 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models
May 29, 2023
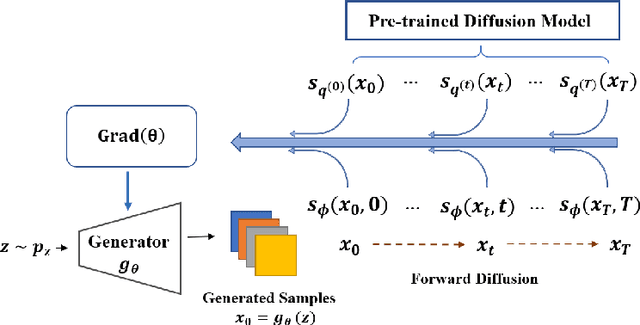
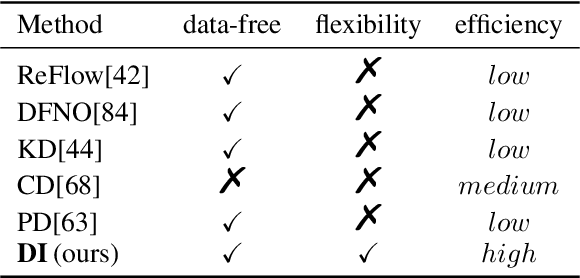

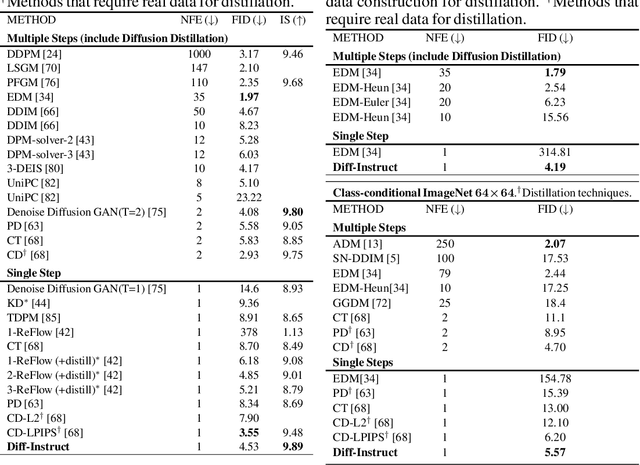
Due to the ease of training, ability to scale, and high sample quality, diffusion models (DMs) have become the preferred option for generative modeling, with numerous pre-trained models available for a wide variety of datasets. Containing intricate information about data distributions, pre-trained DMs are valuable assets for downstream applications. In this work, we consider learning from pre-trained DMs and transferring their knowledge to other generative models in a data-free fashion. Specifically, we propose a general framework called Diff-Instruct to instruct the training of arbitrary generative models as long as the generated samples are differentiable with respect to the model parameters. Our proposed Diff-Instruct is built on a rigorous mathematical foundation where the instruction process directly corresponds to minimizing a novel divergence we call Integral Kullback-Leibler (IKL) divergence. IKL is tailored for DMs by calculating the integral of the KL divergence along a diffusion process, which we show to be more robust in comparing distributions with misaligned supports. We also reveal non-trivial connections of our method to existing works such as DreamFusion, and generative adversarial training. To demonstrate the effectiveness and universality of Diff-Instruct, we consider two scenarios: distilling pre-trained diffusion models and refining existing GAN models. The experiments on distilling pre-trained diffusion models show that Diff-Instruct results in state-of-the-art single-step diffusion-based models. The experiments on refining GAN models show that the Diff-Instruct can consistently improve the pre-trained generators of GAN models across various settings.
