 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Attentive Graph-based Text-aware Preference Modeling for Top-N Recommendation
May 22, 2023

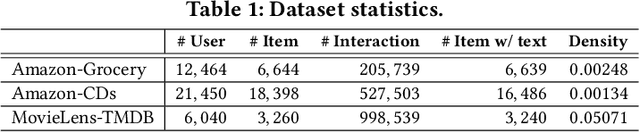
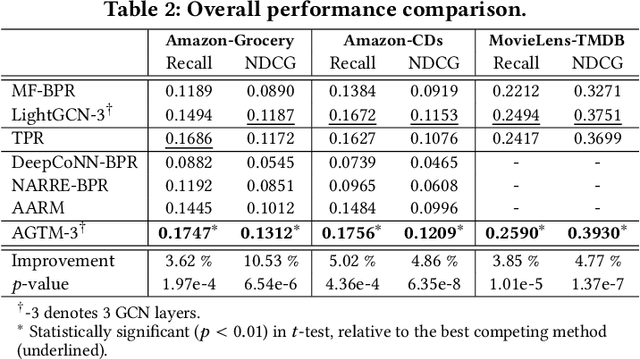
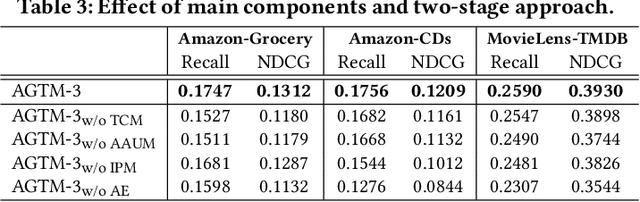
Textual data are commonly used as auxiliary information for modeling user preference nowadays. While many prior works utilize user reviews for rating prediction, few focus on top-N recommendation, and even few try to incorporate item textual contents such as title and description. Though delivering promising performance for rating prediction, we empirically find that many review-based models cannot perform comparably well on top-N recommendation. Also, user reviews are not available in some recommendation scenarios, while item textual contents are more prevalent. On the other hand, recent graph convolutional network (GCN) based models demonstrate state-of-the-art performance for top-N recommendation. Thus, in this work, we aim to further improve top-N recommendation by effectively modeling both item textual content and high-order connectivity in user-item graph. We propose a new model named Attentive Graph-based Text-aware Recommendation Model (AGTM). Extensive experiments are provided to justify the rationality and effectiveness of our model design.
Open-Domain Event Graph Induction for Mitigating Framing Bias
May 22, 2023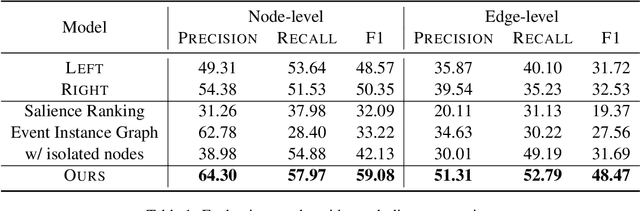
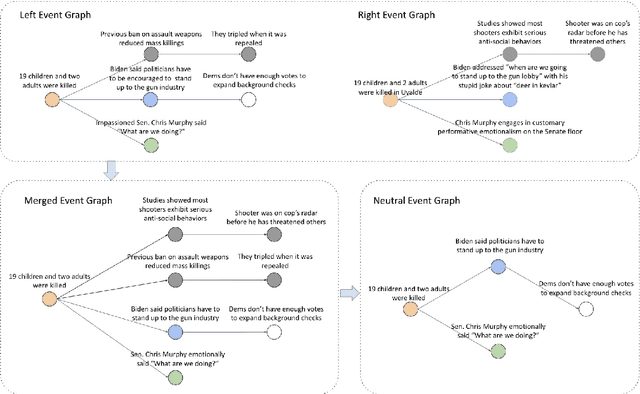
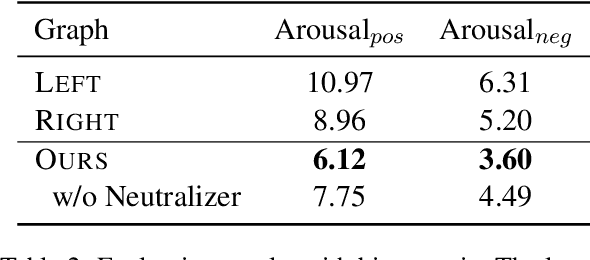

Researchers have proposed various information extraction (IE) techniques to convert news articles into structured knowledge for news understanding. However, none of the existing methods have explicitly addressed the issue of framing bias that is inherent in news articles. We argue that studying and identifying framing bias is a crucial step towards trustworthy event understanding. We propose a novel task, neutral event graph induction, to address this problem. An event graph is a network of events and their temporal relations. Our task aims to induce such structural knowledge with minimal framing bias in an open domain. We propose a three-step framework to induce a neutral event graph from multiple input sources. The process starts by inducing an event graph from each input source, then merging them into one merged event graph, and lastly using a Graph Convolutional Network to remove event nodes with biased connotations. We demonstrate the effectiveness of our framework through the use of graph prediction metrics and bias-focused metrics.
