are based on three possible options, i.e., Gumbel-Softmax differentiation, Reinforcement Learning, and modified training objectives. All alternatives are reviewed in this survey as they present the most recent approaches for generating text using adversarial-based techniques. The selected works were taken from renowned databases, such as Science Direct, IEEEXplore, Springer, Association for Computing Machinery, and arXiv, whereas each selected work has been critically analyzed and assessed to present its objective, methodology, and experimental results.
Receptive Field Alignment Enables Transformer Length Extrapolation
Dec 20, 2022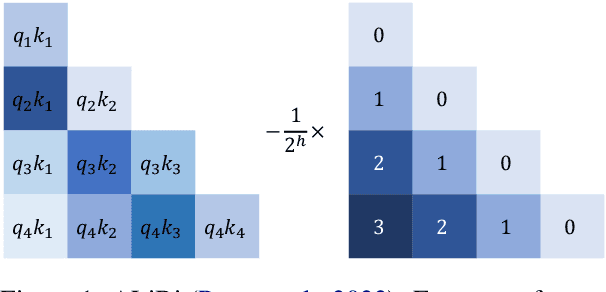
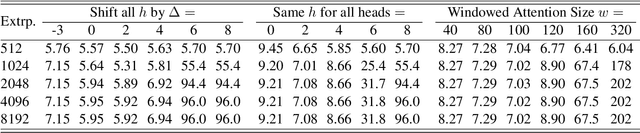
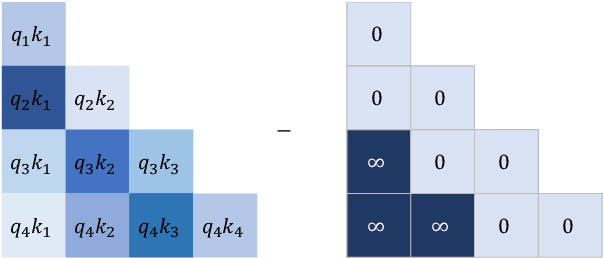
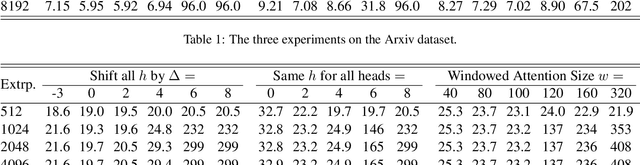
Length extrapolation is a desirable property that permits training a transformer language model on short sequences and retaining similar perplexities when the model is tested on substantially longer sequences. A relative positional embedding mechanism applied on the transformer self-attention matrix, ALiBi, demonstrates the length extrapolation property with the widest usage to date. In this paper, we show that ALiBi surprisingly does not utilize tokens further than the training sequence length, which can be explained by its implicit windowed attention effect that aligns the receptive field during training and testing stages. Inspired by ALiBi and the receptive filed alignment hypothesis, we propose another transformer positional embedding design named~\textbf{Sandwich} that uses longer than training sequence length information, and it is a greatly simplified formulation of the earliest proposed Sinusoidal positional embedding. Finally, we show that both ALiBi and Sandwich enable efficient inference thanks to their implicit windowed attention effect.
Medical Diagnosis with Large Scale Multimodal Transformers: Leveraging Diverse Data for More Accurate Diagnosis
Dec 20, 2022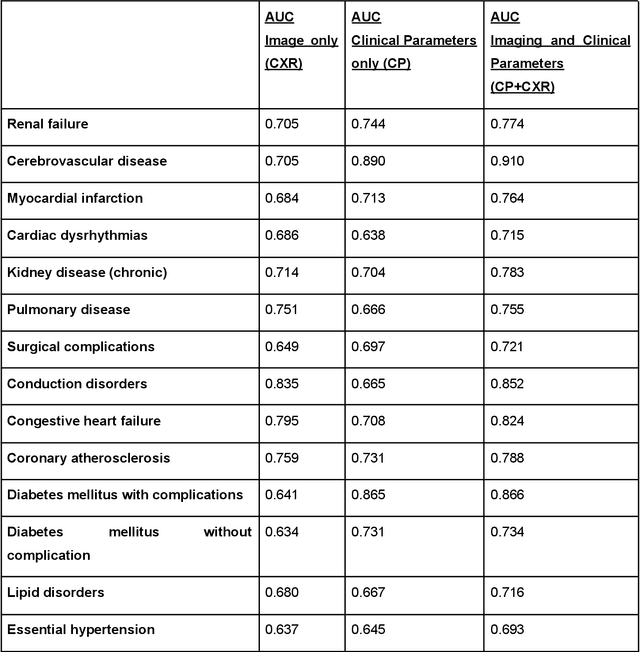
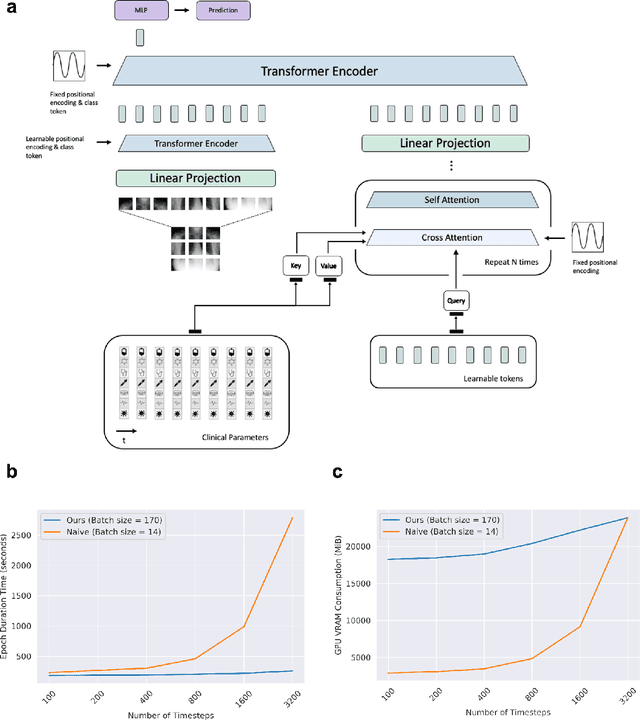
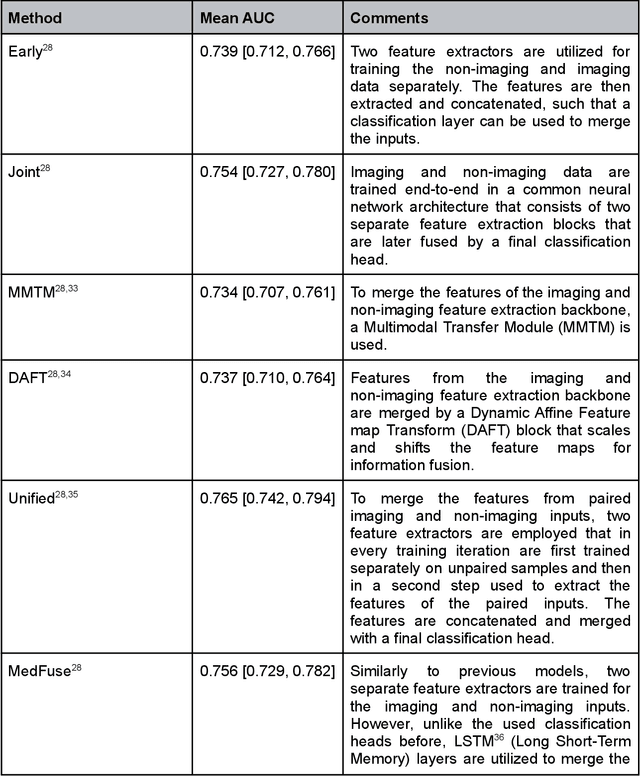
