 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Anomaly Detection in Industrial Machinery using IoT Devices and Machine Learning: a Systematic Mapping
Jul 28, 2023
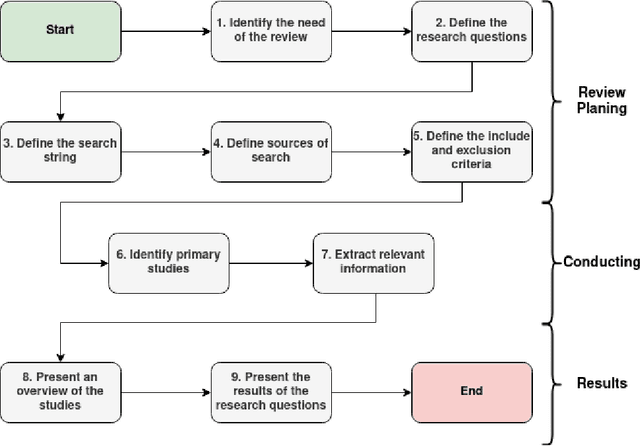

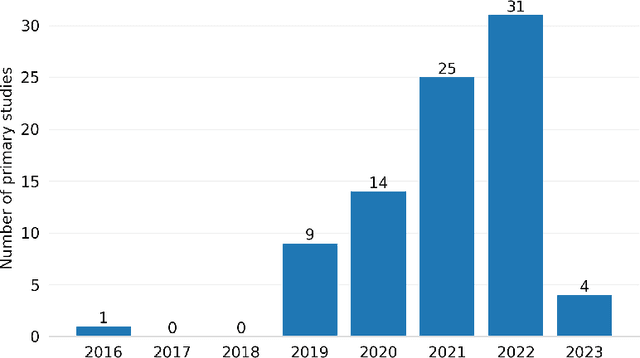

Anomaly detection is critical in the smart industry for preventing equipment failure, reducing downtime, and improving safety. Internet of Things (IoT) has enabled the collection of large volumes of data from industrial machinery, providing a rich source of information for Anomaly Detection. However, the volume and complexity of data generated by the Internet of Things ecosystems make it difficult for humans to detect anomalies manually. Machine learning (ML) algorithms can automate anomaly detection in industrial machinery by analyzing generated data. Besides, each technique has specific strengths and weaknesses based on the data nature and its corresponding systems. However, the current systematic mapping studies on Anomaly Detection primarily focus on addressing network and cybersecurity-related problems, with limited attention given to the industrial sector. Additionally, these studies do not cover the challenges involved in using ML for Anomaly Detection in industrial machinery within the context of the IoT ecosystems. This paper presents a systematic mapping study on Anomaly Detection for industrial machinery using IoT devices and ML algorithms to address this gap. The study comprehensively evaluates 84 relevant studies spanning from 2016 to 2023, providing an extensive review of Anomaly Detection research. Our findings identify the most commonly used algorithms, preprocessing techniques, and sensor types. Additionally, this review identifies application areas and points to future challenges and research opportunities.
Lost in the Middle: How Language Models Use Long Contexts
Jul 06, 2023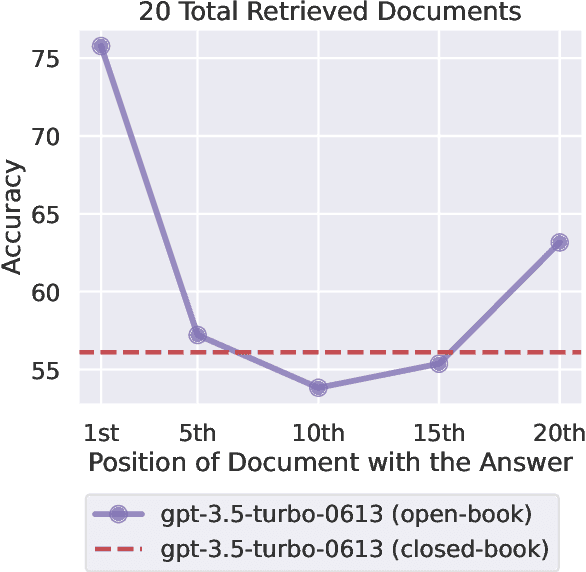
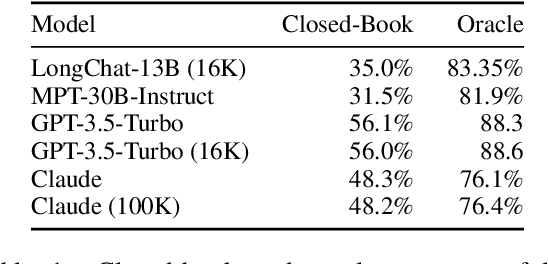


While recent language models have the ability to take long contexts as input, relatively little is known about how well the language models use longer context. We analyze language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.
