 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Large language models surpass human experts in predicting neuroscience results
Mar 14, 2024

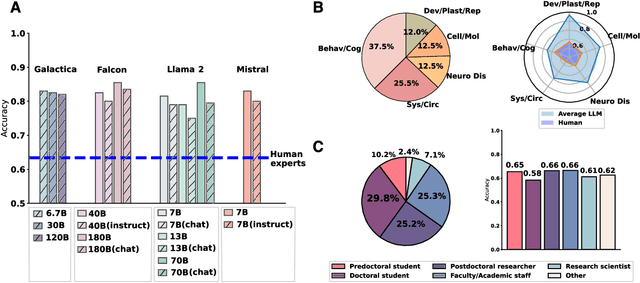
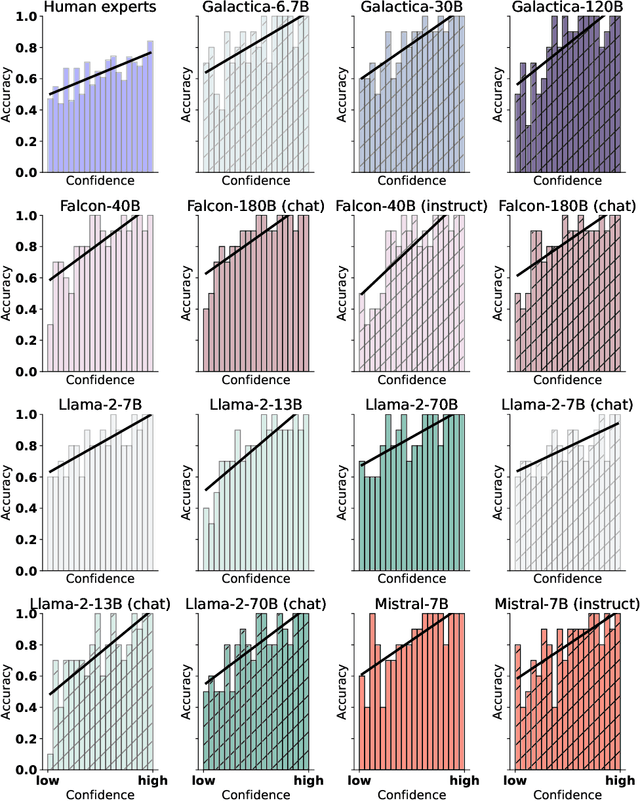
Scientific discoveries often hinge on synthesizing decades of research, a task that potentially outstrips human information processing capacities. Large language models (LLMs) offer a solution. LLMs trained on the vast scientific literature could potentially integrate noisy yet interrelated findings to forecast novel results better than human experts. To evaluate this possibility, we created BrainBench, a forward-looking benchmark for predicting neuroscience results. We find that LLMs surpass experts in predicting experimental outcomes. BrainGPT, an LLM we tuned on the neuroscience literature, performed better yet. Like human experts, when LLMs were confident in their predictions, they were more likely to be correct, which presages a future where humans and LLMs team together to make discoveries. Our approach is not neuroscience-specific and is transferable to other knowledge-intensive endeavors.
