 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning Occupancy for Monocular 3D Object Detection
May 25, 2023
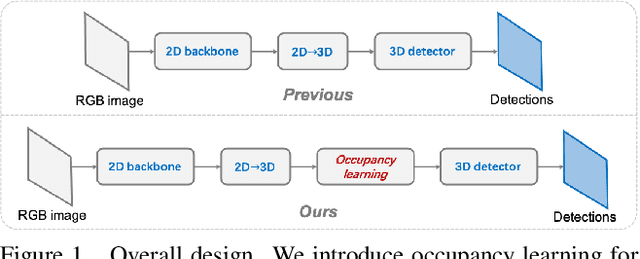
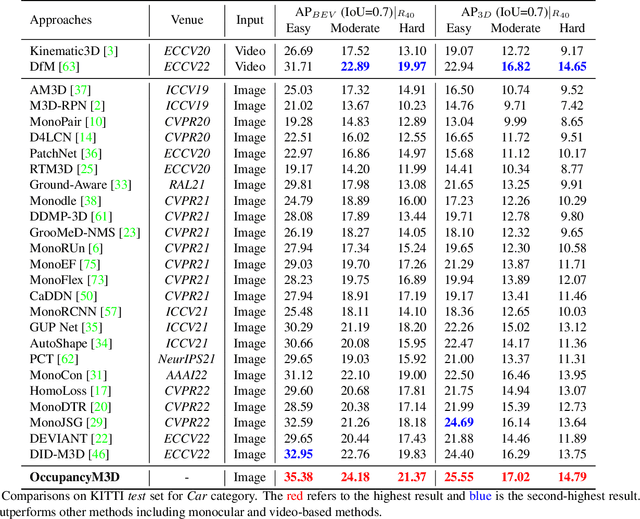
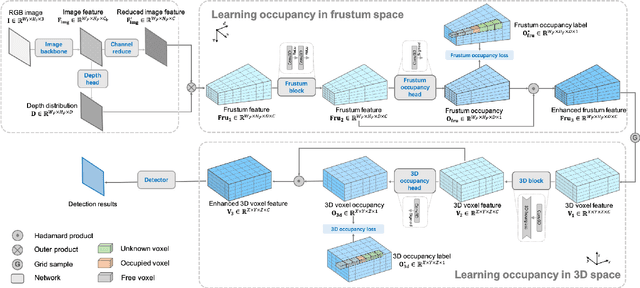
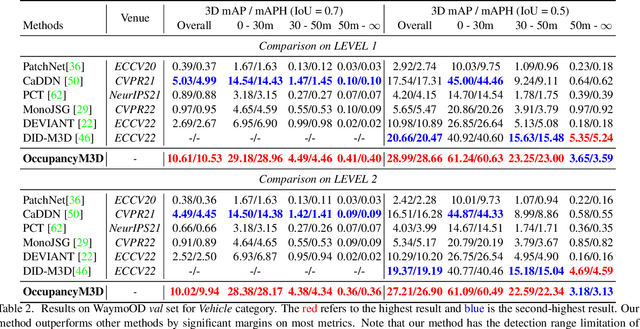
Monocular 3D detection is a challenging task due to the lack of accurate 3D information. Existing approaches typically rely on geometry constraints and dense depth estimates to facilitate the learning, but often fail to fully exploit the benefits of three-dimensional feature extraction in frustum and 3D space. In this paper, we propose \textbf{OccupancyM3D}, a method of learning occupancy for monocular 3D detection. It directly learns occupancy in frustum and 3D space, leading to more discriminative and informative 3D features and representations. Specifically, by using synchronized raw sparse LiDAR point clouds, we define the space status and generate voxel-based occupancy labels. We formulate occupancy prediction as a simple classification problem and design associated occupancy losses. Resulting occupancy estimates are employed to enhance original frustum/3D features. As a result, experiments on KITTI and Waymo open datasets demonstrate that the proposed method achieves a new state of the art and surpasses other methods by a significant margin. Codes and pre-trained models will be available at \url{https://github.com/SPengLiang/OccupancyM3D}.
NODDLE: Node2vec based deep learning model for link prediction
May 25, 2023Computing the probability of an edge's existence in a graph network is known as link prediction. While traditional methods calculate the similarity between two given nodes in a static network, recent research has focused on evaluating networks that evolve dynamically. Although deep learning techniques and network representation learning algorithms, such as node2vec, show remarkable improvements in prediction accuracy, the Stochastic Gradient Descent (SGD) method of node2vec tends to fall into a mediocre local optimum value due to a shortage of prior network information, resulting in failure to capture the global structure of the network. To tackle this problem, we propose NODDLE (integration of NOde2vec anD Deep Learning mEthod), a deep learning model which incorporates the features extracted by node2vec and feeds them into a four layer hidden neural network. NODDLE takes advantage of adaptive learning optimizers such as Adam, Adamax, Adadelta, and Adagrad to improve the performance of link prediction. Experimental results show that this method yields better results than the traditional methods on various social network datasets.