Variantional autoencoder with decremental information bottleneck for disentanglement
Mar 22, 2023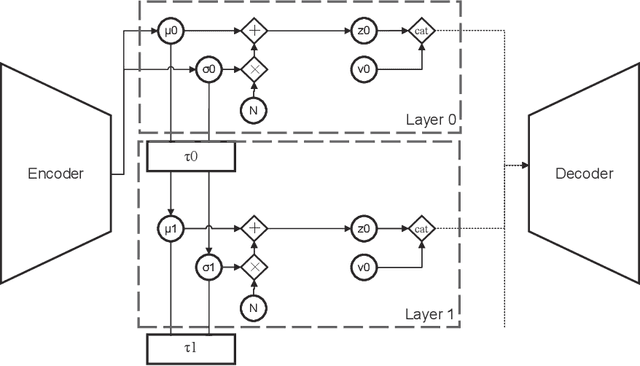
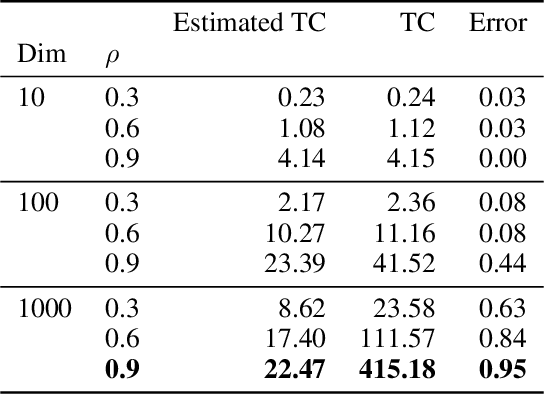
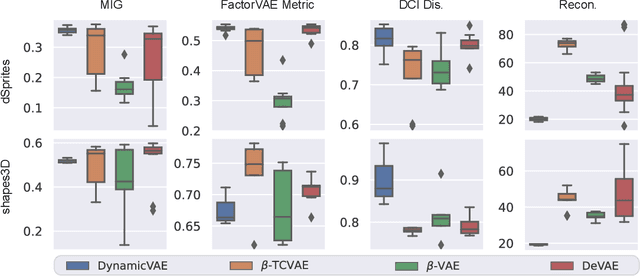
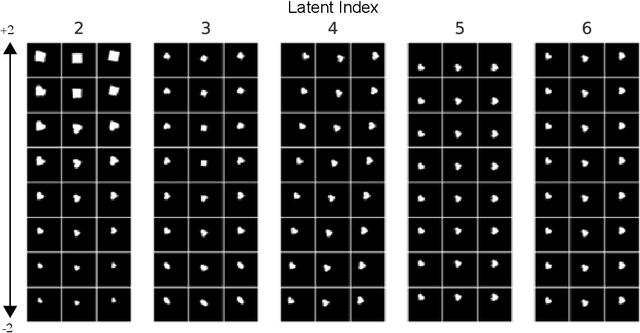
One major challenge of disentanglement learning with variational autoencoders is the trade-off between disentanglement and reconstruction fidelity. Previous incremental methods with only on latent space cannot optimize these two targets simultaneously, so they expand the Information Bottleneck while training to {optimize from disentanglement to reconstruction. However, a large bottleneck will lose the constraint of disentanglement, causing the information diffusion problem. To tackle this issue, we present a novel decremental variational autoencoder with disentanglement-invariant transformations to optimize multiple objectives in different layers, termed DeVAE, for balancing disentanglement and reconstruction fidelity by decreasing the information bottleneck of diverse latent spaces gradually. Benefiting from the multiple latent spaces, DeVAE allows simultaneous optimization of multiple objectives to optimize reconstruction while keeping the constraint of disentanglement, avoiding information diffusion. DeVAE is also compatible with large models with high-dimension latent space. Experimental results on dSprites and Shapes3D that DeVAE achieves \fix{R2q6}{a good balance between disentanglement and reconstruction.DeVAE shows high tolerant of hyperparameters and on high-dimensional latent spaces.
