 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Membership Inference Attacks on DNNs using Adversarial Perturbations
Jul 11, 2023
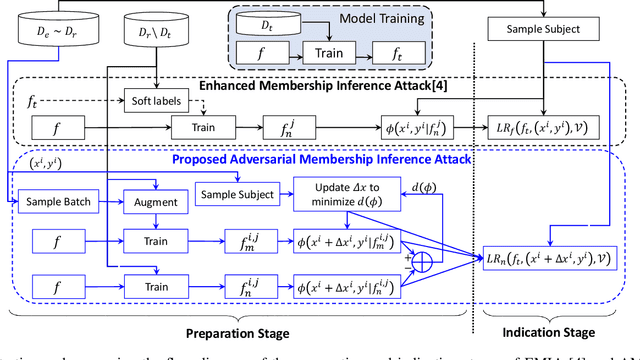
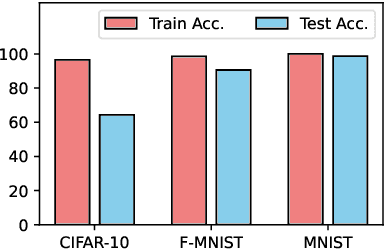
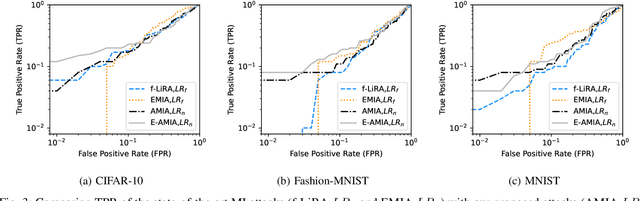
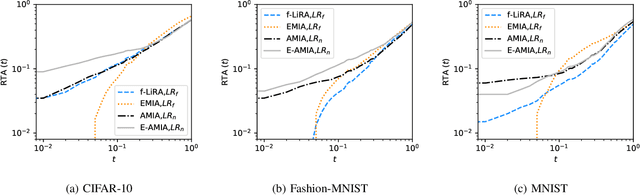
Several membership inference (MI) attacks have been proposed to audit a target DNN. Given a set of subjects, MI attacks tell which subjects the target DNN has seen during training. This work focuses on the post-training MI attacks emphasizing high confidence membership detection -- True Positive Rates (TPR) at low False Positive Rates (FPR). Current works in this category -- likelihood ratio attack (LiRA) and enhanced MI attack (EMIA) -- only perform well on complex datasets (e.g., CIFAR-10 and Imagenet) where the target DNN overfits its train set, but perform poorly on simpler datasets (0% TPR by both attacks on Fashion-MNIST, 2% and 0% TPR respectively by LiRA and EMIA on MNIST at 1% FPR). To address this, firstly, we unify current MI attacks by presenting a framework divided into three stages -- preparation, indication and decision. Secondly, we utilize the framework to propose two novel attacks: (1) Adversarial Membership Inference Attack (AMIA) efficiently utilizes the membership and the non-membership information of the subjects while adversarially minimizing a novel loss function, achieving 6% TPR on both Fashion-MNIST and MNIST datasets; and (2) Enhanced AMIA (E-AMIA) combines EMIA and AMIA to achieve 8% and 4% TPRs on Fashion-MNIST and MNIST datasets respectively, at 1% FPR. Thirdly, we introduce two novel augmented indicators that positively leverage the loss information in the Gaussian neighborhood of a subject. This improves TPR of all four attacks on average by 2.5% and 0.25% respectively on Fashion-MNIST and MNIST datasets at 1% FPR. Finally, we propose simple, yet novel, evaluation metric, the running TPR average (RTA) at a given FPR, that better distinguishes different MI attacks in the low FPR region. We also show that AMIA and E-AMIA are more transferable to the unknown DNNs (other than the target DNN) and are more robust to DP-SGD training as compared to LiRA and EMIA.
