 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SCALE: Scaling up the Complexity for Advanced Language Model Evaluation
Jun 15, 2023
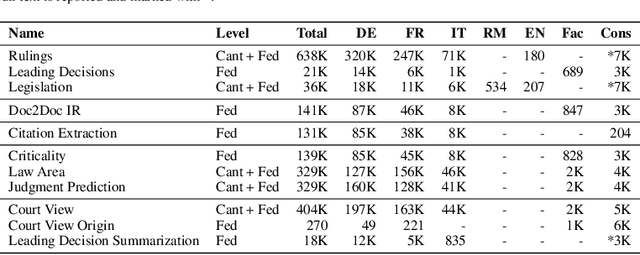
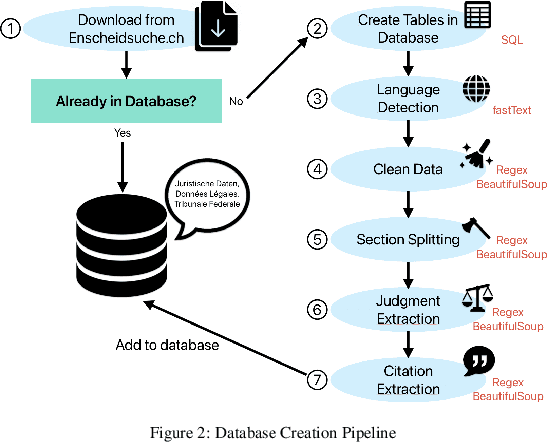
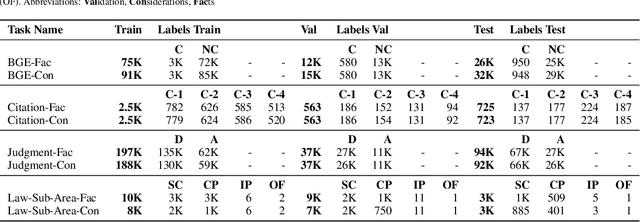
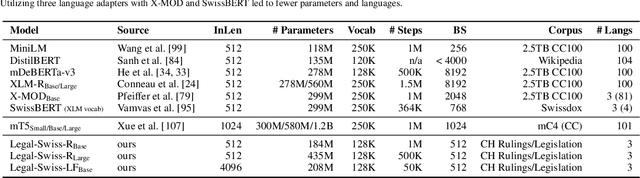
Recent strides in Large Language Models (LLMs) have saturated many NLP benchmarks (even professional domain-specific ones), emphasizing the need for novel, more challenging novel ones to properly assess LLM capabilities. In this paper, we introduce a novel NLP benchmark that poses challenges to current LLMs across four key dimensions: processing long documents (up to 50K tokens), utilizing domain specific knowledge (embodied in legal texts), multilingual understanding (covering five languages), and multitasking (comprising legal document to document Information Retrieval, Court View Generation, Leading Decision Summarization, Citation Extraction, and eight challenging Text Classification tasks). Our benchmark comprises diverse legal NLP datasets from the Swiss legal system, allowing for a comprehensive study of the underlying Non-English, inherently multilingual, federal legal system. Despite recent advances, efficiently processing long documents for intense review/analysis tasks remains an open challenge for language models. Also, comprehensive, domain-specific benchmarks requiring high expertise to develop are rare, as are multilingual benchmarks. This scarcity underscores our contribution's value, considering most public models are trained predominantly on English corpora, while other languages remain understudied, particularly for practical domain-specific NLP tasks. Our benchmark allows for testing and advancing the state-of-the-art LLMs. As part of our study, we evaluate several pre-trained multilingual language models on our benchmark to establish strong baselines as a point of reference. Despite the large size of our datasets (tens to hundreds of thousands of examples), existing publicly available models struggle with most tasks, even after in-domain pretraining. We publish all resources (benchmark suite, pre-trained models, code) under a fully permissive open CC BY-SA license.
