 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Evade ChatGPT Detectors via A Single Space
Jul 05, 2023
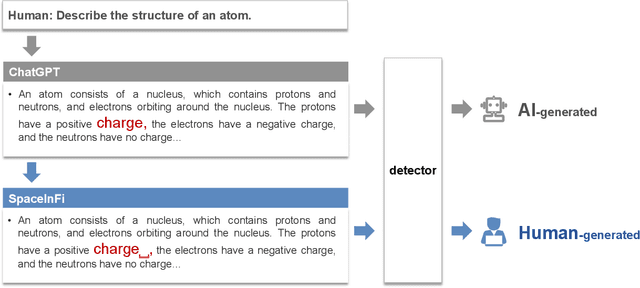
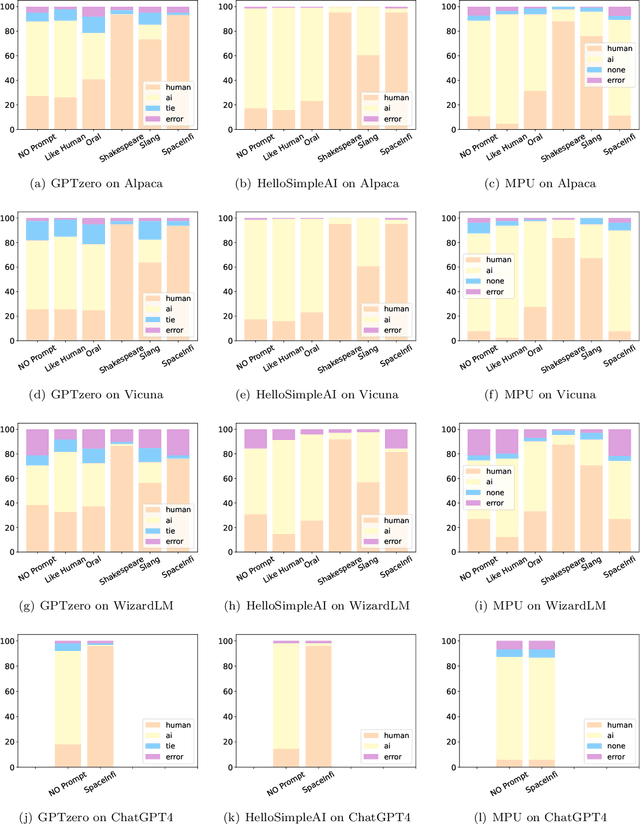
ChatGPT brings revolutionary social value but also raises concerns about the misuse of AI-generated content. Consequently, an important question is how to detect whether content is generated by ChatGPT or by human. Existing detectors are built upon the assumption that there are distributional gaps between human-generated and AI-generated content. These gaps are typically identified using statistical information or classifiers. Our research challenges the distributional gap assumption in detectors. We find that detectors do not effectively discriminate the semantic and stylistic gaps between human-generated and AI-generated content. Instead, the "subtle differences", such as an extra space, become crucial for detection. Based on this discovery, we propose the SpaceInfi strategy to evade detection. Experiments demonstrate the effectiveness of this strategy across multiple benchmarks and detectors. We also provide a theoretical explanation for why SpaceInfi is successful in evading perplexity-based detection. Our findings offer new insights and challenges for understanding and constructing more applicable ChatGPT detectors.
Object Recognition System on a Tactile Device for Visually Impaired
Jul 05, 2023People with visual impairments face numerous challenges when interacting with their environment. Our objective is to develop a device that facilitates communication between individuals with visual impairments and their surroundings. The device will convert visual information into auditory feedback, enabling users to understand their environment in a way that suits their sensory needs. Initially, an object detection model is selected from existing machine learning models based on its accuracy and cost considerations, including time and power consumption. The chosen model is then implemented on a Raspberry Pi, which is connected to a specifically designed tactile device. When the device is touched at a specific position, it provides an audio signal that communicates the identification of the object present in the scene at that corresponding position to the visually impaired individual. Conducted tests have demonstrated the effectiveness of this device in scene understanding, encompassing static or dynamic objects, as well as screen contents such as TVs, computers, and mobile phones.