Evaluating LLMs for Gender Disparities in Notable Persons
Mar 14, 2024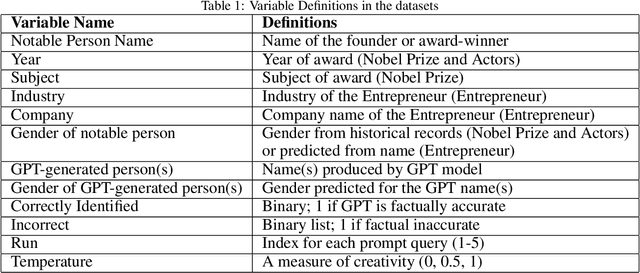
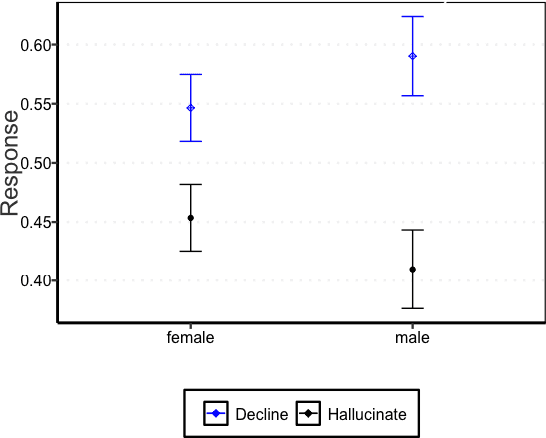
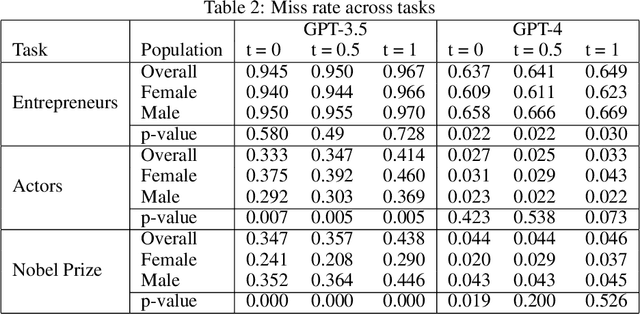
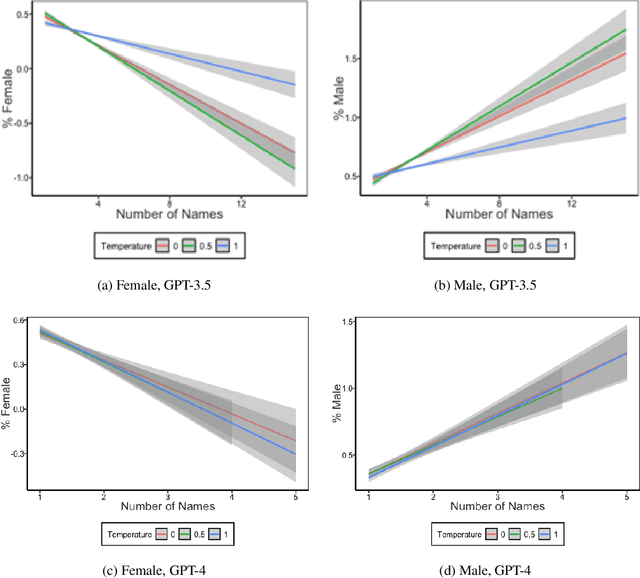
This study examines the use of Large Language Models (LLMs) for retrieving factual information, addressing concerns over their propensity to produce factually incorrect "hallucinated" responses or to altogether decline to even answer prompt at all. Specifically, it investigates the presence of gender-based biases in LLMs' responses to factual inquiries. This paper takes a multi-pronged approach to evaluating GPT models by evaluating fairness across multiple dimensions of recall, hallucinations and declinations. Our findings reveal discernible gender disparities in the responses generated by GPT-3.5. While advancements in GPT-4 have led to improvements in performance, they have not fully eradicated these gender disparities, notably in instances where responses are declined. The study further explores the origins of these disparities by examining the influence of gender associations in prompts and the homogeneity in the responses.
The Geography of Information Diffusion in Online Discourse on Europe and Migration
Feb 21, 2024The online diffusion of information related to Europe and migration has been little investigated from an external point of view. However, this is a very relevant topic, especially if users have had no direct contact with Europe and its perception depends solely on information retrieved online. In this work we analyse the information circulating online about Europe and migration after retrieving a large amount of data from social media (Twitter), to gain new insights into topics, magnitude, and dynamics of their diffusion. We combine retweets and hashtags network analysis with geolocation of users, linking thus data to geography and allowing analysis from an "outside Europe" perspective, with a special focus on Africa. We also introduce a novel approach based on cross-lingual quotes, i.e. when content in a language is commented and retweeted in another language, assuming these interactions are a proxy for connections between very distant communities. Results show how the majority of online discussions occurs at a national level, especially when discussing migration. Language (English) is pivotal for information to become transnational and reach far. Transnational information flow is strongly unbalanced, with content mainly produced in Europe and amplified outside. Conversely Europe-based accounts tend to be self-referential when they discuss migration-related topics. Football is the most exported topic from Europe worldwide. Moreover, important nodes in the communities discussing migration-related topics include accounts of official institutions and international agencies, together with journalists, news, commentators and activists.