Semantic VAD: Low-Latency Voice Activity Detection for Speech Interaction
May 21, 2023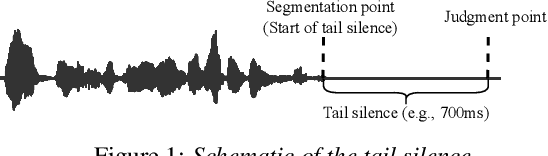
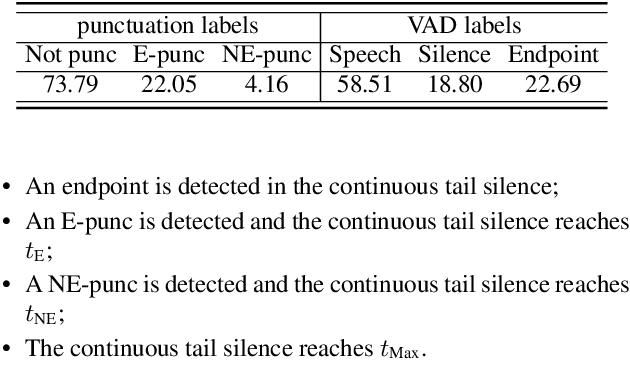
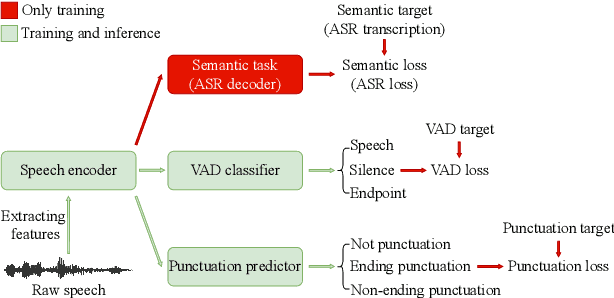
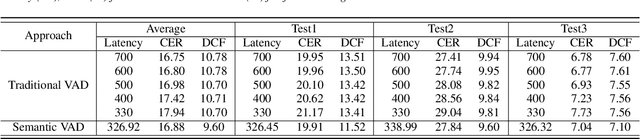
For speech interaction, voice activity detection (VAD) is often used as a front-end. However, traditional VAD algorithms usually need to wait for a continuous tail silence to reach a preset maximum duration before segmentation, resulting in a large latency that affects user experience. In this paper, we propose a novel semantic VAD for low-latency segmentation. Different from existing methods, a frame-level punctuation prediction task is added to the semantic VAD, and the artificial endpoint is included in the classification category in addition to the often-used speech presence and absence. To enhance the semantic information of the model, we also incorporate an automatic speech recognition (ASR) related semantic loss. Evaluations on an internal dataset show that the proposed method can reduce the average latency by 53.3% without significant deterioration of character error rate in the back-end ASR compared to the traditional VAD approach.
Contextualized End-to-End Speech Recognition with Contextual Phrase Prediction Network
May 21, 2023
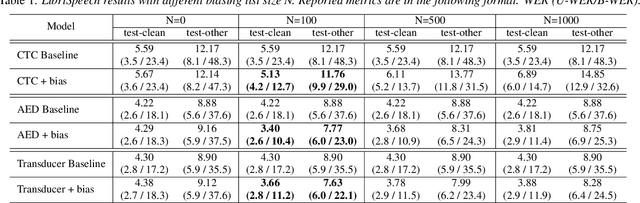
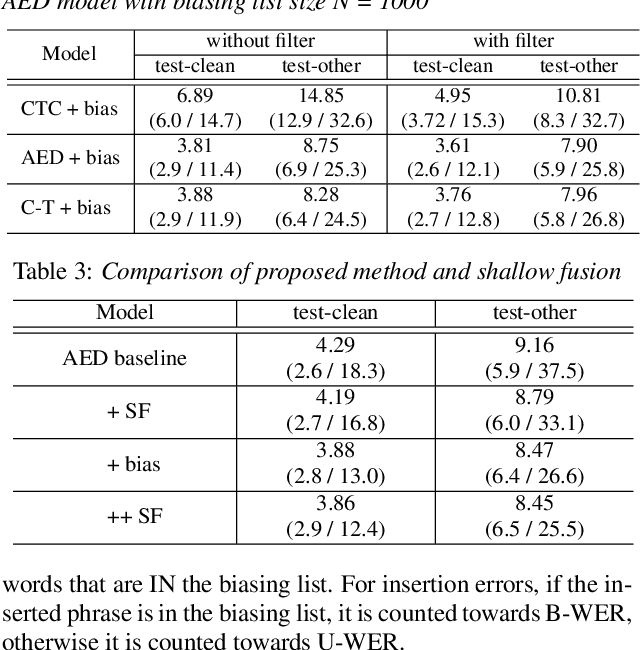
Contextual information plays a crucial role in speech recognition technologies and incorporating it into the end-to-end speech recognition models has drawn immense interest recently. However, previous deep bias methods lacked explicit supervision for bias tasks. In this study, we introduce a contextual phrase prediction network for an attention-based deep bias method. This network predicts context phrases in utterances using contextual embeddings and calculates bias loss to assist in the training of the contextualized model. Our method achieved a significant word error rate (WER) reduction across various end-to-end speech recognition models. Experiments on the LibriSpeech corpus show that our proposed model obtains a 12.1% relative WER improvement over the baseline model, and the WER of the context phrases decreases relatively by 40.5%. Moreover, by applying a context phrase filtering strategy, we also effectively eliminate the WER degradation when using a larger biasing list.