Remote Sensing Image Change Detection with Graph Interaction
Jul 05, 2023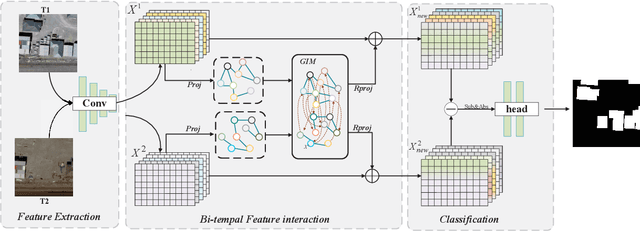
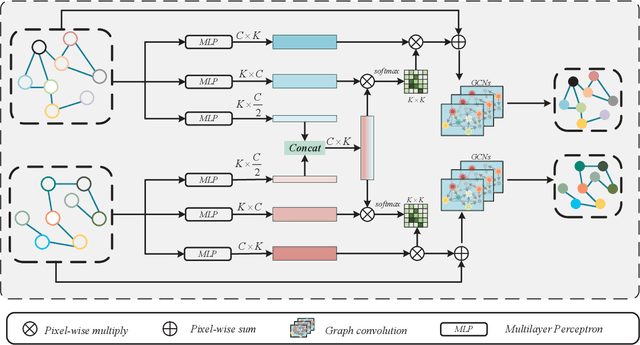

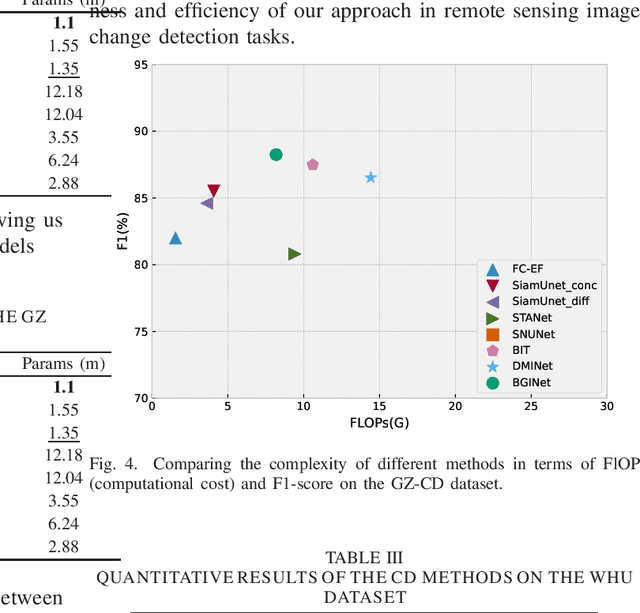
Modern remote sensing image change detection has witnessed substantial advancements by harnessing the potent feature extraction capabilities of CNNs and Transforms.Yet,prevailing change detection techniques consistently prioritize extracting semantic features related to significant alterations,overlooking the viability of directly interacting with bitemporal image features.In this letter,we propose a bitemporal image graph Interaction network for remote sensing change detection,namely BGINet-CD. More specifically,by leveraging the concept of non-local operations and mapping the features obtained from the backbone network to the graph structure space,we propose a unified self-focus mechanism for bitemporal images.This approach enhances the information coupling between the two temporal images while effectively suppressing task-irrelevant interference,Based on a streamlined backbone architecture,namely ResNet18,our model demonstrates superior performance compared to other state-of-the-art methods (SOTA) on the GZ CD dataset. Moreover,the model exhibits an enhanced trade-off between accuracy and computational efficiency,further improving its overall effectiveness
Scaling Distributed Multi-task Reinforcement Learning with Experience Sharing
Jul 11, 2023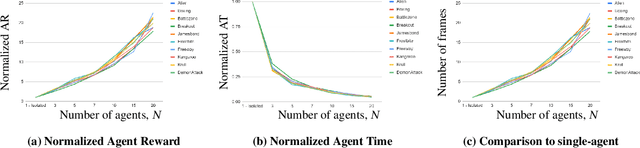
Recently, DARPA launched the ShELL program, which aims to explore how experience sharing can benefit distributed lifelong learning agents in adapting to new challenges. In this paper, we address this issue by conducting both theoretical and empirical research on distributed multi-task reinforcement learning (RL), where a group of $N$ agents collaboratively solves $M$ tasks without prior knowledge of their