 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SALC: Skeleton-Assisted Learning-Based Clustering for Time-Varying Indoor Localization
Jul 14, 2023
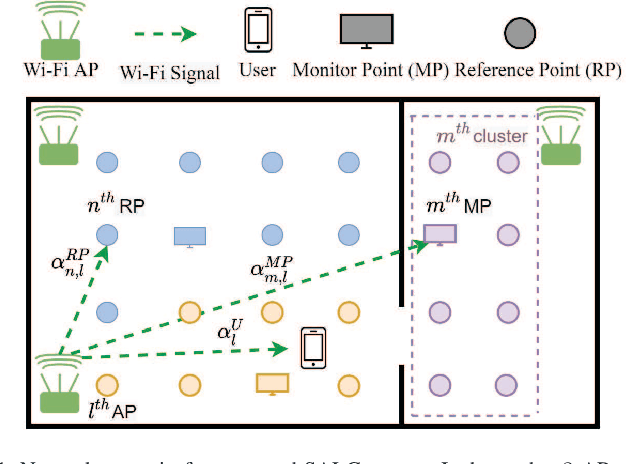
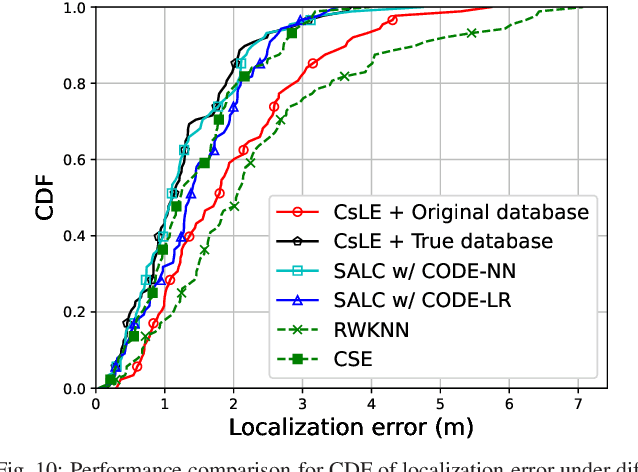

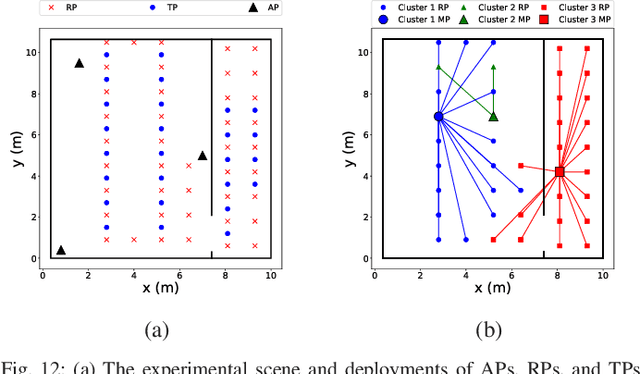
Wireless indoor localization has attracted significant amount of attention in recent years. Using received signal strength (RSS) obtained from WiFi access points (APs) for establishing fingerprinting database is a widely utilized method in indoor localization. However, the time-variant problem for indoor positioning systems is not well-investigated in existing literature. Compared to conventional static fingerprinting, the dynamicallyreconstructed database can adapt to a highly-changing environment, which achieves sustainability of localization accuracy. To deal with the time-varying issue, we propose a skeleton-assisted learning-based clustering localization (SALC) system, including RSS-oriented map-assisted clustering (ROMAC), cluster-based online database establishment (CODE), and cluster-scaled location estimation (CsLE). The SALC scheme jointly considers similarities from the skeleton-based shortest path (SSP) and the time-varying RSS measurements across the reference points (RPs). ROMAC clusters RPs into different feature sets and therefore selects suitable monitor points (MPs) for enhancing location estimation. Moreover, the CODE algorithm aims for establishing adaptive fingerprint database to alleviate the timevarying problem. Finally, CsLE is adopted to acquire the target position by leveraging the benefits of clustering information and estimated signal variations in order to rescale the weights fromweighted k-nearest neighbors (WkNN) method. Both simulation and experimental results demonstrate that the proposed SALC system can effectively reconstruct the fingerprint database with an enhanced location estimation accuracy, which outperforms the other existing schemes in the open literature.