Collective Knowledge Graph Completion with Mutual Knowledge Distillation
May 25, 2023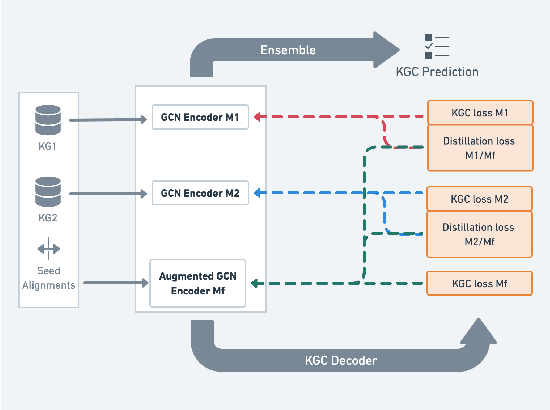
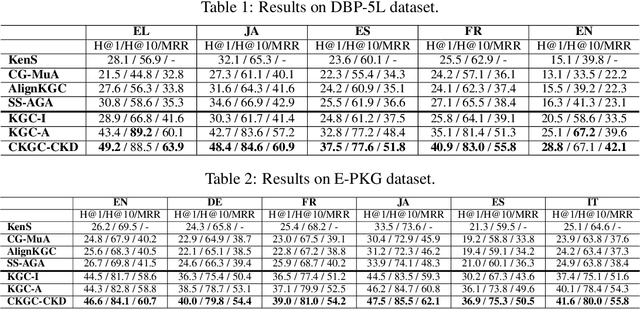
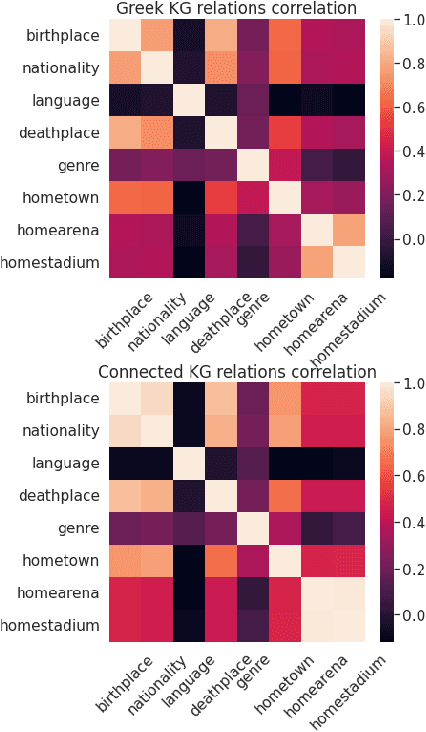
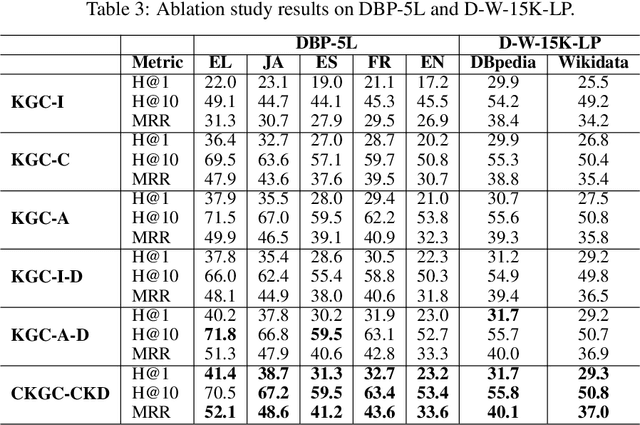
Knowledge graph completion (KGC), the task of predicting missing information based on the existing relational data inside a knowledge graph (KG), has drawn significant attention in recent years. However, the predictive power of KGC methods is often limited by the completeness of the existing knowledge graphs from different sources and languages. In monolingual and multilingual settings, KGs are potentially complementary to each other. In this paper, we study the problem of multi-KG completion, where we focus on maximizing the collective knowledge from different KGs to alleviate the incompleteness of individual KGs. Specifically, we propose a novel method called CKGC-CKD that uses relation-aware graph convolutional network encoder models on both individual KGs and a large fused KG in which seed alignments between KGs are regarded as edges for message propagation. An additional mutual knowledge distillation mechanism is also employed to maximize the knowledge transfer between the models of "global" fused KG and the "local" individual KGs. Experimental results on multilingual datasets have shown that our method outperforms all state-of-the-art models in the KGC task.