Host-Based Network Intrusion Detection via Feature Flattening and Two-stage Collaborative Classifier
Jun 15, 2023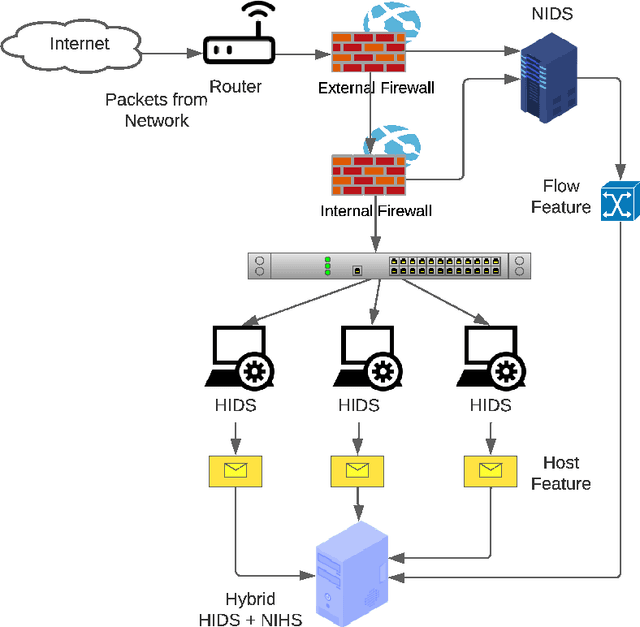
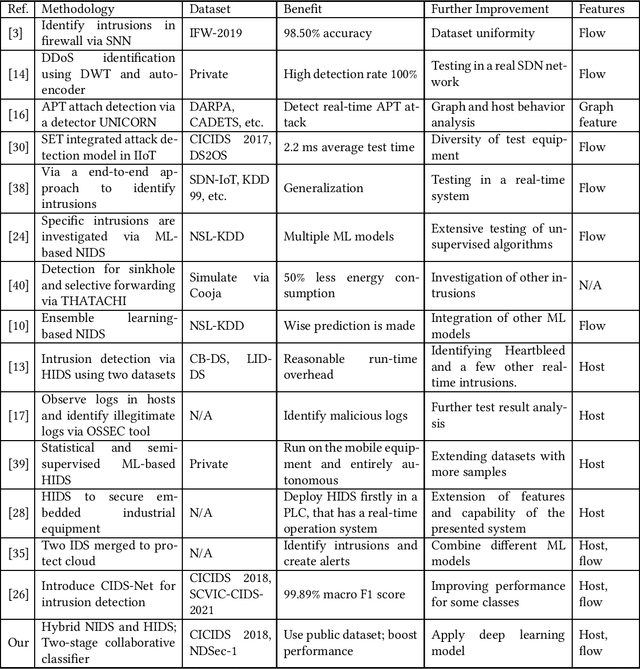
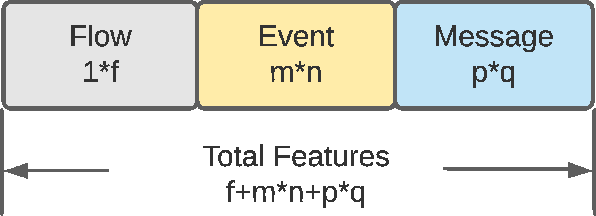
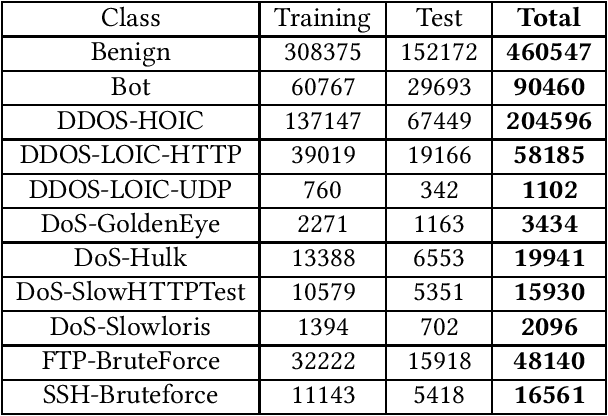
Network Intrusion Detection Systems (NIDS) have been extensively investigated by monitoring real network traffic and analyzing suspicious activities. However, there are limitations in detecting specific types of attacks with NIDS, such as Advanced Persistent Threats (APT). Additionally, NIDS is restricted in observing complete traffic information due to encrypted traffic or a lack of authority. To address these limitations, a Host-based Intrusion Detection system (HIDS) evaluates resources in the host, including logs, files, and folders, to identify APT attacks that routinely inject malicious files into victimized nodes. In this study, a hybrid network intrusion detection system that combines NIDS and HIDS is proposed to improve intrusion detection performance. The feature flattening technique is applied to flatten two-dimensional host-based features into one-dimensional vectors, which can be directly used by traditional Machine Learning (ML) models. A two-stage collaborative classifier is introduced that deploys two levels of ML algorithms to identify network intrusions. In the first stage, a binary classifier is used to detect benign samples. All detected attack types undergo a multi-class classifier to reduce the complexity of the original problem and improve the overall detection performance. The proposed method is shown to generalize across two well-known datasets, CICIDS 2018 and NDSec-1. Performance of XGBoost, which represents conventional ML, is evaluated. Combining host and network features enhances attack detection performance (macro average F1 score) by 8.1% under the CICIDS 2018 dataset and 3.7% under the NDSec-1 dataset. Meanwhile, the two-stage collaborative classifier improves detection performance for most single classes, especially for DoS-LOIC-UDP and DoS-SlowHTTPTest, with improvements of 30.7% and 84.3%, respectively, when compared with the traditional ML XGBoost.