A Topical Approach to Capturing Customer Insight In Social Media
Jul 14, 2023
The age of social media has opened new opportunities for businesses. This flourishing wealth of information is outside traditional channels and frameworks of classical marketing research, including that of Marketing Mix Modeling (MMM). Textual data, in particular, poses many challenges that data analysis practitioners must tackle. Social media constitute massive, heterogeneous, and noisy document sources. Industrial data acquisition processes include some amount of ETL. However, the variability of noise in the data and the heterogeneity induced by different sources create the need for ad-hoc tools. Put otherwise, customer insight extraction in fully unsupervised, noisy contexts is an arduous task. This research addresses the challenge of fully unsupervised topic extraction in noisy, Big Data contexts. We present three approaches we built on the Variational Autoencoder framework: the Embedded Dirichlet Process, the Embedded Hierarchical Dirichlet Process, and the time-aware Dynamic Embedded Dirichlet Process. These nonparametric approaches concerning topics present the particularity of determining word embeddings and topic embeddings. These embeddings do not require transfer learning, but knowledge transfer remains possible. We test these approaches on benchmark and automotive industry-related datasets from a real-world use case. We show that our models achieve equal to better performance than state-of-the-art methods and that the field of topic modeling would benefit from improved evaluation metrics.
VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View
Jul 12, 2023
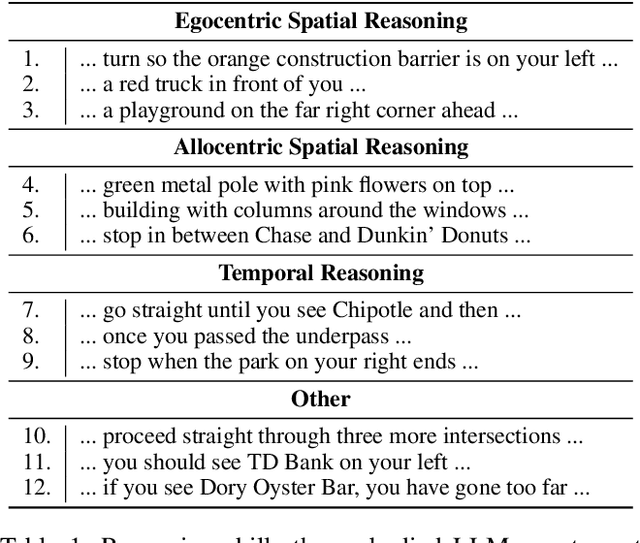
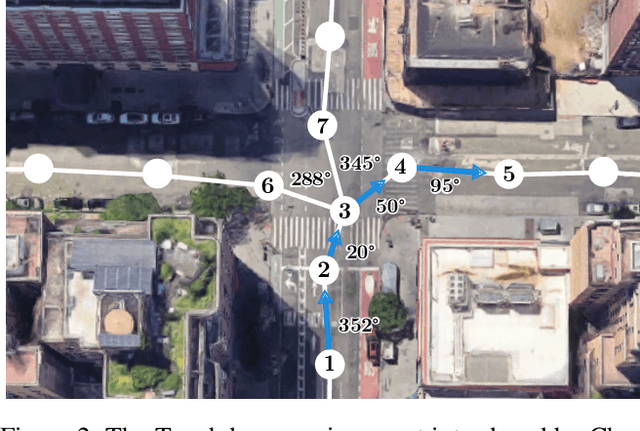
Incremental decision making in real-world environments is one of the most challenging tasks in embodied artificial intelligence. One particularly demanding scenario is Vision and Language Navigation~(VLN) which requires visual and natural language understanding as well as spatial and temporal reasoning capabilities. The embodied agent needs to ground its understanding of navigation instructions in observations of a real-world environment like Street View. Despite the impressive results of LLMs in other research areas, it is an ongoing problem of how to best connect them with an interactive visual environment. In this work, we propose VELMA, an embodied LLM agent that uses a verbalization of the trajectory and of visual environment observations as contextual prompt for the next action. Visual information is verbalized by a pipeline that extracts landmarks from the human written navigation instructions and uses CLIP to determine their visibility in the current panorama view. We show that VELMA is able to successfully follow navigation instructions in Street View with only two in-context examples. We further finetune the LLM agent on a few thousand examples and achieve 25%-30% relative improvement in task completion over the previous state-of-the-art for two datasets.