Multimodal deep learning has been used to predict clinical endpoints and diagnoses from clinical routine data. However, these models suffer from scaling issues: they have to learn pairwise interactions between each piece of information in each data type, thereby escalating model complexity beyond manageable scales. This has so far precluded a widespread use of multimodal deep learning. Here, we present a new technical approach of "learnable synergies", in which the model only selects relevant interactions between data modalities and keeps an "internal memory" of relevant data. Our approach is easily scalable and naturally adapts to multimodal data inputs from clinical routine. We demonstrate this approach on three large multimodal datasets from radiology and ophthalmology and show that it outperforms state-of-the-art models in clinically relevant diagnosis tasks. Our new approach is transferable and will allow the application of multimodal deep learning to a broad set of clinically relevant problems.
Multi-head Uncertainty Inference for Adversarial Attack Detection
Dec 20, 2022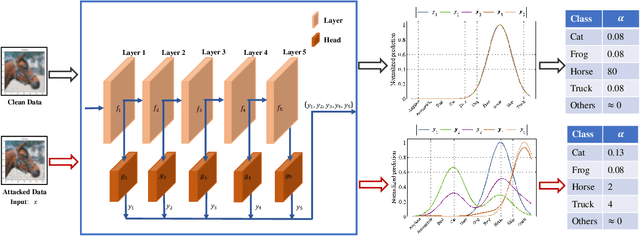
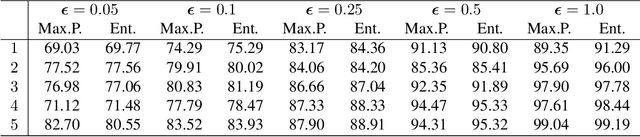


Deep neural networks (DNNs) are sensitive and susceptible to tiny perturbation by adversarial attacks which causes erroneous predictions. Various methods, including adversarial defense and uncertainty inference (UI), have been developed in recent years to overcome the adversarial attacks. In this paper, we propose a multi-head uncertainty inference (MH-UI) framework for detecting adversarial attack examples. We adopt a multi-head architecture with multiple prediction heads (i.e., classifiers) to obtain predictions from different depths in the DNNs and introduce shallow information for the UI. Using independent heads at different depths, the normalized predictions are assumed to follow the same Dirichlet distribution, and we estimate distribution parameter of it by moment matching. Cognitive uncertainty brought by the adversarial attacks will be reflected and amplified on the distribution. Experimental results show that the proposed MH-UI framework can outperform all the referred UI methods in the adversarial attack detection task with different settings.