 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMberjack: Guided Trimming of Debate Trees for Multi-Party Conversation Creation
Jan 07, 2026We present LLMberjack, a platform for creating multi-party conversations starting from existing debates, originally structured as reply trees. The system offers an interactive interface that visualizes discussion trees and enables users to construct coherent linearized dialogue sequences while preserving participant identity and discourse relations. It integrates optional large language model (LLM) assistance to support automatic editing of the messages and speakers' descriptions. We demonstrate the platform's utility by showing how tree visualization facilitates the creation of coherent, meaningful conversation threads and how LLM support enhances output quality while reducing human effort. The tool is open-source and designed to promote transparent and reproducible workflows to create multi-party conversations, addressing a lack of resources of this type.
Multilingual vs Crosslingual Retrieval of Fact-Checked Claims: A Tale of Two Approaches
May 28, 2025



Retrieval of previously fact-checked claims is a well-established task, whose automation can assist professional fact-checkers in the initial steps of information verification. Previous works have mostly tackled the task monolingually, i.e., having both the input and the retrieved claims in the same language. However, especially for languages with a limited availability of fact-checks and in case of global narratives, such as pandemics, wars, or international politics, it is crucial to be able to retrieve claims across languages. In this work, we examine strategies to improve the multilingual and crosslingual performance, namely selection of negative examples (in the supervised) and re-ranking (in the unsupervised setting). We evaluate all approaches on a dataset containing posts and claims in 47 languages (283 language combinations). We observe that the best results are obtained by using LLM-based re-ranking, followed by fine-tuning with negative examples sampled using a sentence similarity-based strategy. Most importantly, we show that crosslinguality is a setup with its own unique characteristics compared to the multilingual setup.
Don't Stop the Multi-Party! On Generating Synthetic Multi-Party Conversations with Constraints
Feb 19, 2025



Multi-Party Conversations (MPCs) are widely studied across disciplines, with social media as a primary data source due to their accessibility. However, these datasets raise privacy concerns and often reflect platform-specific properties. For example, interactions between speakers may be limited due to rigid platform structures (e.g., threads, tree-like discussions), which yield overly simplistic interaction patterns (e.g., as a consequence of ``reply-to'' links). This work explores the feasibility of generating diverse MPCs with instruction-tuned Large Language Models (LLMs) by providing deterministic constraints such as dialogue structure and participants' stance. We investigate two complementary strategies of leveraging LLMs in this context: (i.) LLMs as MPC generators, where we task the LLM to generate a whole MPC at once and (ii.) LLMs as MPC parties, where the LLM generates one turn of the conversation at a time, provided the conversation history. We next introduce an analytical framework to evaluate compliance with the constraints, content quality, and interaction complexity for both strategies. Finally, we assess the quality of obtained MPCs via human annotation and LLM-as-a-judge evaluations. We find stark differences among LLMs, with only some being able to generate high-quality MPCs. We also find that turn-by-turn generation yields better conformance to constraints and higher linguistic variability than generating MPCs in one pass. Nonetheless, our structural and qualitative evaluation indicates that both generation strategies can yield high-quality MPCs.
Fine-grained Fallacy Detection with Human Label Variation
Feb 19, 2025



We introduce Faina, the first dataset for fallacy detection that embraces multiple plausible answers and natural disagreement. Faina includes over 11K span-level annotations with overlaps across 20 fallacy types on social media posts in Italian about migration, climate change, and public health given by two expert annotators. Through an extensive annotation study that allowed discussion over multiple rounds, we minimize annotation errors whilst keeping signals of human label variation. Moreover, we devise a framework that goes beyond "single ground truth" evaluation and simultaneously accounts for multiple (equally reliable) test sets and the peculiarities of the task, i.e., partial span matches, overlaps, and the varying severity of labeling errors. Our experiments across four fallacy detection setups show that multi-task and multi-label transformer-based approaches are strong baselines across all settings. We release our data, code, and annotation guidelines to foster research on fallacy detection and human label variation more broadly.
A Survey on Automatic Credibility Assessment of Textual Credibility Signals in the Era of Large Language Models
Oct 28, 2024