Self-Adaptive Large Language Model (LLM)-Based Multiagent Systems
Jul 12, 2023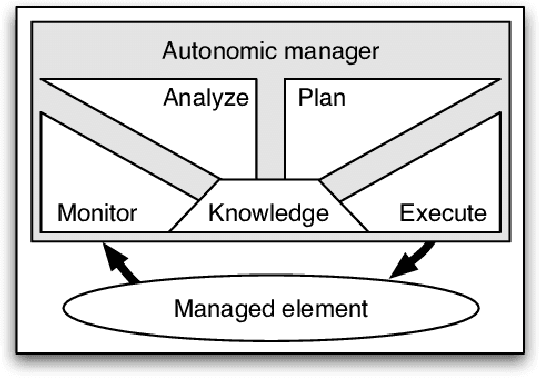
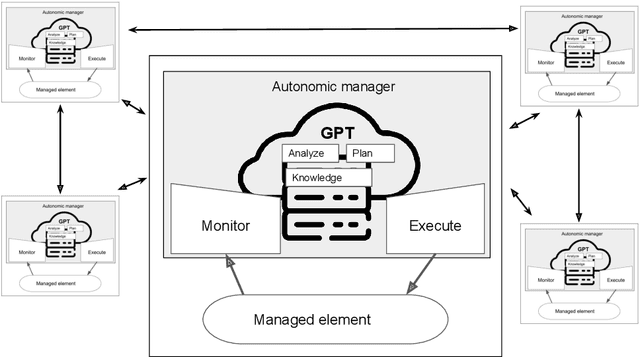
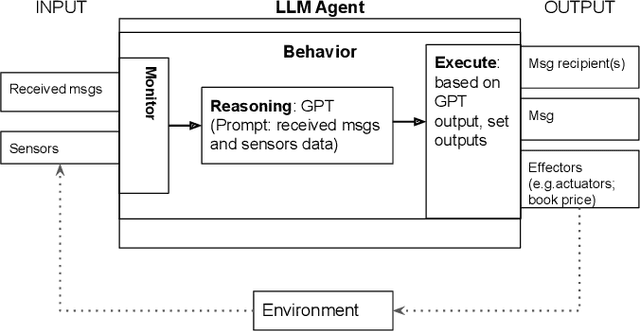
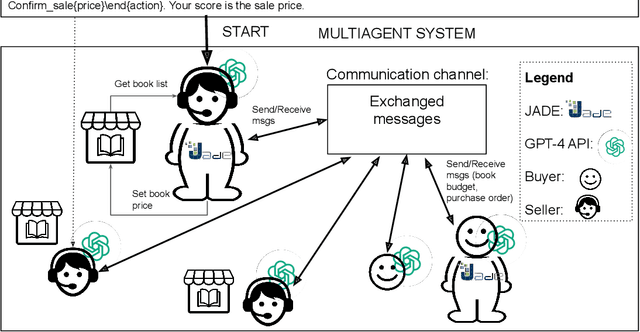
In autonomic computing, self-adaptation has been proposed as a fundamental paradigm to manage the complexity of multiagent systems (MASs). This achieved by extending a system with support to monitor and adapt itself to achieve specific concerns of interest. Communication in these systems is key given that in scenarios involving agent interaction, it enhances cooperation and reduces coordination challenges by enabling direct, clear information exchange. However, improving the expressiveness of the interaction communication with MASs is not without challenges. In this sense, the interplay between self-adaptive systems and effective communication is crucial for future MAS advancements. In this paper, we propose the integration of large language models (LLMs) such as GPT-based technologies into multiagent systems. We anchor our methodology on the MAPE-K model, which is renowned for its robust support in monitoring, analyzing, planning, and executing system adaptations in response to dynamic environments. We also present a practical illustration of the proposed approach, in which we implement and assess a basic MAS-based application. The approach significantly advances the state-of-the-art of self-adaptive systems by proposing a new paradigm for MAS self-adaptation of autonomous systems based on LLM capabilities.
