 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial Self-Attack Defense and Spatial-Temporal Relation Mining for Visible-Infrared Video Person Re-Identification
Jul 08, 2023
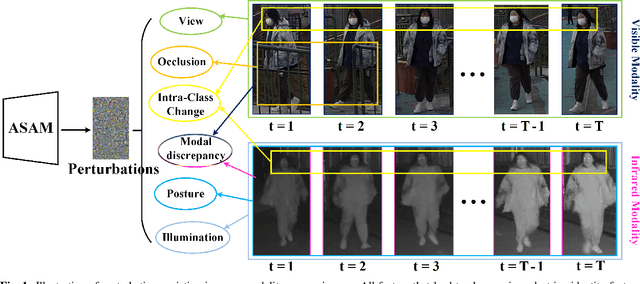
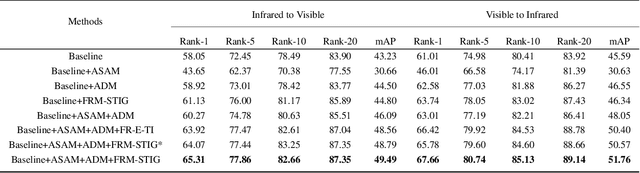
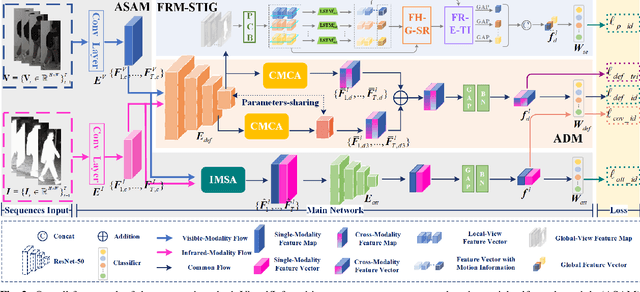
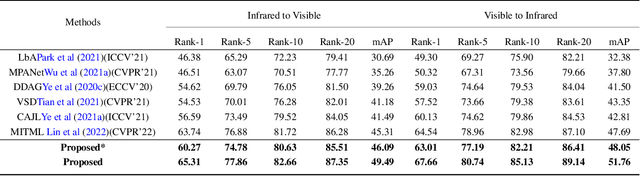
In visible-infrared video person re-identification (re-ID), extracting features not affected by complex scenes (such as modality, camera views, pedestrian pose, background, etc.) changes, and mining and utilizing motion information are the keys to solving cross-modal pedestrian identity matching. To this end, the paper proposes a new visible-infrared video person re-ID method from a novel perspective, i.e., adversarial self-attack defense and spatial-temporal relation mining. In this work, the changes of views, posture, background and modal discrepancy are considered as the main factors that cause the perturbations of person identity features. Such interference information contained in the training samples is used as an adversarial perturbation. It performs adversarial attacks on the re-ID model during the training to make the model more robust to these unfavorable factors. The attack from the adversarial perturbation is introduced by activating the interference information contained in the input samples without generating adversarial samples, and it can be thus called adversarial self-attack. This design allows adversarial attack and defense to be integrated into one framework. This paper further proposes a spatial-temporal information-guided feature representation network to use the information in video sequences. The network cannot only extract the information contained in the video-frame sequences but also use the relation of the local information in space to guide the network to extract more robust features. The proposed method exhibits compelling performance on large-scale cross-modality video datasets. The source code of the proposed method will be released at https://github.com/lhf12278/xxx.