Graph Neural Network for spatiotemporal data: methods and applications
May 30, 2023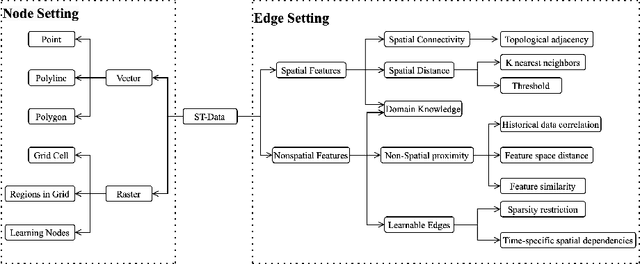

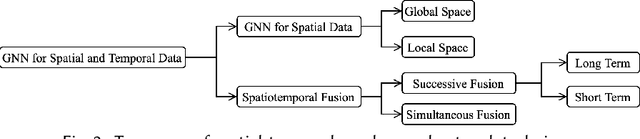
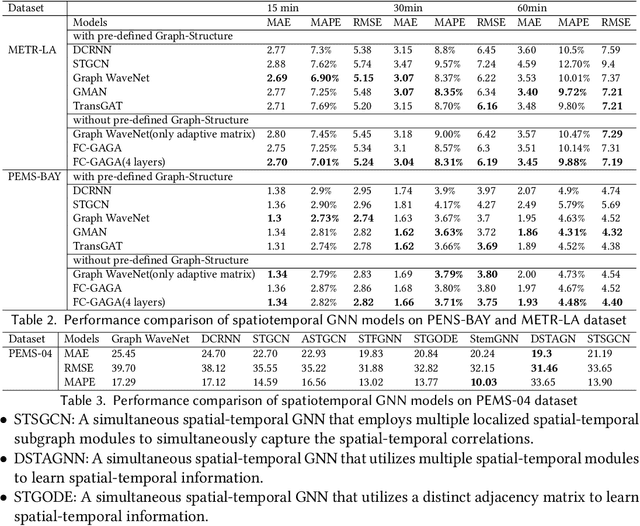
In the era of big data, there has been a surge in the availability of data containing rich spatial and temporal information, offering valuable insights into dynamic systems and processes for applications such as weather forecasting, natural disaster management, intelligent transport systems, and precision agriculture. Graph neural networks (GNNs) have emerged as a powerful tool for modeling and understanding data with dependencies to each other such as spatial and temporal dependencies. There is a large amount of existing work that focuses on addressing the complex spatial and temporal dependencies in spatiotemporal data using GNNs. However, the strong interdisciplinary nature of spatiotemporal data has created numerous GNNs variants specifically designed for distinct application domains. Although the techniques are generally applicable across various domains, cross-referencing these methods remains essential yet challenging due to the absence of a comprehensive literature review on GNNs for spatiotemporal data. This article aims to provide a systematic and comprehensive overview of the technologies and applications of GNNs in the spatiotemporal domain. First, the ways of constructing graphs from spatiotemporal data are summarized to help domain experts understand how to generate graphs from various types of spatiotemporal data. Then, a systematic categorization and summary of existing spatiotemporal GNNs are presented to enable domain experts to identify suitable techniques and to support model developers in advancing their research. Moreover, a comprehensive overview of significant applications in the spatiotemporal domain is offered to introduce a broader range of applications to model developers and domain experts, assisting them in exploring potential research topics and enhancing the impact of their work. Finally, open challenges and future directions are discussed.
