 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Abstractive Summary Generation for the Urdu Language
May 25, 2023
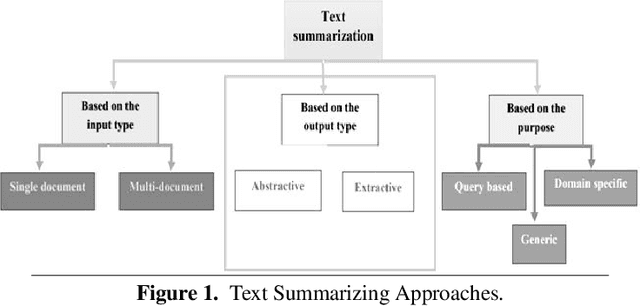
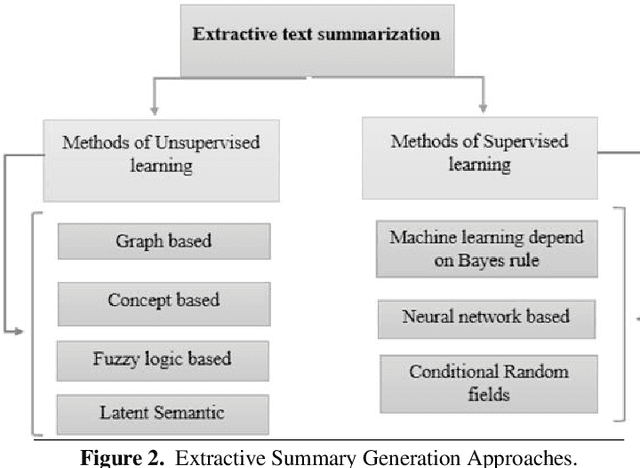
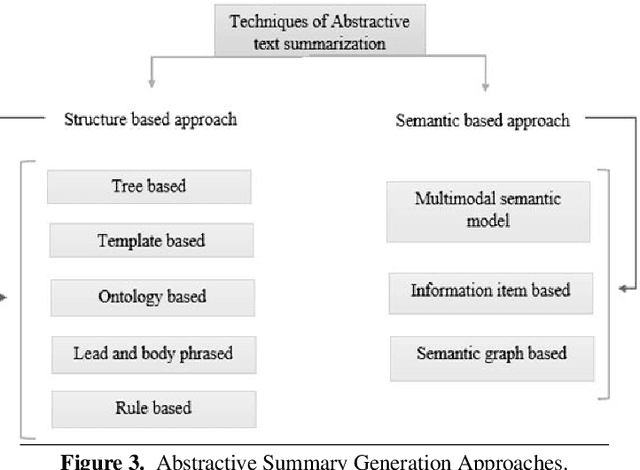
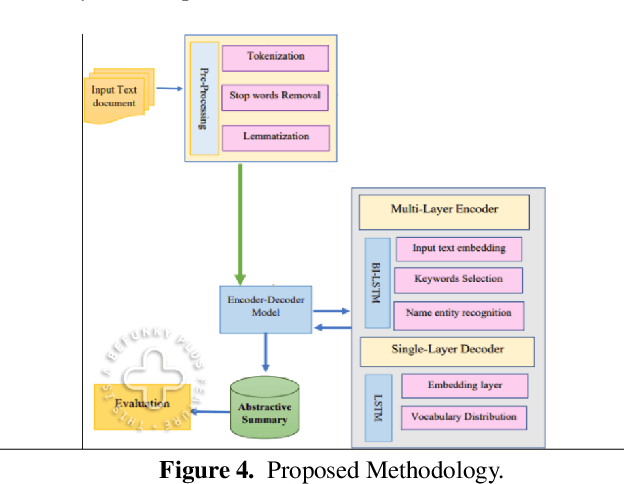
Abstractive summary generation is a challenging task that requires the model to comprehend the source text and generate a concise and coherent summary that captures the essential information. In this paper, we explore the use of an encoder/decoder approach for abstractive summary generation in the Urdu language. We employ a transformer-based model that utilizes self-attention mechanisms to encode the input text and generate a summary. Our experiments show that our model can produce summaries that are grammatically correct and semantically meaningful. We evaluate our model on a publicly available dataset and achieve state-of-the-art results in terms of Rouge scores. We also conduct a qualitative analysis of our model's output to assess its effectiveness and limitations. Our findings suggest that the encoder/decoder approach is a promising method for abstractive summary generation in Urdu and can be extended to other languages with suitable modifications.
