 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HDformer: A Higher Dimensional Transformer for Diabetes Detection Utilizing Long Range Vascular Signals
Mar 17, 2023
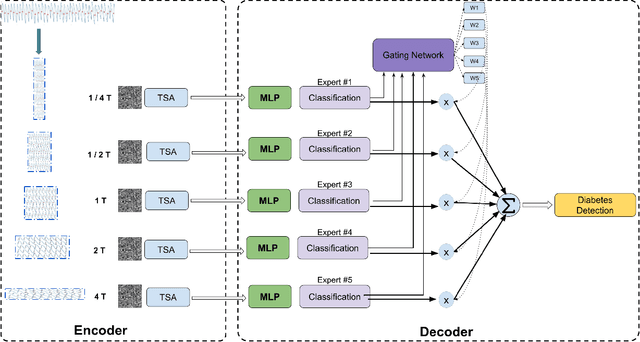
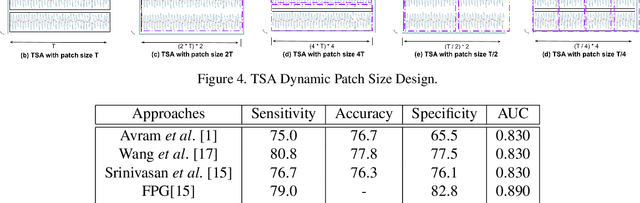
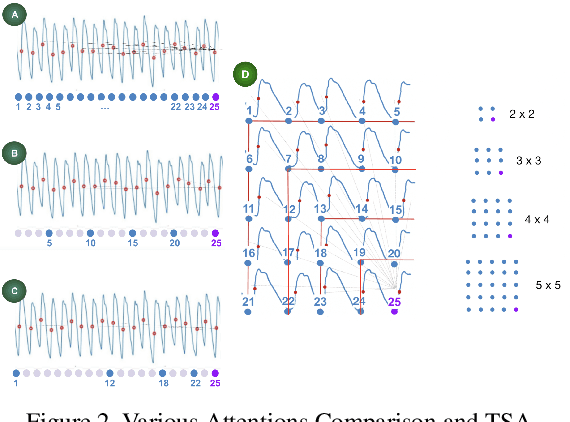
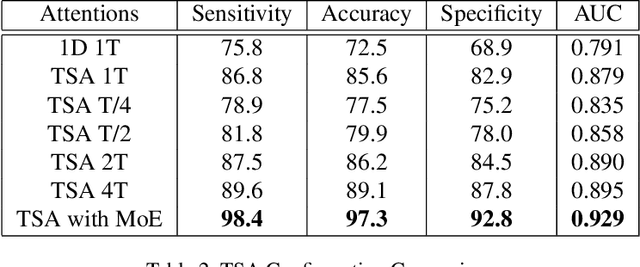
Diabetes mellitus is a worldwide concern, and early detection can help to prevent serious complications. Low-cost, non-invasive detection methods, which take cardiovascular signals into deep learning models, have emerged. However, limited accuracy constrains their clinical usage. In this paper, we present a new Transformer-based architecture, Higher Dimensional Transformer (HDformer), which takes long-range photoplethysmography (PPG) signals to detect diabetes. The long-range PPG contains broader and deeper signal contextual information compared to the less-than-one-minute PPG signals commonly utilized in existing research. To increase the capability and efficiency of processing the long range data, we propose a new attention module Time Square Attention (TSA), reducing the volume of the tokens by more than 10x, while retaining the local/global dependencies. It converts the 1-dimensional inputs into 2-dimensional representations and groups adjacent points into a single 2D token, using the 2D Transformer models as the backbone of the encoder. It generates the dynamic patch sizes into a gated mixture-of-experts (MoE) network as decoder, which optimizes the learning on different attention areas. Extensive experimentations show that HDformer results in the state-of-the-art performance (sensitivity 98.4, accuracy 97.3, specificity 92.8, and AUC 0.929) on the standard MIMIC-III dataset, surpassing existing studies. This work is the first time to take long-range, non-invasive PPG signals via Transformer for diabetes detection, achieving a more scalable and convenient solution compared to traditional invasive approaches. The proposed HDformer can also be scaled to analyze general long-range biomedical waveforms. A wearable prototype finger-ring is designed as a proof of concept.