Unsupervised Discovery of Continuous Skills on a Sphere
May 21, 2023


Recently, methods for learning diverse skills to generate various behaviors without external rewards have been actively studied as a form of unsupervised reinforcement learning. However, most of the existing methods learn a finite number of discrete skills, and thus the variety of behaviors that can be exhibited with the learned skills is limited. In this paper, we propose a novel method for learning potentially an infinite number of different skills, which is named discovery of continuous skills on a sphere (DISCS). In DISCS, skills are learned by maximizing mutual information between skills and states, and each skill corresponds to a continuous value on a sphere. Because the representations of skills in DISCS are continuous, infinitely diverse skills could be learned. We examine existing methods and DISCS in the MuJoCo Ant robot control environments and show that DISCS can learn much more diverse skills than the other methods.
Real-time Aerial Detection and Reasoning on Embedded-UAVs
May 21, 2023
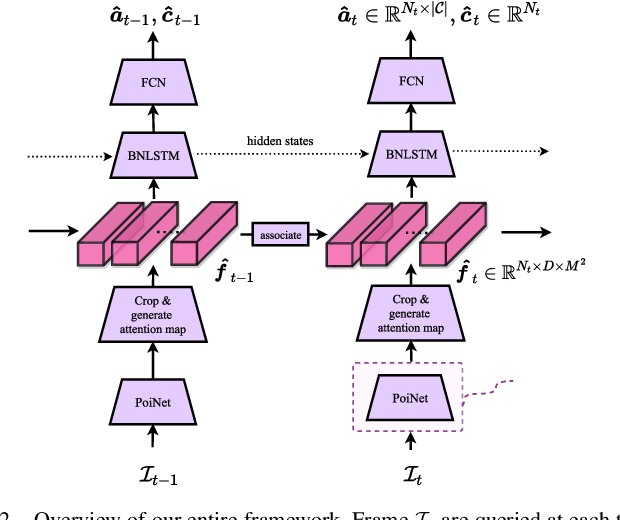
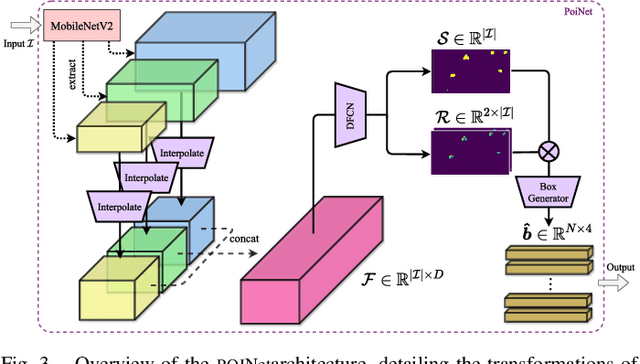

We present a unified pipeline architecture for a real-time detection system on an embedded system for UAVs. Neural architectures have been the industry standard for computer vision. However, most existing works focus solely on concatenating deeper layers to achieve higher accuracy with run-time performance as the trade-off. This pipeline of networks can exploit the domain-specific knowledge on aerial pedestrian detection and activity recognition for the emerging UAV applications of autonomous surveying and activity reporting. In particular, our pipeline architectures operate in a time-sensitive manner, have high accuracy in detecting pedestrians from various aerial orientations, use a novel attention map for multi-activities recognition, and jointly refine its detection with temporal information. Numerically, we demonstrate our model's accuracy and fast inference speed on embedded systems. We empirically deployed our prototype hardware with full live feeds in a real-world open-field environment.