Weakly-Supervised Speech Pre-training: A Case Study on Target Speech Recognition
May 25, 2023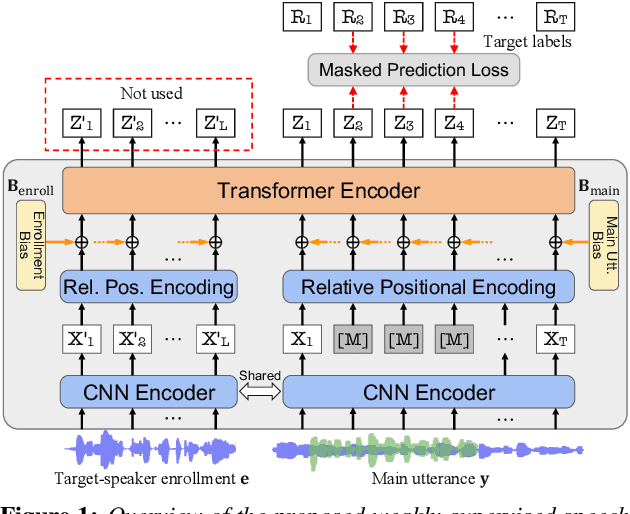
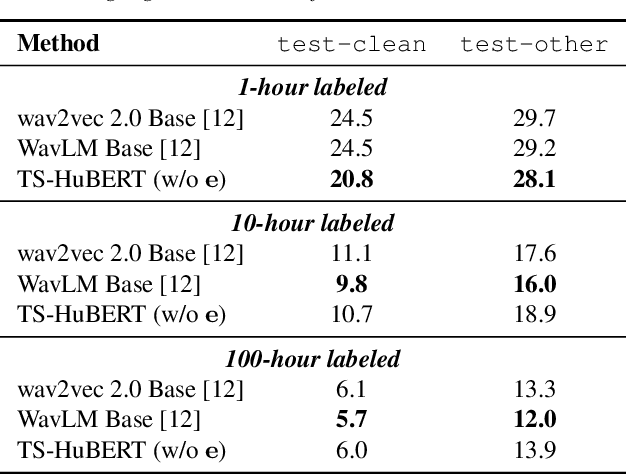
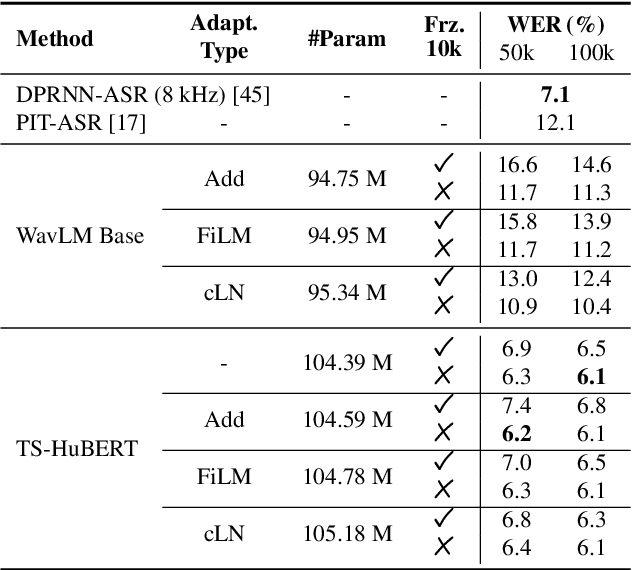
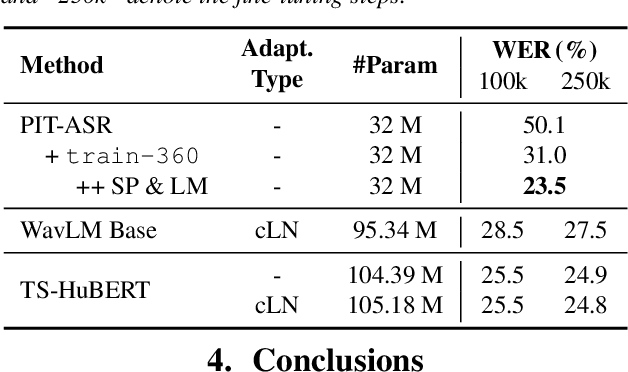
Self-supervised learning (SSL) based speech pre-training has attracted much attention for its capability of extracting rich representations learned from massive unlabeled data. On the other hand, the use of weakly-supervised data is less explored for speech pre-training. To fill this gap, we propose a weakly-supervised speech pre-training method based on speaker-aware speech data. It adopts a similar training procedure to the widely-used masked speech prediction based SSL framework, while incorporating additional target-speaker enrollment information as an auxiliary input. In this way, the learned representation is steered towards the target speaker even in the presence of highly overlapping interference, allowing potential applications to tasks such as target speech recognition. Our experiments on Libri2Mix and WSJ0-2mix datasets show that the proposed model achieves significantly better ASR performance compared to WavLM, the state-of-the-art SSL model with denoising capability.
