 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Spatial-SpinDrop: Spatial Dropout-based Binary Bayesian Neural Network with Spintronics Implementation
Jun 16, 2023
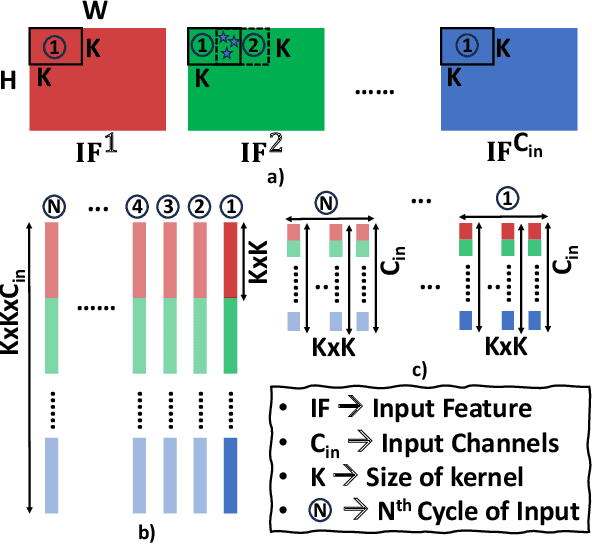
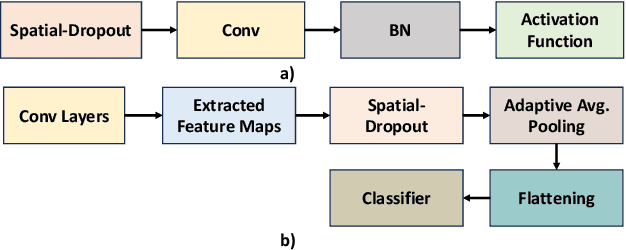
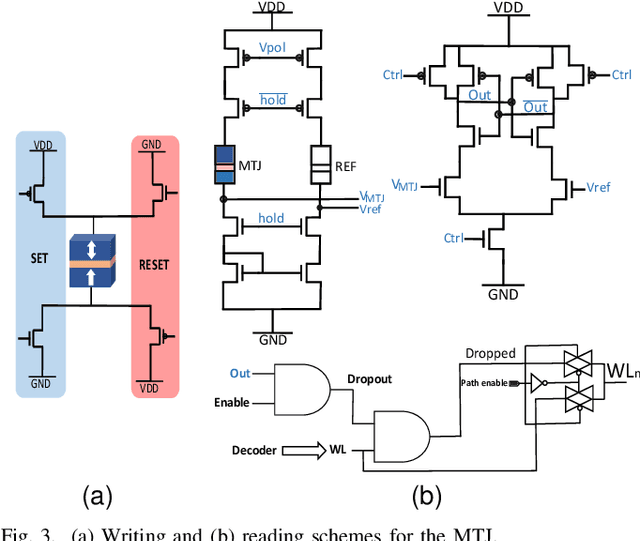
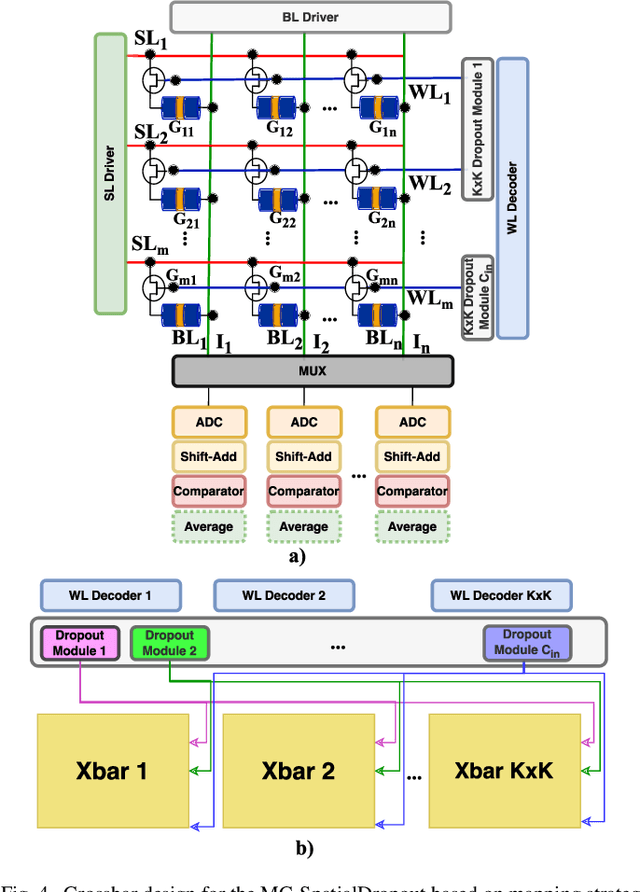
Recently, machine learning systems have gained prominence in real-time, critical decision-making domains, such as autonomous driving and industrial automation. Their implementations should avoid overconfident predictions through uncertainty estimation. Bayesian Neural Networks (BayNNs) are principled methods for estimating predictive uncertainty. However, their computational costs and power consumption hinder their widespread deployment in edge AI. Utilizing Dropout as an approximation of the posterior distribution, binarizing the parameters of BayNNs, and further to that implementing them in spintronics-based computation-in-memory (CiM) hardware arrays provide can be a viable solution. However, designing hardware Dropout modules for convolutional neural network (CNN) topologies is challenging and expensive, as they may require numerous Dropout modules and need to use spatial information to drop certain elements. In this paper, we introduce MC-SpatialDropout, a spatial dropout-based approximate BayNNs with spintronics emerging devices. Our method utilizes the inherent