Locally Adaptive Federated Learning via Stochastic Polyak Stepsizes
Jul 12, 2023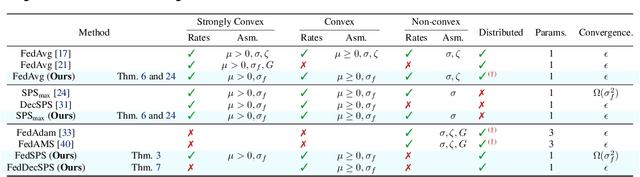
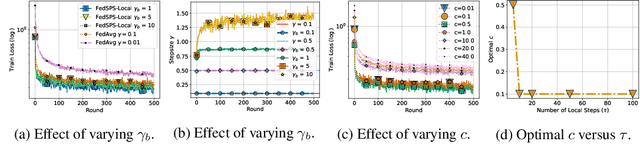
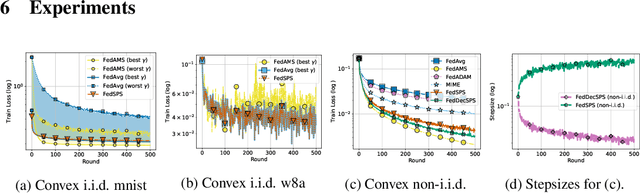

State-of-the-art federated learning algorithms such as FedAvg require carefully tuned stepsizes to achieve their best performance. The improvements proposed by existing adaptive federated methods involve tuning of additional hyperparameters such as momentum parameters, and consider adaptivity only in the server aggregation round, but not locally. These methods can be inefficient in many practical scenarios because they require excessive tuning of hyperparameters and do not capture local geometric information. In this work, we extend the recently proposed stochastic Polyak stepsize (SPS) to the federated learning setting, and propose new locally adaptive and nearly parameter-free distributed SPS variants (FedSPS and FedDecSPS). We prove that FedSPS converges linearly in strongly convex and sublinearly in convex settings when the interpolation condition (overparametrization) is satisfied, and converges to a neighborhood of the solution in the general case. We extend our proposed method to a decreasing stepsize version FedDecSPS, that converges also when the interpolation condition does not hold. We validate our theoretical claims by performing illustrative convex experiments. Our proposed algorithms match the optimization performance of FedAvg with the best tuned hyperparameters in the i.i.d. case, and outperform FedAvg in the non-i.i.d. case.
Diversity-enhancing Generative Network for Few-shot Hypothesis Adaptation
Jul 12, 2023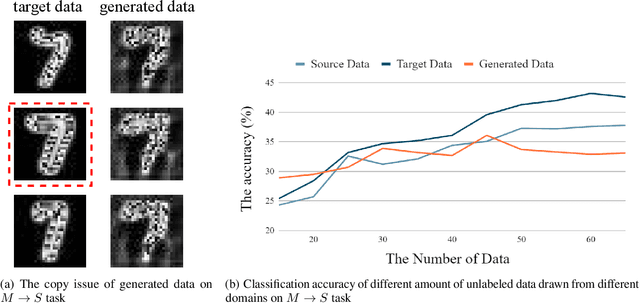
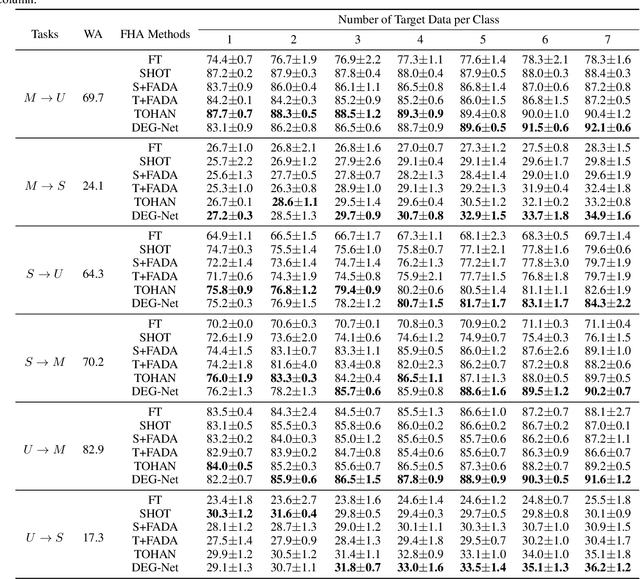
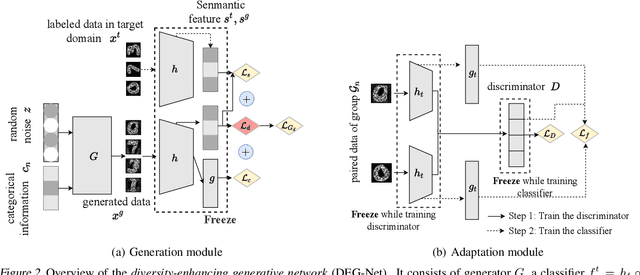

Generating unlabeled data has been recently shown to help address the few-shot hypothesis adaptation (FHA) problem, where we aim to train a classifier for the target domain with a few labeled target-domain data and a well-trained source-domain classifier (i.e., a source hypothesis), for the additional information of the highly-compatible unlabeled data. However, the generated data of the existing methods are