MPE4G: Multimodal Pretrained Encoder for Co-Speech Gesture Generation
May 25, 2023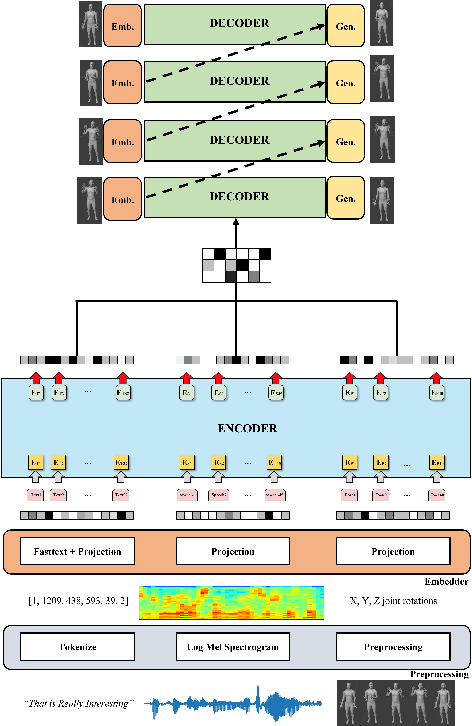
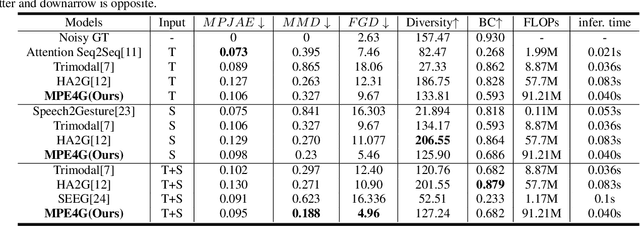
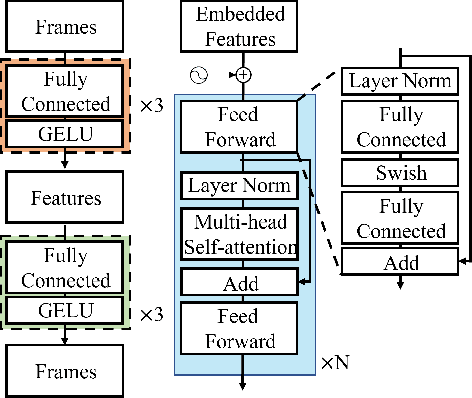
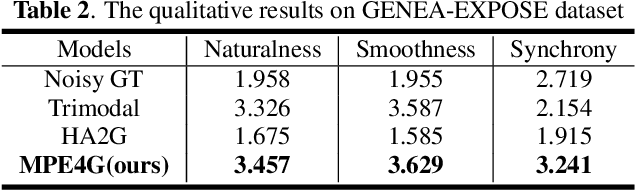
When virtual agents interact with humans, gestures are crucial to delivering their intentions with speech. Previous multimodal co-speech gesture generation models required encoded features of all modalities to generate gestures. If some input modalities are removed or contain noise, the model may not generate the gestures properly. To acquire robust and generalized encodings, we propose a novel framework with a multimodal pre-trained encoder for co-speech gesture generation. In the proposed method, the multi-head-attention-based encoder is trained with self-supervised learning to contain the information on each modality. Moreover, we collect full-body gestures that consist of 3D joint rotations to improve visualization and apply gestures to the extensible body model. Through the series of experiments and human evaluation, the proposed method renders realistic co-speech gestures not only when all input modalities are given but also when the input modalities are missing or noisy.