stochasticity of spintronic devices for efficient implementation of the spatial dropout module compared to existing implementations. Furthermore, the number of dropout modules per network layer is reduced by a factor of $9\times$ and energy consumption by a factor of $94.11\times$, while still achieving comparable predictive performance and uncertainty estimates compared to related works.
Probing Brain Context-Sensitivity with Masked-Attention Generation
May 23, 2023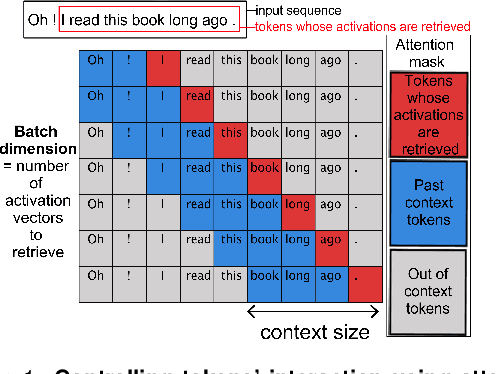
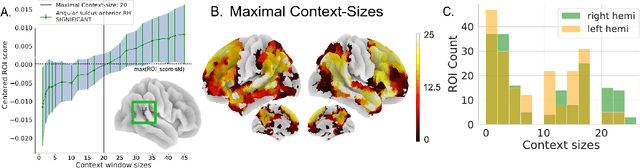
Two fundamental questions in neurolinguistics concerns the brain regions that integrate information beyond the lexical level, and the size of their window of integration. To address these questions we introduce a new approach named masked-attention generation. It uses GPT-2 transformers to generate word embeddings that capture a fixed amount of contextual information. We then tested whether these embeddings could predict fMRI brain activity in humans listening to naturalistic text. The results showed that most of the cortex within the language network is sensitive to contextual information, and that the right hemisphere is more sensitive to longer contexts than the left. Masked-attention generation supports previous analyses of context-sensitivity in the brain, and complements them by quantifying the window size of context integration per voxel.