X-MLP: A Patch Embedding-Free MLP Architecture for Vision
Jul 02, 2023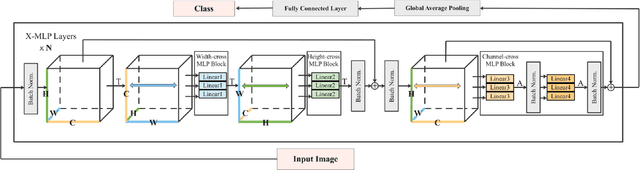
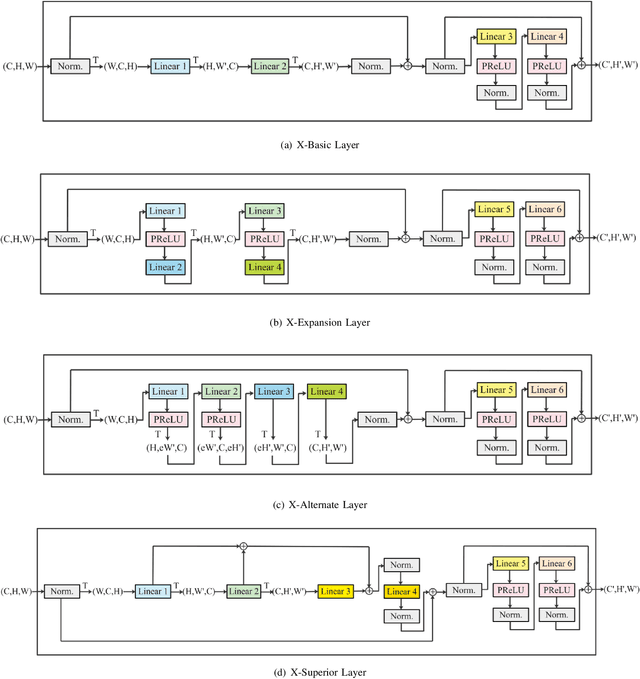
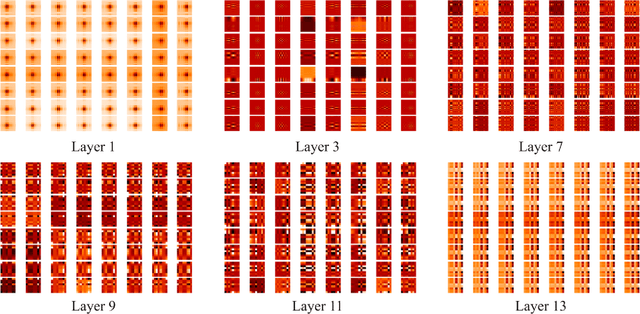
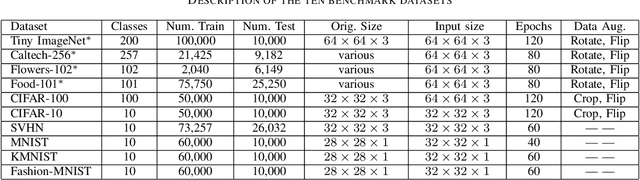
Convolutional neural networks (CNNs) and vision transformers (ViT) have obtained great achievements in computer vision. Recently, the research of multi-layer perceptron (MLP) architectures for vision have been popular again. Vision MLPs are designed to be independent from convolutions and self-attention operations. However, existing vision MLP architectures always depend on convolution for patch embedding. Thus we propose X-MLP, an architecture constructed absolutely upon fully connected layers and free from patch embedding. It decouples the features extremely and utilizes MLPs to interact the information across the dimension of width, height and channel independently and alternately. X-MLP is tested on ten benchmark datasets, all obtaining better performance than other vision MLP models. It even surpasses CNNs by a clear margin on various dataset. Furthermore, through mathematically restoring the spatial weights, we visualize the information communication between any couples of pixels in the feature map and observe the phenomenon of capturing long-range dependency.