Multi-source adversarial transfer learning for ultrasound image segmentation with limited similarity
May 30, 2023
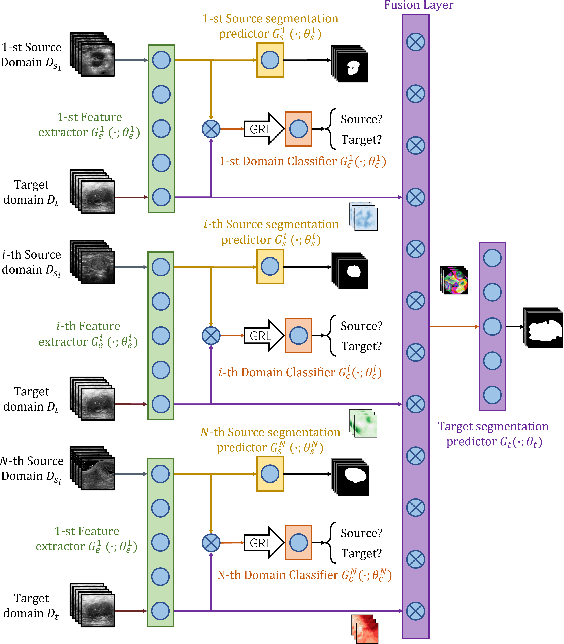
Lesion segmentation of ultrasound medical images based on deep learning techniques is a widely used method for diagnosing diseases. Although there is a large amount of ultrasound image data in medical centers and other places, labeled ultrasound datasets are a scarce resource, and it is likely that no datasets are available for new tissues/organs. Transfer learning provides the possibility to solve this problem, but there are too many features in natural images that are not related to the target domain. As a source domain, redundant features that are not conducive to the task will be extracted. Migration between ultrasound images can avoid this problem, but there are few types of public datasets, and it is difficult to find sufficiently similar source domains. Compared with natural images, ultrasound images have less information, and there are fewer transferable features between different ultrasound images, which may cause negative transfer. To this end, a multi-source adversarial transfer learning network for ultrasound image segmentation is proposed. Specifically, to address the lack of annotations, the idea of adversarial transfer learning is used to adaptively extract common features between a certain pair of source and target domains, which provides the possibility to utilize unlabeled ultrasound data. To alleviate the lack of knowledge in a single source domain, multi-source transfer learning is adopted to fuse knowledge from multiple source domains. In order to ensure the effectiveness of the fusion and maximize the use of precious data, a multi-source domain independent strategy is also proposed to improve the estimation of the target domain data distribution, which further increases the learning ability of the multi-source adversarial migration learning network in multiple domains.
Netizens, Academicians, and Information Professionals' Opinions About AI With Special Reference To ChatGPT
Feb 01, 2023
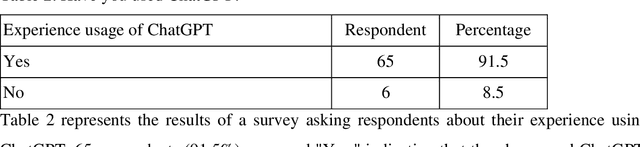
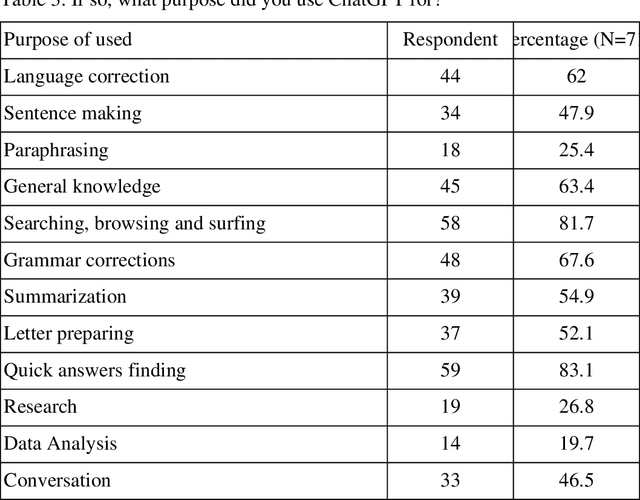
This study aims to understand the perceptions and opinions of academicians towards ChatGPT-3 by collecting and analyzing social media comments, and a survey was conducted with library and information science professionals. The research uses a content analysis method and finds that while ChatGPT-3 can be a valuable tool for research and writing, it is not 100% accurate and should be cross-checked. The study also finds that while some academicians may not accept ChatGPT-3, most are starting to accept it. The study is beneficial for academicians, content developers, and librarians.