* 2 pages, 2 figures, CCN 2023
Sound reconstruction from human brain activity via a generative model with brain-like auditory features
Jun 20, 2023The successful reconstruction of perceptual experiences from human brain activity has provided insights into the neural representations of sensory experiences. However, reconstructing arbitrary sounds has been avoided due to the complexity of temporal sequences in sounds and the limited resolution of neuroimaging modalities. To overcome these challenges, leveraging the hierarchical nature of brain auditory processing could provide a path toward reconstructing arbitrary sounds. Previous studies have indicated a hierarchical homology between the human auditory system and deep neural network (DNN) models. Furthermore, advancements in audio-generative models enable to transform compressed representations back into high-resolution sounds. In this study, we introduce a novel sound reconstruction method that combines brain decoding of auditory features with an audio-generative model. Using fMRI responses to natural sounds, we found that the hierarchical sound features of a DNN model could be better decoded than spectrotemporal features. We then reconstructed the sound using an audio transformer that disentangled compressed temporal information in the decoded DNN features. Our method shows unconstrained sounds reconstruction capturing sound perceptual contents and quality and generalizability by reconstructing sound categories not included in the training dataset. Reconstructions from different auditory regions remain similar to actual sounds, highlighting the distributed nature of auditory representations. To see whether the reconstructions mirrored actual subjective perceptual experiences, we performed an experiment involving selective auditory attention to one of overlapping sounds. The results tended to resemble the attended sound than the unattended. These findings demonstrate that our proposed model provides a means to externalize experienced auditory contents from human brain activity.
Align, Adapt and Inject: Sound-guided Unified Image Generation
Jun 20, 2023
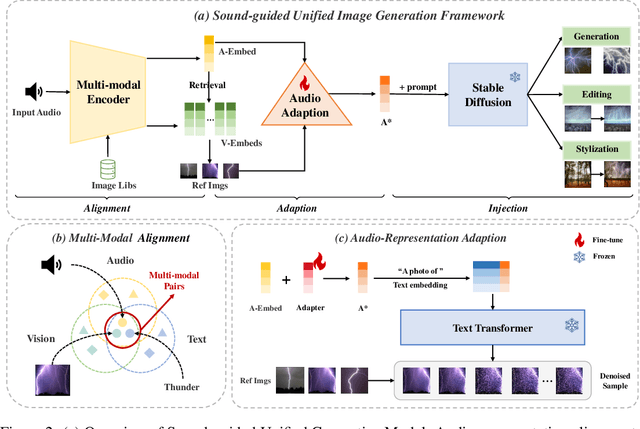

Text-guided image generation has witnessed unprecedented progress due to the development of diffusion models. Beyond text and image, sound is a vital element within the sphere of human perception, offering vivid representations and naturally coinciding with corresponding scenes. Taking advantage of sound therefore presents a promising avenue for exploration within image generation research. However, the relationship between audio and image supervision remains significantly underdeveloped, and the scarcity of related, high-quality datasets brings further obstacles. In this paper, we propose a unified framework 'Align, Adapt, and Inject' (AAI) for sound-guided image generation, editing, and stylization. In particular, our method adapts input sound into a sound token, like an ordinary word, which can plug and play with existing powerful diffusion-based Text-to-Image (T2I) models. Specifically, we first train a multi-modal encoder to align audio representation with the pre-trained textual manifold and visual manifold, respectively. Then, we propose the audio adapter to adapt audio representation into an audio token enriched with specific semantics, which can be injected into a frozen T2I model flexibly. In this way, we are able to extract the dynamic information of varied sounds, while utilizing the formidable capability of existing T2I models to facilitate sound-guided image generation, editing, and stylization in a convenient and cost-effective manner. The experiment results confirm that our proposed AAI outperforms other text and sound-guided state-of-the-art methods. And our aligned multi-modal encoder is also competitive with other approaches in the audio-visual retrieval and audio-text retrieval tasks.