Quantifying the perceptual value of lexical and non-lexical channels in speech
Jul 07, 2023
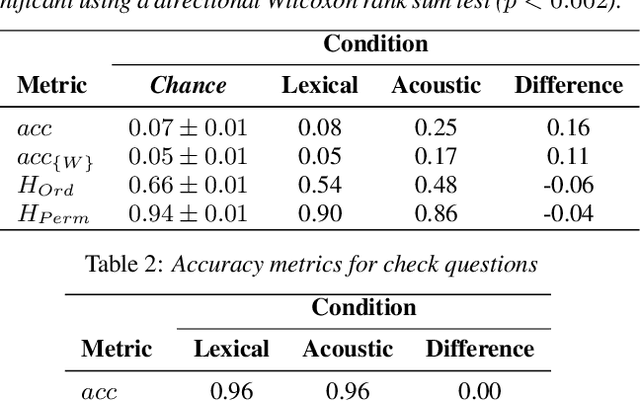
Speech is a fundamental means of communication that can be seen to provide two channels for transmitting information: the lexical channel of which words are said, and the non-lexical channel of how they are spoken. Both channels shape listener expectations of upcoming communication; however, directly quantifying their relative effect on expectations is challenging. Previous attempts require spoken variations of lexically-equivalent dialogue turns or conspicuous acoustic manipulations. This paper introduces a generalised paradigm to study the value of non-lexical information in dialogue across unconstrained lexical content. By quantifying the perceptual value of the non-lexical channel with both accuracy and entropy reduction, we show that non-lexical information produces a consistent effect on expectations of upcoming dialogue: even when it leads to poorer discriminative turn judgements than lexical content alone, it yields higher consensus among participants.
Imperfect CSI: A Key Factor of Uncertainty to Over-the-Air Federated Learning
Jul 24, 2023
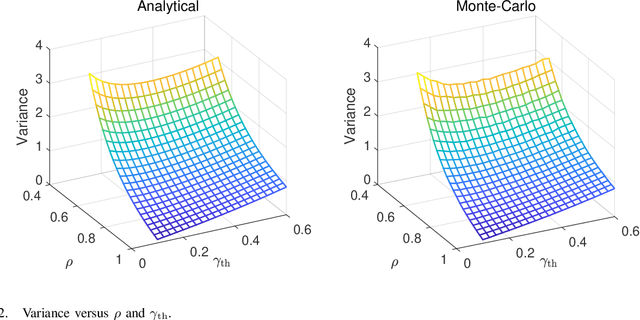
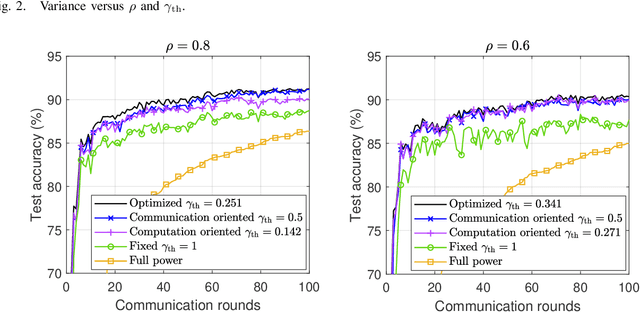
Over-the-air computation (AirComp) has recently been identified as a prominent technique to enhance communication efficiency of wireless federated learning (FL). This letter investigates the impact of channel state information (CSI) uncertainty at the transmitter on an AirComp enabled FL (AirFL) system with the truncated channel inversion strategy. To characterize the performance of the AirFL system, the weight divergence with respect to the ideal aggregation is analytically derived to evaluate learning performance loss. We explicitly reveal that the weight divergence deteriorates as $\mathcal{O}(1/\rho^2)$ as the level of channel estimation accuracy $\rho$ vanishes, and also has a decay rate of $\mathcal{O}(1/K^2)$ with the increasing number of participating devices, $K$. Building upon our analytical results, we formulate the channel truncation threshold optimization problem to adapt to different $\rho$, which can be solved optimally. Numerical results verify the analytical results and show that a lower truncation threshold is preferred with more accurate CSI.