* 5 pages, 3 figures
Enhancing Label Sharing Efficiency in Complementary-Label Learning with Label Augmentation
May 15, 2023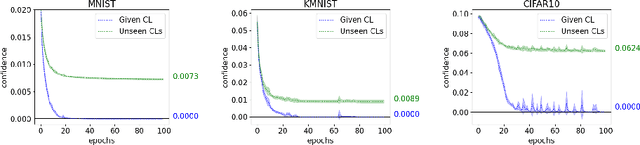

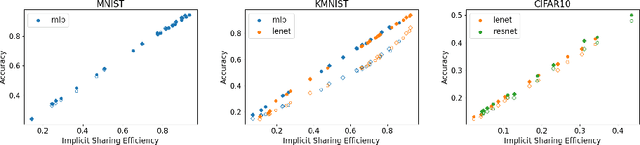
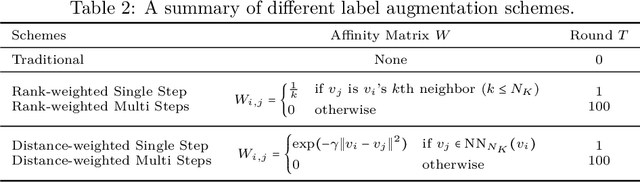
Complementary-label Learning (CLL) is a form of weakly supervised learning that trains an ordinary classifier using only complementary labels, which are the classes that certain instances do not belong to. While existing CLL studies typically use novel loss functions or training techniques to solve this problem, few studies focus on how complementary labels collectively provide information to train the ordinary classifier. In this paper, we fill the gap by analyzing the implicit sharing of complementary labels on nearby instances during training. Our analysis reveals that the efficiency of implicit label sharing is closely related to the performance of existing CLL models. Based on this analysis, we propose a novel technique that enhances the sharing efficiency via complementary-label augmentation, which explicitly propagates additional complementary labels to each instance. We carefully design the augmentation process to enrich the data with new and accurate complementary labels, which provide CLL models with fresh and valuable information to enhance the sharing efficiency. We then verify our proposed technique by conducting thorough experiments on both synthetic and real-world datasets. Our results confirm that complementary-label augmentation can systematically improve empirical performance over state-of-the-art CLL models.
Schema-adaptable Knowledge Graph Construction
May 15, 2023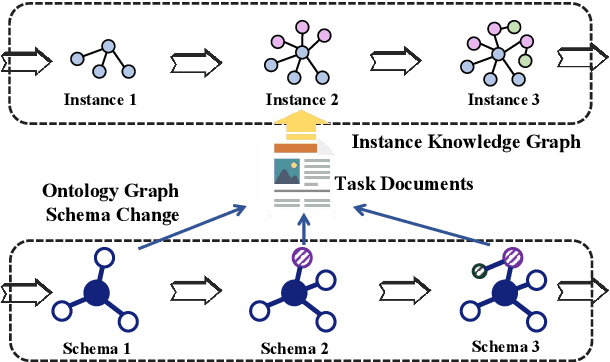
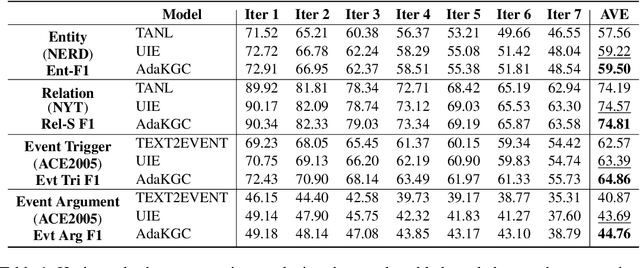
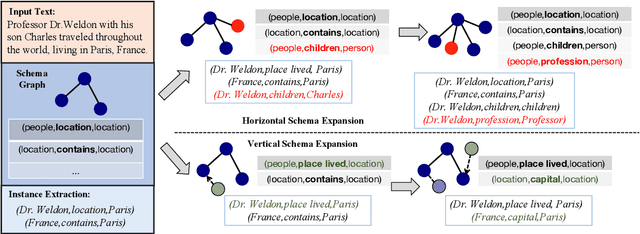
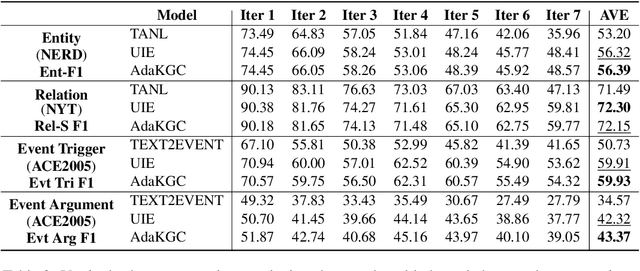
Conventional Knowledge Graph Construction (KGC) approaches typically follow the static information extraction paradigm with a closed set of pre-defined schema. As a result, such approaches fall short when applied to dynamic scenarios or domains, whereas a new type of knowledge emerges. This necessitates a system that can handle evolving schema automatically to extract information for KGC. To address this need, we propose a new task called schema-adaptable KGC, which aims to continually extract entity, relation, and event based on a dynamically changing schema graph without re-training. We first split and convert existing datasets based on three principles to build a benchmark, i.e., horizontal schema expansion, vertical schema expansion, and hybrid schema expansion; then investigate the schema-adaptable performance of several well-known approaches such as Text2Event, TANL, UIE and GPT-3. We further propose a simple yet effective baseline dubbed AdaKGC, which contains schema-enriched prefix instructor and schema-conditioned dynamic decoding to better handle evolving schema. Comprehensive experimental results illustrate that AdaKGC can outperform baselines but still have room for improvement. We hope the proposed work can deliver benefits to the community. Code and datasets will be available in https://github.com/zjunlp/AdaKGC.