identities. We approach the problem by formulating it as linearly parameterized contextual Markov decision processes (MDPs), where each task is represented by a context that specifies the transition dynamics and rewards. To tackle this problem, we propose an algorithm called DistMT-LSVI. First, the agents identify the tasks, and then they exchange information through a central server to derive $\epsilon$-optimal policies for the tasks. Our research demonstrates that to achieve $\epsilon$-optimal policies for all $M$ tasks, a single agent using DistMT-LSVI needs to run a total number of episodes that is at most $\tilde{\mathcal{O}}({d^3H^6(\epsilon^{-2}+c_{\rm sep}^{-2})}\cdot M/N)$, where $c_{\rm sep}>0$ is a constant representing task separability, $H$ is the horizon of each episode, and $d$ is the feature dimension of the dynamics and rewards. Notably, DistMT-LSVI improves the sample complexity of non-distributed settings by a factor of $1/N$, as each agent independently learns $\epsilon$-optimal policies for all $M$ tasks using $\tilde{\mathcal{O}}(d^3H^6M\epsilon^{-2})$ episodes. Additionally, we provide numerical experiments conducted on OpenAI Gym Atari environments that validate our theoretical findings.
MinkSORT: A 3D deep feature extractor using sparse convolutions to improve 3D multi-object tracking in greenhouse tomato plants
Jul 11, 2023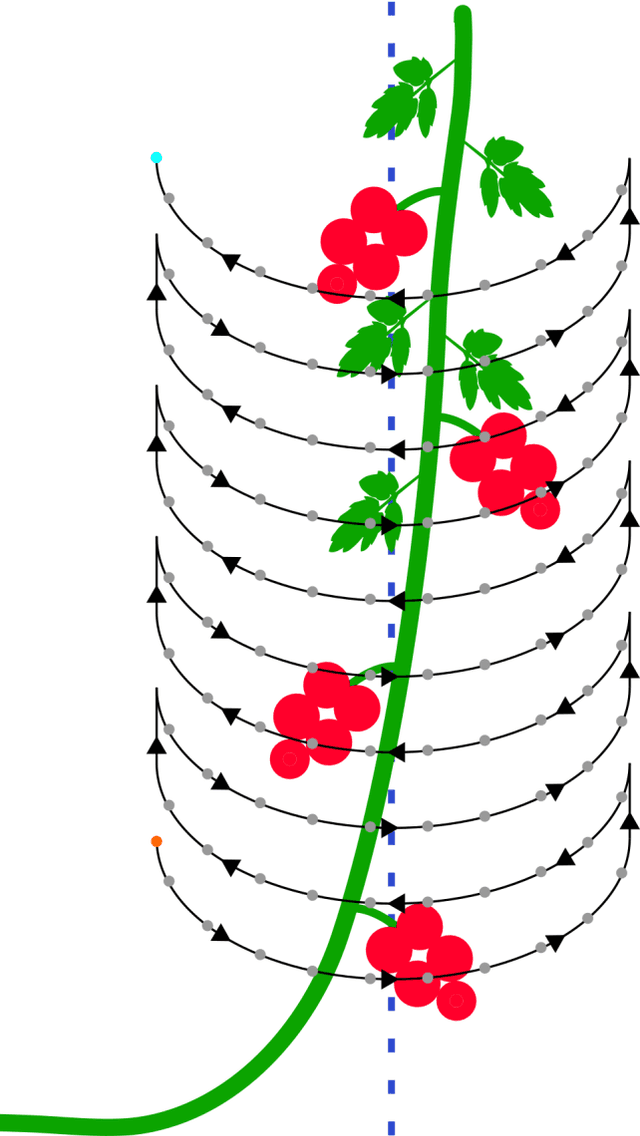
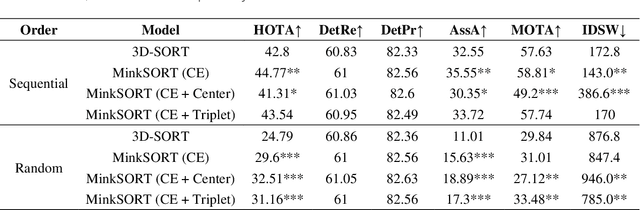

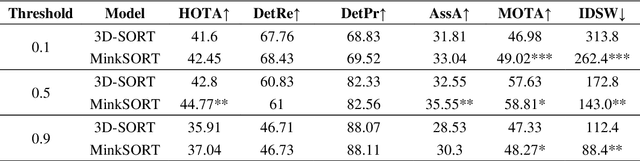
The agro-food industry is turning to robots to address the challenge of labour shortage. However, agro-food environments pose difficulties for robots due to high variation and occlusions. In the presence of these challenges, accurate world models, with information about object location, shape, and properties, are crucial for robots to perform tasks accurately. Building such models is challenging due to the complex and unique