Treatment Outcome Prediction for Intracerebral Hemorrhage via Generative Prognostic Model with Imaging and Tabular Data
Jul 24, 2023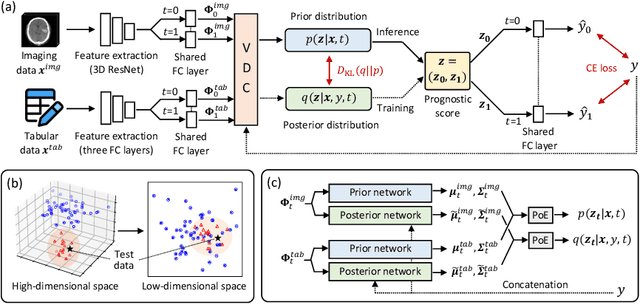
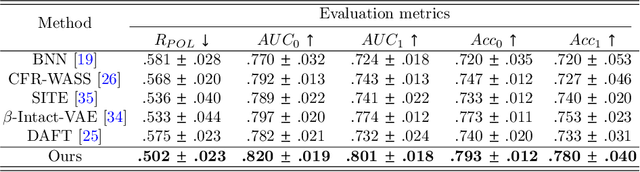
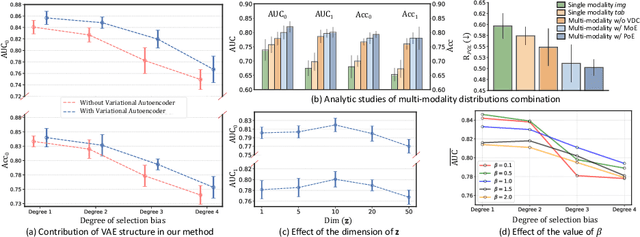
Intracerebral hemorrhage (ICH) is the second most common and deadliest form of stroke. Despite medical advances, predicting treat ment outcomes for ICH remains a challenge. This paper proposes a novel prognostic model that utilizes both imaging and tabular data to predict treatment outcome for ICH. Our model is trained on observational data collected from non-randomized controlled trials, providing reliable predictions of treatment success. Specifically, we propose to employ a variational autoencoder model to generate a low-dimensional prognostic score, which can effectively address the selection bias resulting from the non-randomized controlled trials. Importantly, we develop a variational distributions combination module that combines the information from imaging data, non-imaging clinical data, and treatment assignment to accurately generate the prognostic score. We conducted extensive experiments on a real-world clinical dataset of intracerebral hemorrhage. Our proposed method demonstrates a substantial improvement in treatment outcome prediction compared to existing state-of-the-art approaches. Code is available at https://github.com/med-air/TOP-GPM
Deep Homography Prediction for Endoscopic Camera Motion Imitation Learning
Jul 24, 2023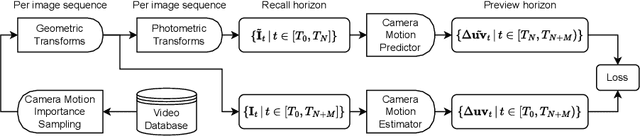

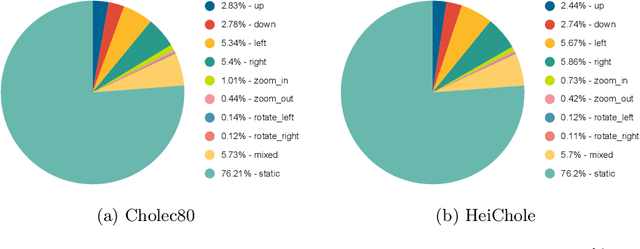
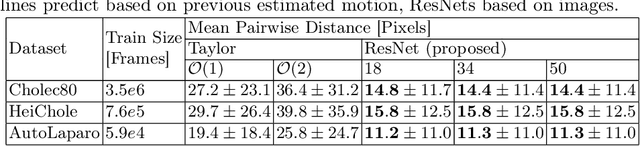
In this work, we investigate laparoscopic camera motion automation through imitation learning from retrospective videos of laparoscopic interventions. A novel method is introduced that learns to augment a surgeon's behavior in image space through object motion invariant image registration via homographies. Contrary to existing approaches, no geometric assumptions are made and no depth information is necessary, enabling immediate translation to a robotic setup. Deviating from the dominant approach in the literature which consist of following a surgical tool, we do not handcraft the objective and no priors are imposed on the surgical scene, allowing the method to discover unbiased policies. In this new research field, significant improvements are demonstrated over two baselines on the Cholec80 and HeiChole datasets, showcasing an improvement of 47% over camera motion continuation. The method is further shown to indeed predict camera motion correctly on the public motion classification labels of the AutoLaparo dataset. All code is made accessible on GitHub.
