 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembrane: A Self-Evolving Contrastive Safety Memory for LLM Agent Defense
Jun 04, 2026Despite advances in safety alignment, large language models remain vulnerable to continuously evolving jailbreaks. Existing fine-tuned safety classifiers cannot adapt to these evolving attacks, while adaptive memory-based guardrails tend to over-refuse benign queries that resemble stored attacks. We propose Membrane, a self-evolving guardrail built on Contrastive Safety Memory (CSM): each cell pairs the conditions for blocking a harmful query with those for permitting a superficially similar benign request. Without retraining, Membrane evolves CSM by distilling each harmful interaction and its benign counterpart into a contrastive cell indexed by the underlying attack strategy, so that one cell generalizes across topical variants of the same mechanism. At inference, retrieved cells serve as grounding context for precise safety decisions. Across model-level safety on HarmBench and agent-level safety on AgentHarm, Membrane achieves the highest F1 on all six jailbreak attacks. Notably, benign refusal on AgentHarm stays at 7-14%, well below the 28-85% range of prior guards. Memory cells also retain 87-88% F1 under cross-attack transfer and remain stable under memory poisoning.
K-FinHallu: A Hallucination Detection Benchmark for Multi-Turn RAG in Korean Finance
May 28, 2026Large Language Models (LLMs) have advanced financial automation through Retrieval-Augmented Generation (RAG), yet hallucinations remain a critical barrier to deployment in high-stakes environments. Existing benchmarks focus on single-turn, English-centric tasks, leaving the multi-turn dynamics and linguistic-regulatory nuances of the Korean financial domain unaddressed. We introduce K-FinHallu, the first benchmark for hallucination detection in multi-turn Korean financial RAG. We construct multi-turn dialogues from authentic Korean financial documents and inject hallucinations under a proposed hierarchical taxonomy based on context answerability that explicitly accounts for justified abstention. Benchmarking frontier and open-source LLMs as hallucination detectors, we find that even the strongest models struggle with fine-grained financial diagnostics and refusal behavior. While fine-tuning an 8B model on our training split yields performance competitive with frontier LLMs, justified abstention remains the weakest axis across all evaluated models.
ExpGuard: LLM Content Moderation in Specialized Domains
Mar 03, 2026With the growing deployment of large language models (LLMs) in real-world applications, establishing robust safety guardrails to moderate their inputs and outputs has become essential to ensure adherence to safety policies. Current guardrail models predominantly address general human-LLM interactions, rendering LLMs vulnerable to harmful and adversarial content within domain-specific contexts, particularly those rich in technical jargon and specialized concepts. To address this limitation, we introduce ExpGuard, a robust and specialized guardrail model designed to protect against harmful prompts and responses across financial, medical, and legal domains. In addition, we present ExpGuardMix, a meticulously curated dataset comprising 58,928 labeled prompts paired with corresponding refusal and compliant responses, from these specific sectors. This dataset is divided into two subsets: ExpGuardTrain, for model training, and ExpGuardTest, a high-quality test set annotated by domain experts to evaluate model robustness against technical and domain-specific content. Comprehensive evaluations conducted on ExpGuardTest and eight established public benchmarks reveal that ExpGuard delivers competitive performance across the board while demonstrating exceptional resilience to domain-specific adversarial attacks, surpassing state-of-the-art models such as WildGuard by up to 8.9% in prompt classification and 15.3% in response classification. To encourage further research and development, we open-source our code, data, and model, enabling adaptation to additional domains and supporting the creation of increasingly robust guardrail models.
BankMathBench: A Benchmark for Numerical Reasoning in Banking Scenarios
Feb 19, 2026Large language models (LLMs)-based chatbots are increasingly being adopted in the financial domain, particularly in digital banking, to handle customer inquiries about products such as deposits, savings, and loans. However, these models still exhibit low accuracy in core banking computations-including total payout estimation, comparison of products with varying interest rates, and interest calculation under early repayment conditions. Such tasks require multi-step numerical reasoning and contextual understanding of banking products, yet existing LLMs often make systematic errors-misinterpreting product types, applying conditions incorrectly, or failing basic calculations involving exponents and geometric progressions. However, such errors have rarely been captured by existing benchmarks. Mathematical datasets focus on fundamental math problems, whereas financial benchmarks primarily target financial documents, leaving everyday banking scenarios underexplored. To address this limitation, we propose BankMathBench, a domain-specific dataset that reflects realistic banking tasks. BankMathBench is organized in three levels of difficulty-basic, intermediate, and advanced-corresponding to single-product reasoning, multi-product comparison, and multi-condition scenarios, respectively. When trained on BankMathBench, open-source LLMs exhibited notable improvements in both formula generation and numerical reasoning accuracy, demonstrating the dataset's effectiveness in enhancing domain-specific reasoning. With tool-augmented fine-tuning, the models achieved average accuracy increases of 57.6%p (basic), 75.1%p (intermediate), and 62.9%p (advanced), representing significant gains over zero-shot baselines. These findings highlight BankMathBench as a reliable benchmark for evaluating and advancing LLMs' numerical reasoning in real-world banking scenarios.