Stable Tomography for Structured Quantum States
Jun 15, 2023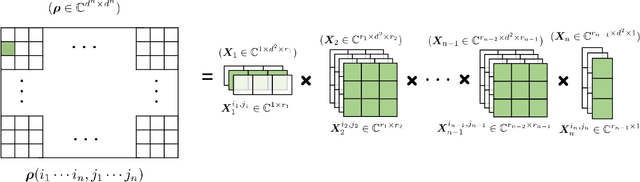
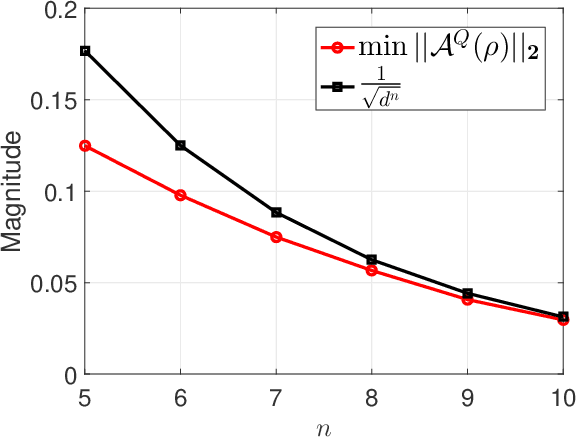
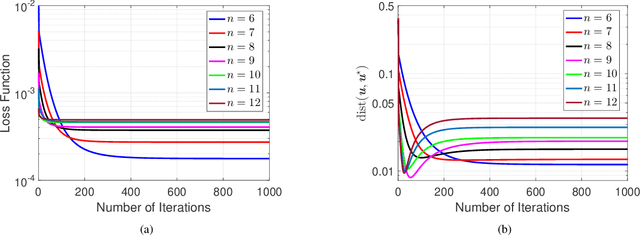
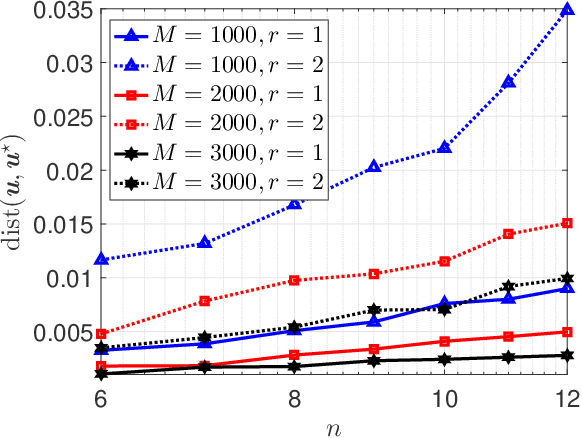
The reconstruction of quantum states from experimental measurements, often achieved using quantum state tomography (QST), is crucial for the verification and benchmarking of quantum devices. However, performing QST for a generic unstructured quantum state requires an enormous number of state copies that grows \emph{exponentially} with the number of individual quanta in the system, even for the most optimal measurement settings. Fortunately, many physical quantum states, such as states generated by noisy, intermediate-scale quantum computers, are usually structured. In one dimension, such states are expected to be well approximated by matrix product operators (MPOs) with a finite matrix/bond dimension independent of the number of qubits, therefore enabling efficient state representation. Nevertheless, it is still unclear whether efficient QST can be performed for these states in general. In this paper, we attempt to bridge this gap and establish theoretical guarantees for the stable recovery of MPOs using tools from compressive sensing and the theory of empirical processes. We begin by studying two types of random measurement settings: Gaussian measurements and Haar random rank-one Positive Operator Valued Measures (POVMs). We show that the information contained in an MPO with a finite bond dimension can be preserved using a number of random measurements that depends only \emph{linearly} on the number of qubits, assuming no statistical error of the measurements. We then study MPO-based QST with physical quantum measurements through Haar random rank-one POVMs that can be implemented on quantum computers. We prove that only a \emph{polynomial} number of state copies in the number of qubits is required to guarantee bounded recovery error of an MPO state.