DRAGON: A Dialogue-Based Robot for Assistive Navigation with Visual Language Grounding
Jul 13, 2023
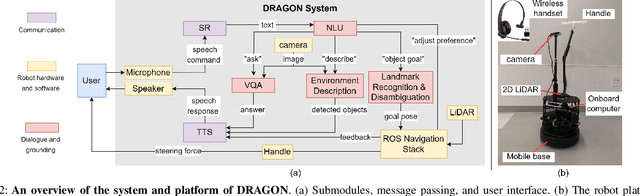
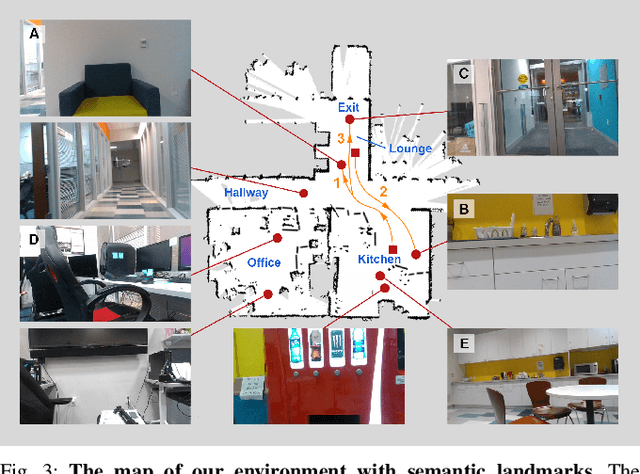

Persons with visual impairments (PwVI) have difficulties understanding and navigating spaces around them. Current wayfinding technologies either focus solely on navigation or provide limited communication about the environment. Motivated by recent advances in visual-language grounding and semantic navigation, we propose DRAGON, a guiding robot powered by a dialogue system and the ability to associate the environment with natural language. By understanding the commands from the user, DRAGON is able to guide the user to the desired landmarks on the map, describe the environment, and answer questions from visual observations. Through effective utilization of dialogue, the robot can ground the user's free-form descriptions to landmarks in the environment, and give the user semantic information through spoken language. We conduct a user study with blindfolded participants in an everyday indoor environment. Our results demonstrate that DRAGON is able to communicate with the user smoothly, provide a good guiding experience, and connect users with their surrounding environment in an intuitive manner.
Discovering How Agents Learn Using Few Data
Jul 13, 2023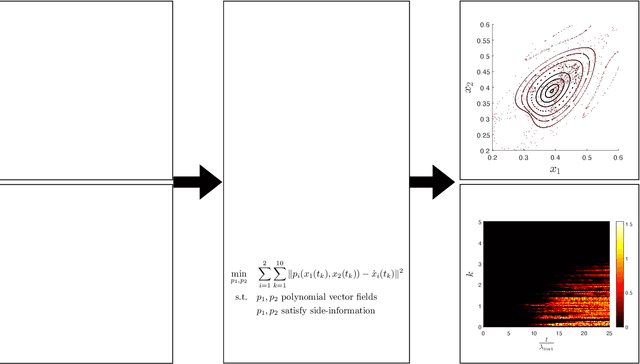

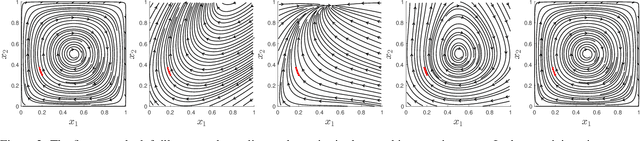

Decentralized learning algorithms are an essential tool for designing multi-agent systems, as they enable agents to autonomously learn from their experience and past interactions. In this work, we propose a theoretical and algorithmic framework for real-time identification of the learning dynamics that govern agent behavior using a short burst of a single system trajectory. Our method identifies agent dynamics through polynomial regression, where we compensate for limited data by incorporating side-information constraints that capture fundamental assumptions or expectations about agent behavior. These constraints are enforced computationally using sum-of-squares optimization, leading to a hierarchy of increasingly better approximations of the true agent dynamics. Extensive experiments demonstrated that our approach, using only 5 samples from a short run of a single trajectory, accurately recovers the true dynamics across various benchmarks, including equilibrium selection and prediction of chaotic systems up to 10 Lyapunov times. These findings suggest that our approach has significant potential to support effective policy and decision-making in strategic multi-agent systems.