Leveraging graph neural networks for supporting Automatic Triage of Patients
Mar 11, 2024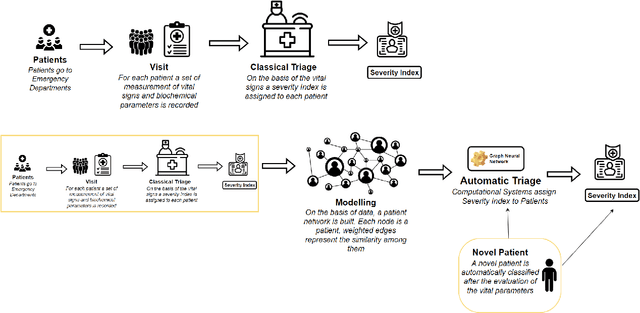
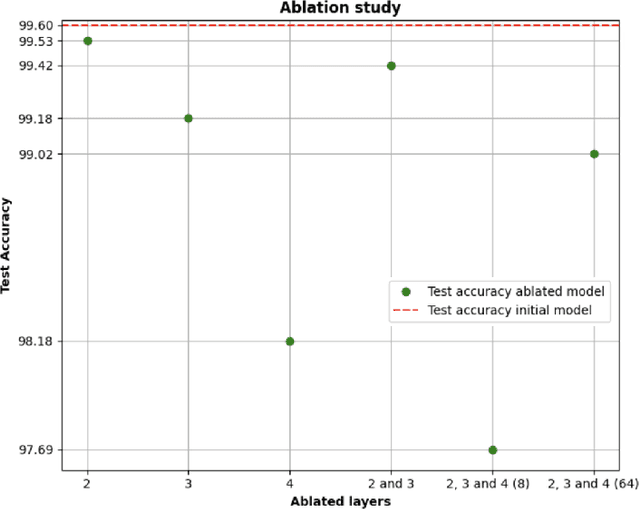
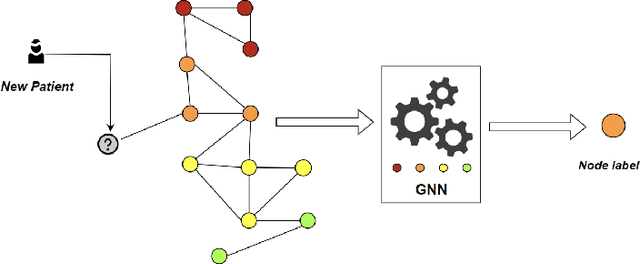
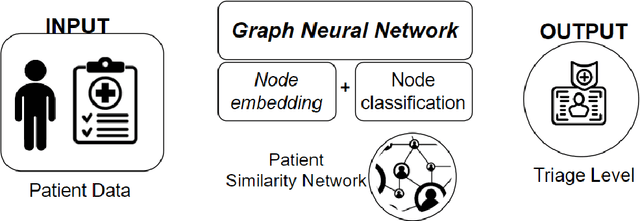
Patient triage plays a crucial role in emergency departments, ensuring timely and appropriate care based on correctly evaluating the emergency grade of patient conditions. Triage methods are generally performed by human operator based on her own experience and information that are gathered from the patient management process. Thus, it is a process that can generate errors in emergency level associations. Recently, Traditional triage methods heavily rely on human decisions, which can be subjective and prone to errors. Recently, a growing interest has been focused on leveraging artificial intelligence (AI) to develop algorithms able to maximize information gathering and minimize errors in patient triage processing. We define and implement an AI based module to manage patients emergency code assignments in emergency departments. It uses emergency department historical data to train the medical decision process. Data containing relevant patient information, such as vital signs, symptoms, and medical history, are used to accurately classify patients into triage categories. Experimental results demonstrate that the proposed algorithm achieved high accuracy outperforming traditional triage methods. By using the proposed method we claim that healthcare professionals can predict severity index to guide patient management processing and resource allocation.