Brain Anatomy Prior Modeling to Forecast Clinical Progression of Cognitive Impairment with Structural MRI
Jun 20, 2023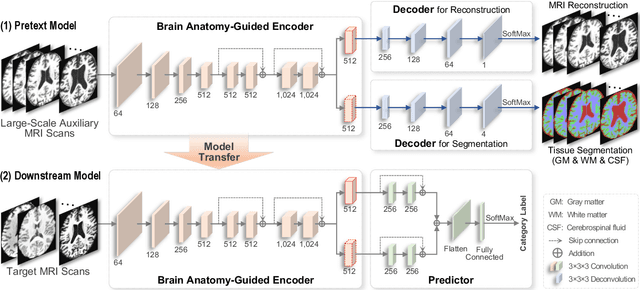

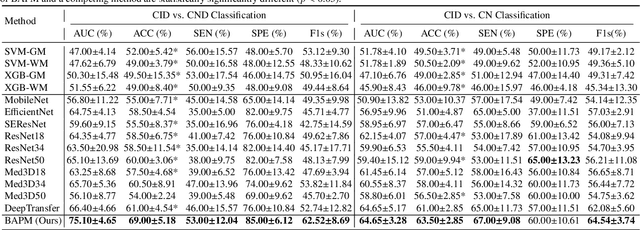
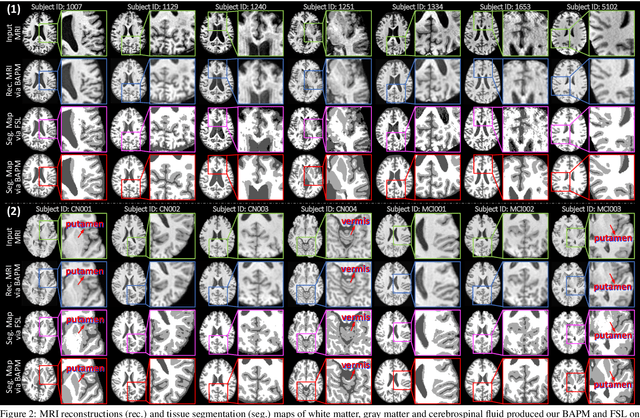
Brain structural MRI has been widely used to assess the future progression of cognitive impairment (CI). Previous learning-based studies usually suffer from the issue of small-sized labeled training data, while there exist a huge amount of structural MRIs in large-scale public databases. Intuitively, brain anatomical structures derived from these public MRIs (even without task-specific label information) can be used to boost CI progression trajectory prediction. However, previous studies seldom take advantage of such brain anatomy prior. To this end, this paper proposes a brain anatomy prior modeling (BAPM) framework to forecast the clinical progression of cognitive impairment with small-sized target MRIs by exploring anatomical brain structures. Specifically, the BAPM consists of a pretext model and a downstream model, with a shared brain anatomy-guided encoder to model brain anatomy prior explicitly. Besides the encoder, the pretext model also contains two decoders for two auxiliary tasks (i.e., MRI reconstruction and brain tissue segmentation), while the downstream model relies on a predictor for classification. The brain anatomy-guided encoder is pre-trained with the pretext model on 9,344 auxiliary MRIs without diagnostic labels for anatomy prior modeling. With this encoder frozen, the downstream model is then fine-tuned on limited target MRIs for prediction. We validate the BAPM on two CI-related studies with T1-weighted MRIs from 448 subjects. Experimental results suggest the effectiveness of BAPM in (1) four CI progression prediction tasks, (2) MR image reconstruction, and (3) brain tissue segmentation, compared with several state-of-the-art methods.