nature of agro-food environments, and errors in the model can lead to task execution issues. In this paper, we propose MinkSORT, a novel method for generating tracking features using a 3D sparse convolutional network in a deepSORT-like approach to improve the accuracy of world models in agro-food environments. We evaluated our feature extractor network using real-world data collected in a tomato greenhouse, which significantly improved the performance of our baseline model that tracks tomato positions in 3D using a Kalman filter and Mahalanobis distance. Our deep learning feature extractor improved the HOTA from 42.8% to 44.77%, the association accuracy from 32.55% to 35.55%, and the MOTA from 57.63% to 58.81%. We also evaluated different contrastive loss functions for training our deep learning feature extractor and demonstrated that our approach leads to improved performance in terms of three separate precision and recall detection outcomes. Our method improves world model accuracy, enabling robots to perform tasks such as harvesting and plant maintenance with greater efficiency and accuracy, which is essential for meeting the growing demand for food in a sustainable manner.
Learning Active Subspaces and Discovering Important Features with Gaussian Radial Basis Functions Neural Networks
Jul 11, 2023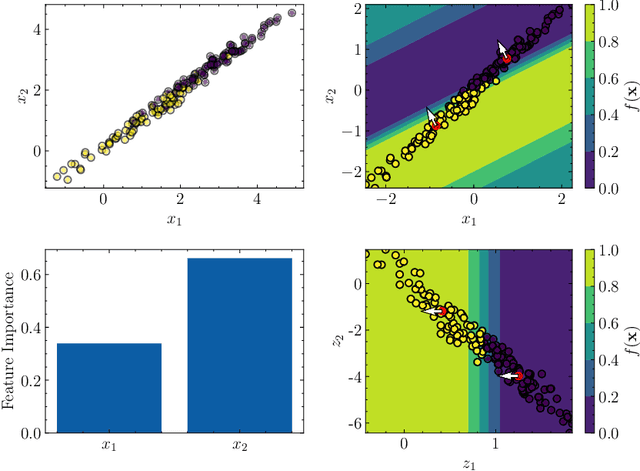
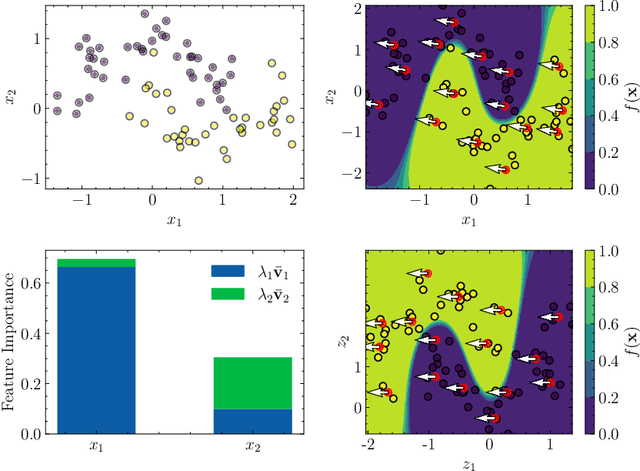
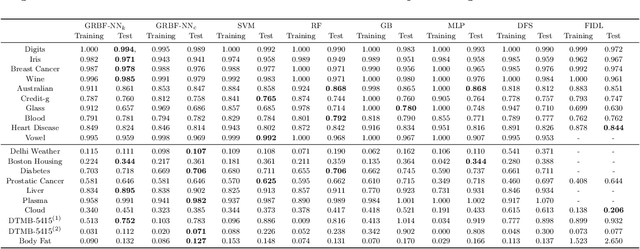
Providing a model that achieves a strong predictive performance and at the same time is interpretable by humans is one of the most difficult challenges in machine learning research due to the conflicting nature of these two objectives. To address this challenge, we propose a modification of the Radial Basis Function Neural Network model by equipping its Gaussian kernel with a learnable precision matrix. We show that precious information is contained in the spectrum of