Self-supervised Fine-tuning for Improved Content Representations by Speaker-invariant Clustering
May 18, 2023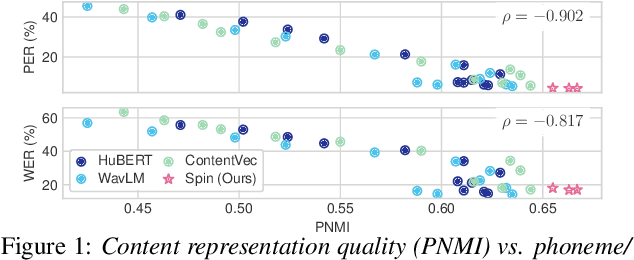
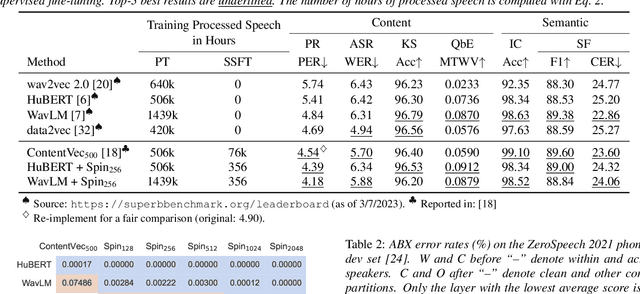
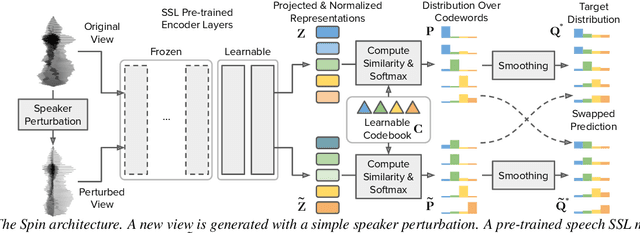
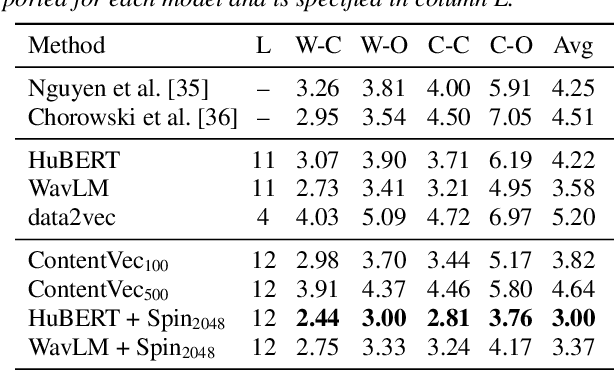
Self-supervised speech representation models have succeeded in various tasks, but improving them for content-related problems using unlabeled data is challenging. We propose speaker-invariant clustering (Spin), a novel self-supervised learning method that clusters speech representations and performs swapped prediction between the original and speaker-perturbed utterances. Spin disentangles speaker information and preserves content representations with just 45 minutes of fine-tuning on a single GPU. Spin improves pre-trained networks and outperforms prior methods in speech recognition and acoustic unit discovery.