Towards Better Entity Linking with Multi-View Enhanced Distillation
May 27, 2023
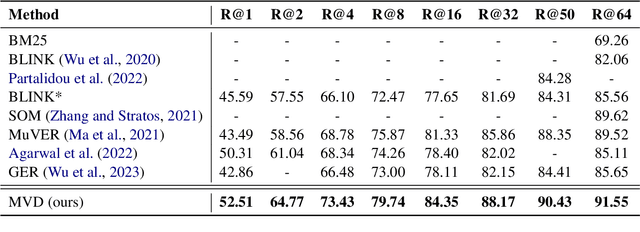
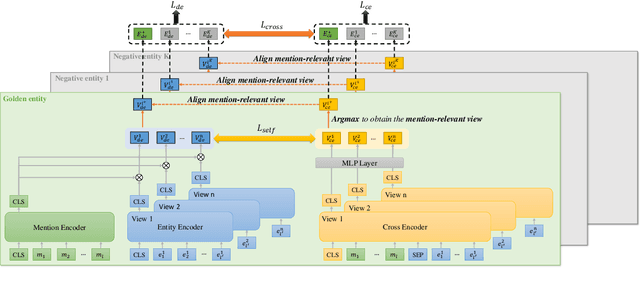
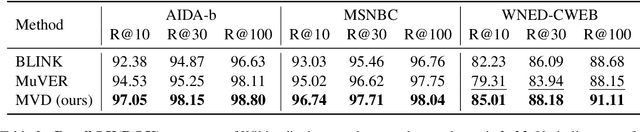
Dense retrieval is widely used for entity linking to retrieve entities from large-scale knowledge bases. Mainstream techniques are based on a dual-encoder framework, which encodes mentions and entities independently and calculates their relevances via rough interaction metrics, resulting in difficulty in explicitly modeling multiple mention-relevant parts within entities to match divergent mentions. Aiming at learning entity representations that can match divergent mentions, this paper proposes a Multi-View Enhanced Distillation (MVD) framework, which can effectively transfer knowledge of multiple fine-grained and mention-relevant parts within entities from cross-encoders to dual-encoders. Each entity is split into multiple views to avoid irrelevant information being over-squashed into the mention-relevant view. We further design cross-alignment and self-alignment mechanisms for this framework to facilitate fine-grained knowledge distillation from the teacher model to the student model. Meanwhile, we reserve a global-view that embeds the entity as a whole to prevent dispersal of uniform information. Experiments show our method achieves state-of-the-art performance on several entity linking benchmarks.