EHRDiff: Exploring Realistic EHR Synthesis with Diffusion Models
Mar 10, 2023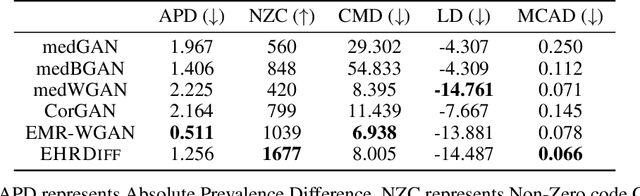
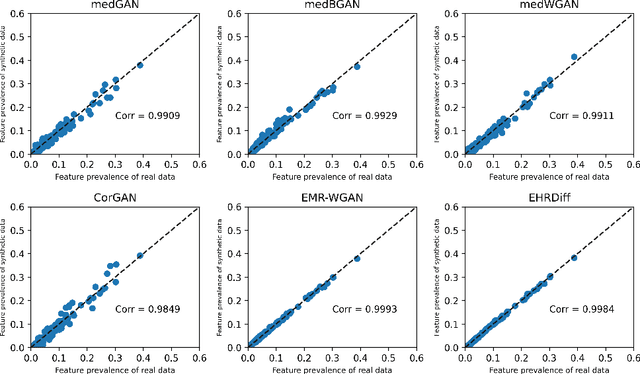
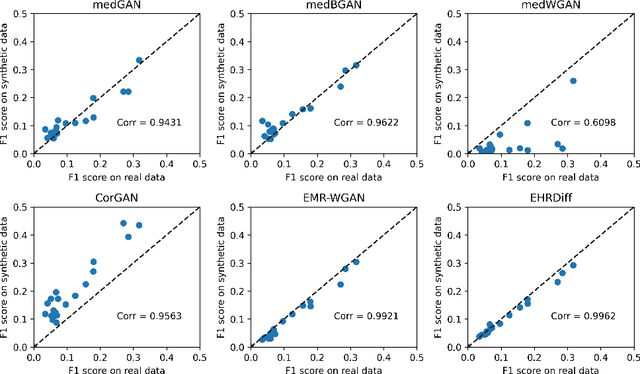
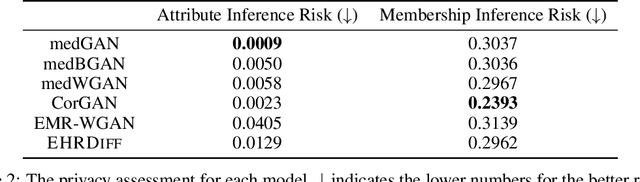
Electronic health records (EHR) contain vast biomedical knowledge and are rich resources for developing precise medicine systems. However, due to privacy concerns, there are limited high-quality EHR data accessible to researchers hence hindering the advancement of methodologies. Recent research has explored using generative modelling methods to synthesize realistic EHR data, and most proposed methods are based on the generative adversarial network (GAN) and its variants for EHR synthesis. Although GAN-style methods achieved state-of-the-art performance in generating high-quality EHR data, such methods are hard to train and prone to mode collapse. Diffusion models are recently proposed generative modelling methods and set cutting-edge performance in image generation. The performance of diffusion models in realistic EHR synthesis is rarely explored. In this work, we explore whether the superior performance of diffusion models can translate to the domain of EHR synthesis and propose a novel EHR synthesis method named EHRDiff. Through comprehensive experiments, EHRDiff achieves new state-of-the-art performance for the quality of synthetic EHR data and can better protect private information in real training EHRs in the meanwhile.
Interpretable Joint Event-Particle Reconstruction for Neutrino Physics at NOvA with Sparse CNNs and Transformers
Mar 10, 2023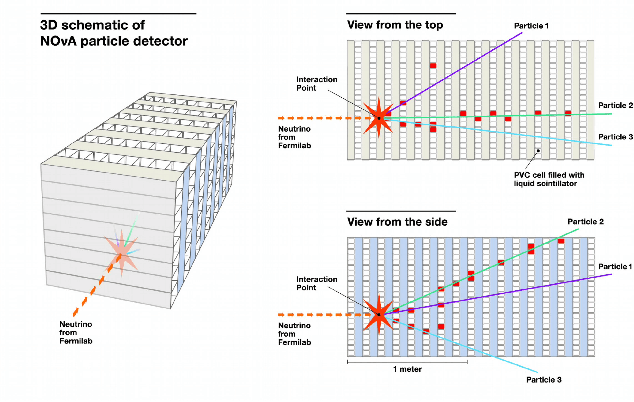
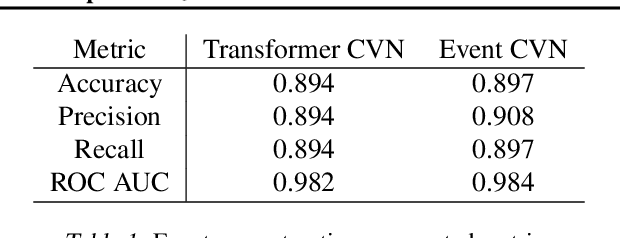
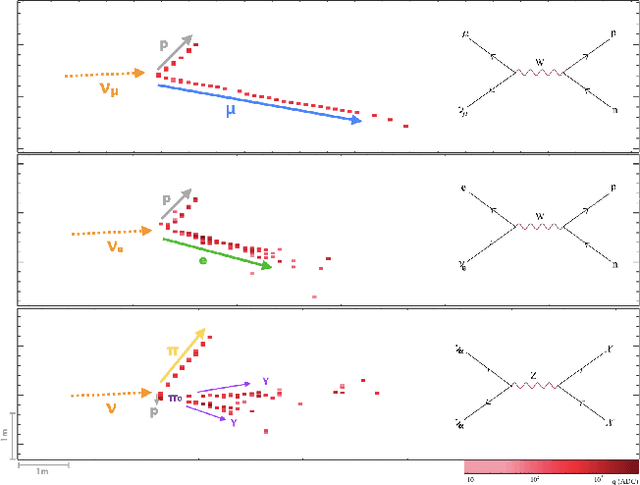
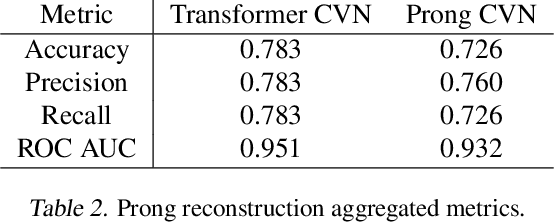
The complex events observed at the NOvA long-baseline neutrino oscillation experiment contain vital information for understanding the most elusive particles in the standard model. The NOvA detectors observe interactions of neutrinos from the NuMI beam at Fermilab. Associating the particles produced in these interaction events to their source particles, a process known as reconstruction, is critical for accurately measuring key parameters of the standard model. Events may contain several particles, each producing sparse high-dimensional spatial