HyperFormer: Learning Expressive Sparse Feature Representations via Hypergraph Transformer
May 27, 2023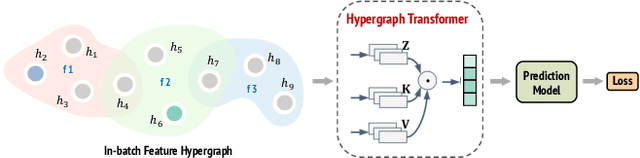
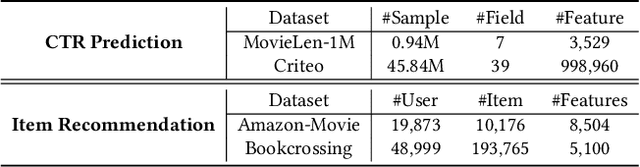
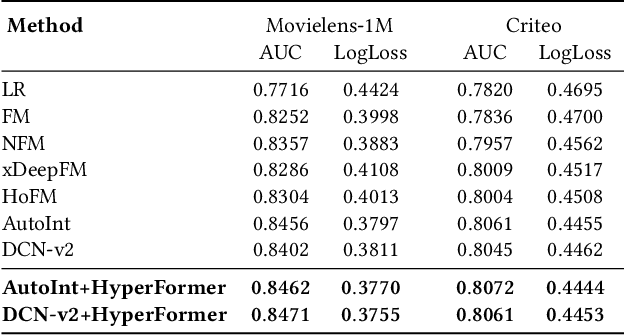
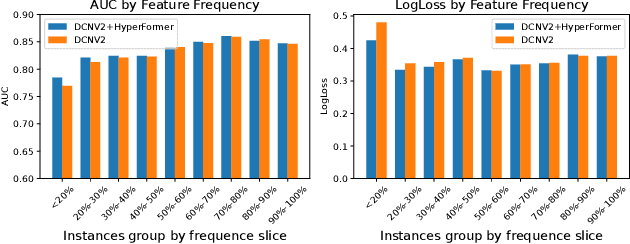
Learning expressive representations for high-dimensional yet sparse features has been a longstanding problem in information retrieval. Though recent deep learning methods can partially solve the problem, they often fail to handle the numerous sparse features, particularly those tail feature values with infrequent occurrences in the training data. Worse still, existing methods cannot explicitly leverage the correlations among different instances to help further improve the representation learning on sparse features since such relational prior knowledge is not provided. To address these challenges, in this paper, we tackle the problem of representation learning on feature-sparse data from a graph learning perspective. Specifically, we propose to model the sparse features of different instances using hypergraphs where each node represents a data instance and each hyperedge denotes a distinct feature value. By passing messages on the constructed hypergraphs based on our Hypergraph Transformer (HyperFormer), the learned feature representations capture not only the correlations among different instances but also the correlations among features. Our experiments demonstrate that the proposed approach can effectively improve feature representation learning on sparse features.
Augmentation-Adapted Retriever Improves Generalization of Language Models as Generic Plug-In
May 27, 2023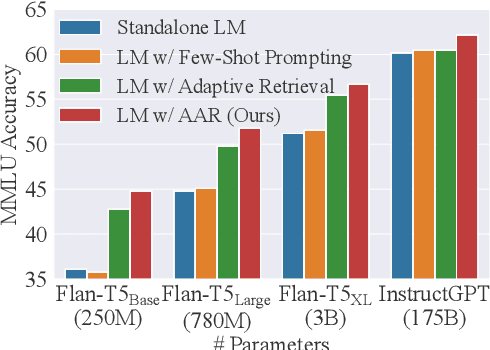
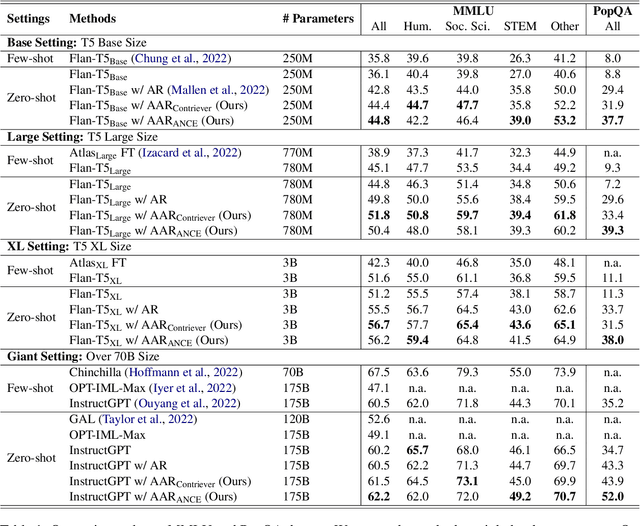
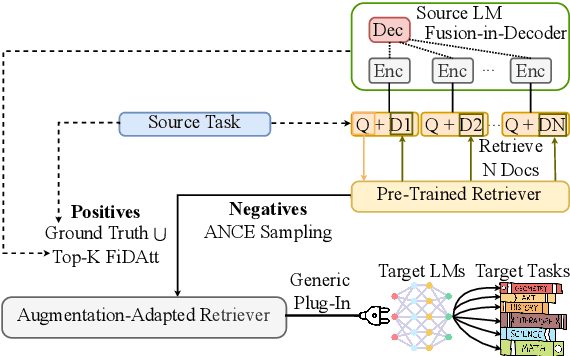

Retrieval augmentation can aid language models (LMs) in knowledge-intensive tasks by supplying them with external information. Prior works on retrieval augmentation usually jointly fine-tune the retriever and the LM, making them closely coupled. In this paper, we explore the scheme of generic retrieval plug-in: the retriever is to assist target LMs that may not be known beforehand or are