Query Generation Pipeline with Enhanced Answerability Assessment for Financial Information Retrieval
Nov 07, 2025As financial applications of large language models (LLMs) gain attention, accurate Information Retrieval (IR) remains crucial for reliable AI services. However, existing benchmarks fail to capture the complex and domain-specific information needs of real-world banking scenarios. Building domain-specific IR benchmarks is costly and constrained by legal restrictions on using real customer data. To address these challenges, we propose a systematic methodology for constructing domain-specific IR benchmarks through LLM-based query generation. As a concrete implementation of this methodology, our pipeline combines single and multi-document query generation with an enhanced and reasoning-augmented answerability assessment method, achieving stronger alignment with human judgments than prior approaches. Using this methodology, we construct KoBankIR, comprising 815 queries derived from 204 official banking documents. Our experiments show that existing retrieval models struggle with the complex multi-document queries in KoBankIR, demonstrating the value of our systematic approach for domain-specific benchmark construction and underscoring the need for improved retrieval techniques in financial domains.
Federated Learning for Face Recognition via Intra-subject Self-supervised Learning
Jul 23, 2024Federated Learning (FL) for face recognition aggregates locally optimized models from individual clients to construct a generalized face recognition model. However, previous studies present two major challenges: insufficient incorporation of self-supervised learning and the necessity for clients to accommodate multiple subjects. To tackle these limitations, we propose FedFS (Federated Learning for personalized Face recognition via intra-subject Self-supervised learning framework), a novel federated learning architecture tailored to train personalized face recognition models without imposing subjects. Our proposed FedFS comprises two crucial components that leverage aggregated features of the local and global models to cooperate with representations of an off-the-shelf model. These components are (1) adaptive soft label construction, utilizing dot product operations to reformat labels within intra-instances, and (2) intra-subject self-supervised learning, employing cosine similarity operations to strengthen robust intra-subject representations. Additionally, we introduce a regularization loss to prevent overfitting and ensure the stability of the optimized model. To assess the effectiveness of FedFS, we conduct comprehensive experiments on the DigiFace-1M and VGGFace datasets, demonstrating superior performance compared to previous methods.
ProtoFL: Unsupervised Federated Learning via Prototypical Distillation
Aug 08, 2023



Federated learning (FL) is a promising approach for enhancing data privacy preservation, particularly for authentication systems. However, limited round communications, scarce representation, and scalability pose significant challenges to its deployment, hindering its full potential. In this paper, we propose 'ProtoFL', Prototypical Representation Distillation based unsupervised Federated Learning to enhance the representation power of a global model and reduce round communication costs. Additionally, we introduce a local one-class classifier based on normalizing flows to improve performance with limited data. Our study represents the first investigation of using FL to improve one-class classification performance. We conduct extensive experiments on five widely used benchmarks, namely MNIST, CIFAR-10, CIFAR-100, ImageNet-30, and Keystroke-Dynamics, to demonstrate the superior performance of our proposed framework over previous methods in the literature.
Robust face anti-spoofing framework with Convolutional Vision Transformer
Jul 24, 2023



Owing to the advances in image processing technology and large-scale datasets, companies have implemented facial authentication processes, thereby stimulating increased focus on face anti-spoofing (FAS) against realistic presentation attacks. Recently, various attempts have been made to improve face recognition performance using both global and local learning on face images; however, to the best of our knowledge, this is the first study to investigate whether the robustness of FAS against domain shifts is improved by considering global information and local cues in face images captured using self-attention and convolutional layers. This study proposes a convolutional vision transformer-based framework that achieves robust performance for various unseen domain data. Our model resulted in 7.3%$p$ and 12.9%$p$ increases in FAS performance compared to models using only a convolutional neural network or vision transformer, respectively. It also shows the highest average rank in sub-protocols of cross-dataset setting over the other nine benchmark models for domain generalization.