observations, and current methods are limited to evaluating individual particles. To accurately label these numerous, high-dimensional observations, we present a novel neural network architecture that combines the spatial learning enabled by convolutions with the contextual learning enabled by attention. This joint approach, TransformerCVN, simultaneously classifies each event and reconstructs every individual particle's identity. TransformerCVN classifies events with 90\% accuracy and improves the reconstruction of individual particles by 6\% over baseline methods which lack the integrated architecture of TransformerCVN. In addition, this architecture enables us to perform several interpretability studies which provide insights into the network's predictions and show that TransformerCVN discovers several fundamental principles that stem from the standard model.
Cross-Layer Retrospective Retrieving via Layer Attention
Feb 20, 2023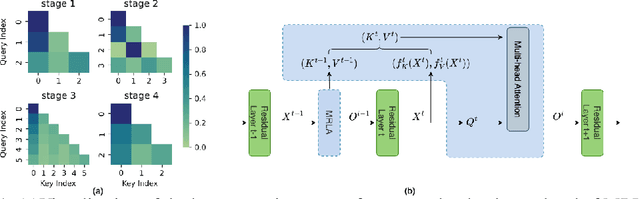
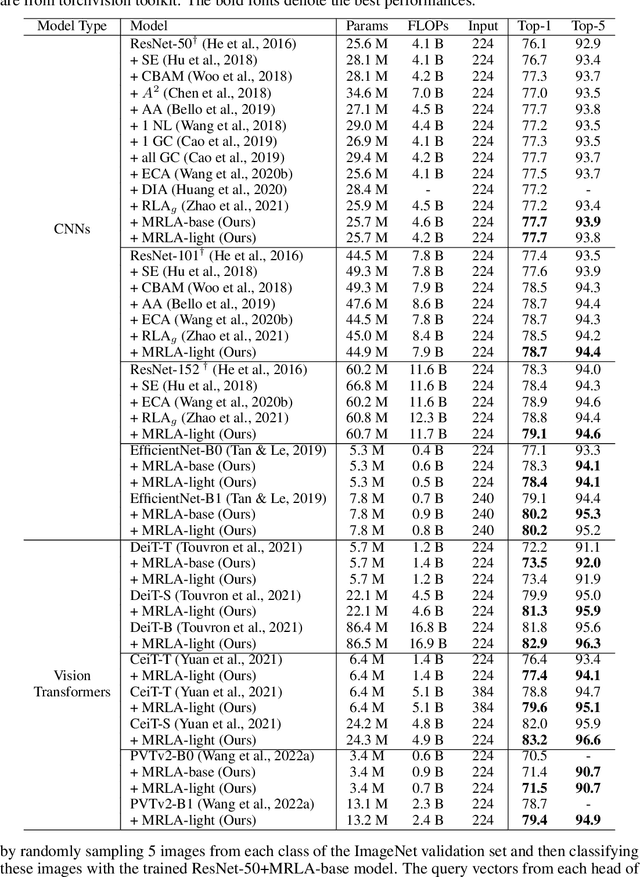
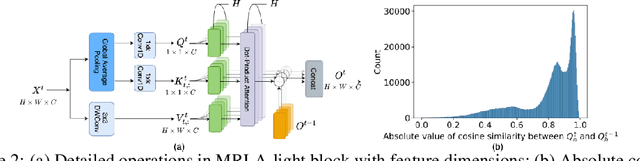
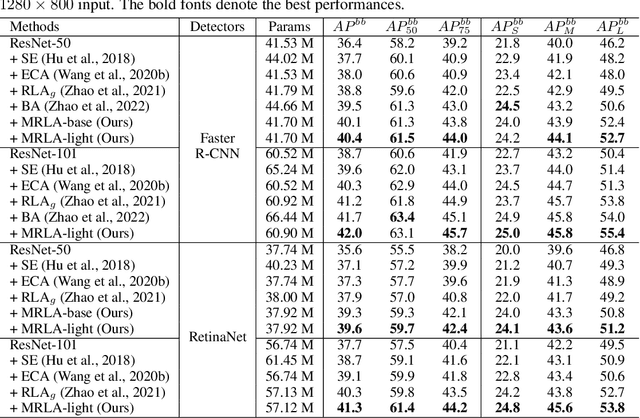
More and more evidence has shown that strengthening layer interactions can enhance the representation power of a deep neural network, while self-attention excels at learning interdependencies by retrieving query-activated information. Motivated by this, we devise a cross-layer attention mechanism, called multi-head recurrent layer attention (MRLA), that sends a query representation of the current layer to all previous layers to retrieve query-related information from different levels of receptive fields. A light-weighted version of MRLA is also proposed to reduce the quadratic computation cost. The proposed layer attention mechanism can enrich the representation power of many state-of-the-art vision networks, including CNNs and vision transformers. Its effectiveness has been extensively evaluated in image classification, object detection and instance segmentation tasks, where improvements can be consistently observed. For example, our MRLA can improve 1.6% Top-1 accuracy on ResNet-50, while only introducing 0.16M parameters and 0.07B FLOPs. Surprisingly, it can boost the performances by a large margin of 3-4% box AP and mask AP in dense prediction tasks. Our code is available at https://github.com/joyfang1106/MRLA.