extremely similar or even the same. The strong dependency among the generated data will lead the learning to fail. In this paper, we propose a diversity-enhancing generative network (DEG-Net) for the FHA problem, which can generate diverse unlabeled data with the help of a kernel independence measure: the Hilbert-Schmidt independence criterion (HSIC). Specifically, DEG-Net will generate data via minimizing the HSIC value (i.e., maximizing the independence) among the semantic features of the generated data. By DEG-Net, the generated unlabeled data are more diverse and more effective for addressing the FHA problem. Experimental results show that the DEG-Net outperforms existing FHA baselines and further verifies that generating diverse data plays a vital role in addressing the FHA problem
Test-Time Training on Video Streams
Jul 12, 2023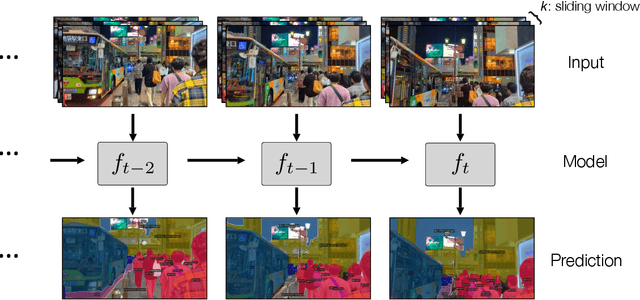
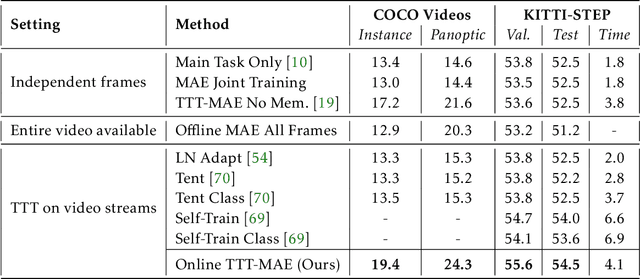
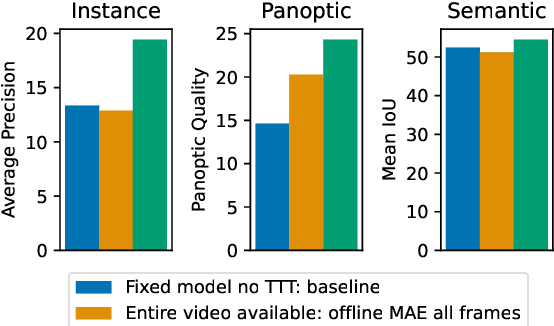
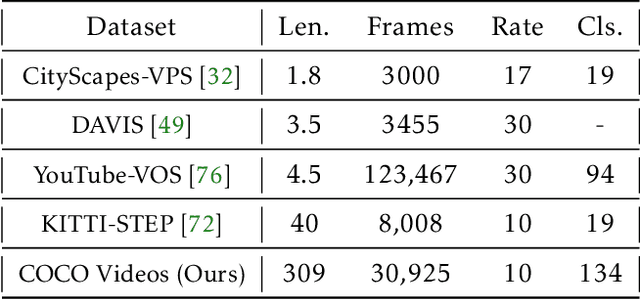
Prior work has established test-time training (TTT) as a general framework to further improve a trained model at test time. Before making a prediction on each test instance, the model is trained on the same instance using a self-supervised task, such as image reconstruction with masked autoencoders. We extend TTT to the streaming setting, where multiple test instances - video frames in our case - arrive in temporal order. Our extension is online TTT: The current model is initialized from the previous model, then trained on the current frame and a small window of frames immediately before. Online TTT significantly outperforms the fixed-model baseline for four tasks, on three real-world datasets. The relative improvement is 45% and 66% for instance and panoptic segmentation. Surprisingly, online TTT also outperforms its offline variant that accesses more information, training on all frames from the entire test video regardless of temporal order. This differs from previous findings using synthetic videos. We conceptualize locality as the advantage of online over offline TTT. We analyze the role of locality with ablations and a theory based on bias-variance trade-off.