Expository Text Generation: Imitate, Retrieve, Paraphrase
May 05, 2023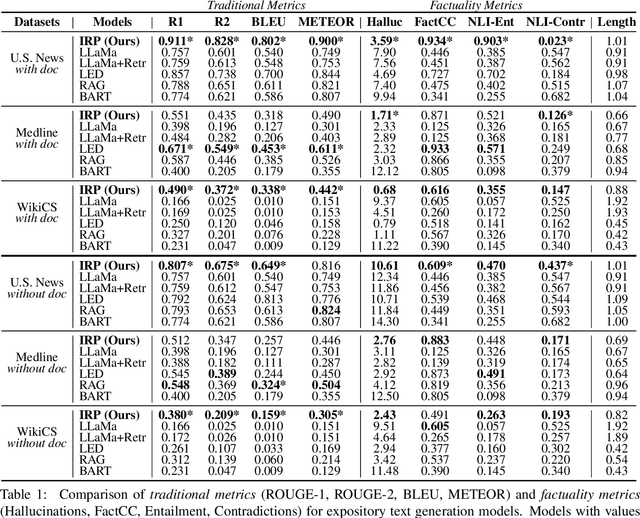
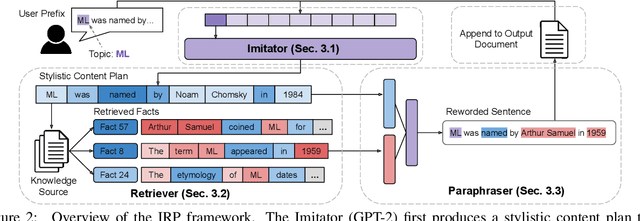
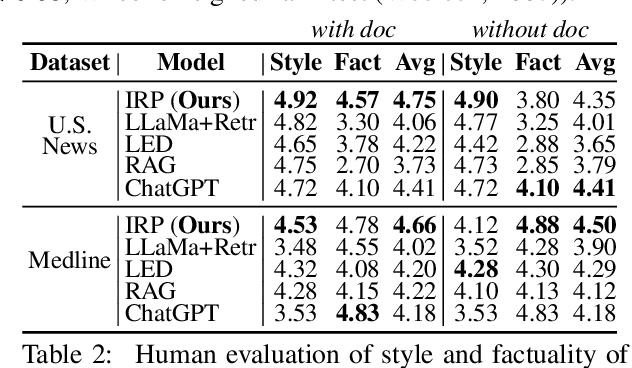
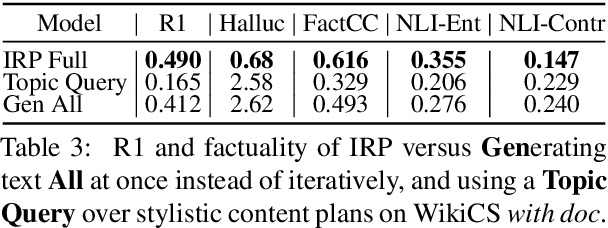
Expository documents are vital resources for conveying complex information to readers. Despite their usefulness, writing expository documents by hand is a time-consuming and labor-intensive process that requires knowledge of the domain of interest, careful content planning, and the ability to synthesize information from multiple sources. To ease these burdens, we introduce the task of expository text generation, which seeks to automatically generate an accurate and informative expository document from a knowledge source. We solve our task by developing IRP, an iterative framework that overcomes the limitations of language models and separately tackles the steps of content planning, fact selection, and rephrasing. Through experiments on three diverse datasets, we demonstrate that IRP produces high-quality expository documents that accurately inform readers.
