 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBhashaSetu: A Data-Centric Approach to Low-Resource Machine Translation
May 26, 2026We present BhashaSetu, a linguistically enriched English--Marathi parallel dataset addressing persistent data limitations in low-resource neural machine translation (NMT). Marathi, spoken by over 95 million people, remains underrepresented in high-quality parallel corpora across diverse domains. Our dataset comprises 2.78 million sentence pairs from heterogeneous sources including news, politics, healthcare, literature, and culture, with stemmed and lemmatized representations to support morphology-aware analysis. We benchmark multiple state-of-the-art translation models using BLEU, spBLEU, chrF++, and TER metrics, and conduct parameter-efficient fine-tuning of NLLB-200-distilled-600M using LoRA. A key finding from our ablation: corpus-level deduplication is the single largest preprocessing contributor to downstream quality (removing it reduces performance by 1.17 BLEU and 2.21 chrF++), demonstrating that disciplined cross-source corpus hygiene is a low-cost, high-impact intervention for low-resource, morphologically rich languages. The dataset is publicly released to promote reproducible and linguistically informed low-resource NMT research.
CORDS: Continuous Representations of Discrete Structures
Jan 29, 2026Many learning problems require predicting sets of objects when the number of objects is not known beforehand. Examples include object detection, molecular modeling, and scientific inference tasks such as astrophysical source detection. Existing methods often rely on padded representations or must explicitly infer the set size, which often poses challenges. We present a novel strategy for addressing this challenge by casting prediction of variable-sized sets as a continuous inference problem. Our approach, CORDS (Continuous Representations of Discrete Structures), provides an invertible mapping that transforms a set of spatial objects into continuous fields: a density field that encodes object locations and count, and a feature field that carries their attributes over the same support. Because the mapping is invertible, models operate entirely in field space while remaining exactly decodable to discrete sets. We evaluate CORDS across molecular generation and regression, object detection, simulation-based inference, and a mathematical task involving recovery of local maxima, demonstrating robust handling of unknown set sizes with competitive accuracy.
Uncertainty and Structure in Neural Ordinary Differential Equations
May 22, 2023



Neural ordinary differential equations (ODEs) are an emerging class of deep learning models for dynamical systems. They are particularly useful for learning an ODE vector field from observed trajectories (i.e., inverse problems). We here consider aspects of these models relevant for their application in science and engineering. Scientific predictions generally require structured uncertainty estimates. As a first contribution, we show that basic and lightweight Bayesian deep learning techniques like the Laplace approximation can be applied to neural ODEs to yield structured and meaningful uncertainty quantification. But, in the scientific domain, available information often goes beyond raw trajectories, and also includes mechanistic knowledge, e.g., in the form of conservation laws. We explore how mechanistic knowledge and uncertainty quantification interact on two recently proposed neural ODE frameworks - symplectic neural ODEs and physical models augmented with neural ODEs. In particular, uncertainty reflects the effect of mechanistic information more directly than the predictive power of the trained model could. And vice versa, structure can improve the extrapolation abilities of neural ODEs, a fact that can be best assessed in practice through uncertainty estimates. Our experimental analysis demonstrates the effectiveness of the Laplace approach on both low dimensional ODE problems and a high dimensional partial differential equation.
Bayesian Numerical Integration with Neural Networks
May 22, 2023



Bayesian probabilistic numerical methods for numerical integration offer significant advantages over their non-Bayesian counterparts: they can encode prior information about the integrand, and can quantify uncertainty over estimates of an integral. However, the most popular algorithm in this class, Bayesian quadrature, is based on Gaussian process models and is therefore associated with a high computational cost. To improve scalability, we propose an alternative approach based on Bayesian neural networks which we call Bayesian Stein networks. The key ingredients are a neural network architecture based on Stein operators, and an approximation of the Bayesian posterior based on the Laplace approximation. We show that this leads to orders of magnitude speed-ups on the popular Genz functions benchmark, and on challenging problems arising in the Bayesian analysis of dynamical systems, and the prediction of energy production for a large-scale wind farm.
Combining Slow and Fast: Complementary Filtering for Dynamics Learning
Mar 01, 2023