Synthesizing Artistic Cinemagraphs from Text
Jul 12, 2023
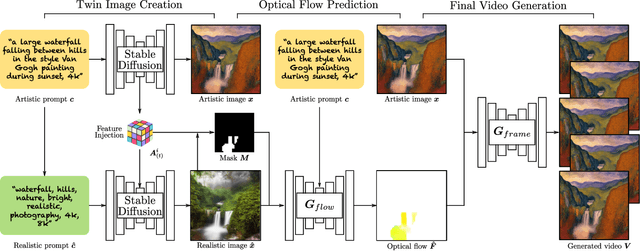


We introduce Text2Cinemagraph, a fully automated method for creating cinemagraphs from text descriptions - an especially challenging task when prompts feature imaginary elements and artistic styles, given the complexity of interpreting the semantics and motions of these images. Existing single-image animation methods fall short on artistic inputs, and recent text-based video methods frequently introduce temporal inconsistencies, struggling to keep certain regions static. To address these challenges, we propose an idea of synthesizing image twins from a single text prompt - a pair of an artistic image and its pixel-aligned corresponding natural-looking twin. While the artistic image depicts the style and appearance detailed in our text prompt, the realistic counterpart greatly simplifies layout and motion analysis. Leveraging existing natural image and video datasets, we can accurately segment the realistic image and predict plausible motion given the semantic information. The predicted motion can then be transferred to the artistic image to create the final cinemagraph. Our method outperforms existing approaches in creating cinemagraphs for natural landscapes as well as artistic and other-worldly scenes, as validated by automated metrics and user studies. Finally, we demonstrate two extensions: animating existing paintings and controlling motion directions using text.
Weakly-supervised positional contrastive learning: application to cirrhosis classification
Jul 12, 2023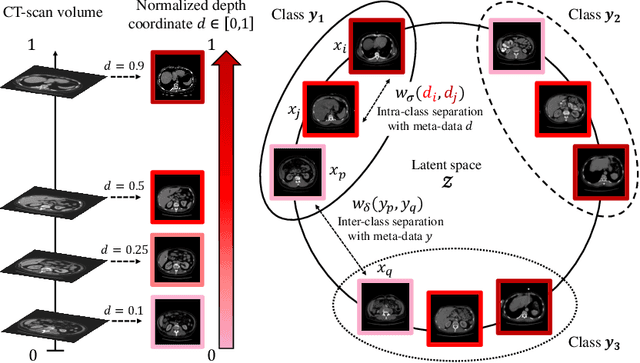
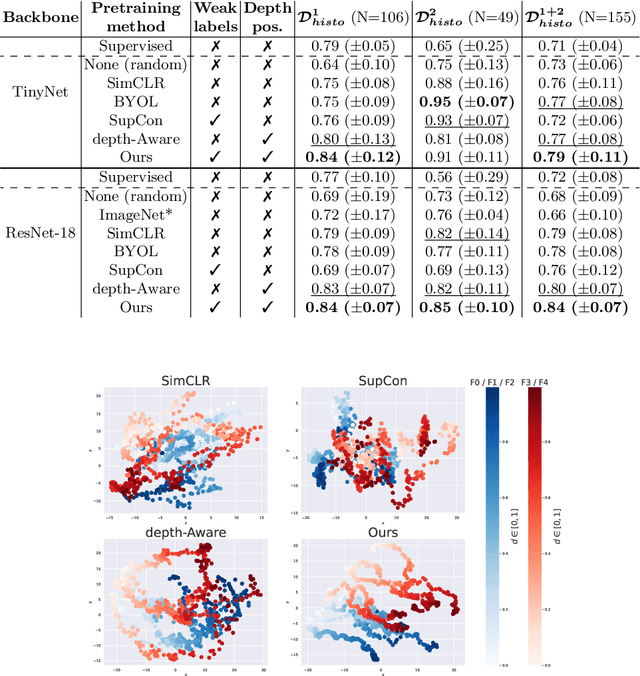
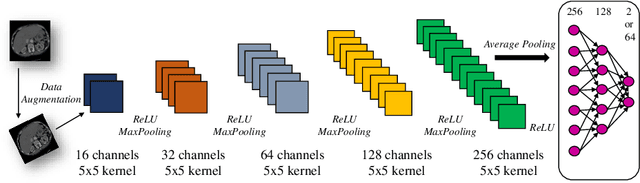
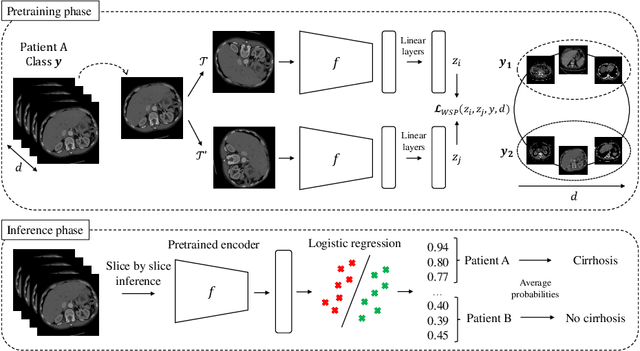
Large medical imaging datasets can be cheaply and quickly annotated with low-confidence, weak labels (e.g., radiological scores). Access to high-confidence labels, such as histology-based diagnoses, is rare and costly. Pretraining strategies, like contrastive learning (CL) methods, can leverage unlabeled or weakly-annotated datasets. These methods typically require large batch sizes, which poses a difficulty in the case of large 3D images at full resolution, due to limited GPU memory. Nevertheless, volumetric positional information