Optimization's Neglected Normative Commitments
May 27, 2023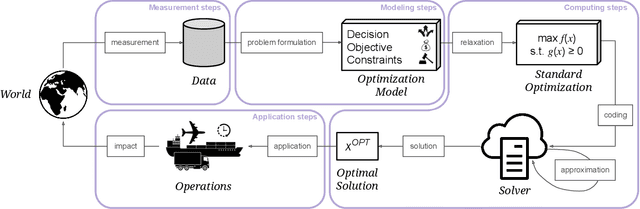
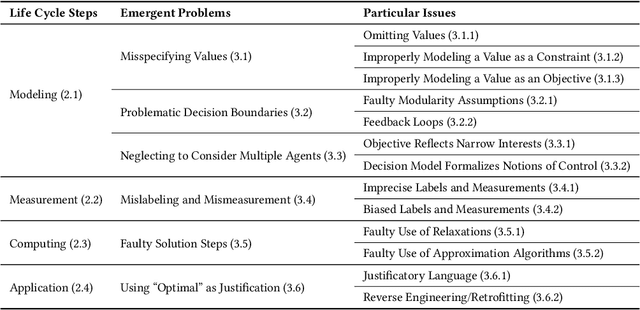
Optimization is offered as an objective approach to resolving complex, real-world decisions involving uncertainty and conflicting interests. It drives business strategies as well as public policies and, increasingly, lies at the heart of sophisticated machine learning systems. A paradigm used to approach potentially high-stakes decisions, optimization relies on abstracting the real world to a set of decision(s), objective(s) and constraint(s). Drawing from the modeling process and a range of actual cases, this paper describes the normative choices and assumptions that are necessarily part of using optimization. It then identifies six emergent problems that may be neglected: 1) Misspecified values can yield optimizations that omit certain imperatives altogether or incorporate them incorrectly as a constraint or as part of the objective, 2) Problematic decision boundaries can lead to faulty modularity assumptions and feedback loops, 3) Failing to account for multiple agents' divergent goals and decisions can lead to policies that serve only certain narrow interests, 4) Mislabeling and mismeasurement can introduce bias and imprecision, 5) Faulty use of relaxation and approximation methods, unaccompanied by formal characterizations and guarantees, can severely impede applicability, and 6) Treating optimization as a justification for action, without specifying the necessary contextual information, can lead to ethically dubious or faulty decisions. Suggestions are given to further understand and curb the harms that can arise when optimization is used wrongfully.
Accelerate Langevin Sampling with Birth-Death process and Exploration Component
May 06, 2023Sampling a probability distribution with known likelihood is a fundamental task in computational science and engineering. Aiming at multimodality, we propose a new sampling method that takes advantage of both birth-death process and exploration component. The main idea of this method is \textit{look before you leap}. We keep two sets of samplers, one at warmer temperature and one at original temperature. The former one serves as pioneer in exploring new modes and passing useful information to the other, while the latter one samples the target distribution after receiving the information. We derive a mean-field limit and show how the exploration process determines sampling efficiency. Moreover, we prove exponential asymptotic convergence under mild assumption. Finally, we test on experiments from previous literature and compared our methodology to previous ones.
