 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoguided Online Data Curation for Diffusion Model Training
Sep 18, 2025The costs of generative model compute rekindled promises and hopes for efficient data curation. In this work, we investigate whether recently developed autoguidance and online data selection methods can improve the time and sample efficiency of training generative diffusion models. We integrate joint example selection (JEST) and autoguidance into a unified code base for fast ablation and benchmarking. We evaluate combinations of data curation on a controlled 2-D synthetic data generation task as well as (3x64x64)-D image generation. Our comparisons are made at equal wall-clock time and equal number of samples, explicitly accounting for the overhead of selection. Across experiments, autoguidance consistently improves sample quality and diversity. Early AJEST (applying selection only at the beginning of training) can match or modestly exceed autoguidance alone in data efficiency on both tasks. However, its time overhead and added complexity make autoguidance or uniform random data selection preferable in most situations. These findings suggest that while targeted online selection can yield efficiency gains in early training, robust sample quality improvements are primarily driven by autoguidance. We discuss limitations and scope, and outline when data selection may be beneficial.
Unsupervised Segmentation by Diffusing, Walking and Cutting
Dec 06, 2024We propose an unsupervised image segmentation method using features from pre-trained text-to-image diffusion models. Inspired by classic spectral clustering approaches, we construct adjacency matrices from self-attention layers between image patches and recursively partition using Normalised Cuts. A key insight is that self-attention probability distributions, which capture semantic relations between patches, can be interpreted as a transition matrix for random walks across the image. We leverage this by first using Random Walk Normalized Cuts directly on these self-attention activations to partition the image, minimizing transition probabilities between clusters while maximizing coherence within clusters. Applied recursively, this yields a hierarchical segmentation that reflects the rich semantics in the pre-trained attention layers, without any additional training. Next, we explore other ways to build the NCuts adjacency matrix from features, and how we can use the random walk interpretation of self-attention to capture long-range relationships. Finally, we propose an approach to automatically determine the NCut cost criterion, avoiding the need to tune this manually. We quantitatively analyse the effect incorporating different features, a constant versus dynamic NCut threshold, and incorporating multi-node paths when constructing the NCuts adjacency matrix. We show that our approach surpasses all existing methods for zero-shot unsupervised segmentation, achieving state-of-the-art results on COCO-Stuff-27 and Cityscapes.
ARTeFACT: Benchmarking Segmentation Models on Diverse Analogue Media Damage
Dec 05, 2024



Accurately detecting and classifying damage in analogue media such as paintings, photographs, textiles, mosaics, and frescoes is essential for cultural heritage preservation. While machine learning models excel in correcting degradation if the damage operator is known a priori, we show that they fail to robustly predict where the damage is even after supervised training; thus, reliable damage detection remains a challenge. Motivated by this, we introduce ARTeFACT, a dataset for damage detection in diverse types analogue media, with over 11,000 annotations covering 15 kinds of damage across various subjects, media, and historical provenance. Furthermore, we contribute human-verified text prompts describing the semantic contents of the images, and derive additional textual descriptions of the annotated damage. We evaluate CNN, Transformer, diffusion-based segmentation models, and foundation vision models in zero-shot, supervised, unsupervised and text-guided settings, revealing their limitations in generalising across media types. Our dataset is available at $\href{https://daniela997.github.io/ARTeFACT/}{https://daniela997.github.io/ARTeFACT/}$ as the first-of-its-kind benchmark for analogue media damage detection and restoration.
State-of-the-Art Fails in the Art of Damage Detection
Aug 23, 2024


Accurately detecting and classifying damage in analogue media such as paintings, photographs, textiles, mosaics, and frescoes is essential for cultural heritage preservation. While machine learning models excel in correcting global degradation if the damage operator is known a priori, we show that they fail to predict where the damage is even after supervised training; thus, reliable damage detection remains a challenge. We introduce DamBench, a dataset for damage detection in diverse analogue media, with over 11,000 annotations covering 15 damage types across various subjects and media. We evaluate CNN, Transformer, and text-guided diffusion segmentation models, revealing their limitations in generalising across media types.
Is One GPU Enough? Pushing Image Generation at Higher-Resolutions with Foundation Models
Jun 12, 2024



In this work, we introduce Pixelsmith, a zero-shot text-to-image generative framework to sample images at higher resolutions with a single GPU. We are the first to show that it is possible to scale the output of a pre-trained diffusion model by a factor of 1000, opening the road for gigapixel image generation at no additional cost. Our cascading method uses the image generated at the lowest resolution as a baseline to sample at higher resolutions. For the guidance, we introduce the Slider, a tunable mechanism that fuses the overall structure contained in the first-generated image with enhanced fine details. At each inference step, we denoise patches rather than the entire latent space, minimizing memory demands such that a single GPU can handle the process, regardless of the image's resolution. Our experimental results show that Pixelsmith not only achieves higher quality and diversity compared to existing techniques, but also reduces sampling time and artifacts. The code for our work is available at https://github.com/Thanos-DB/Pixelsmith.
Generative Fractional Diffusion Models
Oct 26, 2023