Continuation Path Learning for Homotopy Optimization
Jul 24, 2023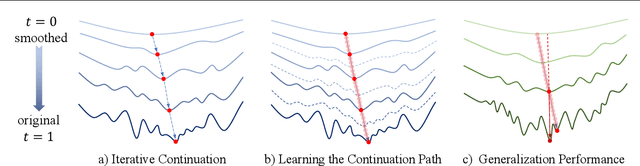

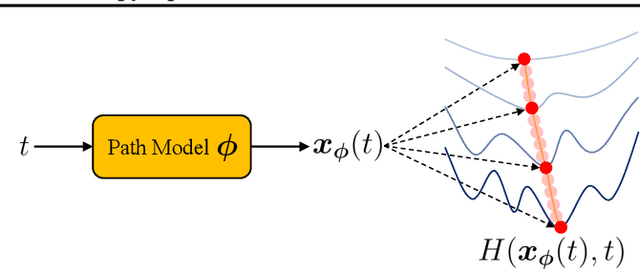

Homotopy optimization is a traditional method to deal with a complicated optimization problem by solving a sequence of easy-to-hard surrogate subproblems. However, this method can be very sensitive to the continuation schedule design and might lead to a suboptimal solution to the original problem. In addition, the intermediate solutions, often ignored by classic homotopy optimization, could be useful for many real-world applications. In this work, we propose a novel model-based approach to learn the whole continuation path for homotopy optimization, which contains infinite intermediate solutions for any surrogate subproblems. Rather than the classic unidirectional easy-to-hard optimization, our method can simultaneously optimize the original problem and all surrogate subproblems in a collaborative manner. The proposed model also supports real-time generation of any intermediate solution, which could be desirable for many applications. Experimental studies on different problems show that our proposed method can significantly improve the performance of homotopy optimization and provide extra helpful information to support better decision-making.