Diff-Instruct: A Universal Approach for Transferring Knowledge From Pre-trained Diffusion Models
May 29, 2023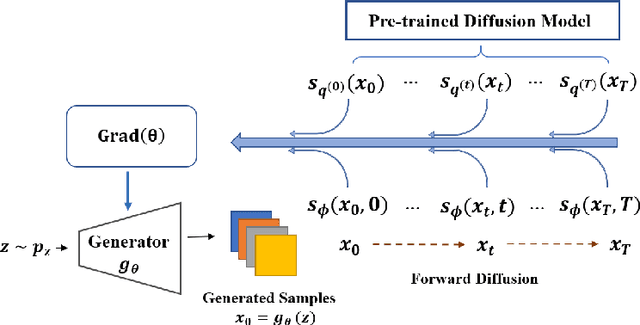
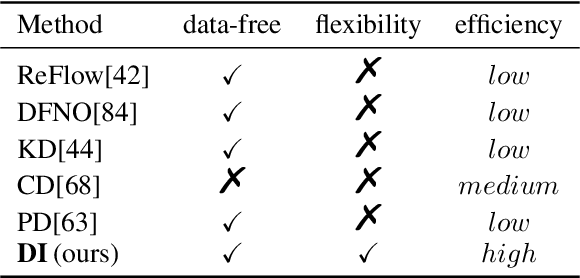

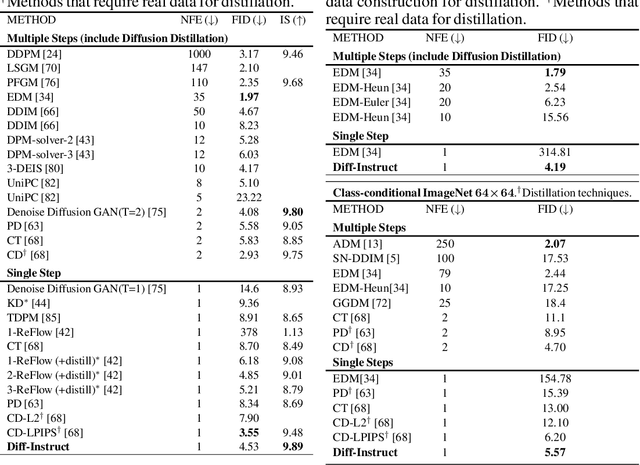
Due to the ease of training, ability to scale, and high sample quality, diffusion models (DMs) have become the preferred option for generative modeling, with numerous pre-trained models available for a wide variety of datasets. Containing intricate information about data distributions, pre-trained DMs are valuable assets for downstream applications. In this work, we consider learning from pre-trained DMs and transferring their knowledge to other generative models in a data-free fashion. Specifically, we propose a general framework called Diff-Instruct to instruct the training of arbitrary generative models as long as the generated samples are differentiable with respect to the model parameters. Our proposed Diff-Instruct is built on a rigorous mathematical foundation where the instruction process directly corresponds to minimizing a novel divergence we call Integral Kullback-Leibler (IKL) divergence. IKL is tailored for DMs by calculating the integral of the KL divergence along a diffusion process, which we show to be more robust in comparing distributions with misaligned supports. We also reveal non-trivial connections of our method to existing works such as DreamFusion, and generative adversarial training. To demonstrate the effectiveness and universality of Diff-Instruct, we consider two scenarios: distilling pre-trained diffusion models and refining existing GAN models. The experiments on distilling pre-trained diffusion models show that Diff-Instruct results in state-of-the-art single-step diffusion-based models. The experiments on refining GAN models show that the Diff-Instruct can consistently improve the pre-trained generators of GAN models across various settings.
chatClimate: Grounding Conversational AI in Climate Science
Apr 28, 2023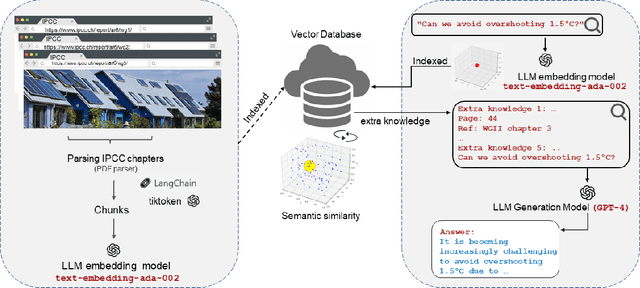
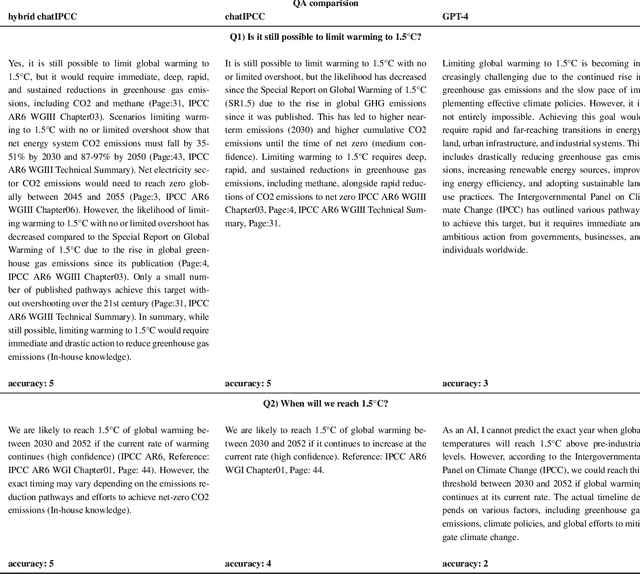