In the current era of social media and generative AI, an ability to automatically assess the credibility of online social media content is of tremendous importance. Credibility assessment is fundamentally based on aggregating credibility signals, which refer to small units of information, such as content factuality, bias, or a presence of persuasion techniques, into an overall credibility score. Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection, which utilizes various (mostly latent) features. A growing body of research on automatic credibility assessment and detection of credibility signals can be characterized as highly fragmented and lacking mutual interconnections. This issue is even more prominent due to a lack of an up-to-date overview of research works on automatic credibility assessment. In this survey, we provide such systematic and comprehensive literature review of 175 research papers while focusing on textual credibility signals and Natural Language Processing (NLP), which undergoes a significant advancement due to Large Language Models (LLMs). While positioning the NLP research into the context of other multidisciplinary research works, we tackle with approaches for credibility assessment as well as with 9 categories of credibility signals (we provide a thorough analysis for 3 of them, namely: 1) factuality, subjectivity and bias, 2) persuasion techniques and logical fallacies, and 3) claims and veracity). Following the description of the existing methods, datasets and tools, we identify future challenges and opportunities, while paying a specific attention to recent rapid development of generative AI.
A Target-Aware Analysis of Data Augmentation for Hate Speech Detection
Oct 10, 2024



Hate speech is one of the main threats posed by the widespread use of social networks, despite efforts to limit it. Although attention has been devoted to this issue, the lack of datasets and case studies centered around scarcely represented phenomena, such as ableism or ageism, can lead to hate speech detection systems that do not perform well on underrepresented identity groups. Given the unpreceded capabilities of LLMs in producing high-quality data, we investigate the possibility of augmenting existing data with generative language models, reducing target imbalance. We experiment with augmenting 1,000 posts from the Measuring Hate Speech corpus, an English dataset annotated with target identity information, adding around 30,000 synthetic examples using both simple data augmentation methods and different types of generative models, comparing autoregressive and sequence-to-sequence approaches. We find traditional DA methods to often be preferable to generative models, but the combination of the two tends to lead to the best results. Indeed, for some hate categories such as origin, religion, and disability, hate speech classification using augmented data for training improves by more than 10% F1 over the no augmentation baseline. This work contributes to the development of systems for hate speech detection that are not only better performing but also fairer and more inclusive towards targets that have been neglected so far.
Do LLMs suffer from Multi-Party Hangover? A Diagnostic Approach to Addressee Recognition and Response Selection in Conversations
Sep 27, 2024



Assessing the performance of systems to classify Multi-Party Conversations (MPC) is challenging due to the interconnection between linguistic and structural characteristics of conversations. Conventional evaluation methods often overlook variances in model behavior across different levels of structural complexity on interaction graphs. In this work, we propose a methodological pipeline to investigate model performance across specific structural attributes of conversations. As a proof of concept we focus on Response Selection and Addressee Recognition tasks, to diagnose model weaknesses. To this end, we extract representative diagnostic subdatasets with a fixed number of users and a good structural variety from a large and open corpus of online MPCs. We further frame our work in terms of data minimization, avoiding the use of original usernames to preserve privacy, and propose alternatives to using original text messages. Results show that response selection relies more on the textual content of conversations, while addressee recognition requires capturing their structural dimension. Using an LLM in a zero-shot setting, we further highlight how sensitivity to prompt variations is task-dependent.
The Geography of Information Diffusion in Online Discourse on Europe and Migration
Feb 21, 2024



The online diffusion of information related to Europe and migration has been little investigated from an external point of view. However, this is a very relevant topic, especially if users have had no direct contact with Europe and its perception depends solely on information retrieved online. In this work we analyse the information circulating online about Europe and migration after retrieving a large amount of data from social media (Twitter), to gain new insights into topics, magnitude, and dynamics of their diffusion. We combine retweets and hashtags network analysis with geolocation of users, linking thus data to geography and allowing analysis from an "outside Europe" perspective, with a special focus on Africa. We also introduce a novel approach based on cross-lingual quotes, i.e. when content in a language is commented and retweeted in another language, assuming these interactions are a proxy for connections between very distant communities. Results show how the majority of online discussions occurs at a national level, especially when discussing migration. Language (English) is pivotal for information to become transnational and reach far. Transnational information flow is strongly unbalanced, with content mainly produced in Europe and amplified outside. Conversely Europe-based accounts tend to be self-referential when they discuss migration-related topics. Football is the most exported topic from Europe worldwide. Moreover, important nodes in the communities discussing migration-related topics include accounts of official institutions and international agencies, together with journalists, news, commentators and activists.
Putting Context in Context: the Impact of Discussion Structure on Text Classification
Feb 05, 2024