Mixture-of-Expert Conformer for Streaming Multilingual ASR
May 25, 2023
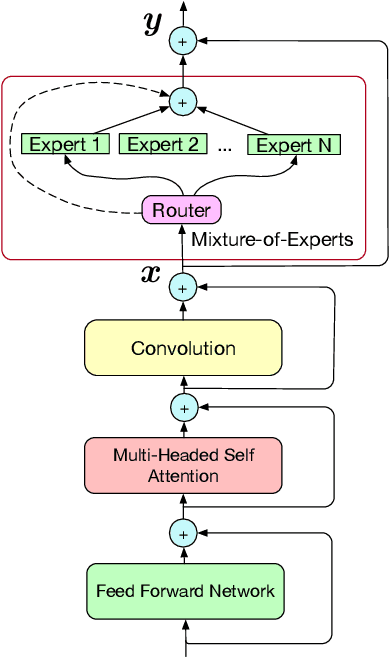
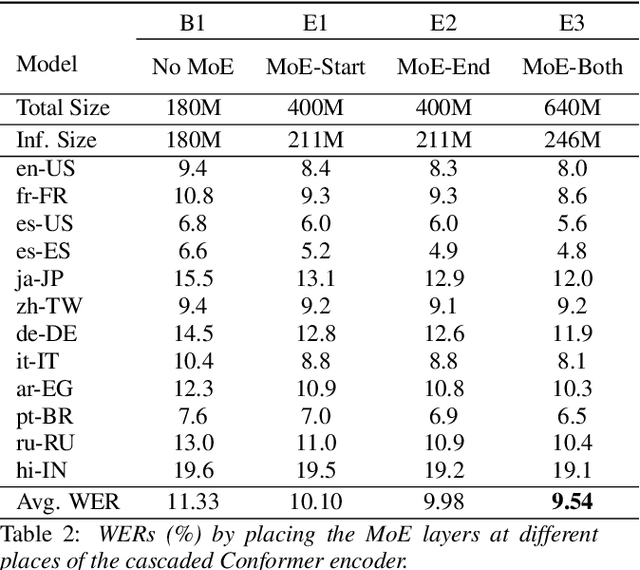
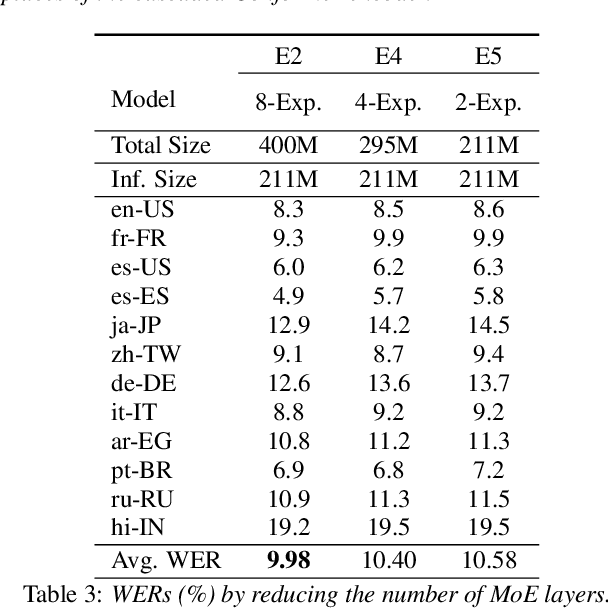
End-to-end models with large capacity have significantly improved multilingual automatic speech recognition, but their computation cost poses challenges for on-device applications. We propose a streaming truly multilingual Conformer incorporating mixture-of-expert (MoE) layers that learn to only activate a subset of parameters in training and inference. The MoE layer consists of a softmax gate which chooses the best two experts among many in forward propagation. The proposed MoE layer offers efficient inference by activating a fixed number of parameters as the number of experts increases. We evaluate the proposed model on a set of 12 languages, and achieve an average 11.9% relative improvement in WER over the baseline. Compared to an adapter model using ground truth information, our MoE model achieves similar WER and activates similar number of parameters but without any language information. We further show around 3% relative WER improvement by multilingual shallow fusion.