the precision matrix that can be extracted once the training of the model is completed. In particular, the eigenvectors explain the directions of maximum sensitivity of the model revealing the active subspace and suggesting potential applications for supervised dimensionality reduction. At the same time, the eigenvectors highlight the relationship in terms of absolute variation between the input and the latent variables, thereby allowing us to extract a ranking of the input variables based on their importance to the prediction task enhancing the model interpretability. We conducted numerical experiments for regression, classification, and feature selection tasks, comparing our model against popular machine learning models and the state-of-the-art deep learning-based embedding feature selection techniques. Our results demonstrate that the proposed model does not only yield an attractive prediction performance with respect to the competitors but also provides meaningful and interpretable results that potentially could assist the decision-making process in real-world applications. A PyTorch implementation of the model is available on GitHub at the following link. https://github.com/dannyzx/GRBF-NNs
Generative Contrastive Graph Learning for Recommendation
Jul 11, 2023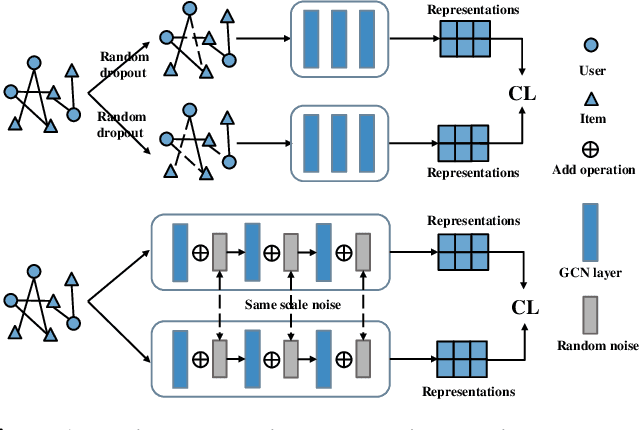
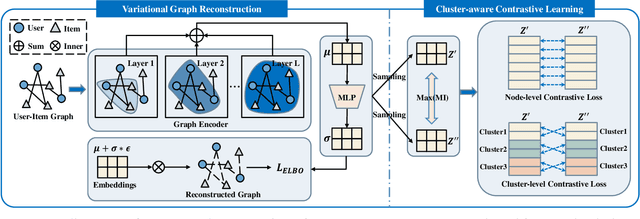
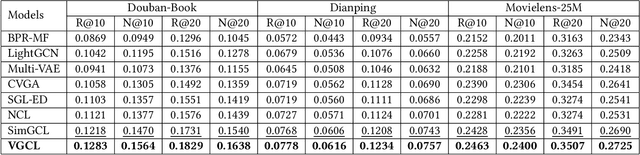
By treating users' interactions as a user-item graph, graph learning models have been widely deployed in Collaborative Filtering(CF) based recommendation. Recently, researchers have introduced Graph Contrastive Learning(GCL) techniques into CF to alleviate the sparse supervision issue, which first constructs contrastive views by data augmentations and then provides self-supervised signals by maximizing the mutual information between contrastive views. Despite the effectiveness, we argue that current GCL-based