 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Semantically Enriched Embeddings for Knowledge Graph Completion
Aug 02, 2023

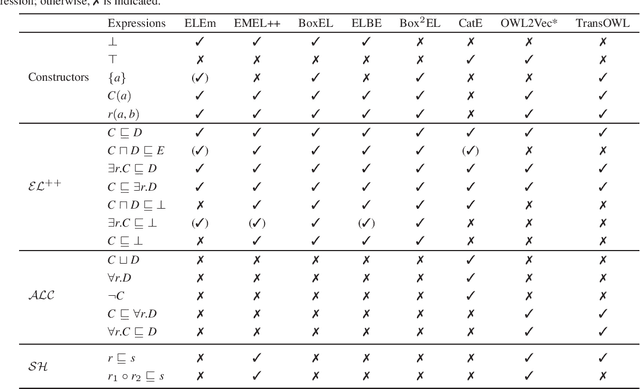
Embedding based Knowledge Graph (KG) Completion has gained much attention over the past few years. Most of the current algorithms consider a KG as a multidirectional labeled graph and lack the ability to capture the semantics underlying the schematic information. In a separate development, a vast amount of information has been captured within the Large Language Models (LLMs) which has revolutionized the field of Artificial Intelligence. KGs could benefit from these LLMs and vice versa. This vision paper discusses the existing algorithms for KG completion based on the variations for generating KG embeddings. It starts with discussing various KG completion algorithms such as transductive and inductive link prediction and entity type prediction algorithms. It then moves on to the algorithms utilizing type information within the KGs, LLMs, and finally to algorithms capturing the semantics represented in different description logic axioms. We conclude the paper with a critical reflection on the current state of work in the community and give recommendations for future directions.
CFN-ESA: A Cross-Modal Fusion Network with Emotion-Shift Awareness for Dialogue Emotion Recognition
Jul 28, 2023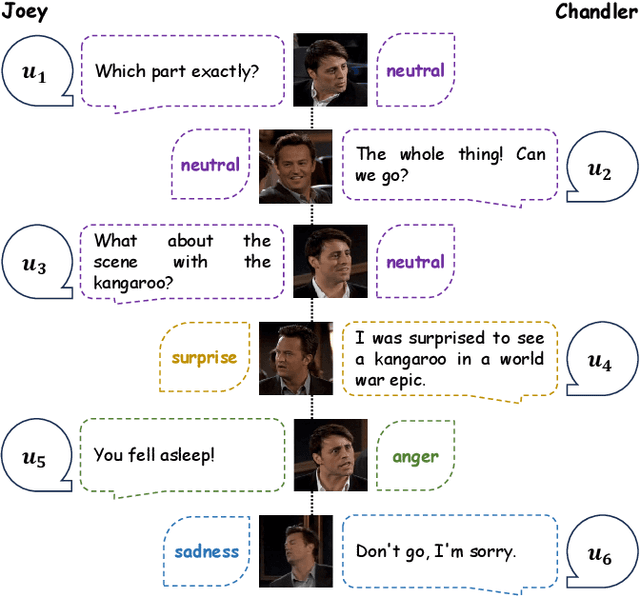
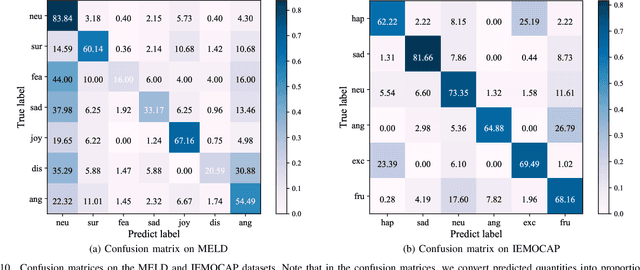
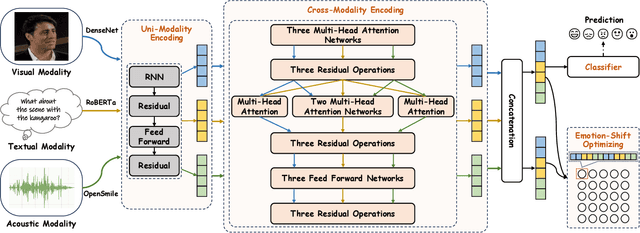
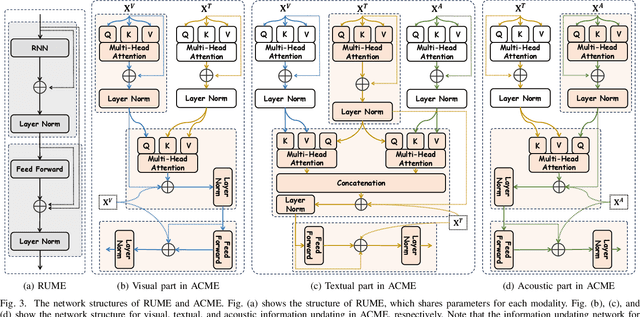
Multimodal Emotion Recognition in Conversation (ERC) has garnered growing attention from research communities in various fields. In this paper, we propose a cross-modal fusion network with emotion-shift awareness (CFN-ESA) for ERC. Extant approaches employ each modality equally without distinguishing the amount of emotional information, rendering it hard to adequately extract