Mining bias-target Alignment from Voronoi Cells
May 05, 2023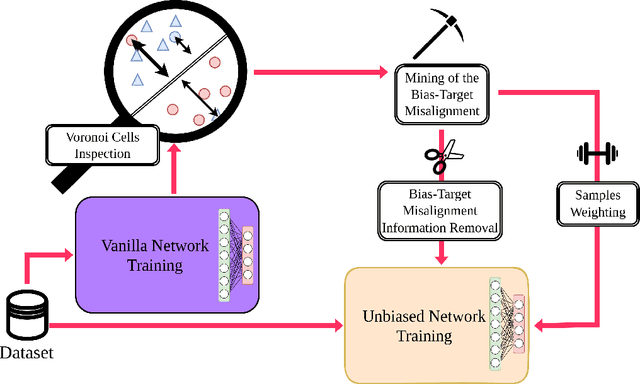
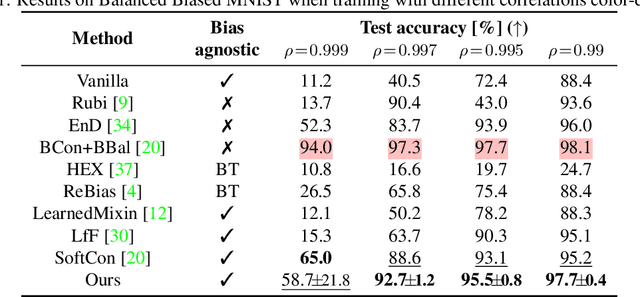
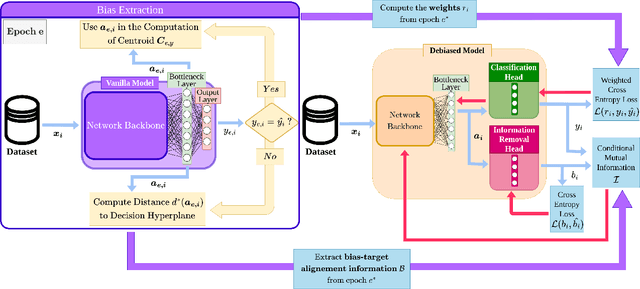
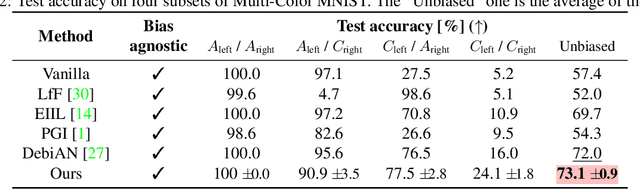
Despite significant research efforts, deep neural networks are still vulnerable to biases: this raises concerns about their fairness and limits their generalization. In this paper, we propose a bias-agnostic approach to mitigate the impact of bias in deep neural networks. Unlike traditional debiasing approaches, we rely on a metric to quantify ``bias alignment/misalignment'' on target classes, and use this information to discourage the propagation of bias-target alignment information through the network. We conduct experiments on several commonly used datasets for debiasing and compare our method to supervised and bias-specific approaches. Our results indicate that the proposed method achieves comparable performance to state-of-the-art supervised approaches, although it is bias-agnostic, even in presence of multiple biases in the same sample.
Deep Learning-Assisted Simultaneous Targets Sensing and Super-Resolution Imaging
May 02, 2023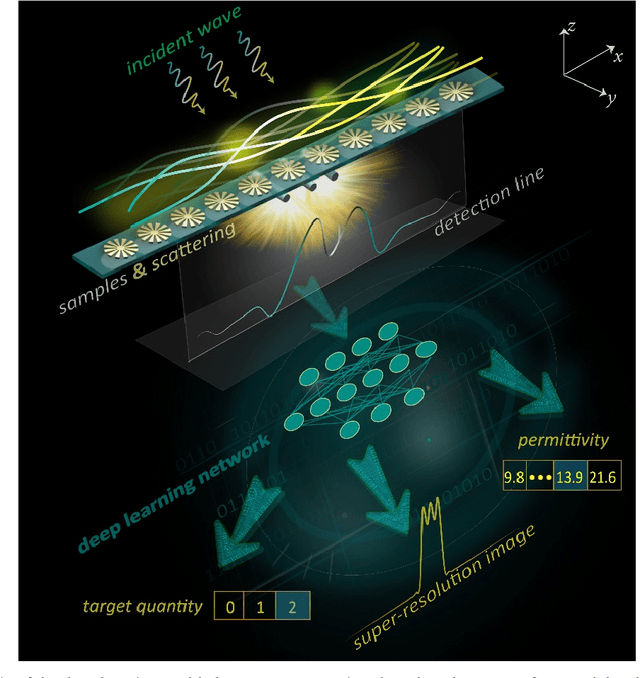
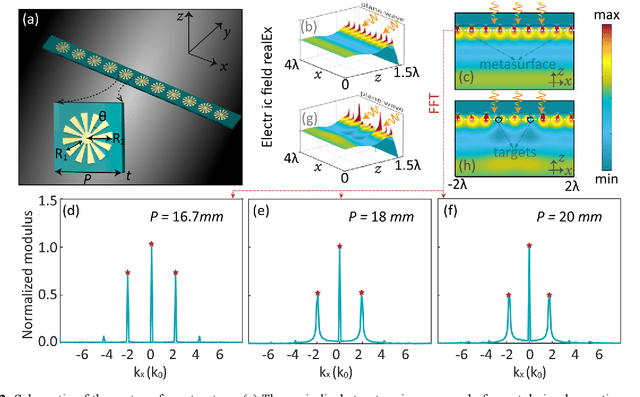
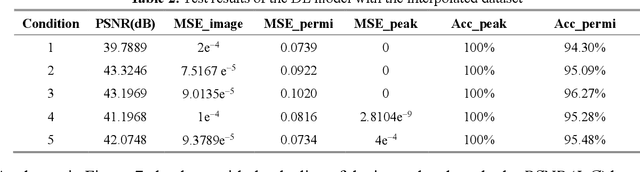
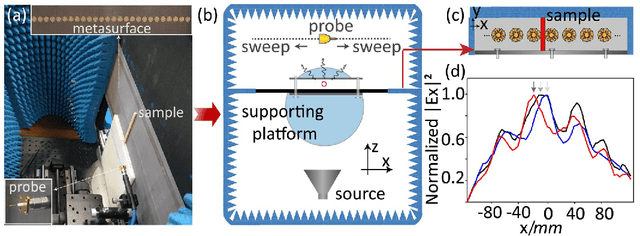
Recently, metasurfaces have experienced revolutionary growth in the sensing and superresolution imaging field, due to their enabling of subwavelength manipulation of electromagnetic waves. However, the addition of metasurfaces multiplies the complexity of retrieving target information from the detected fields. Besides, although the deep learning method affords a compelling platform for a series of electromagnetic problems, many studies mainly concentrate on resolving one single function and limit the research's versatility. In this study, a multifunctional deep neural network is demonstrated to reconstruct target information in a metasurface targets