Cultural evolution in populations of Large Language Models
Mar 13, 2024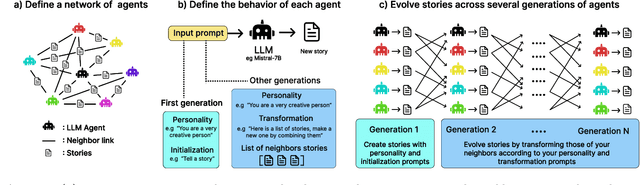
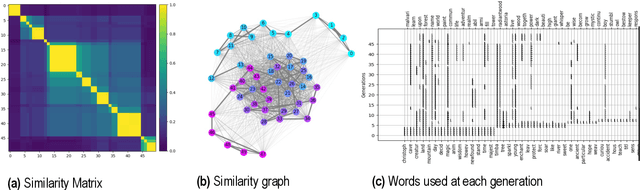
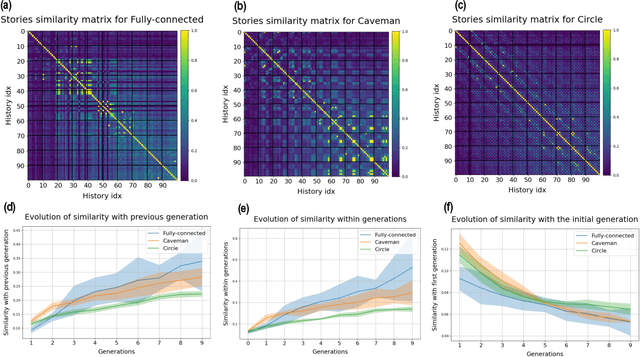
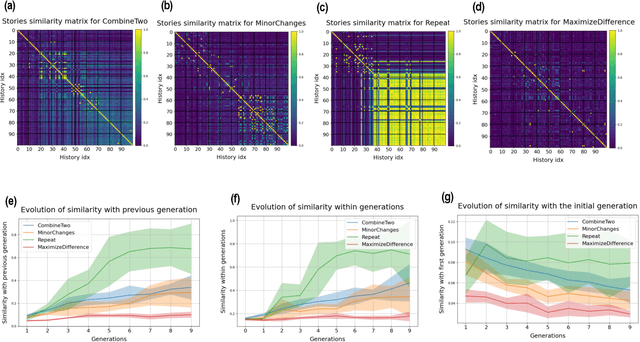
Research in cultural evolution aims at providing causal explanations for the change of culture over time. Over the past decades, this field has generated an important body of knowledge, using experimental, historical, and computational methods. While computational models have been very successful at generating testable hypotheses about the effects of several factors, such as population structure or transmission biases, some phenomena have so far been more complex to capture using agent-based and formal models. This is in particular the case for the effect of the transformations of social information induced by evolved cognitive mechanisms. We here propose that leveraging the capacity of Large Language Models (LLMs) to mimic human behavior may be fruitful to address this gap. On top of being an useful approximation of human cultural dynamics, multi-agents models featuring generative agents are also important to study for their own sake. Indeed, as artificial agents are bound to participate more and more to the evolution of culture, it is crucial to better understand the dynamics of machine-generated cultural evolution. We here present a framework for simulating cultural evolution in populations of LLMs, allowing the manipulation of variables known to be important in cultural evolution, such as network structure, personality, and the way social information is aggregated and transformed. The software we developed for conducting these simulations is open-source and features an intuitive user-interface, which we hope will help to build bridges between the fields of cultural evolution and generative artificial intelligence.