On the ability of CNNs to extract color invariant intensity based features for image classification
Jul 13, 2023

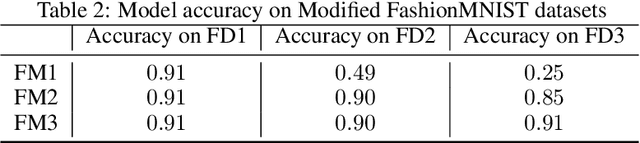
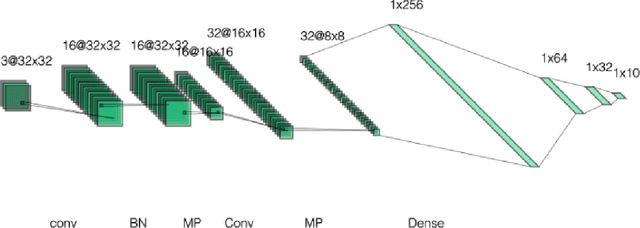
Convolutional neural networks (CNNs) have demonstrated remarkable success in vision-related tasks. However, their susceptibility to failing when inputs deviate from the training distribution is well-documented. Recent studies suggest that CNNs exhibit a bias toward texture instead of object shape in image classification tasks, and that background information may affect predictions. This paper investigates the ability of CNNs to adapt to different color distributions in an image while maintaining context and background. The results of our experiments on modified MNIST and FashionMNIST data demonstrate that changes in color can substantially affect classification accuracy. The paper explores the effects of various regularization techniques on generalization error across datasets and proposes a minor architectural modification utilizing the dropout regularization in a novel way that enhances model reliance on color-invariant intensity-based features for improved classification accuracy. Overall, this work contributes to ongoing efforts to understand the limitations and challenges of CNNs in image classification tasks and offers potential solutions to enhance their performance.
Nested Elimination: A Simple Algorithm for Best-Item Identification from Choice-Based Feedback
Jul 13, 2023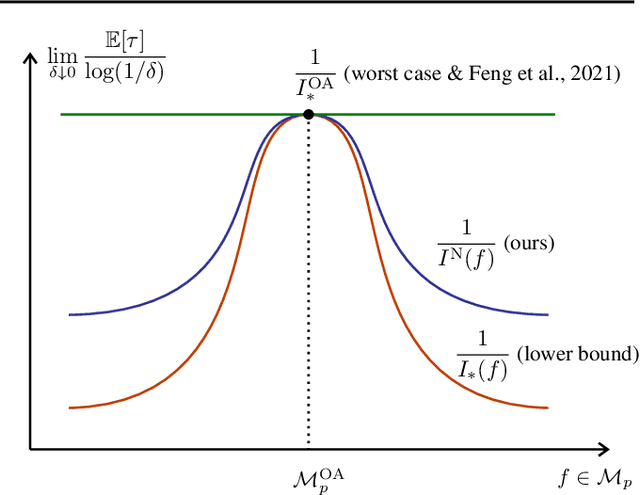
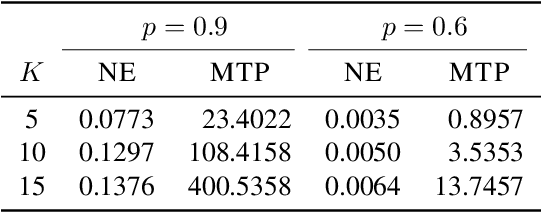
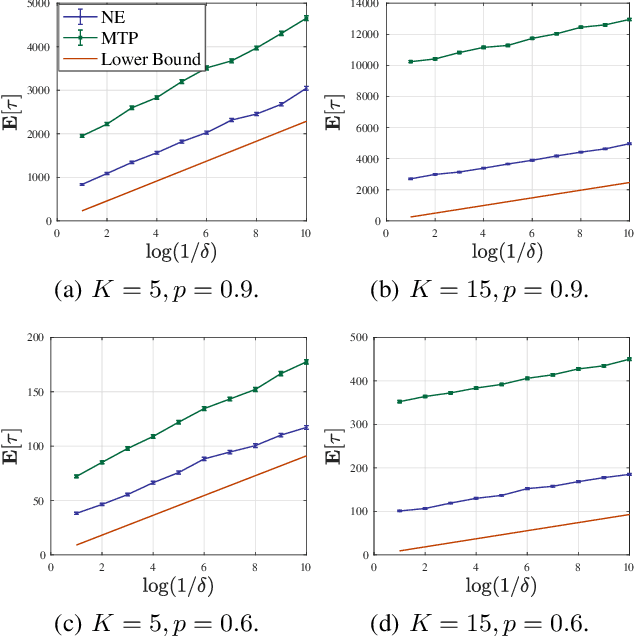
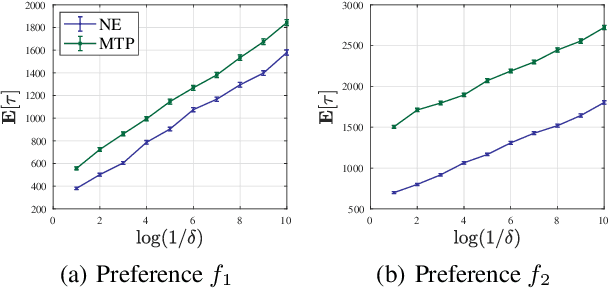
We study the problem of best-item identification from choice-based feedback. In this problem, a company sequentially and adaptively shows display sets to a population of customers and collects their choices. The objective is to identify the most preferred item with the least number of samples and at a high confidence level. We propose an elimination-based algorithm, namely Nested Elimination (NE), which is inspired by the nested structure implied by the information-theoretic lower bound. NE is simple in structure, easy to implement, and has a strong theoretical guarantee for sample complexity. Specifically, NE utilizes an innovative elimination criterion and circumvents the need to solve any complex combinatorial optimization problem. We provide an instance-specific and non-asymptotic bound on the expected sample complexity of NE. We also show NE achieves high-order worst-case asymptotic optimality. Finally, numerical experiments from both synthetic and real data corroborate our theoretical findings.