GaitGS: Temporal Feature Learning in Granularity and Span Dimension for Gait Recognition
Jun 01, 2023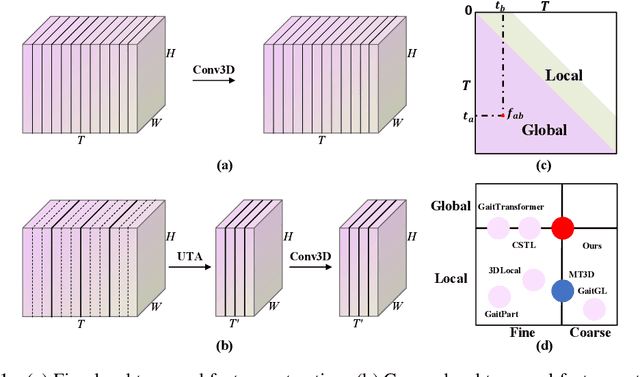
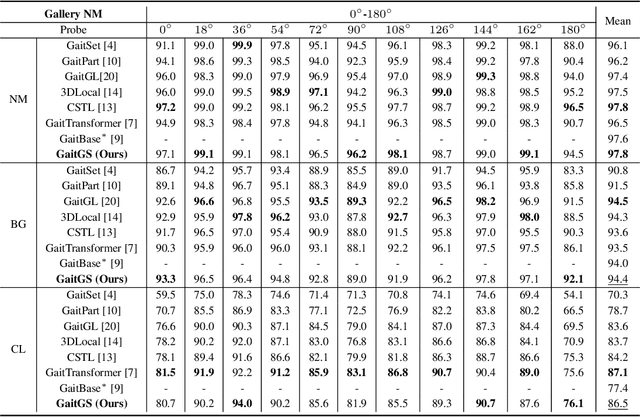
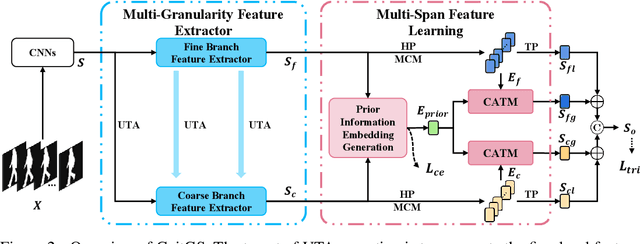
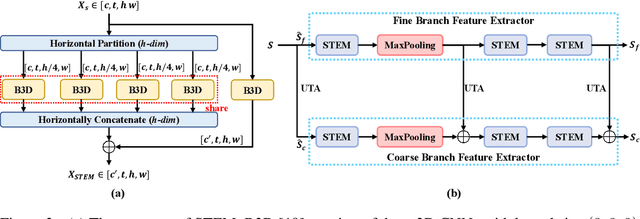
Gait recognition is an emerging biological recognition technology that identifies and verifies individuals based on their walking patterns. However, many current methods are limited in their use of temporal information. In order to fully harness the potential of gait recognition, it is crucial to consider temporal features at various granularities and spans. Hence, in this paper, we propose a novel framework named GaitGS, which aggregates temporal features in the granularity dimension and span dimension simultaneously. Specifically, Multi-Granularity Feature Extractor (MGFE) is proposed to focus on capturing the micro-motion and macro-motion information at the frame level and unit level respectively. Moreover, we present Multi-Span Feature Learning (MSFL) module to generate global and local temporal representations. On three popular gait datasets, extensive experiments demonstrate the state-of-the-art performance of our method. Our method achieves the Rank-1 accuracies of 92.9% (+0.5%), 52.0% (+1.4%), and 97.5% (+0.8%) on CASIA-B, GREW, and OU-MVLP respectively. The source code will be released soon.