Automatic Extraction of Time-windowed ROS Computation Graphs from ROS Bag Files
May 25, 2023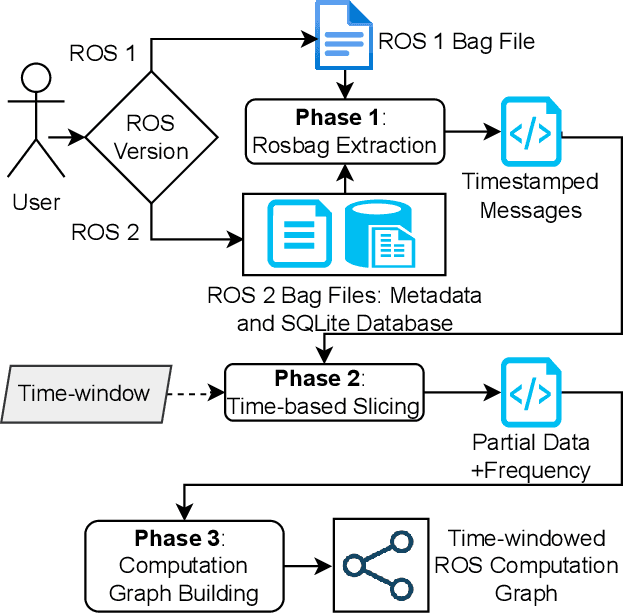
Robotic systems react to different environmental stimuli, potentially resulting in the dynamic reconfiguration of the software controlling such systems. One effect of such dynamism is the reconfiguration of the software architecture reconfiguration of the system at runtime. Such reconfigurations might severely impact the runtime properties of robotic systems, e.g., in terms of performance and energy efficiency. The ROS \emph{rosbag} package enables developers to record and store timestamped data related to the execution of robotic missions, implicitly containing relevant information about the architecture of the monitored system during its execution. In this study, we discuss about our approach for statically extracting (time-windowed) architectural information from ROS bag files. The proposed approach can support the robotics community in better discussing and reasoning the software architecture (and its runtime reconfigurations) of ROS-based systems. We evaluate our approach against hundreds of ROS bag files systematically mined from 4,434 public GitHub repositories.
* 2 pages, workshop paper
Partial Identifiability for Domain Adaptation
Jun 10, 2023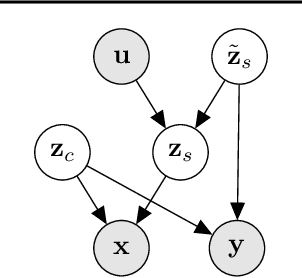
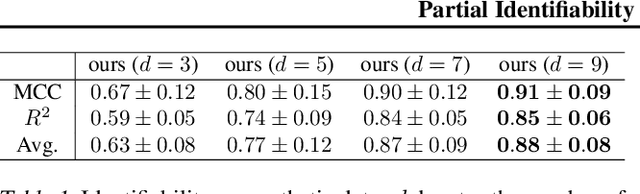
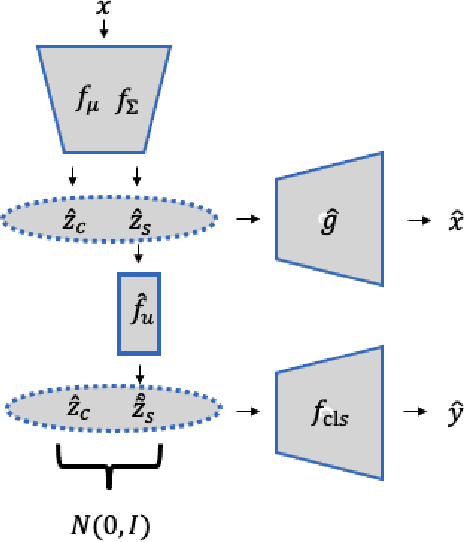
Unsupervised domain adaptation is critical to many real-world applications where label information is unavailable in the target domain. In general, without further assumptions, the joint distribution of the features and the label is not identifiable in the target domain. To address this issue, we rely on the property of minimal changes of causal mechanisms across domains to minimize unnecessary influences of distribution shifts. To encode this property, we first formulate the data-generating process using a latent variable model with two partitioned latent subspaces: invariant components whose distributions stay the same across domains and sparse changing components that vary across domains. We further constrain the domain shift to have a restrictive influence on the changing components. Under mild conditions, we show that the latent variables are partially identifiable, from which it follows that the joint distribution of data and labels in the target domain is also identifiable. Given the theoretical insights, we propose a practical domain adaptation framework called iMSDA. Extensive experimental results reveal that iMSDA outperforms state-of-the-art domain adaptation algorithms on benchmark datasets, demonstrating the effectiveness of our framework.