complementary and associative information from multimodal data. To cope with this problem, in CFN-ESA, textual modalities are treated as the primary source of emotional information, while visual and acoustic modalities are taken as the secondary sources. Besides, most multimodal ERC models ignore emotion-shift information and overfocus on contextual information, leading to the failure of emotion recognition under emotion-shift scenario. We elaborate an emotion-shift module to address this challenge. CFN-ESA mainly consists of the unimodal encoder (RUME), cross-modal encoder (ACME), and emotion-shift module (LESM). RUME is applied to extract conversation-level contextual emotional cues while pulling together the data distributions between modalities; ACME is utilized to perform multimodal interaction centered on textual modality; LESM is used to model emotion shift and capture related information, thereby guide the learning of the main task. Experimental results demonstrate that CFN-ESA can effectively promote performance for ERC and remarkably outperform the state-of-the-art models.
When Are Two Lists Better than One?: Benefits and Harms in Joint Decision-making
Aug 22, 2023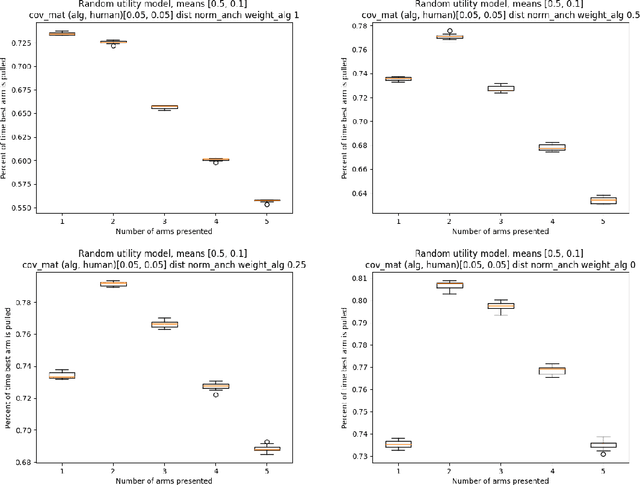
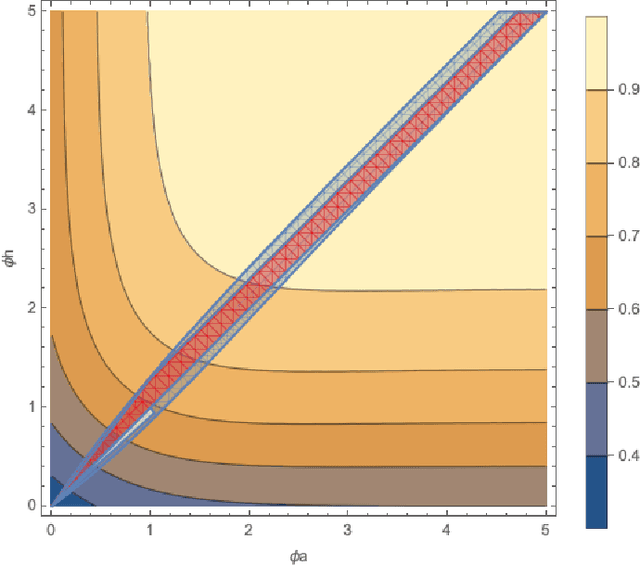
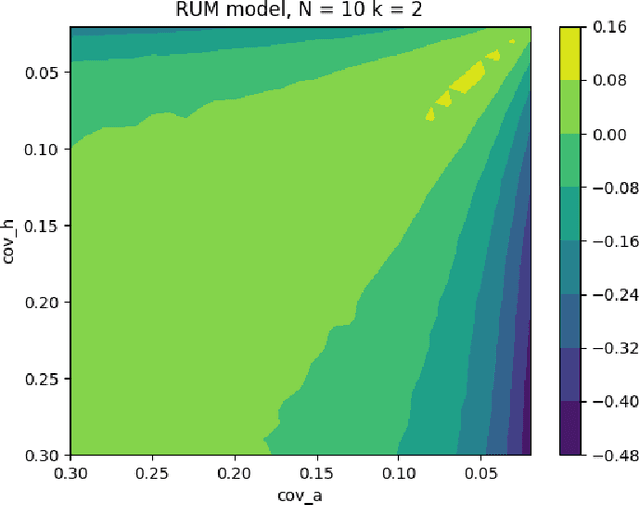
Historically, much of machine learning research has focused on the performance of the algorithm alone, but recently more attention has been focused on optimizing joint human-algorithm performance. Here, we analyze a specific type of human-algorithm collaboration where the algorithm has access to a set of $n$ items, and presents a subset of size $k$ to the human, who selects a final item from among those $k$. This scenario could model content recommendation, route planning, or any type of labeling task. Because both the human and algorithm have imperfect, noisy information about the true ordering of items, the