Predicting delays in Indian lower courts using AutoML and Decision Forests
Jul 30, 2023
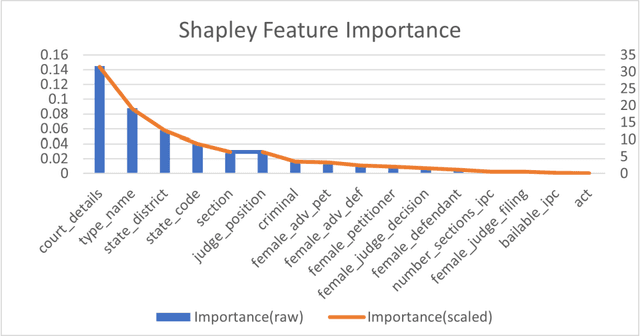
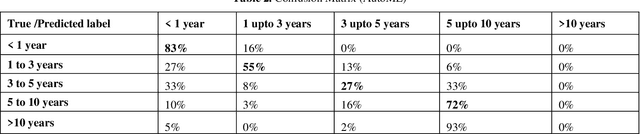
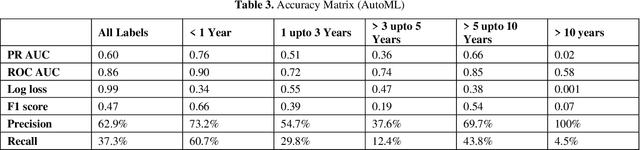
This paper presents a classification model that predicts delays in Indian lower courts based on case information available at filing. The model is built on a dataset of 4.2 million court cases filed in 2010 and their outcomes over a 10-year period. The data set is drawn from 7000+ lower courts in India. The authors employed AutoML to develop a multi-class classification model over all periods of pendency and then used binary decision forest classifiers to improve predictive accuracy for the classification of delays. The best model achieved an accuracy of 81.4%, and the precision, recall, and F1 were found to be 0.81. The study demonstrates the feasibility of AI models for predicting delays in Indian courts, based on relevant data points such as jurisdiction, court, judge, subject, and the parties involved. The paper also discusses the results in light of relevant literature and suggests areas for improvement and future research. The authors have made the dataset and Python code files used for the analysis available for further research in the crucial and contemporary field of Indian judicial reform.
StylePrompter: All Styles Need Is Attention
Jul 30, 2023
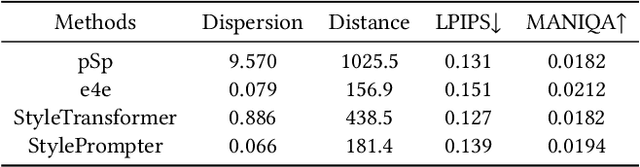
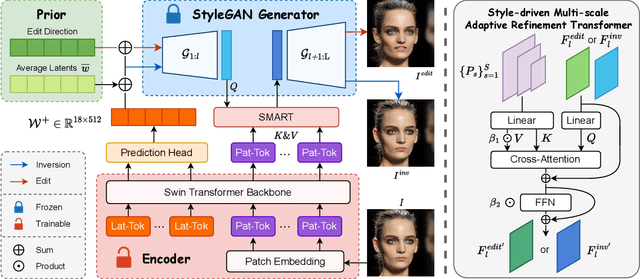
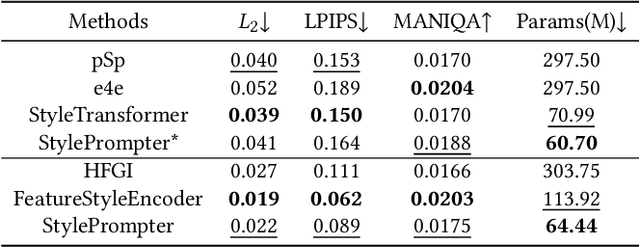
GAN inversion aims at inverting given images into corresponding latent codes for Generative Adversarial Networks (GANs), especially StyleGAN where exists a disentangled latent space that allows attribute-based image manipulation at latent level. As most inversion methods build upon Convolutional Neural Networks (CNNs), we transfer a hierarchical vision Transformer backbone innovatively to predict $\mathcal{W^+}$ latent codes at token level. We further apply a Style-driven Multi-scale Adaptive Refinement Transformer (SMART) in $\mathcal{F}$ space to refine the intermediate style features of the generator. By treating style features as queries to retrieve lost identity information from the encoder's feature maps, SMART can not only produce high-quality inverted images but also surprisingly adapt to editing tasks. We then prove that StylePrompter lies in a more disentangled $\mathcal{W^+}$ and show the controllability of SMART. Finally, quantitative and qualitative experiments demonstrate that StylePrompter can achieve desirable performance in balancing reconstruction quality and editability, and is "smart" enough to fit into most edits, outperforming other $\mathcal{F}$-involved inversion methods.