Revisiting the Plastic Surgery Hypothesis via Large Language Models
Mar 18, 2023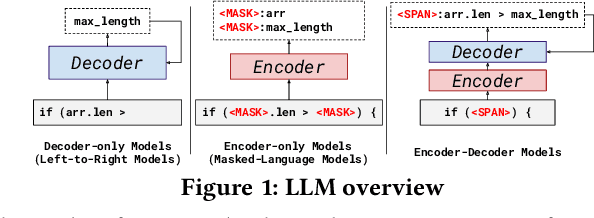
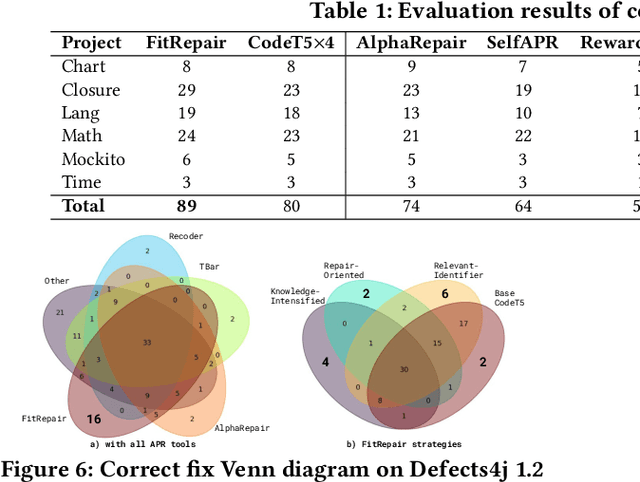
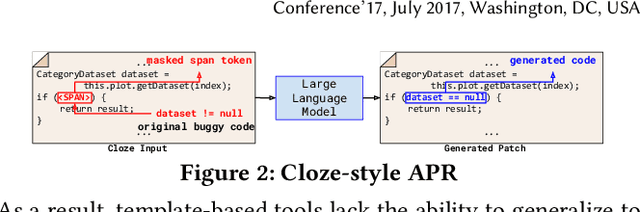
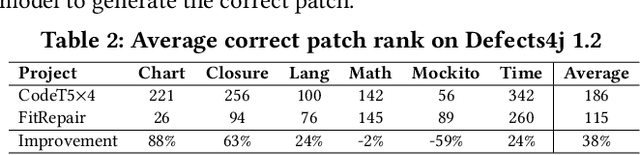
Automated Program Repair (APR) aspires to automatically generate patches for an input buggy program. Traditional APR tools typically focus on specific bug types and fixes through the use of templates, heuristics, and formal specifications. However, these techniques are limited in terms of the bug types and patch variety they can produce. As such, researchers have designed various learning-based APR tools with recent work focused on directly using Large Language Models (LLMs) for APR. While LLM-based APR tools are able to achieve state-of-the-art performance on many repair datasets, the LLMs used for direct repair are not fully aware of the project-specific information such as unique variable or method names. The plastic surgery hypothesis is a well-known insight for APR, which states that the code ingredients to fix the bug usually already exist within the same project. Traditional APR tools have largely leveraged the plastic surgery hypothesis by designing manual or heuristic-based approaches to exploit such existing code ingredients. However, as recent APR research starts focusing on LLM-based approaches, the plastic surgery hypothesis has been largely ignored. In this paper, we ask the following question: How useful is the plastic surgery hypothesis in the era of LLMs? Interestingly, LLM-based APR presents a unique opportunity to fully automate the plastic surgery hypothesis via fine-tuning and prompting. To this end, we propose FitRepair, which combines the direct usage of LLMs with two domain-specific fine-tuning strategies and one prompting strategy for more powerful APR. Our experiments on the widely studied Defects4j 1.2 and 2.0 datasets show that FitRepair fixes 89 and 44 bugs (substantially outperforming the best-performing baseline by 15 and 8), respectively, demonstrating a promising future of the plastic surgery hypothesis in the era of LLMs.