Large Language Models (LLMs) have made significant progress in recent years, achieving remarkable results in question-answering tasks (QA). However, they still face two major challenges: hallucination and outdated information after the training phase. These challenges take center stage in critical domains like climate change, where obtaining accurate and up-to-date information from reliable sources in a limited time is essential and difficult. To overcome these barriers, one potential solution is to provide LLMs with access to external, scientifically accurate, and robust sources (long-term memory) to continuously update their knowledge and prevent the propagation of inaccurate, incorrect, or outdated information. In this study, we enhanced GPT-4 by integrating the information from the Sixth Assessment Report of the Intergovernmental (IPCC AR6), the most comprehensive, up-to-date, and reliable source in this domain. We present our conversational AI prototype, available at www.chatclimate.ai and demonstrate its ability to answer challenging questions accurately in three different QA scenarios: asking from 1) GPT-4, 2) chatClimate, and 3) hybrid chatClimate. The answers and their sources were evaluated by our team of IPCC authors, who used their expert knowledge to score the accuracy of the answers from 1 (very-low) to 5 (very-high). The evaluation showed that the hybrid chatClimate provided more accurate answers, highlighting the effectiveness of our solution. This approach can be easily scaled for chatbots in specific domains, enabling the delivery of reliable and accurate information.
Semantic VAD: Low-Latency Voice Activity Detection for Speech Interaction
May 21, 2023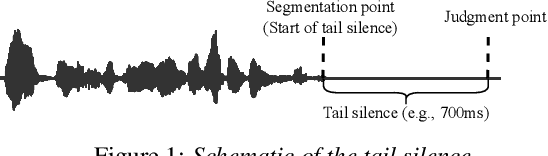
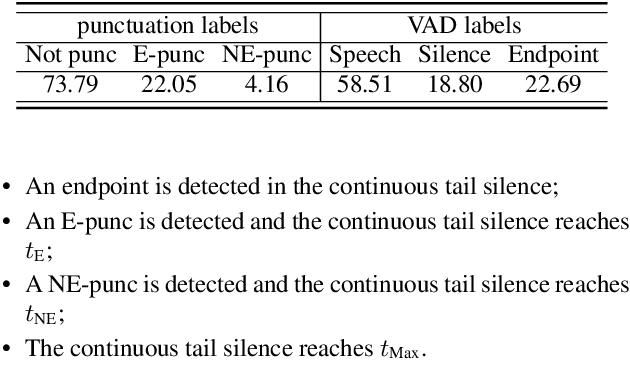
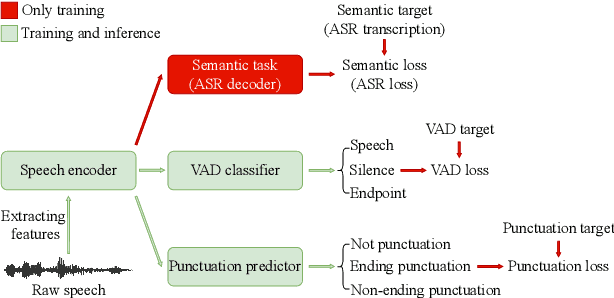
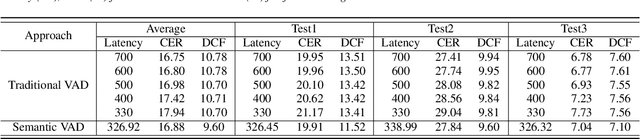
For speech interaction, voice activity detection (VAD) is often used as a front-end. However, traditional VAD algorithms usually need to wait for a continuous tail silence to reach a preset maximum duration before segmentation, resulting in a large latency that affects user experience. In this paper, we propose a novel semantic VAD for low-latency segmentation. Different from existing methods, a frame-level punctuation prediction task is added to the semantic VAD, and the artificial endpoint is included in the classification category in addition to the often-used speech presence and absence. To enhance the semantic information of the model, we also incorporate an automatic speech recognition (ASR) related semantic loss. Evaluations on an internal dataset show that the proposed method can reduce the average latency by 53.3% without significant deterioration of character error rate in the back-end ASR compared to the traditional VAD approach.