Edge Private Graph Neural Networks with Singular Value Perturbation
Mar 16, 2024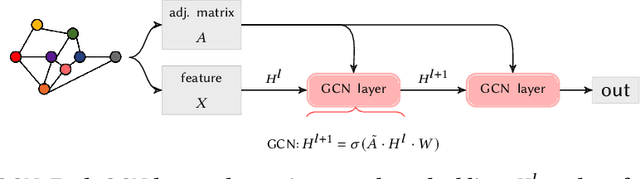
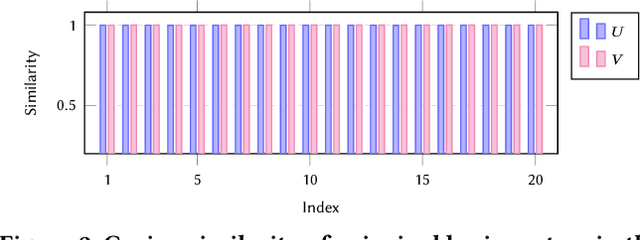
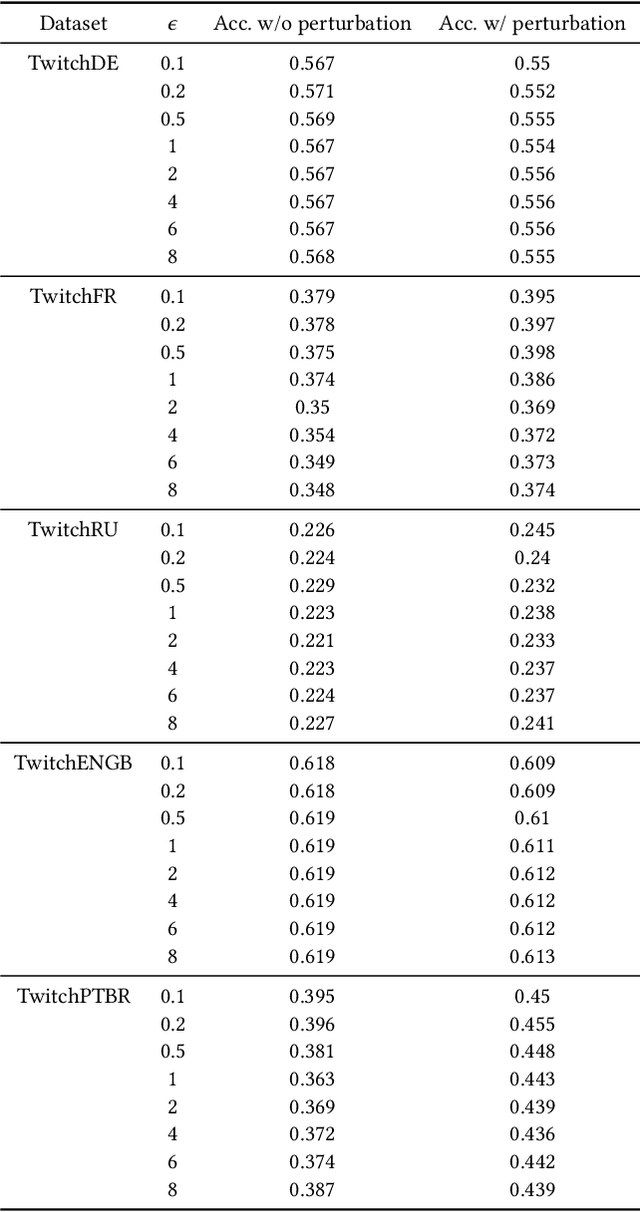
Graph neural networks (GNNs) play a key role in learning representations from graph-structured data and are demonstrated to be useful in many applications. However, the GNN training pipeline has been shown to be vulnerable to node feature leakage and edge extraction attacks. This paper investigates a scenario where an attacker aims to recover private edge information from a trained GNN model. Previous studies have employed differential privacy (DP) to add noise directly to the adjacency matrix or a compact graph representation. The added perturbations cause the graph structure to be substantially morphed, reducing the model utility. We propose a new privacy-preserving GNN training algorithm, Eclipse, that maintains good model utility while providing strong privacy protection on edges. Eclipse is based on two key observations. First, adjacency matrices in graph structures exhibit low-rank behavior. Thus, Eclipse trains GNNs with a low-rank format of the graph via singular values decomposition (SVD), rather than the original graph. Using the low-rank format, Eclipse preserves the primary graph topology and removes the remaining residual edges. Eclipse adds noise to the low-rank singular values instead of the entire graph, thereby preserving the graph privacy while still maintaining enough of the graph structure to maintain model utility. We theoretically show Eclipse provide formal DP guarantee on edges. Experiments on benchmark graph datasets show that Eclipse achieves significantly better privacy-utility tradeoff compared to existing privacy-preserving GNN training methods. In particular, under strong privacy constraints ($\epsilon$ < 4), Eclipse shows significant gains in the model utility by up to 46%. We further demonstrate that Eclipse also has better resilience against common edge attacks (e.g., LPA), lowering the attack AUC by up to 5% compared to other state-of-the-art baselines.