Augmented Modular Reinforcement Learning based on Heterogeneous Knowledge
Jun 01, 2023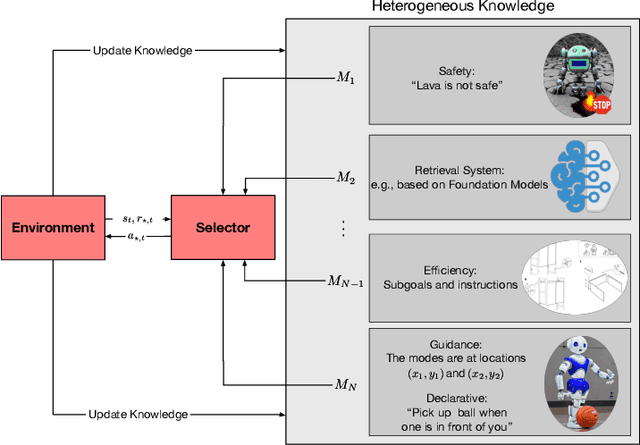
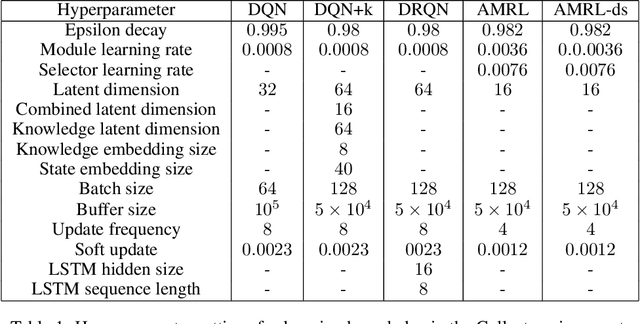
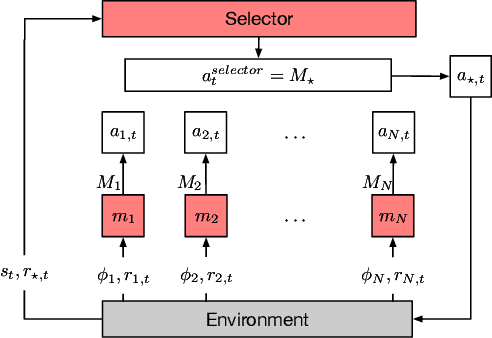
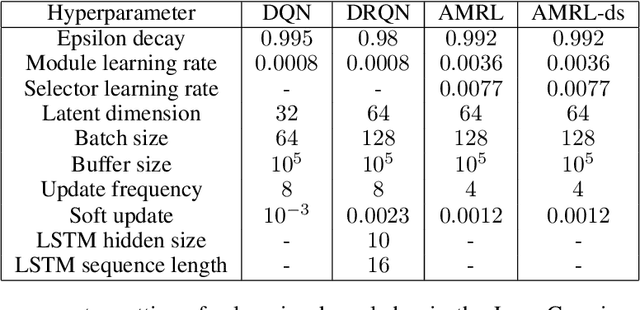
In order to mitigate some of the inefficiencies of Reinforcement Learning (RL), modular approaches composing different decision-making policies to derive agents capable of performing a variety of tasks have been proposed. The modules at the basis of these architectures are generally reusable, also allowing for "plug-and-play" integration. However, such solutions still lack the ability to process and integrate multiple types of information (knowledge), such as rules, sub-goals, and skills. We propose Augmented Modular Reinforcement Learning (AMRL) to address these limitations. This new framework uses an arbitrator to select heterogeneous modules and seamlessly incorporate different types of knowledge. Additionally, we introduce a variation of the selection mechanism, namely the Memory-Augmented Arbitrator, which adds the capability of exploiting temporal information. We evaluate the proposed mechanisms on established as well as new environments and benchmark them against prominent deep RL algorithms. Our results demonstrate the performance improvements that can be achieved by augmenting traditional modular RL with other forms of heterogeneous knowledge.