interactive system. Firstly, the interactive scenario is confirmed to tolerate the system noises in a primary verification experiment. Then, fed with the electric field distributions, the multitask deep neural network can not only sense the quantity and permittivity of targets but also generate superresolution images with high precision. The deep learning method provides another way to recover targets' diverse information in metasurface based target detection, accelerating the progression of target reconstruction areas. This methodology may also hold promise for inverse reconstruction or forward prediction problems in other electromagnetic scenarios.
Selective In-Context Data Augmentation for Intent Detection using Pointwise V-Information
Feb 10, 2023

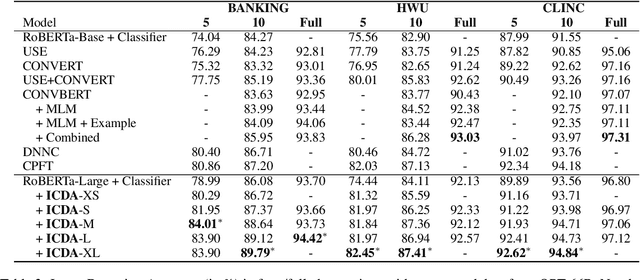
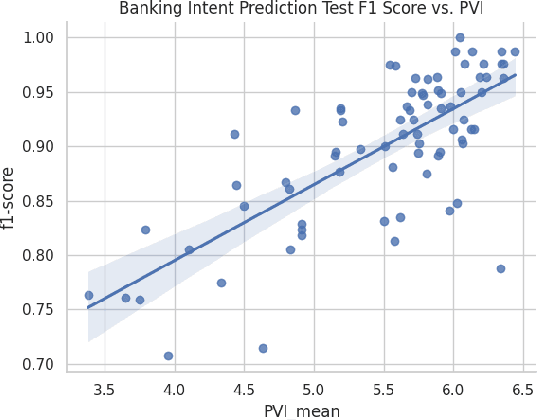
This work focuses on in-context data augmentation for intent detection. Having found that augmentation via in-context prompting of large pre-trained language models (PLMs) alone does not improve performance, we introduce a novel approach based on PLMs and pointwise V-information (PVI), a metric that can measure the usefulness of a datapoint for training a model. Our method first fine-tunes a PLM on a small seed of training data and then synthesizes new datapoints - utterances that correspond to given intents. It then employs intent-aware filtering, based on PVI, to remove datapoints that are not helpful to the downstream intent classifier. Our method is thus able to leverage the expressive power of large language models to produce diverse training data. Empirical results demonstrate that our method can produce synthetic training data that achieve state-of-the-art performance on three challenging intent detection datasets under few-shot settings (1.28% absolute improvement in 5-shot and 1.18% absolute in 10-shot, on average) and perform on par with the state-of-the-art in full-shot settings (within 0.01% absolute, on average).