Backdoor Defense via Deconfounded Representation Learning
Mar 13, 2023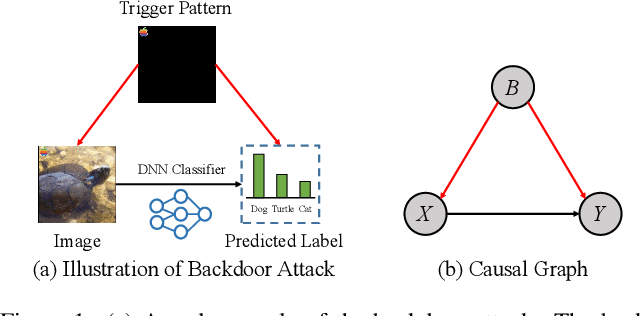
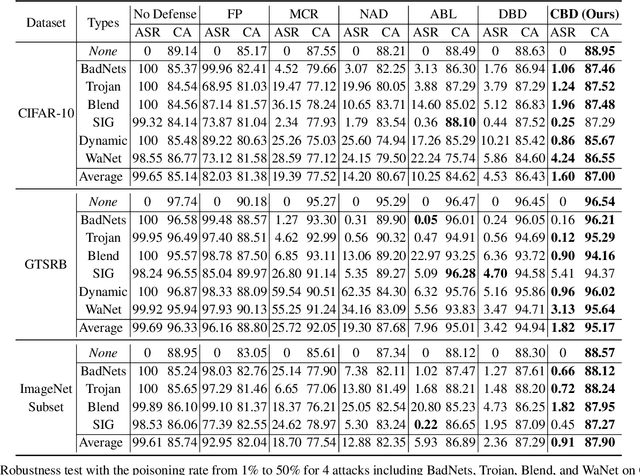
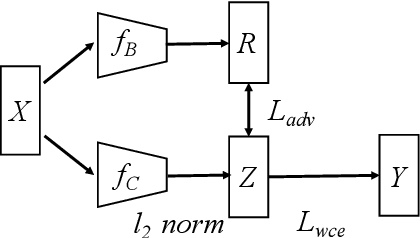
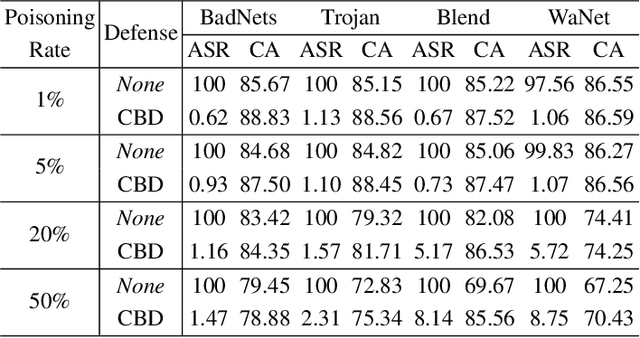
Deep neural networks (DNNs) are recently shown to be vulnerable to backdoor attacks, where attackers embed hidden backdoors in the DNN model by injecting a few poisoned examples into the training dataset. While extensive efforts have been made to detect and remove backdoors from backdoored DNNs, it is still not clear whether a backdoor-free clean model can be directly obtained from poisoned datasets. In this paper, we first construct a causal graph to model the generation process of poisoned data and find that the backdoor attack acts as the confounder, which brings spurious associations between the input images and target labels, making the model predictions less reliable. Inspired by the causal understanding, we propose the Causality-inspired Backdoor Defense (CBD), to learn deconfounded representations for reliable classification. Specifically, a backdoored model is intentionally trained to capture the confounding effects. The other clean model dedicates to capturing the desired causal effects by minimizing the mutual information with the confounding representations from the backdoored model and employing a sample-wise re-weighting scheme. Extensive experiments on multiple benchmark datasets against 6 state-of-the-art attacks verify that our proposed defense method is effective in reducing backdoor threats while maintaining high accuracy in predicting benign samples. Further analysis shows that CBD can also resist potential adaptive attacks. The code is available at \url{https://github.com/zaixizhang/CBD}.