Mind the GAP: Improving Robustness to Subpopulation Shifts with Group-Aware Priors
Mar 14, 2024Machine learning models often perform poorly under subpopulation shifts in the data distribution. Developing methods that allow machine learning models to better generalize to such shifts is crucial for safe deployment in real-world settings. In this paper, we develop a family of group-aware prior (GAP) distributions over neural network parameters that explicitly favor models that generalize well under subpopulation shifts. We design a simple group-aware prior that only requires access to a small set of data with group information and demonstrate that training with this prior yields state-of-the-art performance -- even when only retraining the final layer of a previously trained non-robust model. Group aware-priors are conceptually simple, complementary to existing approaches, such as attribute pseudo labeling and data reweighting, and open up promising new avenues for harnessing Bayesian inference to enable robustness to subpopulation shifts.
Semi- and Weakly-Supervised Learning for Mammogram Mass Segmentation with Limited Annotations
Mar 14, 2024
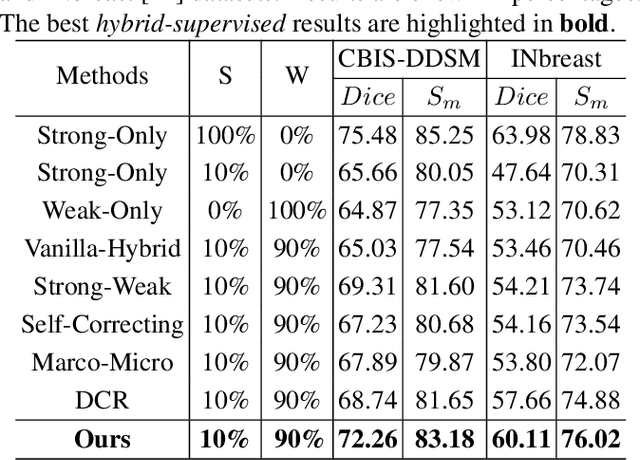
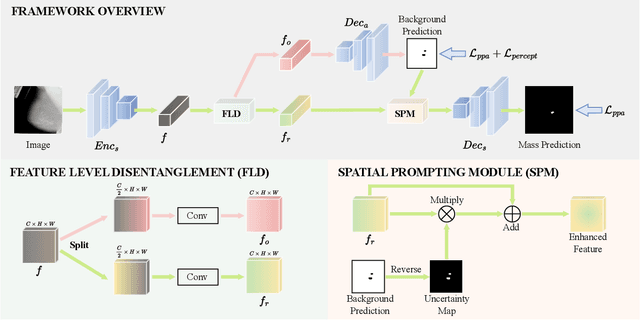
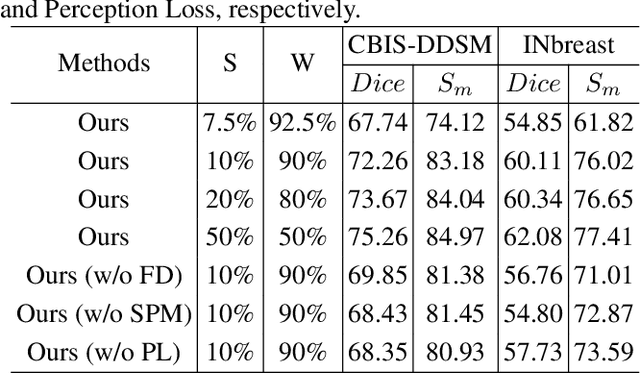
Accurate identification of breast masses is crucial in diagnosing breast cancer; however, it can be challenging due to their small size and being camouflaged in surrounding normal glands. Worse still, it is also expensive in clinical practice to obtain adequate pixel-wise annotations for training deep neural networks. To overcome these two difficulties with one stone, we propose a semi- and weakly-supervised learning framework for mass segmentation that utilizes limited strongly-labeled samples and sufficient weakly-labeled samples to achieve satisfactory performance. The framework consists of an auxiliary branch to exclude lesion-irrelevant background areas, a segmentation branch for final prediction, and a spatial prompting module to integrate the complementary information of the two branches. We further disentangle encoded obscure features into lesion-related and others to boost performance. Experiments on CBIS-DDSM and INbreast datasets demonstrate the effectiveness of our method.