ScribbleVC: Scribble-supervised Medical Image Segmentation with Vision-Class Embedding
Jul 30, 2023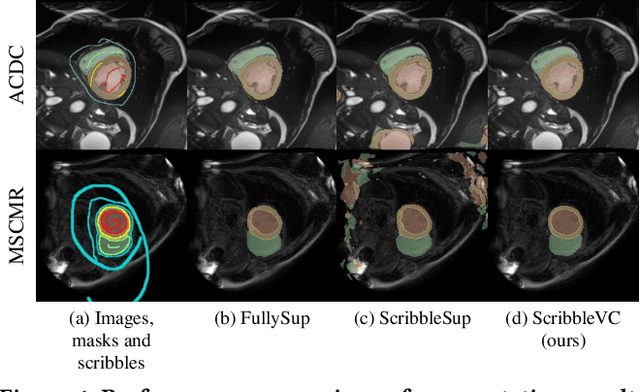
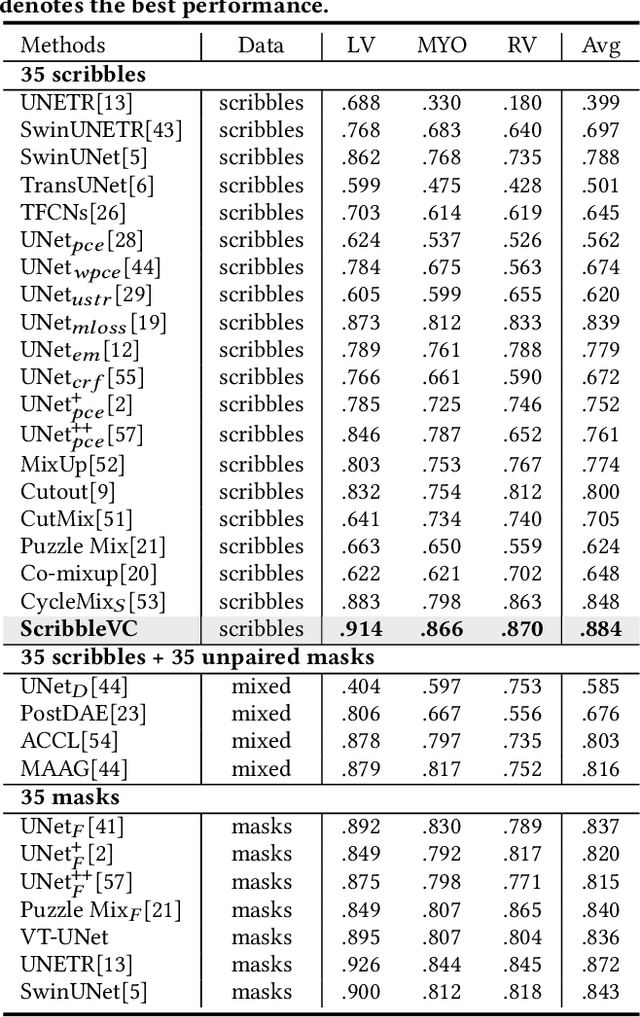
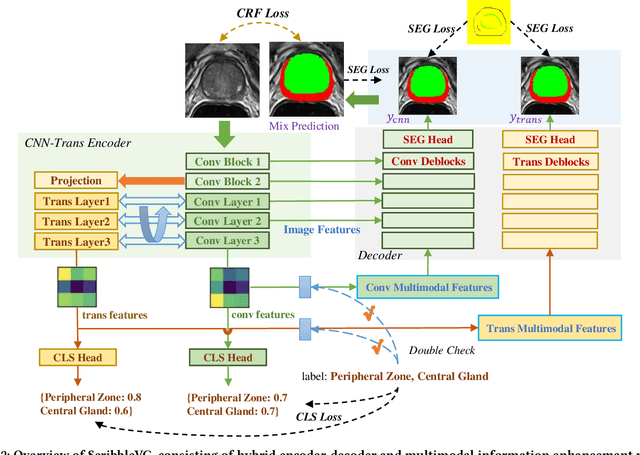
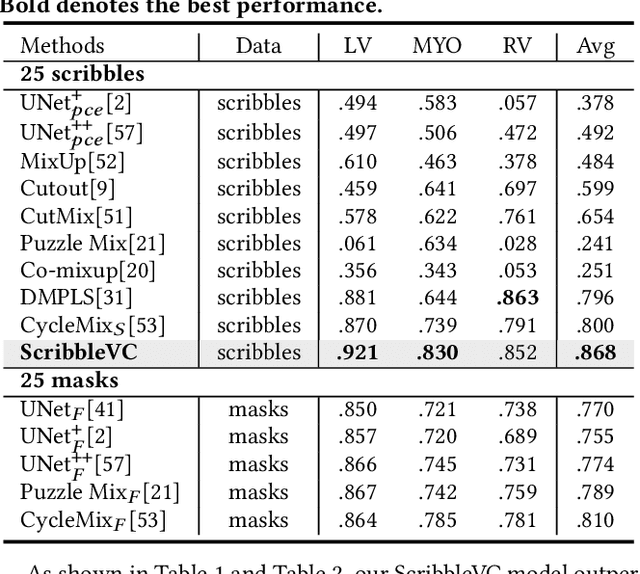
Medical image segmentation plays a critical role in clinical decision-making, treatment planning, and disease monitoring. However, accurate segmentation of medical images is challenging due to several factors, such as the lack of high-quality annotation, imaging noise, and anatomical differences across patients. In addition, there is still a considerable gap in performance between the existing label-efficient methods and fully-supervised methods. To address the above challenges, we propose ScribbleVC, a novel framework for scribble-supervised medical image segmentation that leverages vision and class embeddings via the multimodal information enhancement mechanism. In addition, ScribbleVC uniformly utilizes the CNN features and Transformer features to achieve better visual feature extraction. The proposed method combines a scribble-based approach with a segmentation network and a class-embedding module to produce accurate segmentation masks. We evaluate ScribbleVC on three benchmark datasets and compare it with state-of-the-art methods. The experimental results demonstrate that our method outperforms existing approaches in terms of accuracy, robustness, and efficiency. The datasets and code are released on GitHub.
Decisive Data using Multi-Modality Optical Sensors for Advanced Vehicular Systems
Jul 25, 2023



Optical sensors have played a pivotal role in acquiring real world data for critical applications. This data, when integrated with advanced machine learning algorithms provides meaningful information thus enhancing human vision. This paper focuses on various optical technologies for design and development of state-of-the-art out-cabin forward vision systems and in-cabin driver monitoring systems. The focused optical sensors include Longwave Thermal Imaging (LWIR) cameras, Near Infrared (NIR), Neuromorphic/ event cameras, Visible CMOS cameras and Depth cameras. Further the paper discusses different potential applications which can be employed using the unique strengths of each these optical modalities in real time environment.