key question is: which value of $k$ maximizes the probability that the best item will be ultimately selected? For $k=1$, performance is optimized by the algorithm acting alone, and for $k=n$ it is optimized by the human acting alone. Surprisingly, we show that for multiple of noise models, it is optimal to set $k \in [2, n-1]$ - that is, there are strict benefits to collaborating, even when the human and algorithm have equal accuracy separately. We demonstrate this theoretically for the Mallows model and experimentally for the Random Utilities models of noisy permutations. However, we show this pattern is reversed when the human is anchored on the algorithm's presented ordering - the joint system always has strictly worse performance. We extend these results to the case where the human and algorithm differ in their accuracy levels, showing that there always exist regimes where a more accurate agent would strictly benefit from collaborating with a less accurate one, but these regimes are asymmetric between the human and the algorithm's accuracy.
BioBERT Based SNP-traits Associations Extraction from Biomedical Literature
Aug 03, 2023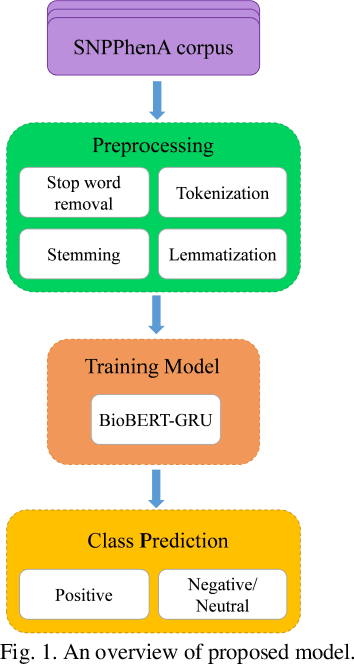
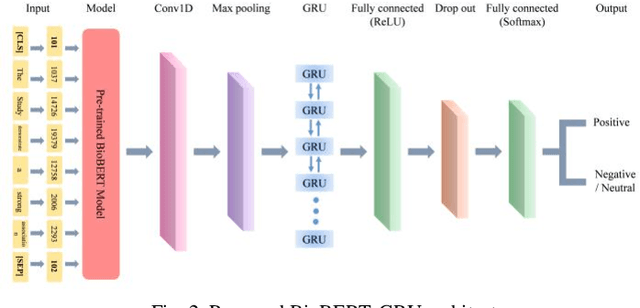
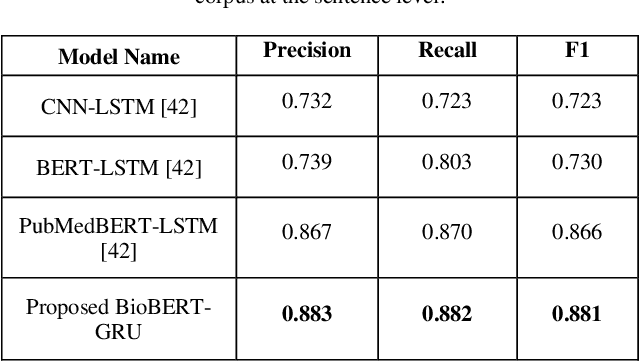
Scientific literature contains a considerable amount of information that provides an excellent opportunity for developing text mining methods to extract biomedical relationships. An important type of information is the relationship between singular nucleotide polymorphisms (SNP) and traits. In this paper, we present a BioBERT-GRU method to identify SNP- traits associations. Based on the evaluation of our method on the SNPPhenA dataset, it is concluded that this new method performs better than previous machine learning and deep learning based methods. BioBERT-GRU achieved the result a precision of 0.883, recall of 0.882 and F1-score of 0.881.