Liveness score-based regression neural networks for face anti-spoofing
Feb 19, 2023Previous anti-spoofing methods have used either pseudo maps or user-defined labels, and the performance of each approach depends on the accuracy of the third party networks generating pseudo maps and the way in which the users define the labels. In this paper, we propose a liveness score-based regression network for overcoming the dependency on third party networks and users. First, we introduce a new labeling technique, called pseudo-discretized label encoding for generating discretized labels indicating the amount of information related to real images. Secondly, we suggest the expected liveness score based on a regression network for training the difference between the proposed supervision and the expected liveness score. Finally, extensive experiments were conducted on four face anti-spoofing benchmarks to verify our proposed method on both intra-and cross-dataset tests. The experimental results show our approach outperforms previous methods.
A Generalized and Robust Method Towards Practical Gaze Estimation on Smart Phone
Oct 16, 2019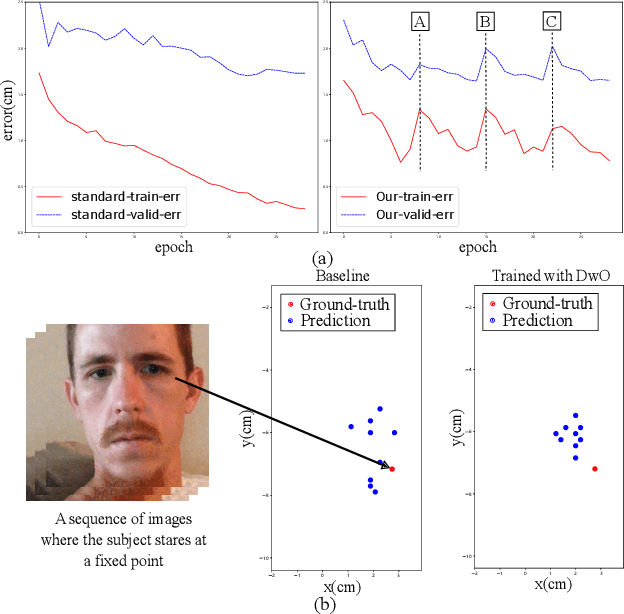
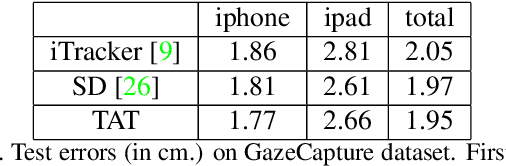
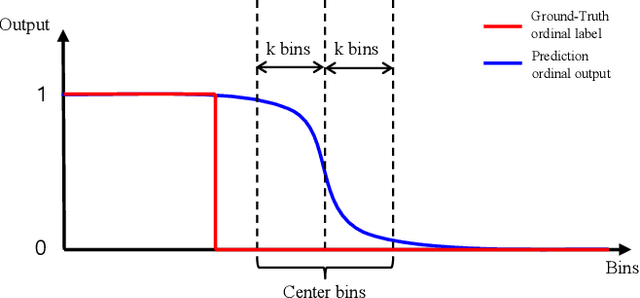
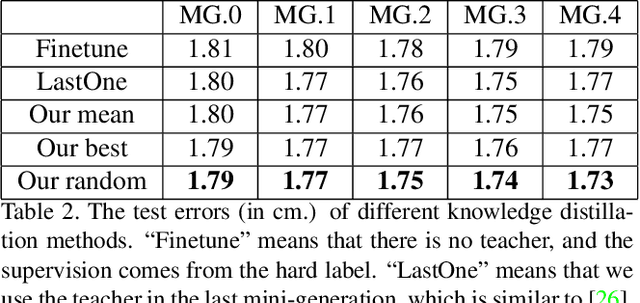
Gaze estimation for ordinary smart phone, e.g. estimating where the user is looking at on the phone screen, can be applied in various applications. However, the widely used appearance-based CNN methods still have two issues for practical adoption. First, due to the limited dataset, gaze estimation is very likely to suffer from over-fitting, leading to poor accuracy at run time. Second, the current methods are usually not robust, i.e. their prediction results having notable jitters even when the user is performing gaze fixation, which degrades user experience greatly. For the first issue, we propose a new tolerant and talented (TAT) training scheme, which is an iterative random knowledge distillation framework enhanced with cosine similarity pruning and aligned orthogonal initialization. The knowledge distillation is a tolerant teaching process providing diverse and informative supervision. The enhanced pruning and initialization is a talented learning process prompting the network to escape from the local minima and re-born from a better start. For the second issue, we define a new metric to measure the robustness of gaze estimator, and propose an adversarial training based Disturbance with Ordinal loss (DwO) method to improve it. The experimental results show that our TAT method achieves state-of-the-art performance on GazeCapture dataset, and that our DwO method improves the robustness while keeping comparable accuracy.