Universal Approximation of Linear Time-Invariant (LTI) Systems through RNNs: Power of Randomness in Reservoir Computing
Aug 04, 2023Recurrent neural networks (RNNs) are known to be universal approximators of dynamic systems under fairly mild and general assumptions, making them good tools to process temporal information. However, RNNs usually suffer from the issues of vanishing and exploding gradients in the standard RNN training. Reservoir computing (RC), a special RNN where the recurrent weights are randomized and left untrained, has been introduced to overcome these issues and has demonstrated superior empirical performance in fields as diverse as natural language processing and wireless communications especially in scenarios where training samples are extremely limited. On the contrary, the theoretical grounding to support this observed performance has not been fully developed at the same pace. In this work, we show that RNNs can provide universal approximation of linear time-invariant (LTI) systems. Specifically, we show that RC can universally approximate a general LTI system. We present a clear signal processing interpretation of RC and utilize this understanding in the problem of simulating a generic LTI system through RC. Under this setup, we analytically characterize the optimal probability distribution function for generating the recurrent weights of the underlying RNN of the RC. We provide extensive numerical evaluations to validate the optimality of the derived optimum distribution of the recurrent weights of the RC for the LTI system simulation problem. Our work results in clear signal processing-based model interpretability of RC and provides theoretical explanation for the power of randomness in setting instead of training RC's recurrent weights. It further provides a complete optimum analytical characterization for the untrained recurrent weights, marking an important step towards explainable machine learning (XML) which is extremely important for applications where training samples are limited.