Boosting Breast Ultrasound Video Classification by the Guidance of Keyframe Feature Centers
Jun 12, 2023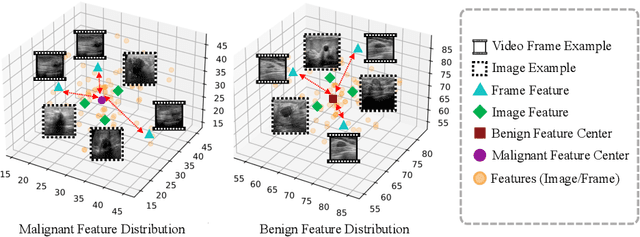
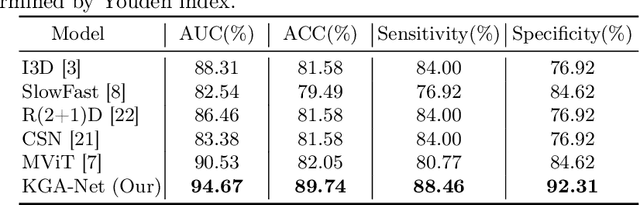
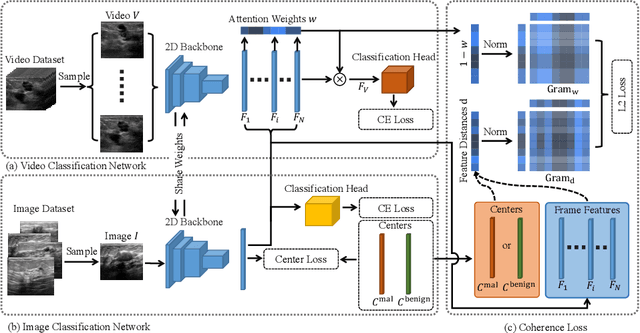
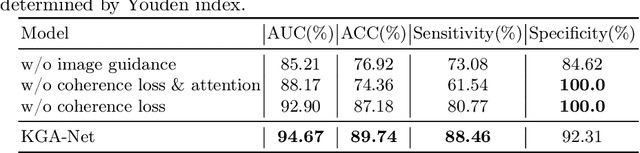
Breast ultrasound videos contain richer information than ultrasound images, therefore it is more meaningful to develop video models for this diagnosis task. However, the collection of ultrasound video datasets is much harder. In this paper, we explore the feasibility of enhancing the performance of ultrasound video classification using the static image dataset. To this end, we propose KGA-Net and coherence loss. The KGA-Net adopts both video clips and static images to train the network. The coherence loss uses the feature centers generated by the static images to guide the frame attention in the video model. Our KGA-Net boosts the performance on the public BUSV dataset by a large margin. The visualization results of frame attention prove the explainability of our method. The codes and model weights of our method will be made publicly available.
What drives the acceptance of AI technology?: the role of expectations and experiences
Jun 17, 2023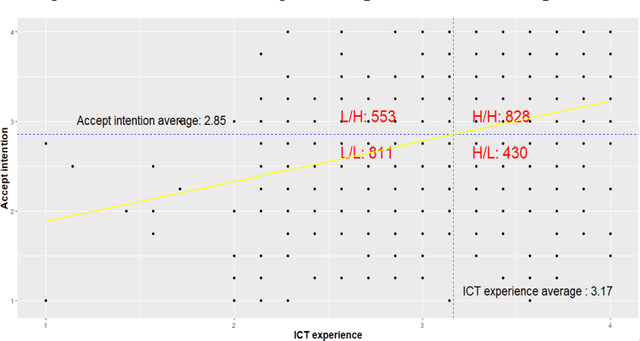
In recent years, Artificial intelligence products and services have been offered potential users as pilots. The acceptance intention towards artificial intelligence is greatly influenced by the experience with current AI products and services, expectations for AI, and past experiences with ICT technology. This study aims to explore the factors that impact AI acceptance intention and understand the process of its formation. The analysis results of this study reveal that AI experience and past ICT experience affect AI acceptance intention in two ways. Through the direct path, higher AI experience and ICT experience are associated with a greater intention to accept AI. Additionally, there is an indirect path where AI experience and ICT experience contribute to increased expectations for AI, and these expectations, in turn, elevate acceptance intention. Based on the findings, several recommendations are suggested for companies and public organizations planning to implement artificial intelligence in the future. It is crucial to manage the user experience of ICT services and pilot AI products and services to deliver positive experiences. It is essential to provide potential AI users with specific information about the features and benefits of AI products and services. This will enable them to develop realistic expectations regarding AI technology.