TabGSL: Graph Structure Learning for Tabular Data Prediction
May 25, 2023
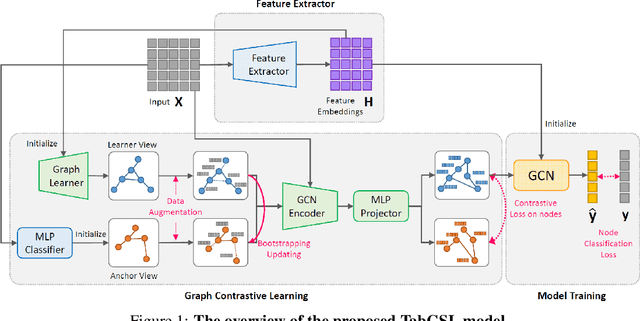

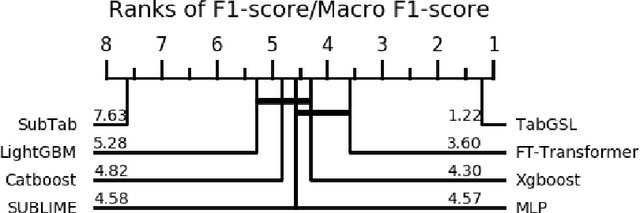
This work presents a novel approach to tabular data prediction leveraging graph structure learning and graph neural networks. Despite the prevalence of tabular data in real-world applications, traditional deep learning methods often overlook the potentially valuable associations between data instances. Such associations can offer beneficial insights for classification tasks, as instances may exhibit similar patterns of correlations among features and target labels. This information can be exploited by graph neural networks, necessitating robust graph structures. However, existing studies primarily focus on improving graph structure from noisy data, largely neglecting the possibility of deriving graph structures from tabular data. We present a novel solution, Tabular Graph Structure Learning (TabGSL), to enhance tabular data prediction by simultaneously learning instance correlation and feature interaction within a unified framework. This is achieved through a proposed graph contrastive learning module, along with transformer-based feature extractor and graph neural network. Comprehensive experiments conducted on 30 benchmark tabular datasets demonstrate that TabGSL markedly outperforms both tree-based models and recent deep learning-based tabular models. Visualizations of the learned instance embeddings further substantiate the effectiveness of TabGSL.