We generalize the continuous time framework for score-based generative models from an underlying Brownian motion (BM) to an approximation of fractional Brownian motion (FBM). We derive a continuous reparameterization trick and the reverse time model by representing FBM as a stochastic integral over a family of Ornstein-Uhlenbeck processes to define generative fractional diffusion models (GFDM) with driving noise converging to a non-Markovian process of infinite quadratic variation. The Hurst index $H\in(0,1)$ of FBM enables control of the roughness of the distribution transforming path. To the best of our knowledge, this is the first attempt to build a generative model upon a stochastic process with infinite quadratic variation.
DiffInfinite: Large Mask-Image Synthesis via Parallel Random Patch Diffusion in Histopathology
Jun 23, 2023



We present DiffInfinite, a hierarchical diffusion model that generates arbitrarily large histological images while preserving long-range correlation structural information. Our approach first generates synthetic segmentation masks, subsequently used as conditions for the high-fidelity generative diffusion process. The proposed sampling method can be scaled up to any desired image size while only requiring small patches for fast training. Moreover, it can be parallelized more efficiently than previous large-content generation methods while avoiding tiling artefacts. The training leverages classifier-free guidance to augment a small, sparsely annotated dataset with unlabelled data. Our method alleviates unique challenges in histopathological imaging practice: large-scale information, costly manual annotation, and protective data handling. The biological plausibility of DiffInfinite data is validated in a survey by ten experienced pathologists as well as a downstream segmentation task. Furthermore, the model scores strongly on anti-copying metrics which is beneficial for the protection of patient data.
Data Models for Dataset Drift Controls in Machine Learning With Images
Nov 04, 2022



Camera images are ubiquitous in machine learning research. They also play a central role in the delivery of important services spanning medicine and environmental surveying. However, the application of machine learning models in these domains has been limited because of robustness concerns. A primary failure mode are performance drops due to differences between the training and deployment data. While there are methods to prospectively validate the robustness of machine learning models to such dataset drifts, existing approaches do not account for explicit models of the primary object of interest: the data. This makes it difficult to create physically faithful drift test cases or to provide specifications of data models that should be avoided when deploying a machine learning model. In this study, we demonstrate how these shortcomings can be overcome by pairing machine learning robustness validation with physical optics. We examine the role raw sensor data and differentiable data models can play in controlling performance risks related to image dataset drift. The findings are distilled into three applications. First, drift synthesis enables the controlled generation of physically faithful drift test cases. The experiments presented here show that the average decrease in model performance is ten to four times less severe than under post-hoc augmentation testing. Second, the gradient connection between task and data models allows for drift forensics that can be used to specify performance-sensitive data models which should be avoided during deployment of a machine learning model. Third, drift adjustment opens up the possibility for processing adjustments in the face of drift. This can lead to speed up and stabilization of classifier training at a margin of up to 20% in validation accuracy. A guide to access the open code and datasets is available at https://github.com/aiaudit-org/raw2logit.
Bessel Equivariant Networks for Inversion of Transmission Effects in Multi-Mode Optical Fibres
Jul 26, 2022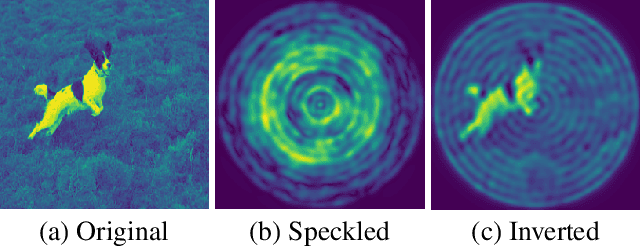
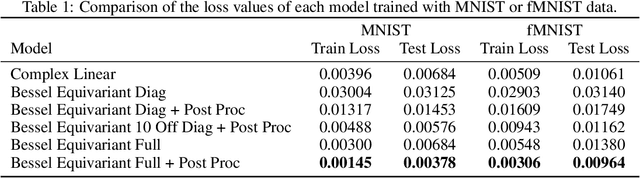


We develop a new type of model for solving the task of inverting the transmission effects of multi-mode optical fibres through the construction of an $\mathrm{SO}^{+}(2,1)$-equivariant neural network. This model takes advantage of the of the azimuthal correlations known to exist in fibre speckle patterns and naturally accounts for the difference in spatial arrangement between input and speckle patterns. In addition, we use a second post-processing network to remove circular artifacts, fill gaps, and sharpen the images, which is required due to the nature of optical fibre transmission. This two stage approach allows for the inspection of the predicted images produced by the more robust physically motivated equivariant model, which could be useful in a safety-critical application, or by the output of both models, which produces high quality images. Further, this model can scale to previously unachievable resolutions of imaging with multi-mode optical fibres and is demonstrated on $256 \times 256$ pixel images. This is a result of improving the trainable parameter requirement from $\mathcal{O}(N^4)$ to $\mathcal{O}(m)$, where $N$ is pixel size and $m$ is number of fibre modes. Finally, this model generalises to new images, outside of the set of training data classes, better than previous models.