Progressive Divide-and-Conquer via Subsampling Decomposition for Accelerated MRI
Mar 15, 2024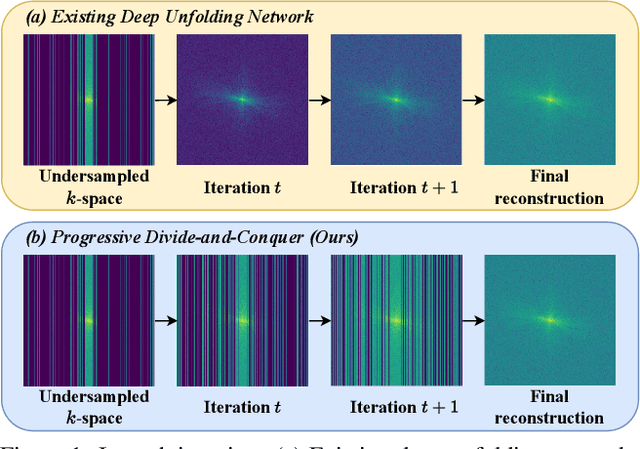
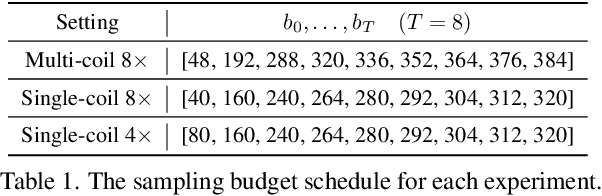
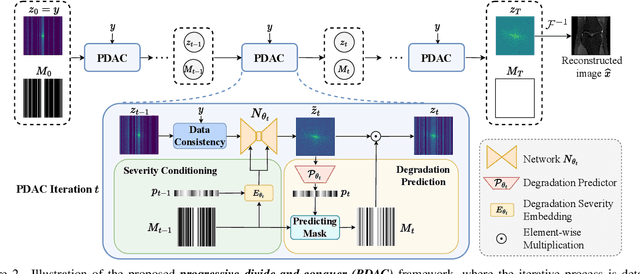
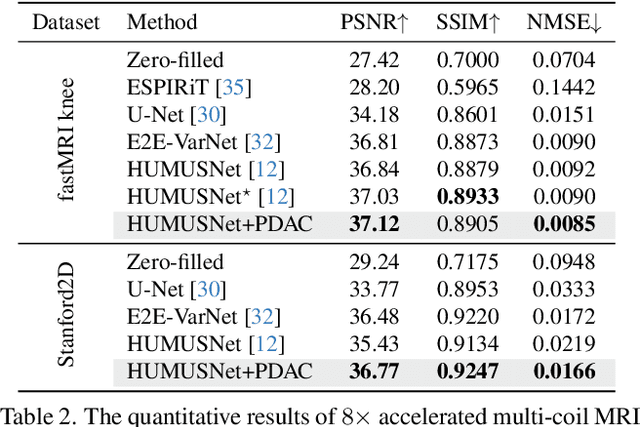
Deep unfolding networks (DUN) have emerged as a popular iterative framework for accelerated magnetic resonance imaging (MRI) reconstruction. However, conventional DUN aims to reconstruct all the missing information within the entire null space in each iteration. Thus it could be challenging when dealing with highly ill-posed degradation, usually leading to unsatisfactory reconstruction. In this work, we propose a Progressive Divide-And-Conquer (PDAC) strategy, aiming to break down the subsampling process in the actual severe degradation and thus perform reconstruction sequentially. Starting from decomposing the original maximum-a-posteriori problem of accelerated MRI, we present a rigorous derivation of the proposed PDAC framework, which could be further unfolded into an end-to-end trainable network. Specifically, each iterative stage in PDAC focuses on recovering a distinct moderate degradation according to the decomposition. Furthermore, as part of the PDAC iteration, such decomposition is adaptively learned as an auxiliary task through a degradation predictor which provides an estimation of the decomposed sampling mask. Following this prediction, the sampling mask is further integrated via a severity conditioning module to ensure awareness of the degradation severity at each stage. Extensive experiments demonstrate that our proposed method achieves superior performance on the publicly available fastMRI and Stanford2D FSE datasets in both multi-coil and single-coil settings.