Towards a Capability Assessment Model for the Comprehension and Adoption of AI in Organisations
May 25, 2023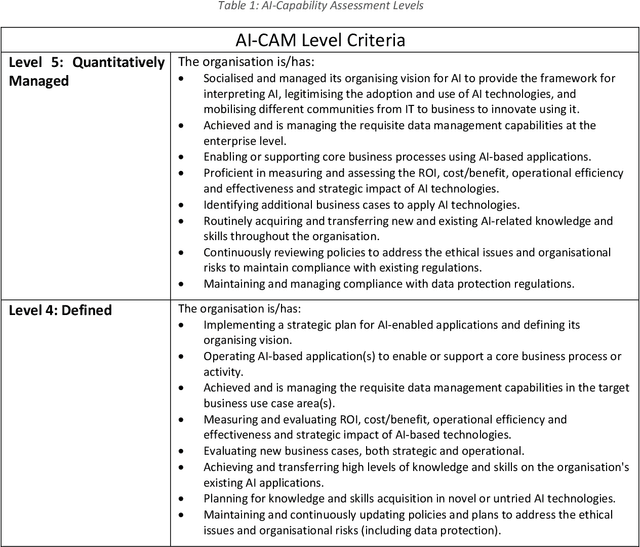
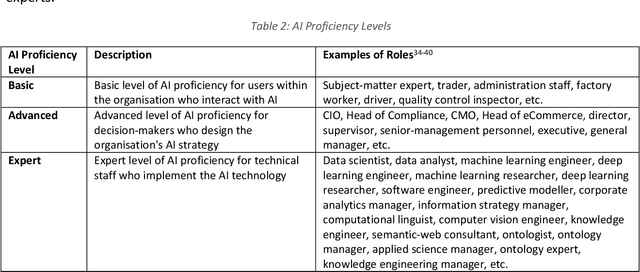
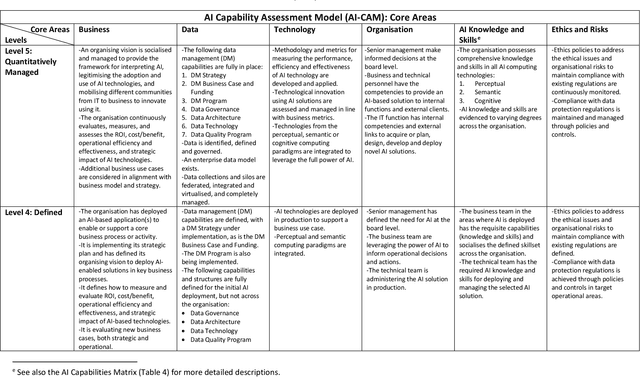
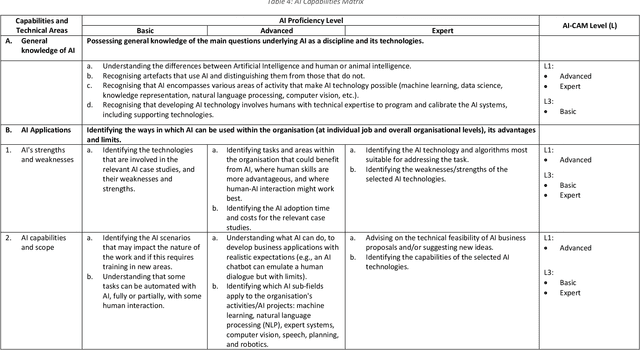
The comprehension and adoption of Artificial Intelligence (AI) are beset with practical and ethical problems. This article presents a 5-level AI Capability Assessment Model (AI-CAM) and a related AI Capabilities Matrix (AI-CM) to assist practitioners in AI comprehension and adoption. These practical tools were developed with business executives, technologists, and other organisational stakeholders in mind. They are founded on a comprehensive conception of AI compared to those in other AI adoption models and are also open-source artefacts. Thus, the AI-CAM and AI-CM present an accessible resource to help inform organisational decision-makers on the capability requirements for (1) AI-based data analytics use cases based on machine learning technologies; (2) Knowledge representation to engineer and represent data, information and knowledge using semantic technologies; and (3) AI-based solutions that seek to emulate human reasoning and decision-making. The AI-CAM covers the core capability dimensions (business, data, technology, organisation, AI skills, risks, and ethical considerations) required at the five capability maturity levels to achieve optimal use of AI in organisations.