Analogy in Contact: Modeling Maltese Plural Inflection
May 20, 2023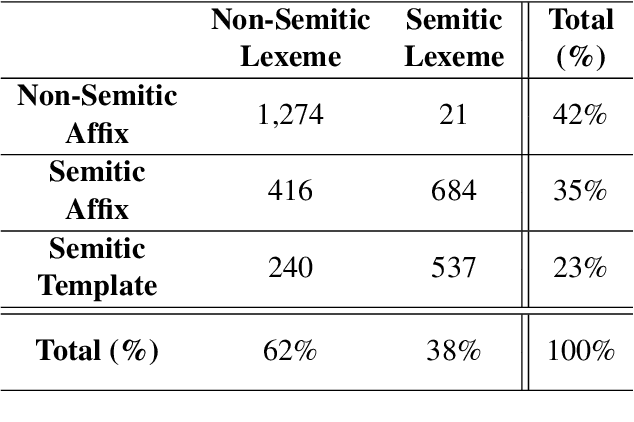
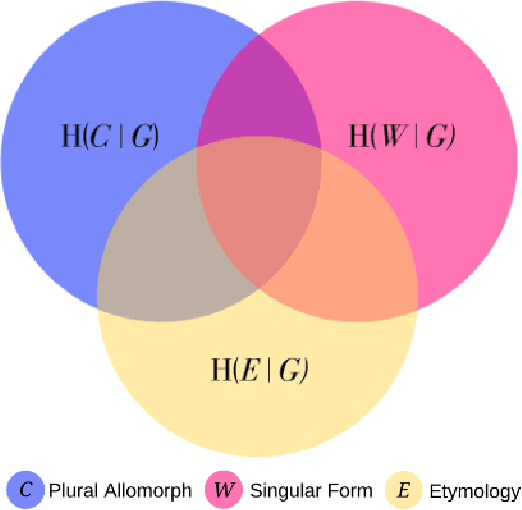
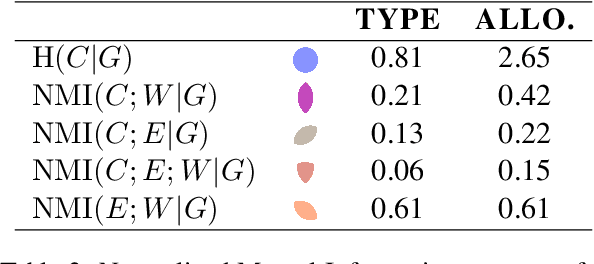
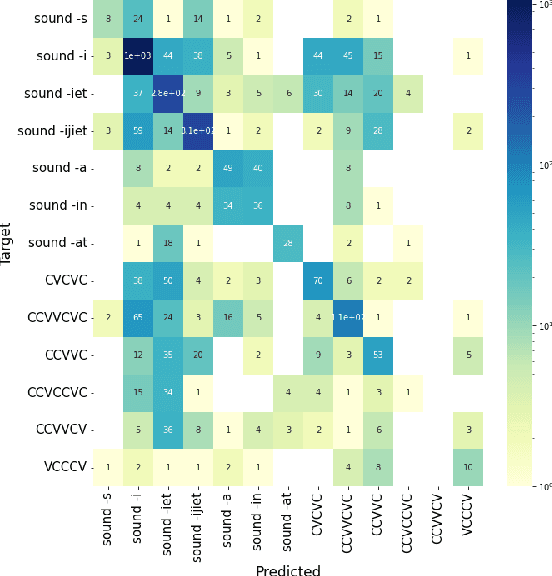
Maltese is often described as having a hybrid morphological system resulting from extensive contact between Semitic and Romance language varieties. Such a designation reflects an etymological divide as much as it does a larger tradition in the literature to consider concatenative and non-concatenative morphological patterns as distinct in the language architecture. Using a combination of computational modeling and information theoretic methods, we quantify the extent to which the phonology and etymology of a Maltese singular noun may predict the morphological process (affixal vs. templatic) as well as the specific plural allomorph (affix or template) relating a singular noun to its associated plural form(s) in the lexicon. The results indicate phonological pressures shape the organization of the Maltese lexicon with predictive power that extends beyond that of a word's etymology, in line with analogical theories of language change in contact.