Robust face anti-spoofing framework with Convolutional Vision Transformer
Jul 24, 2023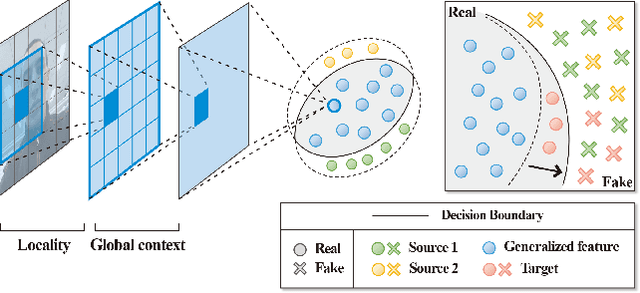
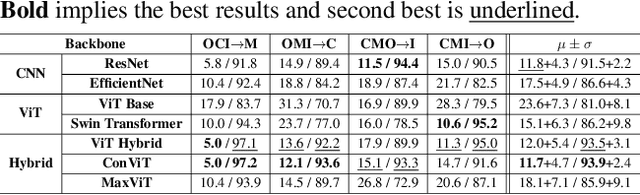
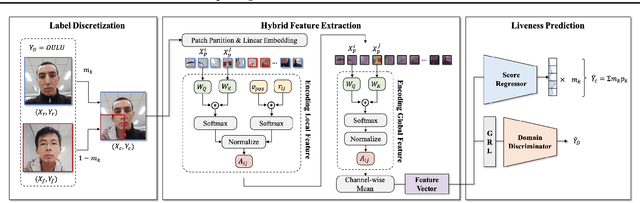
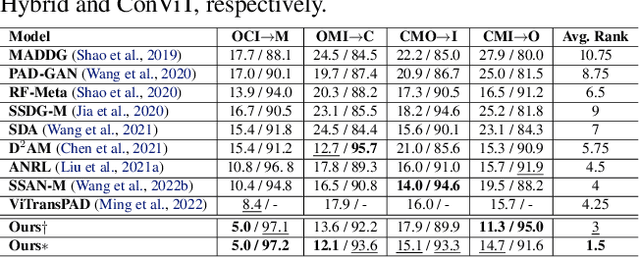
Owing to the advances in image processing technology and large-scale datasets, companies have implemented facial authentication processes, thereby stimulating increased focus on face anti-spoofing (FAS) against realistic presentation attacks. Recently, various attempts have been made to improve face recognition performance using both global and local learning on face images; however, to the best of our knowledge, this is the first study to investigate whether the robustness of FAS against domain shifts is improved by considering global information and local cues in face images captured using self-attention and convolutional layers. This study proposes a convolutional vision transformer-based framework that achieves robust performance for various unseen domain data. Our model resulted in 7.3%$p$ and 12.9%$p$ increases in FAS performance compared to models using only a convolutional neural network or vision transformer, respectively. It also shows the highest average rank in sub-protocols of cross-dataset setting over the other nine benchmark models for domain generalization.
Dense Transformer based Enhanced Coding Network for Unsupervised Metal Artifact Reduction
Jul 24, 2023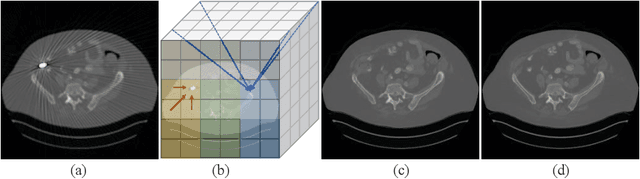

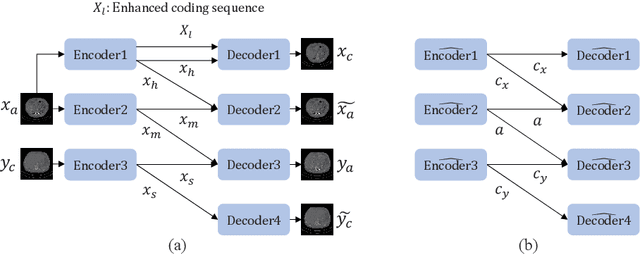
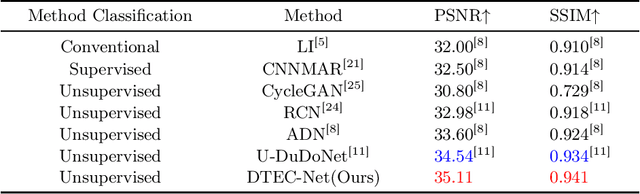
CT images corrupted by metal artifacts have serious negative effects on clinical diagnosis. Considering the difficulty of collecting paired data with ground truth in clinical settings, unsupervised methods for metal artifact reduction are of high interest. However, it is difficult for previous unsupervised methods to retain structural information from CT images while handling the non-local characteristics of metal artifacts. To address these challenges, we proposed a novel Dense Transformer based Enhanced Coding Network (DTEC-Net) for unsupervised metal artifact reduction. Specifically, we introduce a Hierarchical Disentangling Encoder, supported by the high-order dense process, and transformer to obtain densely encoded sequences with long-range correspondence. Then, we present a second-order disentanglement method to improve the dense sequence's decoding process. Extensive experiments and model discussions illustrate DTEC-Net's effectiveness, which outperforms the previous state-of-the-art methods on a benchmark dataset, and greatly reduces metal artifacts while restoring richer texture details.