Betray Oneself: A Novel Audio DeepFake Detection Model via Mono-to-Stereo Conversion
May 25, 2023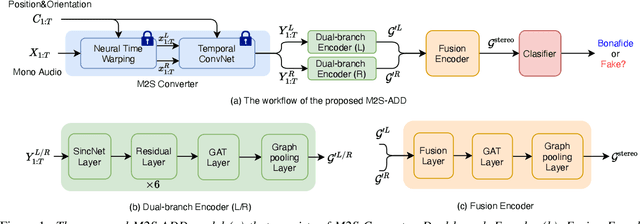
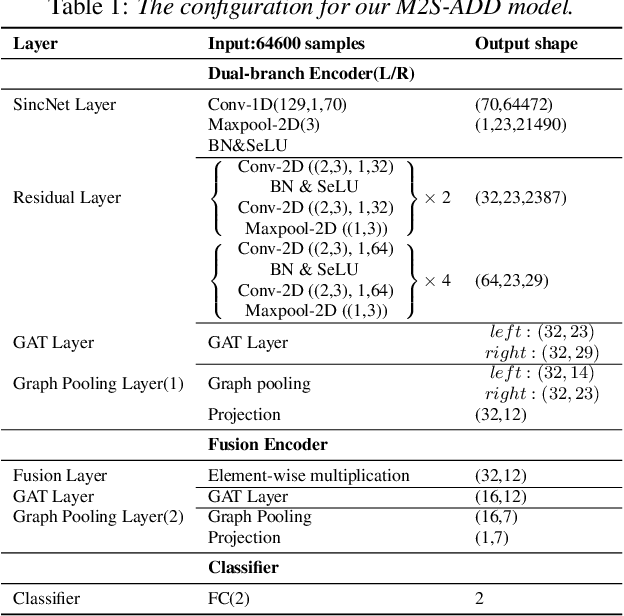
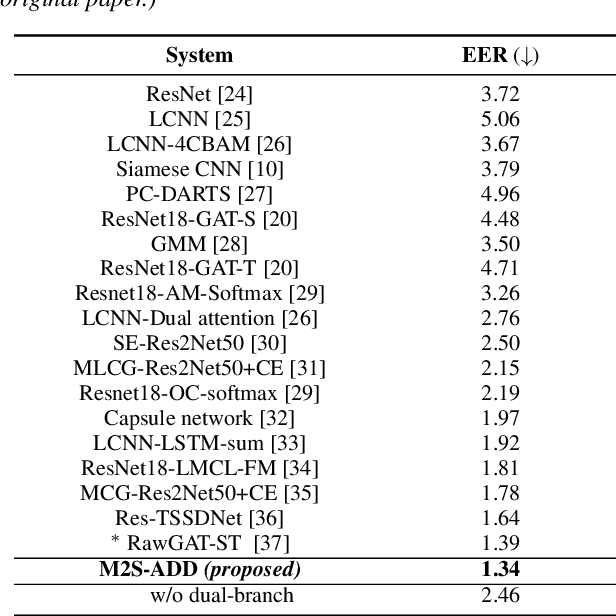
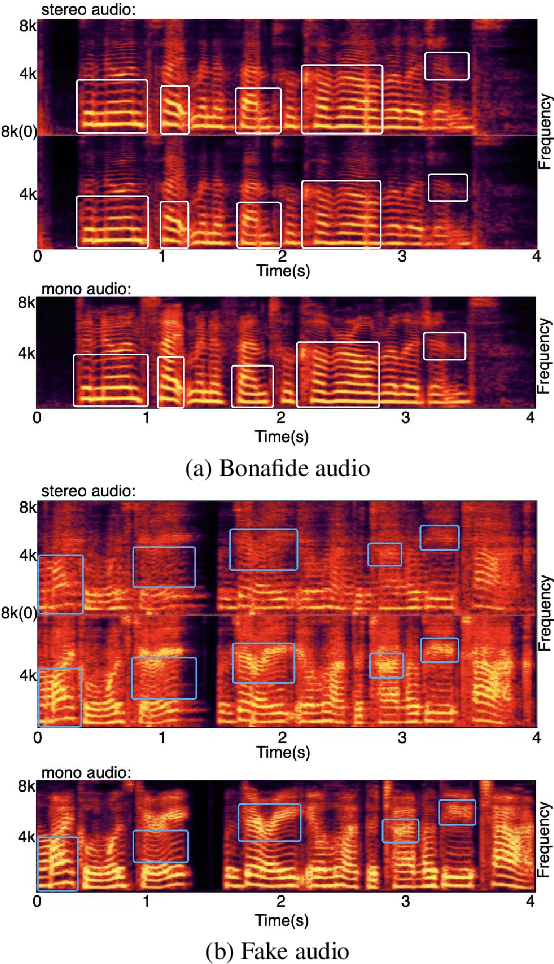
Audio Deepfake Detection (ADD) aims to detect the fake audio generated by text-to-speech (TTS), voice conversion (VC) and replay, etc., which is an emerging topic. Traditionally we take the mono signal as input and focus on robust feature extraction and effective classifier design. However, the dual-channel stereo information in the audio signal also includes important cues for deepfake, which has not been studied in the prior work. In this paper, we propose a novel ADD model, termed as M2S-ADD, that attempts to discover audio authenticity cues during the mono-to-stereo conversion process. We first projects the mono to a stereo signal using a pretrained stereo synthesizer, then employs a dual-branch neural architecture to process the left and right channel signals, respectively. In this way, we effectively reveal the artifacts in the fake audio, thus improve the ADD performance. The experiments on the ASVspoof2019 database show that M2S-ADD outperforms all baselines that input mono. We release the source code at \url{https://github.com/AI-S2-Lab/M2S-ADD}.