Modeling an unknown dynamical system is crucial in order to predict the future behavior of the system. A standard approach is training recurrent models on measurement data. While these models typically provide exact short-term predictions, accumulating errors yield deteriorated long-term behavior. In contrast, models with reliable long-term predictions can often be obtained, either by training a robust but less detailed model, or by leveraging physics-based simulations. In both cases, inaccuracies in the models yield a lack of short-time details. Thus, different models with contrastive properties on different time horizons are available. This observation immediately raises the question: Can we obtain predictions that combine the best of both worlds? Inspired by sensor fusion tasks, we interpret the problem in the frequency domain and leverage classical methods from signal processing, in particular complementary filters. This filtering technique combines two signals by applying a high-pass filter to one signal, and low-pass filtering the other. Essentially, the high-pass filter extracts high-frequencies, whereas the low-pass filter extracts low frequencies. Applying this concept to dynamics model learning enables the construction of models that yield accurate long- and short-term predictions. Here, we propose two methods, one being purely learning-based and the other one being a hybrid model that requires an additional physics-based simulator.
Symplectic Gaussian Process Dynamics
Feb 02, 2021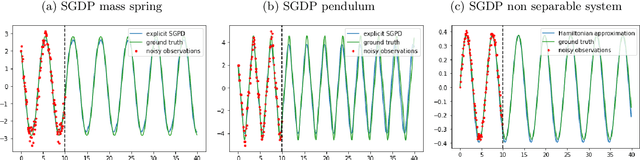
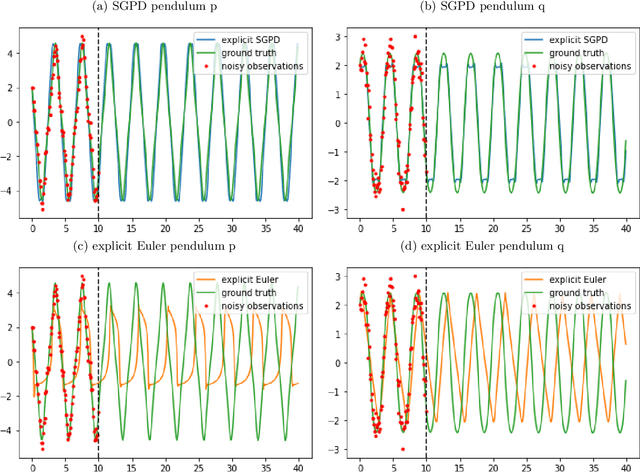

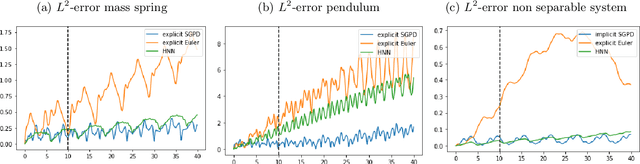
Dynamics model learning is challenging and at the same time an active field of research. Due to potential safety critical downstream applications, such as control tasks, there is a need for theoretical guarantees. While GPs induce rich theoretical guarantees as function approximators in space, they do not explicitly cope with the time aspect of dynamical systems. However, propagating system properties through time is exactly what classical numerical integrators were designed for. We introduce a recurrent sparse Gaussian process based variational inference scheme that is able to discretize the underlying system with any explicit or implicit single or multistep integrator, thus leveraging properties of numerical integrators. In particular we discuss Hamiltonian problems coupled with symplectic integrators producing volume preserving predictions.
When are Neural ODE Solutions Proper ODEs?
Jul 30, 2020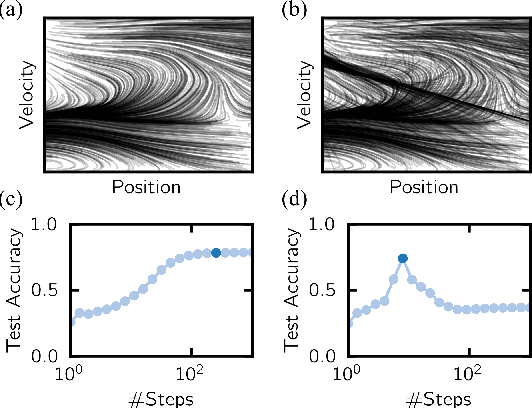
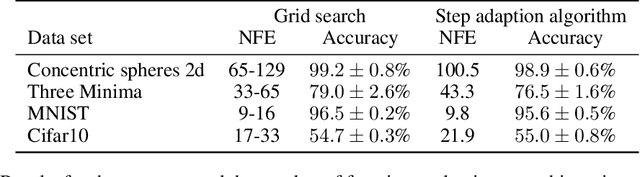