Joint Perceptual Learning for Enhancement and Object Detection in Underwater Scenarios
Jul 07, 2023
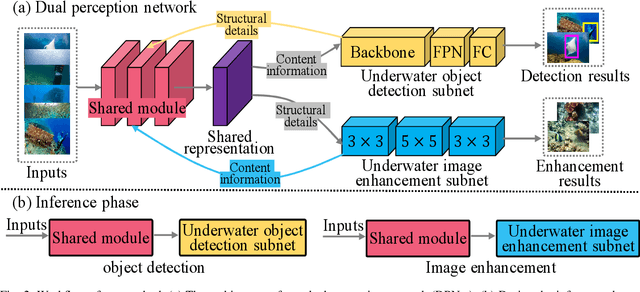
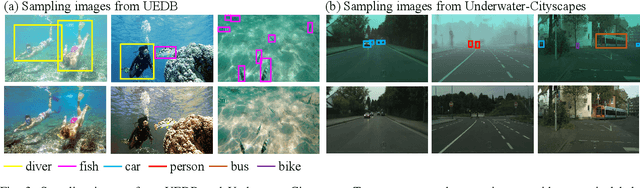

Underwater degraded images greatly challenge existing algorithms to detect objects of interest. Recently, researchers attempt to adopt attention mechanisms or composite connections for improving the feature representation of detectors. However, this solution does \textit{not} eliminate the impact of degradation on image content such as color and texture, achieving minimal improvements. Another feasible solution for underwater object detection is to develop sophisticated deep architectures in order to enhance image quality or features. Nevertheless, the visually appealing output of these enhancement modules do \textit{not} necessarily generate high accuracy for deep detectors. More recently, some multi-task learning methods jointly learn underwater detection and image enhancement, accessing promising improvements. Typically, these methods invoke huge architecture and expensive computations, rendering inefficient inference. Definitely, underwater object detection and image enhancement are two interrelated tasks. Leveraging information coming from the two tasks can benefit each task. Based on these factual opinions, we propose a bilevel optimization formulation for jointly learning underwater object detection and image enhancement, and then unroll to a dual perception network (DPNet) for the two tasks. DPNet with one shared module and two task subnets learns from the two different tasks, seeking a shared representation. The shared representation provides more structural details for image enhancement and rich content information for object detection. Finally, we derive a cooperative training strategy to optimize parameters for DPNet. Extensive experiments on real-world and synthetic underwater datasets demonstrate that our method outputs visually favoring images and higher detection accuracy.