Dynamic Enhancement Network for Partial Multi-modality Person Re-identification
May 25, 2023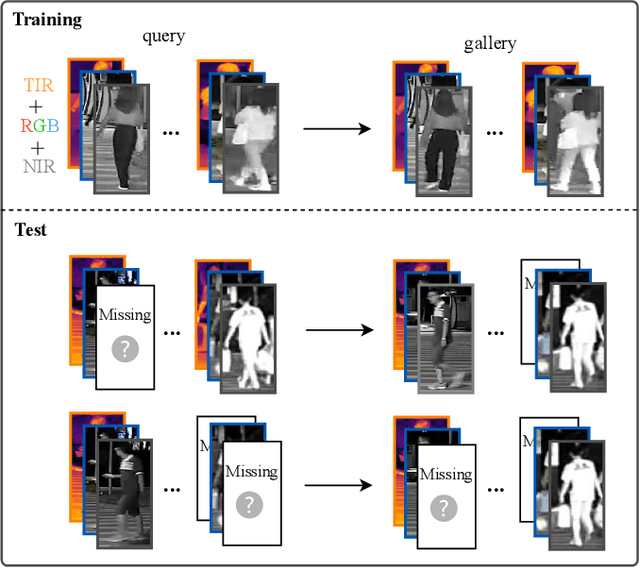
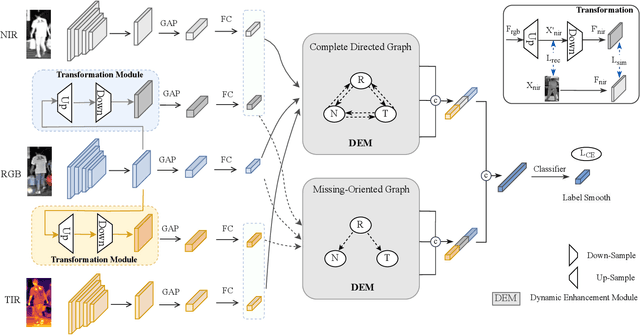
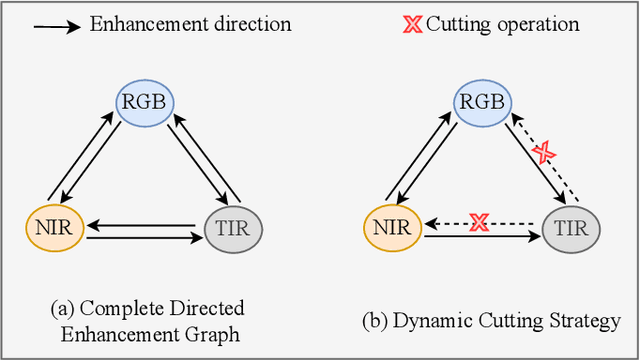
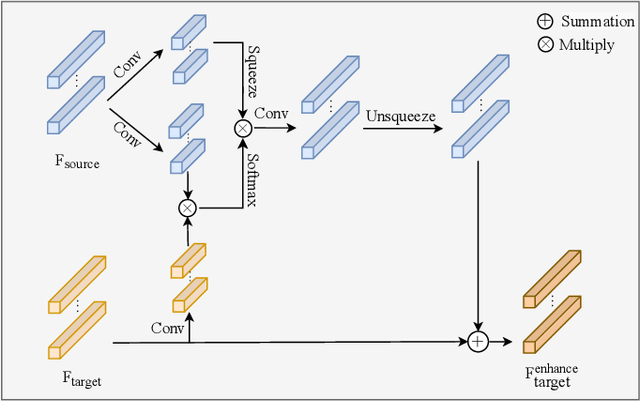
Many existing multi-modality studies are based on the assumption of modality integrity. However, the problem of missing arbitrary modalities is very common in real life, and this problem is less studied, but actually important in the task of multi-modality person re-identification (Re-ID). To this end, we design a novel dynamic enhancement network (DENet), which allows missing arbitrary modalities while maintaining the representation ability of multiple modalities, for partial multi-modality person Re-ID. To be specific, the multi-modal representation of the RGB, near-infrared (NIR) and thermal-infrared (TIR) images is learned by three branches, in which the information of missing modalities is recovered by the feature transformation module. Since the missing state might be changeable, we design a dynamic enhancement module, which dynamically enhances modality features according to the missing state in an adaptive manner, to improve the multi-modality representation. Extensive experiments on multi-modality person Re-ID dataset RGBNT201 and vehicle Re-ID dataset RGBNT100 comparing to the state-of-the-art methods verify the effectiveness of our method in complex and changeable environments.