AdaptiveNet: Post-deployment Neural Architecture Adaptation for Diverse Edge Environments
Mar 13, 2023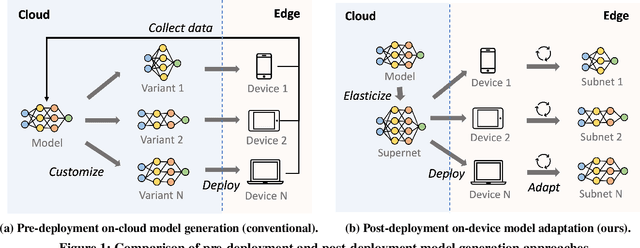

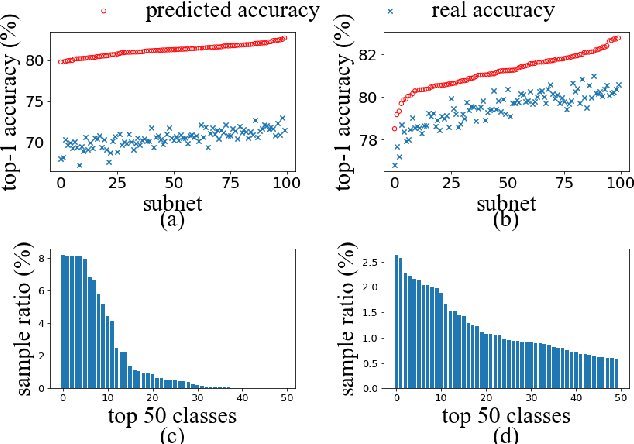
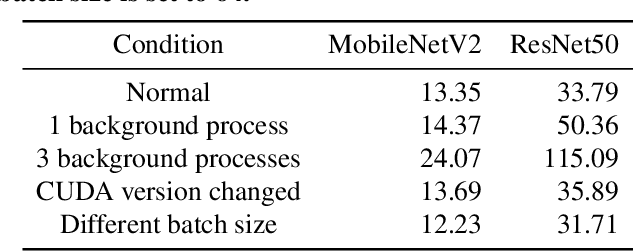
Deep learning models are increasingly deployed to edge devices for real-time applications. To ensure stable service quality across diverse edge environments, it is highly desirable to generate tailored model architectures for different conditions. However, conventional pre-deployment model generation approaches are not satisfactory due to the difficulty of handling the diversity of edge environments and the demand for edge information. In this paper, we propose to adapt the model architecture after deployment in the target environment, where the model quality can be precisely measured and private edge data can be retained. To achieve efficient and effective edge model generation, we introduce a pretraining-assisted on-cloud model elastification method and an edge-friendly on-device architecture search method. Model elastification generates a high-quality search space of model architectures with the guidance of a developer-specified oracle model. Each subnet in the space is a valid model with different environment affinity, and each device efficiently finds and maintains the most suitable subnet based on a series of edge-tailored optimizations. Extensive experiments on various edge devices demonstrate that our approach is able to achieve significantly better accuracy-latency tradeoffs (e.g. 46.74\% higher on average accuracy with a 60\% latency budget) than strong baselines with minimal overhead (13 GPU hours in the cloud and 2 minutes on the edge server).
Vessel-Promoted OCT to OCTA Image Translation by Heuristic Contextual Constraints
Mar 13, 2023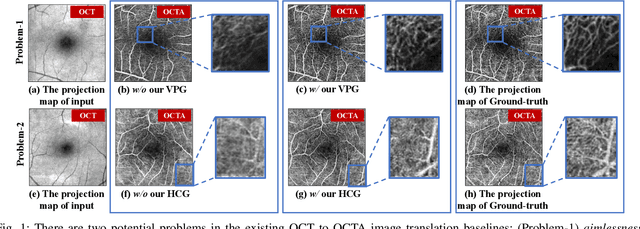
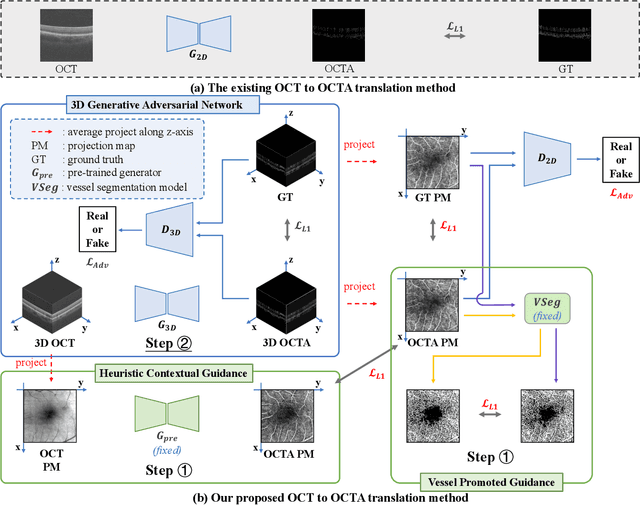
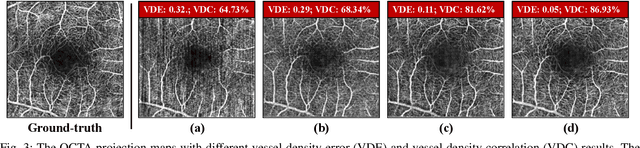
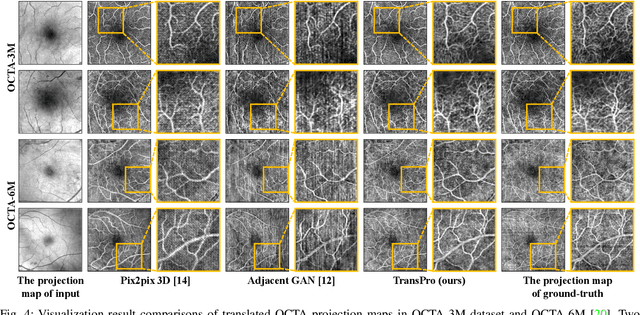
Optical Coherence Tomography Angiography (OCTA) has become increasingly vital in the clinical screening of fundus diseases due to its ability to capture accurate 3D imaging of blood vessels in a non-contact scanning manner. However, the acquisition of OCTA images remains challenging due to the requirement of exclusive sensors and expensive devices. In this paper, we propose a novel framework, TransPro, that translates 3D Optical Coherence Tomography (OCT) images into exclusive 3D OCTA images using an image translation pattern. Our main objective is to address two issues in existing image translation baselines, namely, the aimlessness in the translation process and incompleteness of the translated object. The former refers to the overall quality of the translated OCTA images being satisfactory, but the retinal vascular quality being low. The latter refers to incomplete objects in translated OCTA images due to the lack of global contexts. TransPro merges a 2D retinal vascular segmentation model and a 2D OCTA image translation model into a 3D image translation baseline for the 2D projection map projected by the translated OCTA images. The 2D retinal vascular segmentation model can improve attention to the retinal vascular, while the 2D OCTA image translation model introduces beneficial heuristic contextual information. Extensive experimental results on two challenging datasets demonstrate that TransPro can consistently outperform existing approaches with minimal computational overhead during training and none during testing.