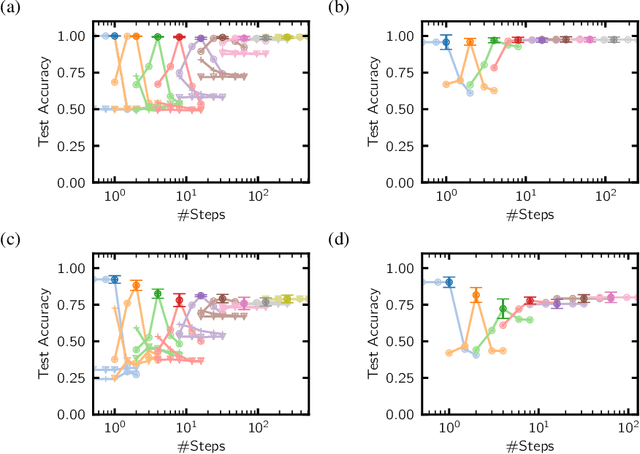
A key appeal of the recently proposed Neural Ordinary Differential Equation(ODE) framework is that it seems to provide a continuous-time extension of discrete residual neural networks. As we show herein, though, trained Neural ODE models actually depend on the specific numerical method used during training. If the trained model is supposed to be a flow generated from an ODE, it should be possible to choose another numerical solver with equal or smaller numerical error without loss of performance. We observe that if training relies on a solver with overly coarse discretization, then testing with another solver of equal or smaller numerical error results in a sharp drop in accuracy. In such cases, the combination of vector field and numerical method cannot be interpreted as a flow generated from an ODE, which arguably poses a fatal breakdown of the Neural ODE concept. We observe, however, that there exists a critical step size beyond which the training yields a valid ODE vector field. We propose a method that monitors the behavior of the ODE solver during training to adapt its step size, aiming to ensure a valid ODE without unnecessarily increasing computational cost. We verify this adaption algorithm on two common bench mark datasets as well as a synthetic dataset. Furthermore, we introduce a novel synthetic dataset in which the underlying ODE directly generates a classification task.
Differentiable Likelihoods for Fast Inversion of 'Likelihood-Free' Dynamical Systems
Feb 21, 2020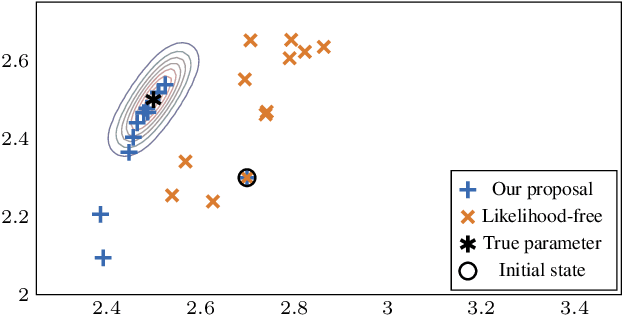
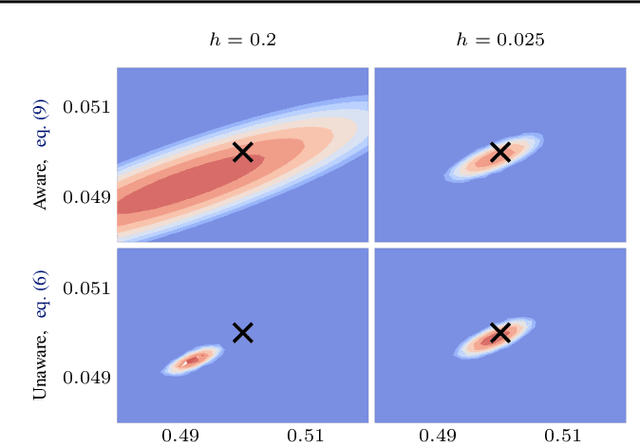
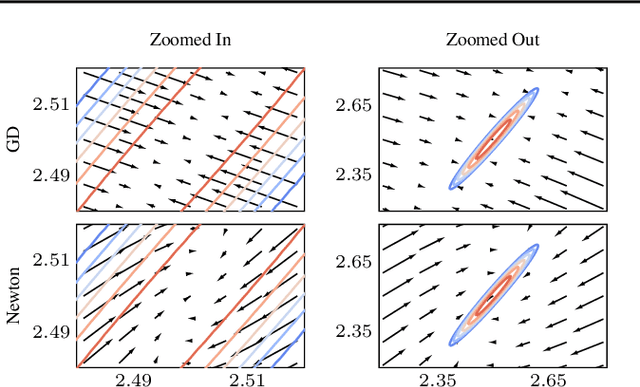
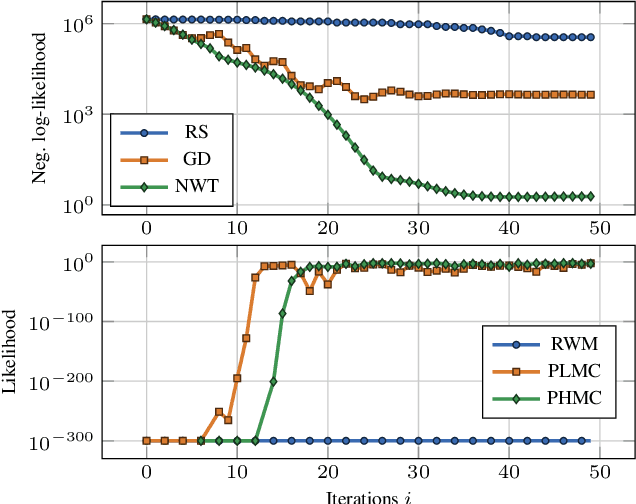
Likelihood-free (a.k.a. simulation-based) inference problems are inverse problems with expensive, or intractable, forward models. ODE inverse problems are commonly treated as likelihood-free, as their forward map has to be numerically approximated by an ODE solver. This, however, is not a fundamental constraint but just a lack of functionality in classic ODE solvers, which do not return a likelihood but a point estimate. To address this shortcoming, we employ Gaussian ODE filtering (a probabilistic numerical method for ODEs) to construct a local Gaussian approximation to the likelihood. This approximation yields tractable estimators for the gradient and Hessian of the (log-)likelihood. Insertion of these estimators into existing gradient-based optimization and sampling methods engenders new solvers for ODE inverse problems. We demonstrate that these methods outperform standard likelihood-free approaches on three benchmark-systems.