about the spatial context of each 2D slice can be very important for some medical applications. In this work, we propose an efficient weakly-supervised positional (WSP) contrastive learning strategy where we integrate both the spatial context of each 2D slice and a weak label via a generic kernel-based loss function. We illustrate our method on cirrhosis prediction using a large volume of weakly-labeled images, namely radiological low-confidence annotations, and small strongly-labeled (i.e., high-confidence) datasets. The proposed model improves the classification AUC by 5% with respect to a baseline model on our internal dataset, and by 26% on the public LIHC dataset from the Cancer Genome Atlas. The code is available at: https://github.com/Guerbet-AI/wsp-contrastive.
Bag of Views: An Appearance-based Approach to Next-Best-View Planning for 3D Reconstruction
Jul 13, 2023UAV-based intelligent data acquisition for 3D reconstruction and monitoring of infrastructure has been experiencing an increasing surge of interest due to the recent advancements in image processing and deep learning-based techniques. View planning is an essential part of this task that dictates the information capture strategy and heavily impacts the quality of the 3D model generated from the captured data. Recent methods have used prior knowledge or partial reconstruction of the target to accomplish view planning for active reconstruction; the former approach poses a challenge for complex or newly identified targets while the latter is computationally expensive. In this work, we present Bag-of-Views (BoV), a fully appearance-based model used to assign utility to the captured views for both offline dataset refinement and online next-best-view (NBV) planning applications targeting the task of 3D reconstruction. With this contribution, we also developed the View Planning Toolbox (VPT), a lightweight package for training and testing machine learning-based view planning frameworks, custom view dataset generation of arbitrary 3D scenes, and 3D reconstruction. Through experiments which pair a BoV-based reinforcement learning model with VPT, we demonstrate the efficacy of our model in reducing the number of required views for high-quality reconstructions in dataset refinement and NBV planning.