Process-and-Forward: Deep Joint Source-Channel Coding Over Cooperative Relay Networks
Mar 15, 2024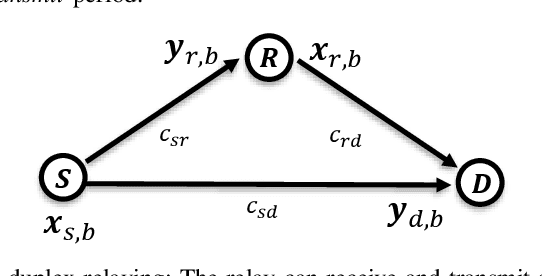
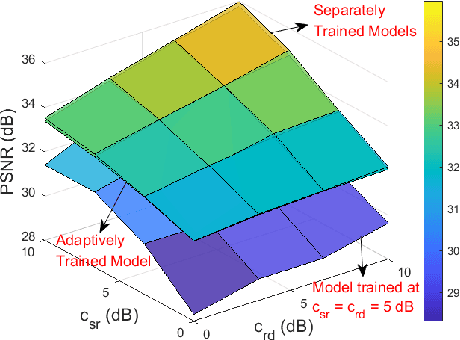

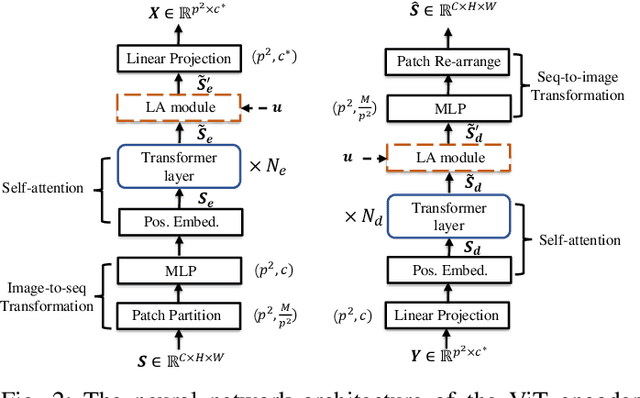
This paper introduces an innovative deep joint source-channel coding (DeepJSCC) approach to image transmission over a cooperative relay channel. The relay either amplifies and forwards a scaled version of its received signal, referred to as DeepJSCC-AF, or leverages neural networks to extract relevant features about the source signal before forwarding it to the destination, which we call DeepJSCC-PF (Process-and-Forward). In the full-duplex scheme, inspired by the block Markov coding (BMC) concept, we introduce a novel block transmission strategy built upon novel vision transformer architecture. In the proposed scheme, the source transmits information in blocks, and the relay updates its knowledge about the input signal after each block and generates its own signal to be conveyed to the destination. To enhance practicality, we introduce an adaptive transmission model, which allows a single trained DeepJSCC model to adapt seamlessly to various channel qualities, making it a versatile solution. Simulation results demonstrate the superior performance of our proposed DeepJSCC compared to the state-of-the-art BPG image compression algorithm, even when operating at the maximum achievable rate of conventional decode-and-forward and compress-and-forward protocols, for both half-duplex and full-duplex relay scenarios.