Enhance Reasoning Ability of Visual-Language Models via Large Language Models
May 22, 2023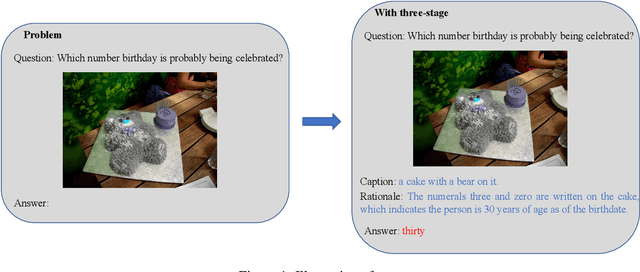
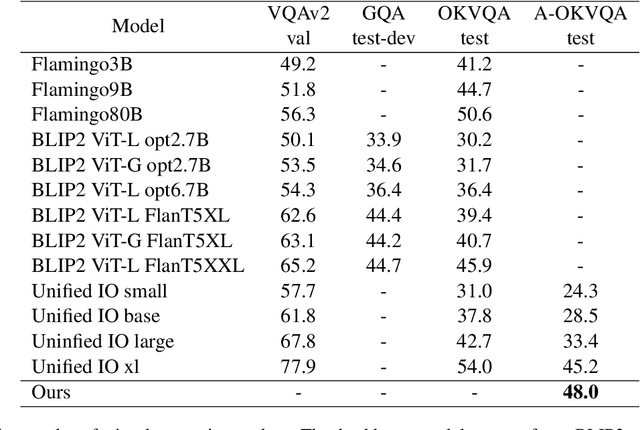


Pre-trained visual language models (VLM) have shown excellent performance in image caption tasks. However, it sometimes shows insufficient reasoning ability. In contrast, large language models (LLMs) emerge with powerful reasoning capabilities. Therefore, we propose a method called TReE, which transfers the reasoning ability of a large language model to a visual language model in zero-shot scenarios. TReE contains three stages: observation, thinking, and re-thinking. Observation stage indicates that VLM obtains the overall information of the relative image. Thinking stage combines the image information and task description as the prompt of the LLM, inference with the rationals. Re-Thinking stage learns from rationale and then inference the final result through VLM.
Imagery Tracking of Sun Activity Using 2D Circular Kernel Time Series Transformation, Entropy Measures and Machine Learning Approaches
Jun 14, 2023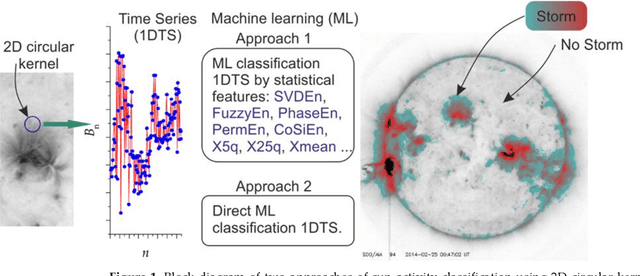

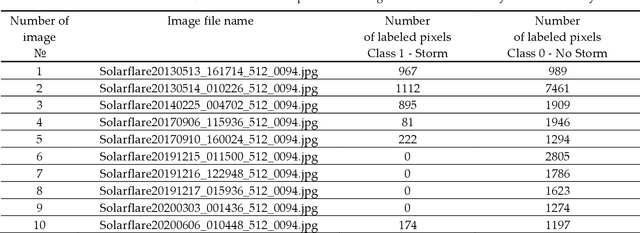
The sun is highly complex in nature and its observatory imagery features is one of the most important sources of information about the sun activity, space and Earth's weather conditions. The NASA, solar Dynamics Observatory captures approximately 70,000 images of the sun activity in a day and the continuous visual inspection of this solar observatory images is challenging. In this study, we developed a technique of tracking the sun's activity using 2D circular kernel time series transformation, statistical and entropy measures, with machine learning approaches. The technique involves transforming the solar observatory image section into 1-Dimensional time series (1-DTS) while the statistical and entropy measures (Approach 1) and direct classification (Approach 2) is used to capture the extraction features from the 1-DTS for machine learning classification into 'solar storm' and 'no storm'. We found that the potential accuracy of the model in tracking the activity of the sun is approximately 0.981 for Approach 1 and 0.999 for Approach 2. The stability of the developed approach to rotational transformation of the solar observatory image is evident. When training on the original dataset for Approach 1, the match index (T90) of the distribution of solar storm areas reaches T90 ~ 0.993, and T90 ~ 0.951 for Approach 2. In addition, when using the extended training base, the match indices increased to T90 ~ 0.994 and T90 ~ 1, respectively. This model consistently classifies areas with swirling magnetic lines associated with solar storms and is robust to image rotation, glare, and optical artifacts.