unable to be fine-tuned together. To retrieve useful documents for unseen target LMs, we propose augmentation-adapted retriever (AAR), which learns LM's preferences obtained from a known source LM. Experiments on the MMLU and PopQA datasets demonstrate that our AAR trained with a small source LM is able to significantly improve the zero-shot generalization of larger target LMs ranging from 250M Flan-T5 to 175B InstructGPT. Further analysis indicates that the preferences of different LMs overlap, enabling AAR trained with a single source LM to serve as a generic plug-in for various target LMs. Our code is open-sourced at https://github.com/OpenMatch/Augmentation-Adapted-Retriever.
How Good is Automatic Segmentation as a Multimodal Discourse Annotation Aid?
May 27, 2023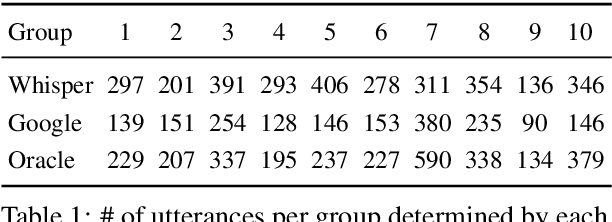
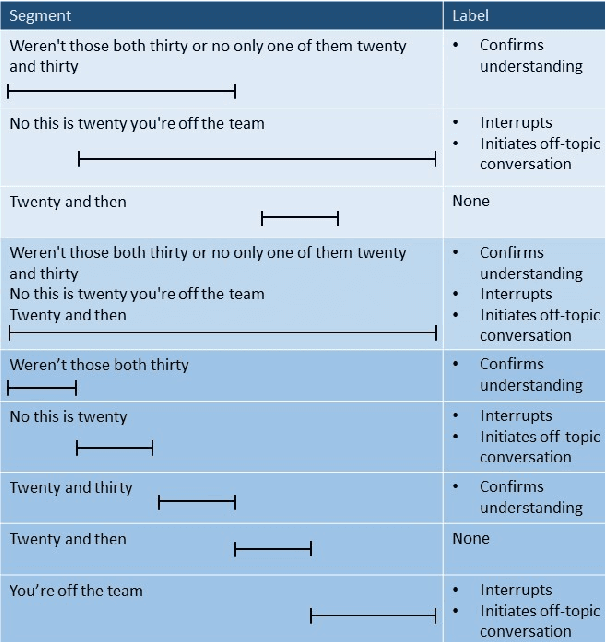
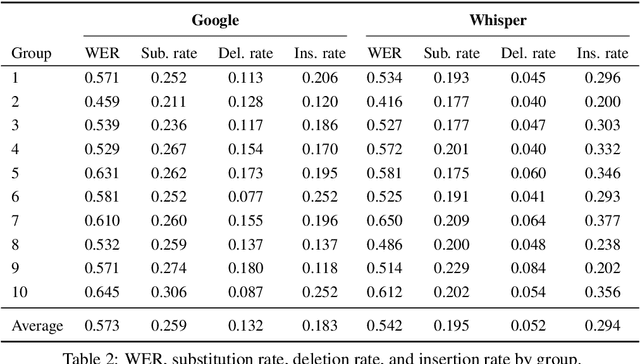
Collaborative problem solving (CPS) in teams is tightly coupled with the creation of shared meaning between participants in a situated, collaborative task. In this work, we assess the quality of different utterance segmentation techniques as an aid in annotating CPS. We (1) manually transcribe utterances in a dataset of triads collaboratively solving a problem involving dialogue and physical object manipulation, (2) annotate collaborative moves according to these gold-standard transcripts, and then (3) apply these annotations to utterances that have been automatically segmented using toolkits from Google and OpenAI's Whisper. We show that the oracle utterances have minimal correspondence to automatically segmented speech, and that automatically segmented speech using different segmentation methods is also inconsistent. We also show that annotating automatically segmented speech has distinct implications compared with annotating oracle utterances--since most annotation schemes are designed for oracle cases, when annotating automatically-segmented utterances, annotators must invoke other information to make arbitrary judgments which other annotators may not replicate. We conclude with a discussion of how future annotation specs can account for these needs.