Beyond the Obvious: Evaluating the Reasoning Ability In Real-life Scenarios of Language Models on Life Scapes Reasoning Benchmark~(LSR-Benchmark)
Jul 11, 2023
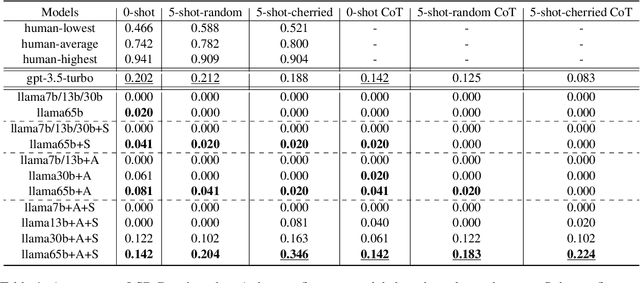


This paper introduces the Life Scapes Reasoning Benchmark (LSR-Benchmark), a novel dataset targeting real-life scenario reasoning, aiming to close the gap in artificial neural networks' ability to reason in everyday contexts. In contrast to domain knowledge reasoning datasets, LSR-Benchmark comprises free-text formatted questions with rich information on real-life scenarios, human behaviors, and character roles. The dataset consists of 2,162 questions collected from open-source online sources and is manually annotated to improve its quality. Experiments are conducted using state-of-the-art language models, such as gpt3.5-turbo and instruction fine-tuned llama models, to test the performance in LSR-Benchmark. The results reveal that humans outperform these models significantly, indicating a persisting challenge for machine learning models in comprehending daily human life.
Modeling Entities as Semantic Points for Visual Information Extraction in the Wild
Mar 23, 2023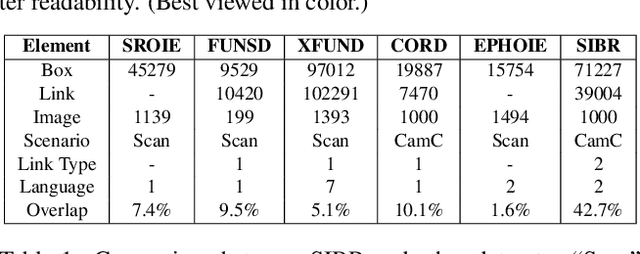
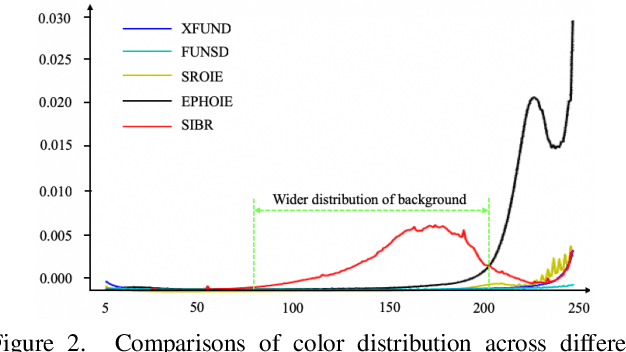
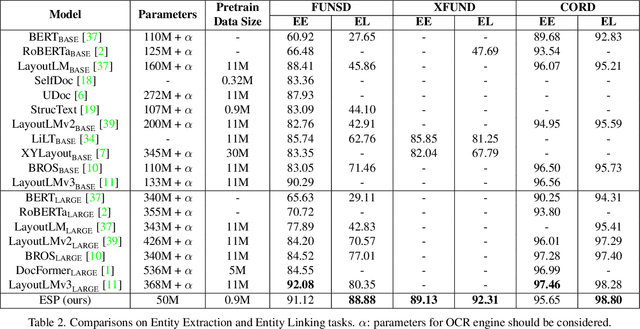
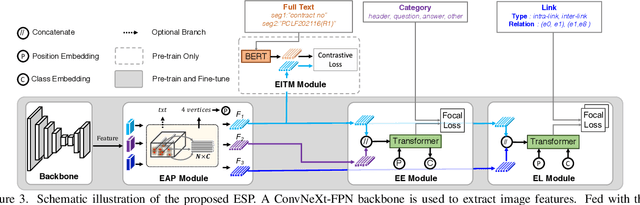
Recently, Visual Information Extraction (VIE) has been becoming increasingly important in both the academia and industry, due to the wide range of real-world applications. Previously, numerous works have been proposed to tackle this problem. However, the benchmarks used to assess these methods are relatively plain, i.e., scenarios with real-world complexity are not fully represented in these benchmarks. As the first contribution of this work, we curate and release a new dataset for VIE, in which the document images are much more challenging in that they are taken from real applications, and difficulties such as blur, partial occlusion, and printing shift are quite common. All these factors may lead to failures in information extraction. Therefore, as the second contribution, we explore an alternative approach to precisely and robustly extract key information from document images under such tough conditions. Specifically, in contrast to previous methods, which usually either incorporate visual information into a multi-modal architecture or train text spotting and information extraction in an end-to-end fashion, we explicitly model entities as semantic points, i.e., center points of entities are enriched with semantic information describing the attributes and relationships of different entities, which could largely benefit entity labeling and linking. Extensive experiments on standard benchmarks in this field as well as the proposed dataset demonstrate that the proposed method can achieve significantly enhanced performance on entity labeling and linking, compared with previous state-of-the-art models. Dataset is available at https://www.modelscope.cn/datasets/damo/SIBR/summary.