A Quantize-then-Estimate Protocol for CSI Acquisition in IRS-Aided Downlink Communication
Aug 04, 2023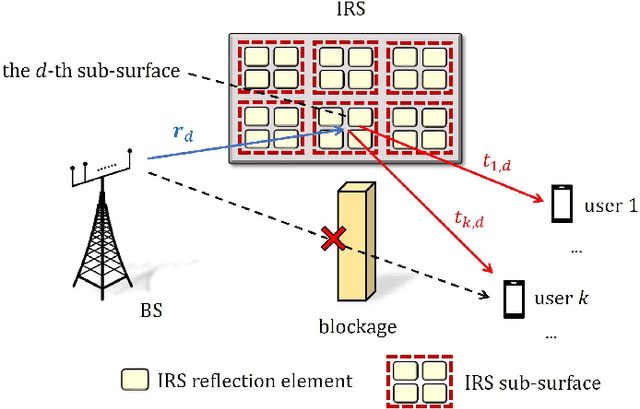
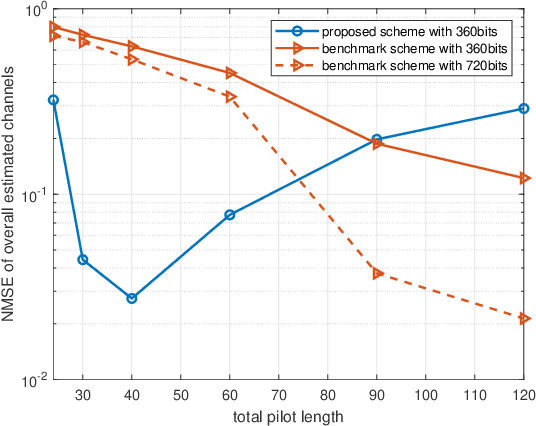
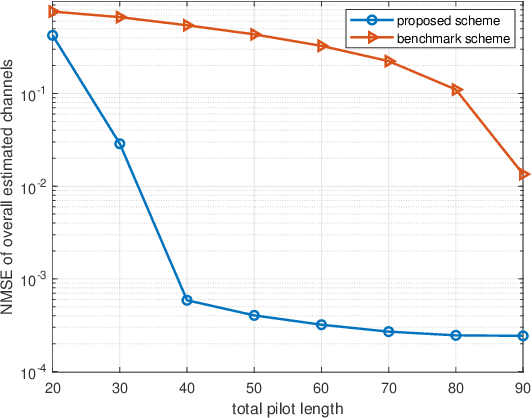
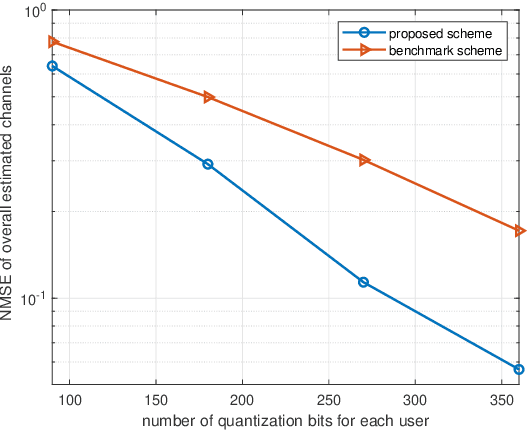
For intelligent reflecting surface (IRS) aided downlink communication in frequency division duplex (FDD) systems, the overhead for the base station (BS) to acquire channel state information (CSI) is extremely high under the conventional ``estimate-then-quantize'' scheme, where the users first estimate and then feed back their channels to the BS. Recently, [1] revealed a strong correlation in different users' cascaded channels stemming from their common BS-IRS channel component, and leveraged such a correlation to significantly reduce the pilot transmission overhead in IRS-aided uplink communication. In this paper, we aim to exploit the above channel property for reducing the overhead of both pilot transmission and feedback transmission in IRS-aided downlink communication. Different from the uplink counterpart where the BS possesses the pilot signals containing the CSI of all the users, in downlink communication, the distributed users merely receive the pilot signals containing their own CSI and cannot leverage the correlation in different users' channels revealed in [1]. To tackle this challenge, this paper proposes a novel ``quantize-then-estimate'' protocol in FDD IRS-aided downlink communication. Specifically, the users first quantize their received pilot signals, instead of the channels estimated from the pilot signals, and then transmit the quantization bits to the BS. After de-quantizing the pilot signals received by all the users, the BS estimates all the cascaded channels by leveraging the correlation embedded in them, similar to the uplink scenario. Furthermore, we manage to show both analytically and numerically the great overhead reduction in terms of pilot transmission and feedback transmission arising from our proposed ``quantize-then-estimate'' protocol.