Modeling Dynamic Heterogeneous Graph and Node Importance for Future Citation Prediction
May 27, 2023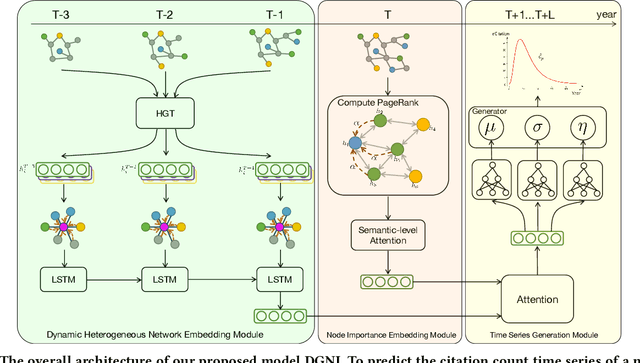
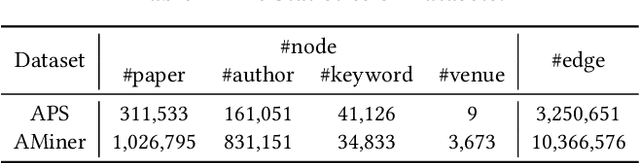
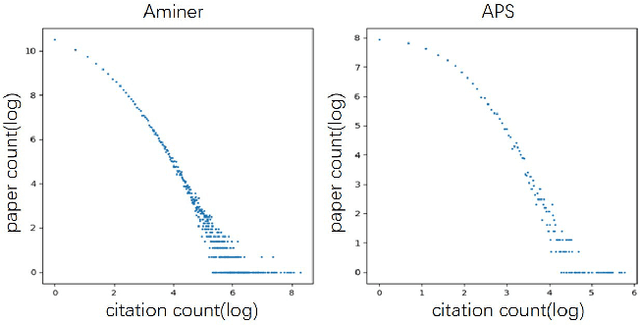
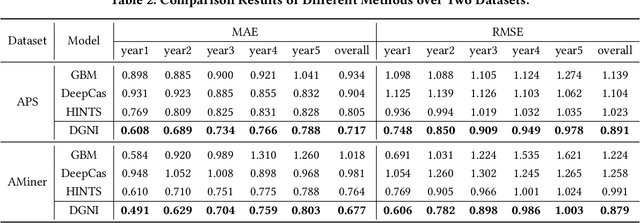
Accurate citation count prediction of newly published papers could help editors and readers rapidly figure out the influential papers in the future. Though many approaches are proposed to predict a paper's future citation, most ignore the dynamic heterogeneous graph structure or node importance in academic networks. To cope with this problem, we propose a Dynamic heterogeneous Graph and Node Importance network (DGNI) learning framework, which fully leverages the dynamic heterogeneous graph and node importance information to predict future citation trends of newly published papers. First, a dynamic heterogeneous network embedding module is provided to capture the dynamic evolutionary trends of the whole academic network. Then, a node importance embedding module is proposed to capture the global consistency relationship to figure out each paper's node importance. Finally, the dynamic evolutionary trend embeddings and node importance embeddings calculated above are combined to jointly predict the future citation counts of each paper, by a log-normal distribution model according to multi-faced paper node representations. Extensive experiments on two large-scale datasets demonstrate that our model significantly improves all indicators compared to the SOTA models.