UniG3D: A Unified 3D Object Generation Dataset
Jun 19, 2023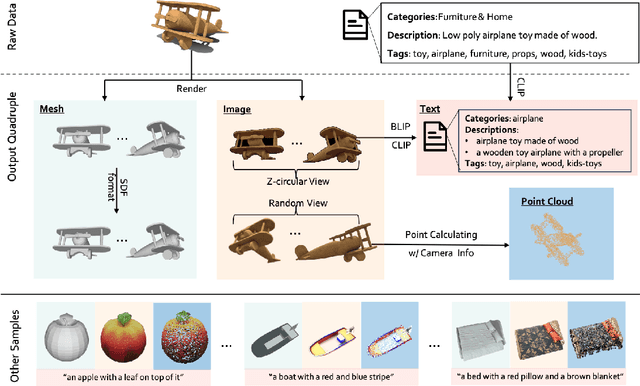
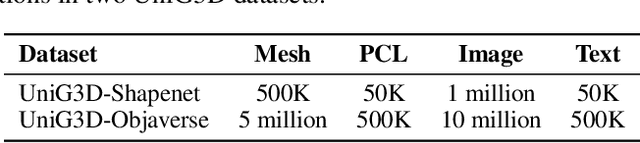
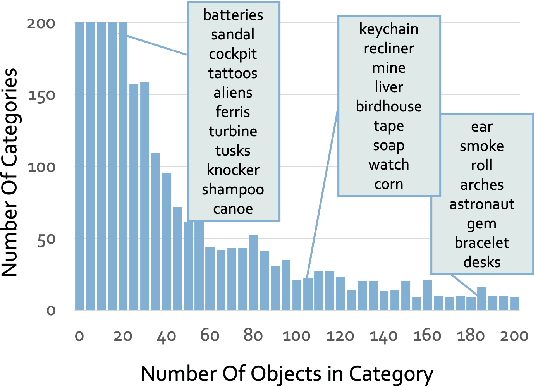
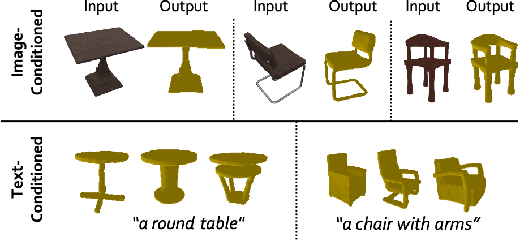
The field of generative AI has a transformative impact on various areas, including virtual reality, autonomous driving, the metaverse, gaming, and robotics. Among these applications, 3D object generation techniques are of utmost importance. This technique has unlocked fresh avenues in the realm of creating, customizing, and exploring 3D objects. However, the quality and diversity of existing 3D object generation methods are constrained by the inadequacies of existing 3D object datasets, including issues related to text quality, the incompleteness of multi-modal data representation encompassing 2D rendered images and 3D assets, as well as the size of the dataset. In order to resolve these issues, we present UniG3D, a unified 3D object generation dataset constructed by employing a universal data transformation pipeline on Objaverse and ShapeNet datasets. This pipeline converts each raw 3D model into comprehensive multi-modal data representation <text, image, point cloud, mesh> by employing rendering engines and multi-modal models. These modules ensure the richness of textual information and the comprehensiveness of data representation. Remarkably, the universality of our pipeline refers to its ability to be applied to any 3D dataset, as it only requires raw 3D data. The selection of data sources for our dataset is based on their scale and quality. Subsequently, we assess the effectiveness of our dataset by employing Point-E and SDFusion, two widely recognized methods for object generation, tailored to the prevalent 3D representations of point clouds and signed distance functions. Our dataset is available at: https://unig3d.github.io.