Current text classification approaches usually focus on the content to be classified. Contextual aspects (both linguistic and extra-linguistic) are usually neglected, even in tasks based on online discussions. Still in many cases the multi-party and multi-turn nature of the context from which these elements are selected can be fruitfully exploited. In this work, we propose a series of experiments on a large dataset for stance detection in English, in which we evaluate the contribution of different types of contextual information, i.e. linguistic, structural and temporal, by feeding them as natural language input into a transformer-based model. We also experiment with different amounts of training data and analyse the topology of local discussion networks in a privacy-compliant way. Results show that structural information can be highly beneficial to text classification but only under certain circumstances (e.g. depending on the amount of training data and on discussion chain complexity). Indeed, we show that contextual information on smaller datasets from other classification tasks does not yield significant improvements. Our framework, based on local discussion networks, allows the integration of structural information, while minimising user profiling, thus preserving their privacy.
Agreeing to Disagree: Annotating Offensive Language Datasets with Annotators' Disagreement
Sep 28, 2021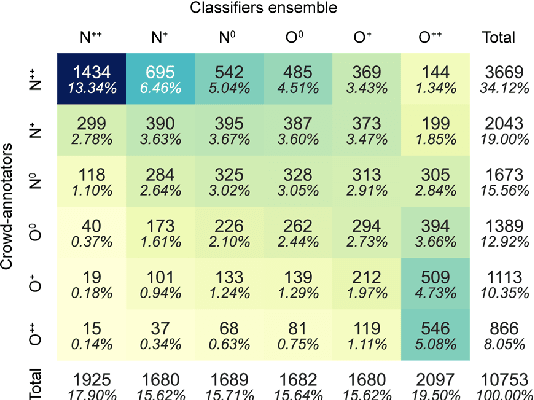

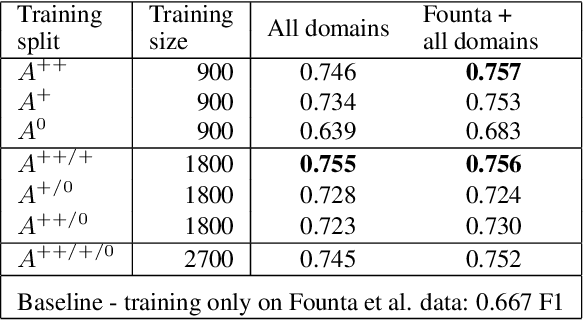
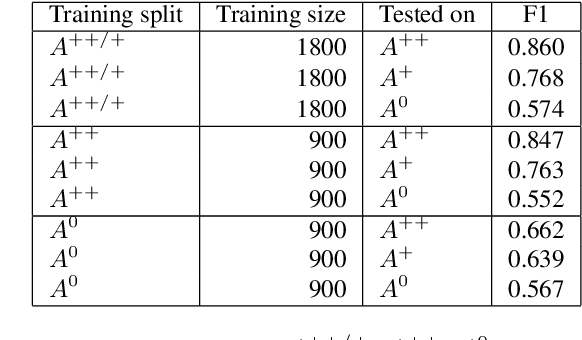
Since state-of-the-art approaches to offensive language detection rely on supervised learning, it is crucial to quickly adapt them to the continuously evolving scenario of social media. While several approaches have been proposed to tackle the problem from an algorithmic perspective, so to reduce the need for annotated data, less attention has been paid to the quality of these data. Following a trend that has emerged recently, we focus on the level of agreement among annotators while selecting data to create offensive language datasets, a task involving a high level of subjectivity. Our study comprises the creation of three novel datasets of English tweets covering different topics and having five crowd-sourced judgments each. We also present an extensive set of experiments showing that selecting training and test data according to different levels of annotators' agreement has a strong effect on classifiers performance and robustness. Our findings are further validated in cross-domain experiments and studied using a popular benchmark dataset. We show that such hard cases, where low agreement is present, are not necessarily due to poor-quality annotation and we advocate for a higher presence of ambiguous cases in future datasets, particularly in test sets, to better account for the different points of view expressed online.