recommendation models are still limited as current data augmentation techniques, either structure augmentation or feature augmentation. First, structure augmentation randomly dropout nodes or edges, which is easy to destroy the intrinsic nature of the user-item graph. Second, feature augmentation imposes the same scale noise augmentation on each node, which neglects the unique characteristics of nodes on the graph. To tackle the above limitations, we propose a novel Variational Graph Generative-Contrastive Learning(VGCL) framework for recommendation. Specifically, we leverage variational graph reconstruction to estimate a Gaussian distribution of each node, then generate multiple contrastive views through multiple samplings from the estimated distributions, which builds a bridge between generative and contrastive learning. Besides, the estimated variances are tailored to each node, which regulates the scale of contrastive loss for each node on optimization. Considering the similarity of the estimated distributions, we propose a cluster-aware twofold contrastive learning, a node-level to encourage consistency of a node's contrastive views and a cluster-level to encourage consistency of nodes in a cluster. Finally, extensive experimental results on three public datasets clearly demonstrate the effectiveness of the proposed model.
DiffInfinite: Large Mask-Image Synthesis via Parallel Random Patch Diffusion in Histopathology
Jun 23, 2023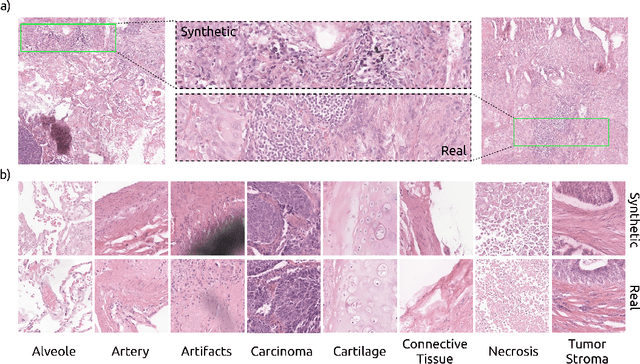
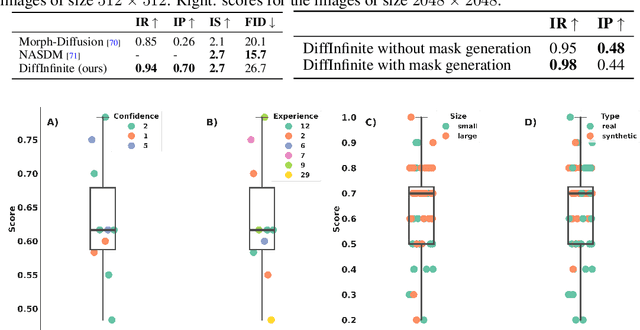
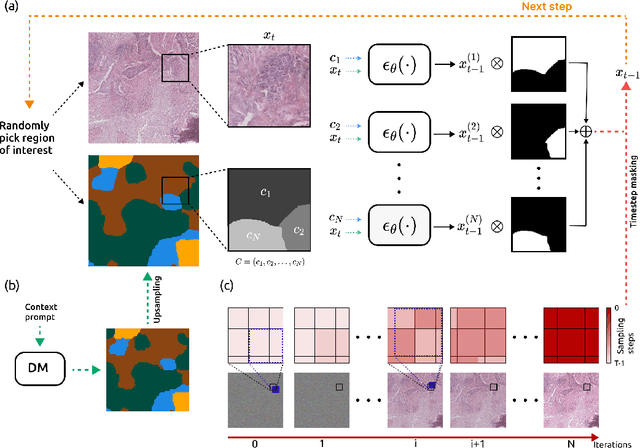

We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artefacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is validated in a survey by ten experienced pathologists as well as a downstream segmentation task. Furthermore, the model scores strongly on anti-copying metrics which is beneficial for the protection of patient data.