Step-GRAND: A Low Latency Universal Soft-input Decoder
Jul 27, 2023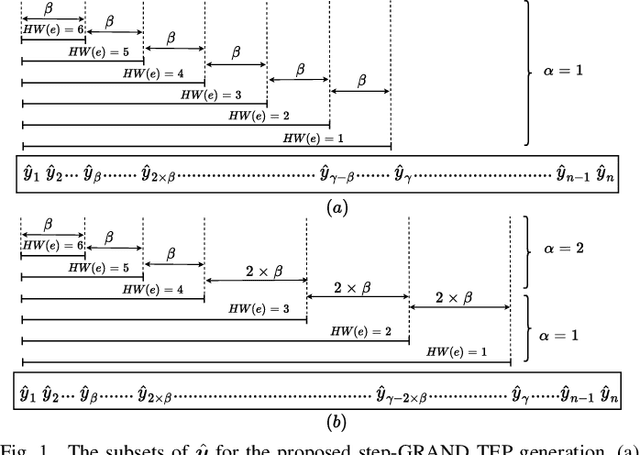
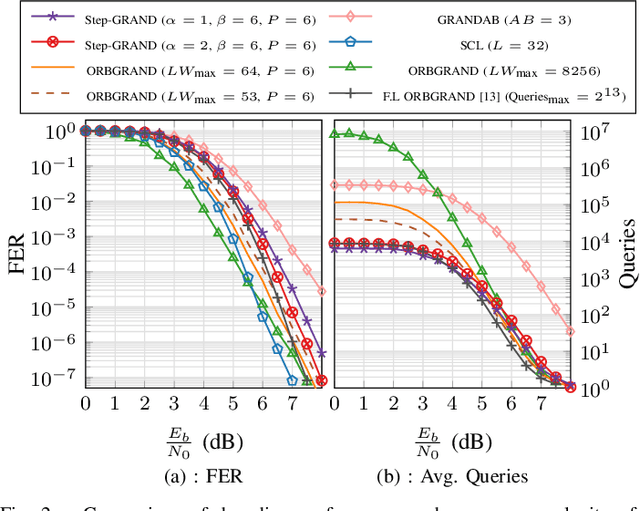
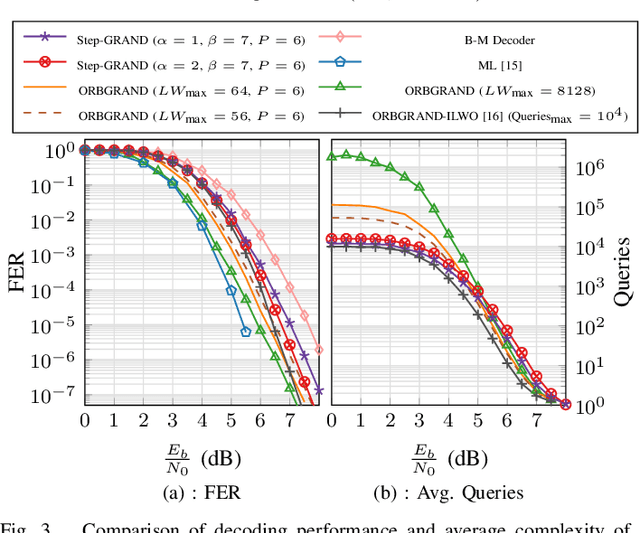
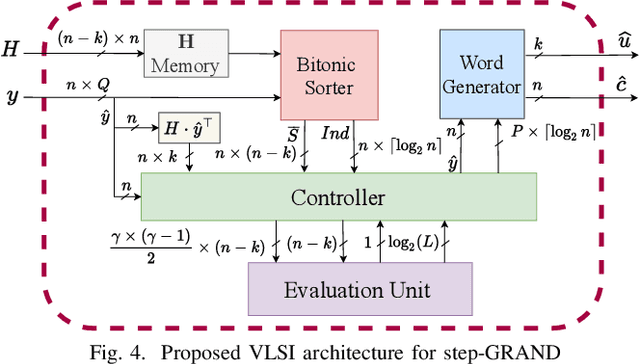
GRAND features both soft-input and hard-input variants that are well suited to efficient hardware implementations that can be characterized with achievable average and worst-case decoding latency. This paper introduces step-GRAND, a soft-input variant of GRAND that, in addition to achieving appealing average decoding latency, also reduces the worst-case decoding latency of the corresponding hardware implementation. The hardware implementation results demonstrate that the proposed step-GRAND can decode CA-polar code $(128,105+11)$ with an average information throughput of $47.7$ Gbps at the target FER of $\leq10^{-7}$. Furthermore, the proposed step-GRAND hardware is $10\times$ more area efficient than the previous soft-input ORBGRAND hardware implementation, and its worst-case latency is $\frac{1}{6.8}\times$ that of the previous ORBGRAND hardware.