Transformer Encoder with Multiscale Deep Learning for Pain Classification Using Physiological Signals
Mar 13, 2023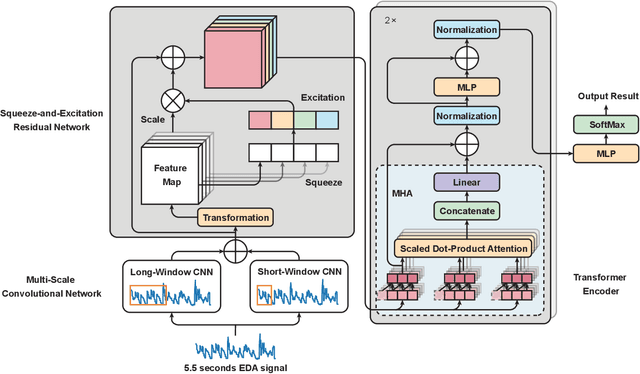

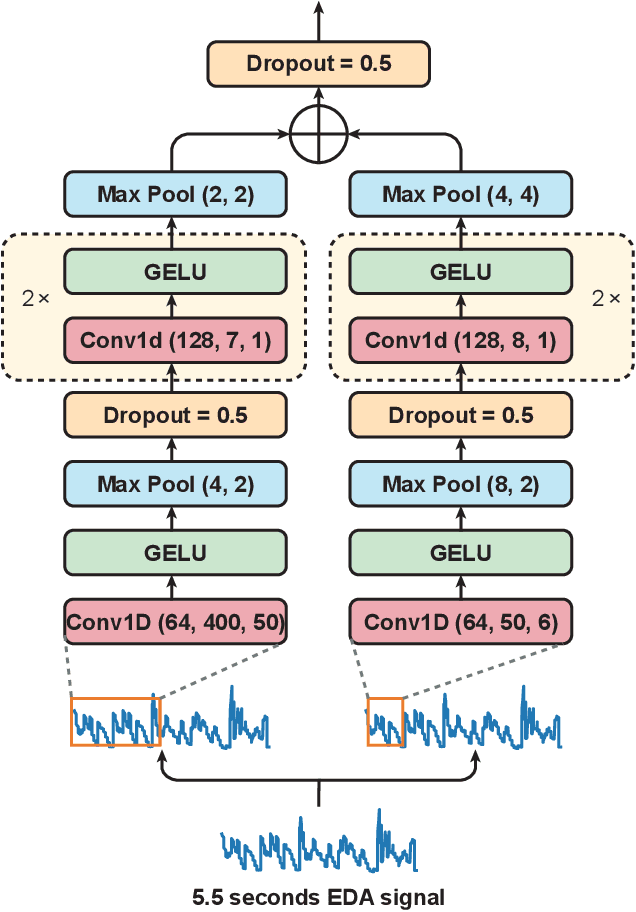
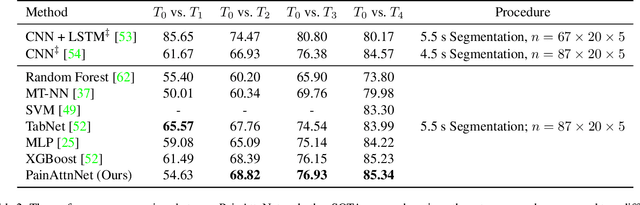
Pain is a serious worldwide health problem that affects a vast proportion of the population. For efficient pain management and treatment, accurate classification and evaluation of pain severity are necessary. However, this can be challenging as pain is a subjective sensation-driven experience. Traditional techniques for measuring pain intensity, e.g. self-report scales, are susceptible to bias and unreliable in some instances. Consequently, there is a need for more objective and automatic pain intensity assessment strategies. In this research, we develop PainAttnNet (PAN), a novel transfomer-encoder deep-learning framework for classifying pain intensities with physiological signals as input. The proposed approach is comprised of three feature extraction architectures: multiscale convolutional networks (MSCN), a squeeze-and-excitation residual network (SEResNet), and a transformer encoder block. On the basis of pain stimuli, MSCN extracts short- and long-window information as well as sequential features. SEResNet highlights relevant extracted features by mapping the interdependencies among features. The third architecture employs a transformer encoder consisting of three temporal convolutional networks (TCN) with three multi-head attention (MHA) layers to extract temporal dependencies from the features. Using the publicly available BioVid pain dataset, we test the proposed PainAttnNet model and demonstrate that our outcomes outperform state-of-the-art models. These results confirm that our approach can be utilized for automated classification of pain intensity using physiological signals to improve pain management and treatment.