Dual Arbitrary Scale Super-Resolution for Multi-Contrast MRI
Jul 10, 2023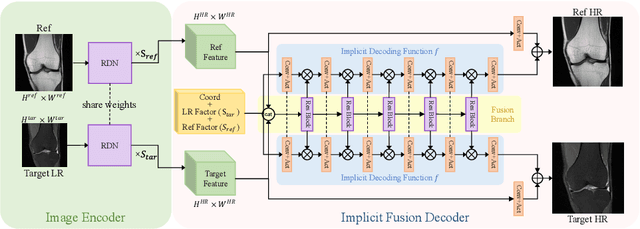
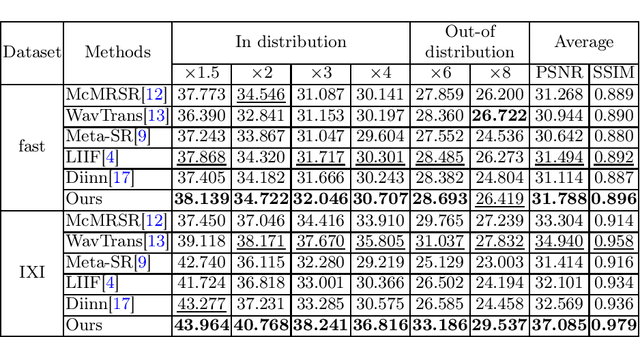
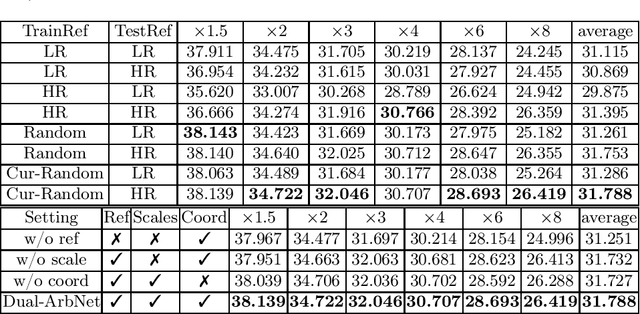
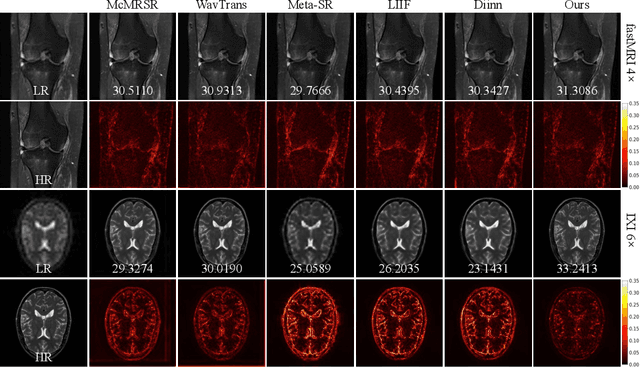
Limited by imaging systems, the reconstruction of Magnetic Resonance Imaging (MRI) images from partial measurement is essential to medical imaging research. Benefiting from the diverse and complementary information of multi-contrast MR images in different imaging modalities, multi-contrast Super-Resolution (SR) reconstruction is promising to yield SR images with higher quality. In the medical scenario, to fully visualize the lesion, radiologists are accustomed to zooming the MR images at arbitrary scales rather than using a fixed scale, as used by most MRI SR methods. In addition, existing multi-contrast MRI SR methods often require a fixed resolution for the reference image, which makes acquiring reference images difficult and imposes limitations on arbitrary scale SR tasks. To address these issues, we proposed an implicit neural representations based dual-arbitrary multi-contrast MRI super-resolution method, called Dual-ArbNet. First, we decouple the resolution of the target and reference images by a feature encoder, enabling the network to input target and reference images at arbitrary scales. Then, an implicit fusion decoder fuses the multi-contrast features and uses an Implicit Decoding Function~(IDF) to obtain the final MRI SR results. Furthermore, we introduce a curriculum learning strategy to train our network, which improves the generalization and performance of our Dual-ArbNet. Extensive experiments in two public MRI datasets demonstrate that our method outperforms state-of-the-art approaches under different scale factors and has great potential in clinical practice.