Cascaded information enhancement and cross-modal attention feature fusion for multispectral pedestrian detection
Feb 17, 2023
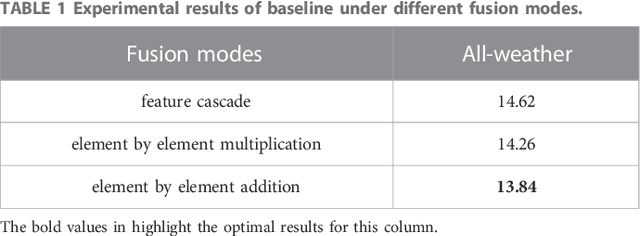
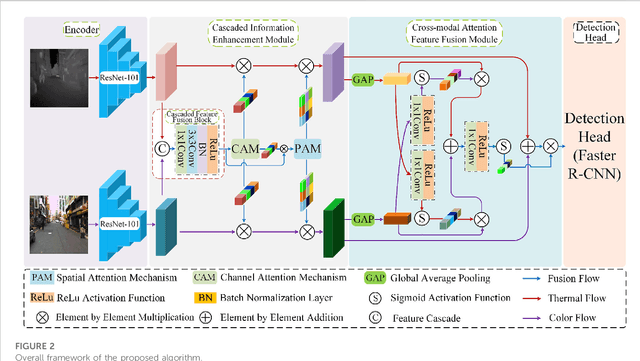
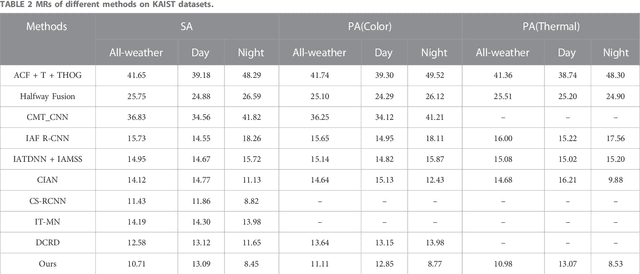
Multispectral pedestrian detection is a technology designed to detect and locate pedestrians in Color and Thermal images, which has been widely used in automatic driving, video surveillance, etc. So far most available multispectral pedestrian detection algorithms only achieved limited success in pedestrian detection because of the lacking take into account the confusion of pedestrian information and background noise in Color and Thermal images. Here we propose a multispectral pedestrian detection algorithm, which mainly consists of a cascaded information enhancement module and a cross-modal attention feature fusion module. On the one hand, the cascaded information enhancement module adopts the channel and spatial attention mechanism to perform attention weighting on the features fused by the cascaded feature fusion block. Moreover, it multiplies the single-modal features with the attention weight element by element to enhance the pedestrian features in the single-modal and thus suppress the interference from the background. On the other hand, the cross-modal attention feature fusion module mines the features of both Color and Thermal modalities to complement each other, then the global features are constructed by adding the cross-modal complemented features element by element, which are attentionally weighted to achieve the effective fusion of the two modal features. Finally, the fused features are input into the detection head to detect and locate pedestrians. Extensive experiments have been performed on two improved versions of annotations (sanitized annotations and paired annotations) of the public dataset KAIST. The experimental results show that our method demonstrates a lower pedestrian miss rate and more accurate pedestrian detection boxes compared to the comparison method. Additionally, the ablation experiment also proved the effectiveness of each module designed in this paper.