Enhancing Mapless Trajectory Prediction through Knowledge Distillation
Jun 25, 2023
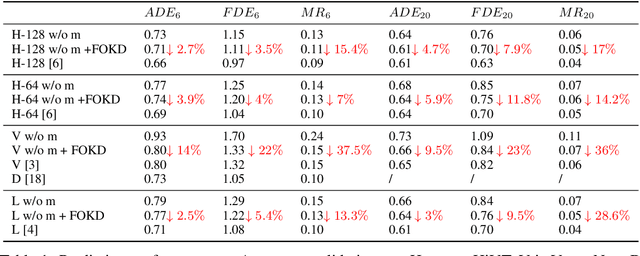
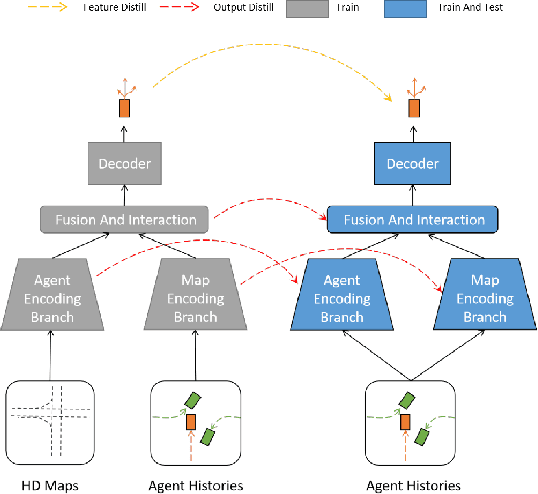
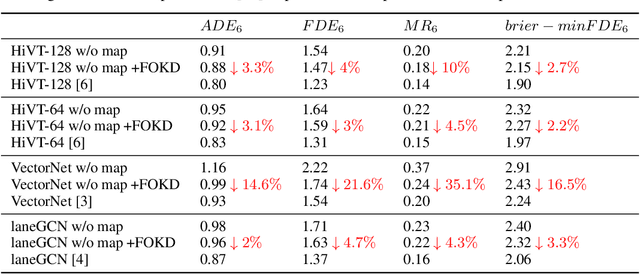
Scene information plays a crucial role in trajectory forecasting systems for autonomous driving by providing semantic clues and constraints on potential future paths of traffic agents. Prevalent trajectory prediction techniques often take high-definition maps (HD maps) as part of the inputs to provide scene knowledge. Although HD maps offer accurate road information, they may suffer from the high cost of annotation or restrictions of law that limits their widespread use. Therefore, those methods are still expected to generate reliable prediction results in mapless scenarios. In this paper, we tackle the problem of improving the consistency of multi-modal prediction trajectories and the real road topology when map information is unavailable during the test phase. Specifically, we achieve this by training a map-based prediction teacher network on the annotated samples and transferring the knowledge to a student mapless prediction network using a two-fold knowledge distillation framework. Our solution is generalizable for common trajectory prediction networks and does not bring extra computation burden. Experimental results show that our method stably improves prediction performance in mapless mode on many widely used state-of-the-art trajectory prediction baselines, compensating for the gaps caused by the absence of HD maps. Qualitative visualization results demonstrate that our approach helps infer unseen map information.