Response Length Perception and Sequence Scheduling: An LLM-Empowered LLM Inference Pipeline
May 22, 2023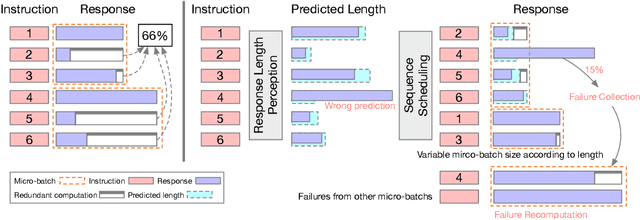

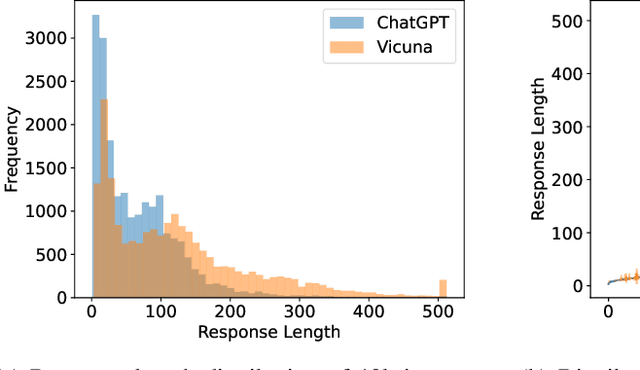
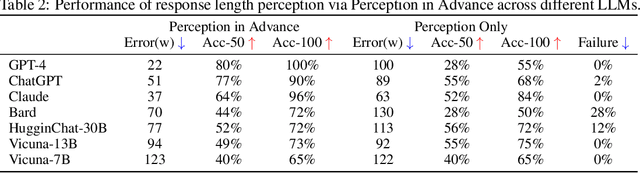
Large language models (LLMs) have revolutionized the field of AI, demonstrating unprecedented capacity across various tasks. However, the inference process for LLMs comes with significant computational costs. In this paper, we propose an efficient LLM inference pipeline that harnesses the power of LLMs. Our approach begins by tapping into the potential of LLMs to accurately perceive and predict the response length with minimal overhead. By leveraging this information, we introduce an efficient sequence scheduling technique that groups queries with similar response lengths into micro-batches. We evaluate our approach on real-world instruction datasets using the LLaMA-based model, and our results demonstrate an impressive 86% improvement in inference throughput without compromising effectiveness. Notably, our method is orthogonal to other inference acceleration techniques, making it a valuable addition to many existing toolkits (e.g., FlashAttention, Quantization) for LLM inference.
Prompt-based methods may underestimate large language models' linguistic generalizations
May 22, 2023
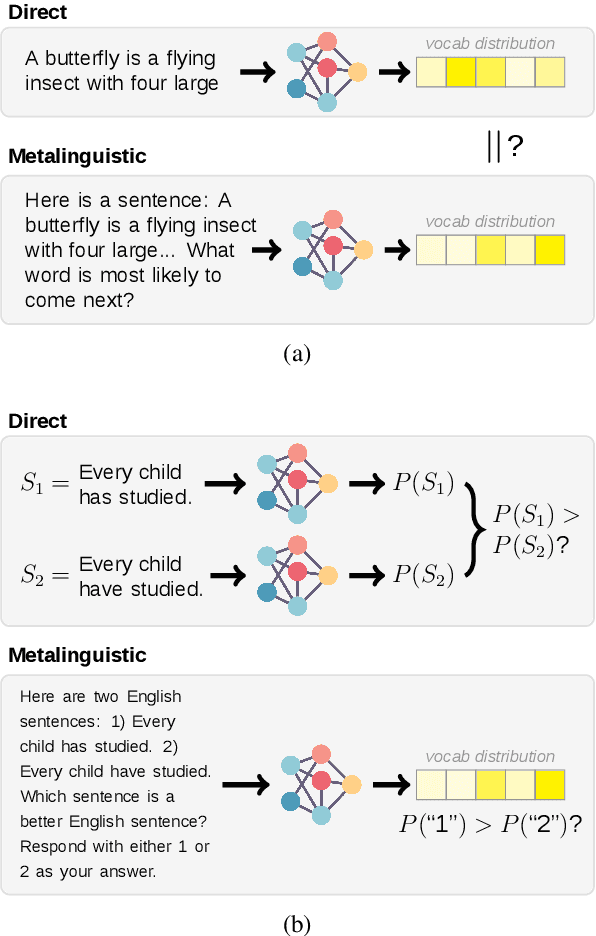

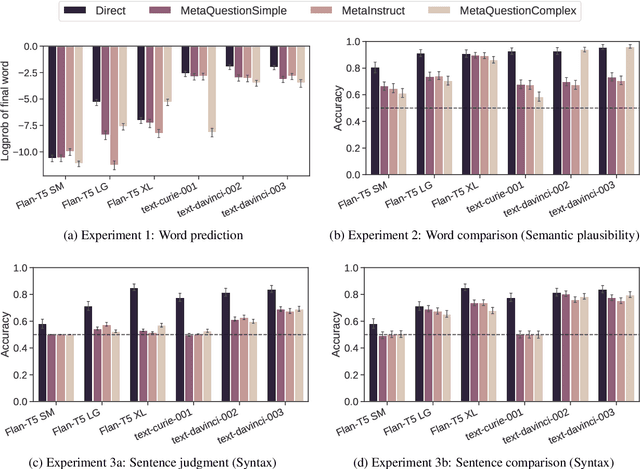
Prompting is now a dominant method for evaluating the linguistic knowledge of large language models (LLMs). While other methods directly read out models' probability distributions over strings, prompting requires models to access this internal information by processing linguistic input, thereby implicitly testing a new type of emergent ability: metalinguistic judgment. In this study, we compare metalinguistic prompting and direct probability measurements as ways of measuring models' knowledge of English. Broadly, we find that LLMs' metalinguistic judgments are inferior to quantities directly derived from representations. Furthermore, consistency gets worse as the prompt diverges from direct measurements of next-word probabilities. Our findings suggest that negative results relying on metalinguistic prompts cannot be taken as conclusive evidence that an LLM lacks a particular linguistic competence. Our results also highlight the lost value with the move to closed APIs where access to probability distributions is limited.