VerifAI: Verified Generative AI
Jul 06, 2023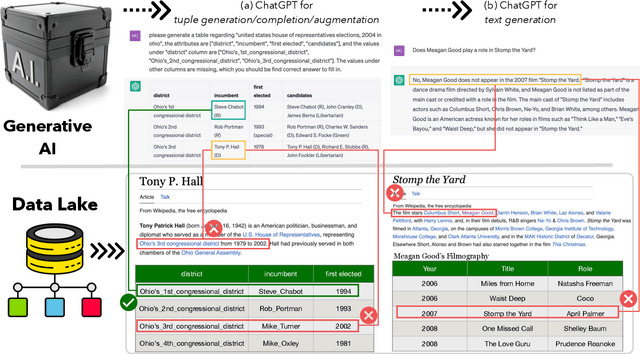
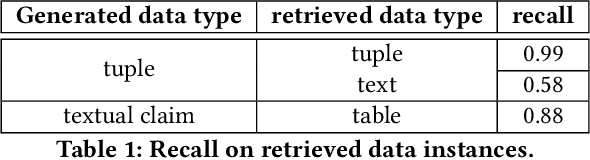
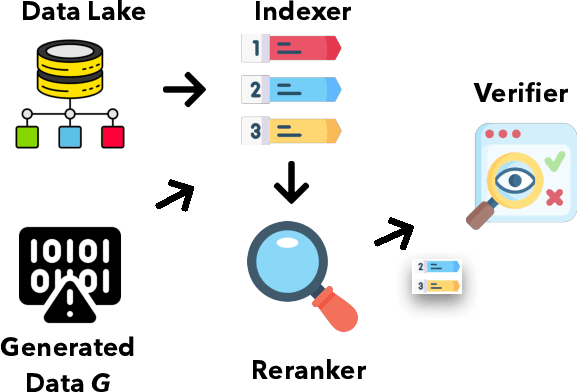
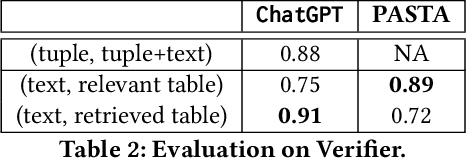
Generative AI has made significant strides, yet concerns about the accuracy and reliability of its outputs continue to grow. Such inaccuracies can have serious consequences such as inaccurate decision-making, the spread of false information, privacy violations, legal liabilities, and more. Although efforts to address these risks are underway, including explainable AI and responsible AI practices such as transparency, privacy protection, bias mitigation, and social and environmental responsibility, misinformation caused by generative AI will remain a significant challenge. We propose that verifying the outputs of generative AI from a data management perspective is an emerging issue for generative AI. This involves analyzing the underlying data from multi-modal data lakes, including text files, tables, and knowledge graphs, and assessing its quality and consistency. By doing so, we can establish a stronger foundation for evaluating the outputs of generative AI models. Such an approach can ensure the correctness of generative AI, promote transparency, and enable decision-making with greater confidence. Our vision is to promote the development of verifiable generative AI and contribute to a more trustworthy and responsible use of AI.