Benchmarking Performance of Deep Learning Model for Material Segmentation on Two HPC Systems
Jul 27, 2023Performance Benchmarking of HPC systems is an ongoing effort that seeks to provide information that will allow for increased performance and improve the job schedulers that manage these systems. We develop a benchmarking tool that utilizes machine learning models and gathers performance data on GPU-accelerated nodes while they perform material segmentation analysis. The benchmark uses a ML model that has been converted from Caffe to PyTorch using the MMdnn toolkit and the MINC-2500 dataset. Performance data is gathered on two ERDC DSRC systems, Onyx and Vulcanite. The data reveals that while Vulcanite has faster model times in a large number of benchmarks, and it is also more subject to some environmental factors that can cause performances slower than Onyx. In contrast the model times from Onyx are consistent across benchmarks.
Visual Information Matters for ASR Error Correction
Mar 16, 2023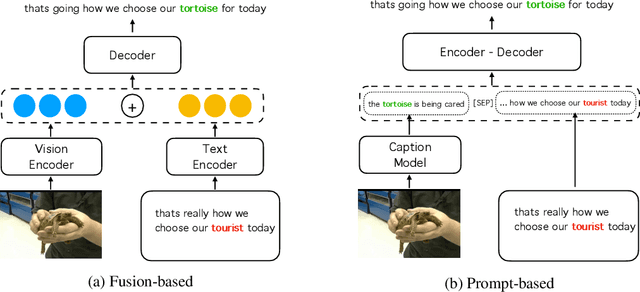
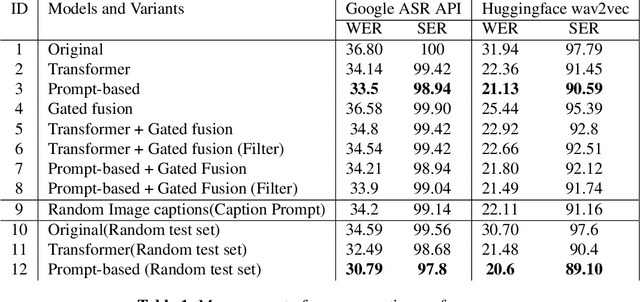


Aiming to improve the Automatic Speech Recognition (ASR) outputs with a post-processing step, ASR error correction (EC) techniques have been widely developed due to their efficiency in using parallel text data. Previous works mainly focus on using text or/ and speech data, which hinders the performance gain when not only text and speech information, but other modalities, such as visual information are critical for EC. The challenges are mainly two folds: one is that previous work fails to emphasize visual information, thus rare exploration has been studied. The other is that the community lacks a high-quality benchmark where visual information matters for the EC models. Therefore, this paper provides 1) simple yet effective methods, namely gated fusion and image captions as prompts to incorporate visual information to help EC; 2) large-scale benchmark datasets, namely Visual-ASR-EC, where each item in the training data consists of visual, speech, and text information, and the test data are carefully selected by human annotators to ensure that even humans could make mistakes when visual information is missing. Experimental results show that using captions as prompts could effectively use the visual information and surpass state-of-the-art methods by upto 1.2% in Word Error Rate(WER), which also indicates that visual information is critical in our proposed Visual-ASR-EC dataset