Bayesian Numerical Integration with Neural Networks
May 22, 2023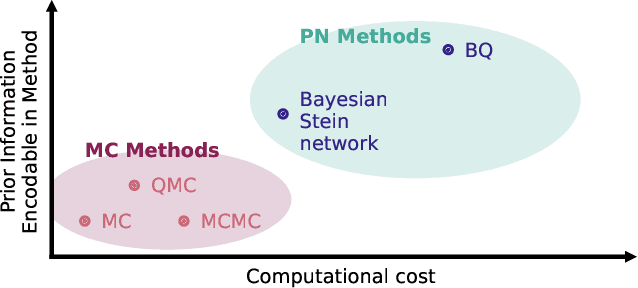
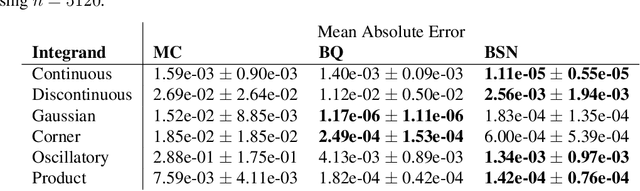
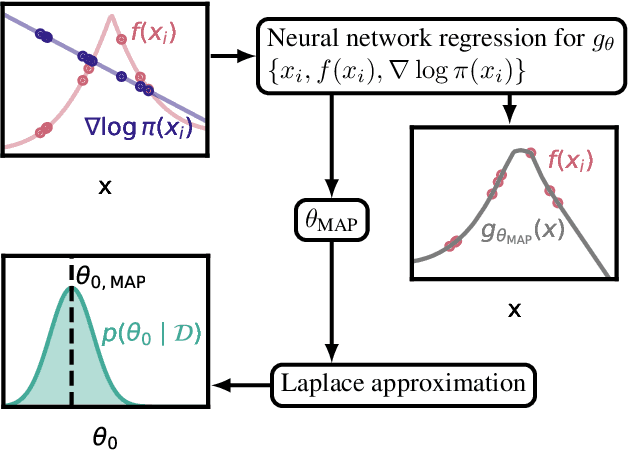
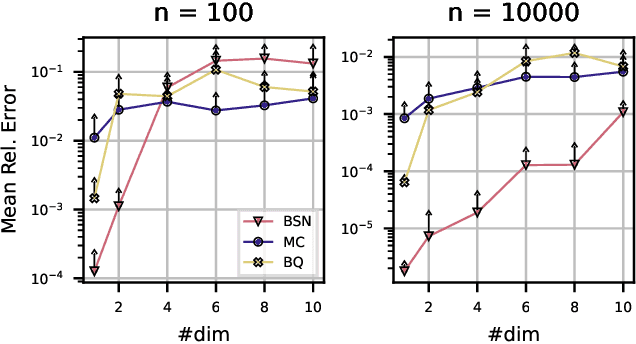
Bayesian probabilistic numerical methods for numerical integration offer significant advantages over their non-Bayesian counterparts: they can encode prior information about the integrand, and can quantify uncertainty over estimates of an integral. However, the most popular algorithm in this class, Bayesian quadrature, is based on Gaussian process models and is therefore associated with a high computational cost. To improve scalability, we propose an alternative approach based on Bayesian neural networks which we call Bayesian Stein networks. The key ingredients are a neural network architecture based on Stein operators, and an approximation of the Bayesian posterior based on the Laplace approximation. We show that this leads to orders of magnitude speed-ups on the popular Genz functions benchmark, and on challenging problems arising in the Bayesian analysis of dynamical systems, and the prediction of energy production for a large-scale wind farm.