DeepVigor: Vulnerability Value Ranges and Factors for DNNs' Reliability Assessment
Mar 13, 2023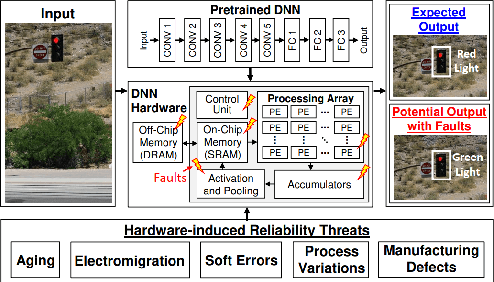
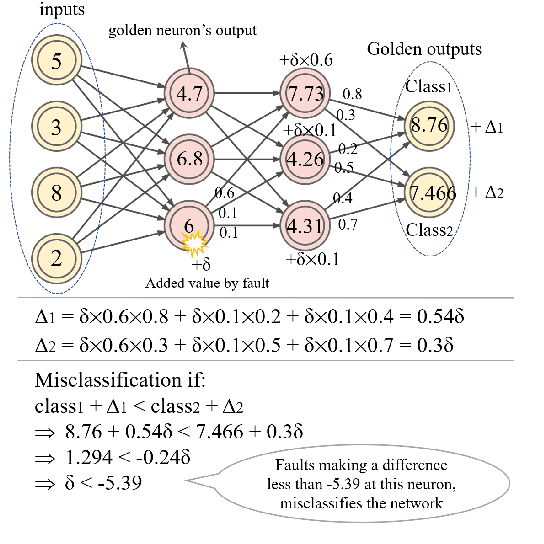
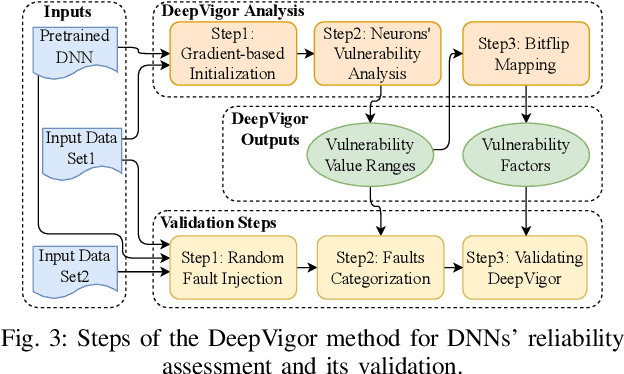
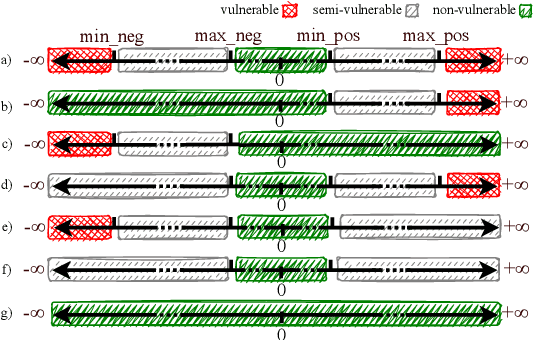
Deep Neural Networks (DNNs) and their accelerators are being deployed ever more frequently in safety-critical applications leading to increasing reliability concerns. A traditional and accurate method for assessing DNNs' reliability has been resorting to fault injection, which, however, suffers from prohibitive time complexity. While analytical and hybrid fault injection-/analytical-based methods have been proposed, they are either inaccurate or specific to particular accelerator architectures. In this work, we propose a novel accurate, fine-grain, metric-oriented, and accelerator-agnostic method called DeepVigor that provides vulnerability value ranges for DNN neurons' outputs. An outcome of DeepVigor is an analytical model representing vulnerable and non-vulnerable ranges for each neuron that can be exploited to develop different techniques for improving DNNs' reliability. Moreover, DeepVigor provides reliability assessment metrics based on vulnerability factors for bits, neurons, and layers using the vulnerability ranges. The proposed method is not only faster than fault injection but also provides extensive and accurate information about the reliability of DNNs, independent from the accelerator. The experimental evaluations in the paper indicate that the proposed vulnerability ranges are 99.9% to 100% accurate even when evaluated on previously unseen test data. Also, it is shown that the obtained vulnerability factors represent the criticality of bits, neurons, and layers proficiently. DeepVigor is implemented in the PyTorch framework and validated on complex DNN benchmarks.