Multi-modal Visual Understanding with Prompts for Semantic Information Disentanglement of Image
May 16, 2023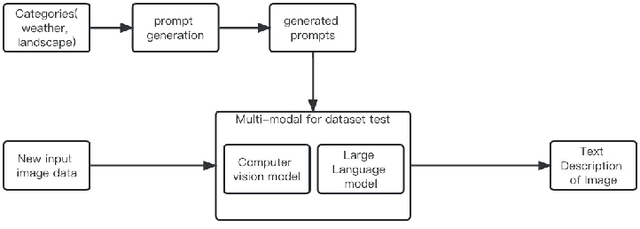


Multi-modal visual understanding of images with prompts involves using various visual and textual cues to enhance the semantic understanding of images. This approach combines both vision and language processing to generate more accurate predictions and recognition of images. By utilizing prompt-based techniques, models can learn to focus on certain features of an image to extract useful information for downstream tasks. Additionally, multi-modal understanding can improve upon single modality models by providing more robust representations of images. Overall, the combination of visual and textual information is a promising area of research for advancing image recognition and understanding. In this paper we will try an amount of prompt design methods and propose a new method for better extraction of semantic information
Lost in the Middle: How Language Models Use Long Contexts
Jul 31, 2023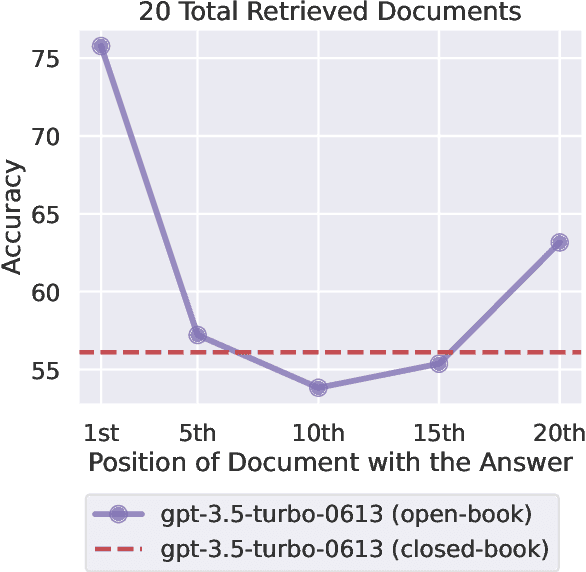
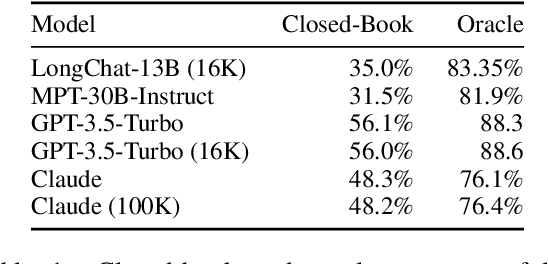


While recent language models have the ability to take long contexts as input, relatively little is known about how well they use longer context. We analyze language model performance on two tasks that require identifying relevant information within their input contexts: multi-document question answering and key-value retrieval. We find that performance is often highest when relevant information occurs at the beginning or end of the input context, and significantly degrades when models must access relevant information in the middle of long contexts. Furthermore, performance substantially decreases as the input context grows longer, even for explicitly long-context models. Our analysis provides a better understanding of how language models use their input context and provides new evaluation protocols for future long-context models.
UniAP: Towards Universal Animal Perception in Vision via Few-shot Learning
Aug 19, 2023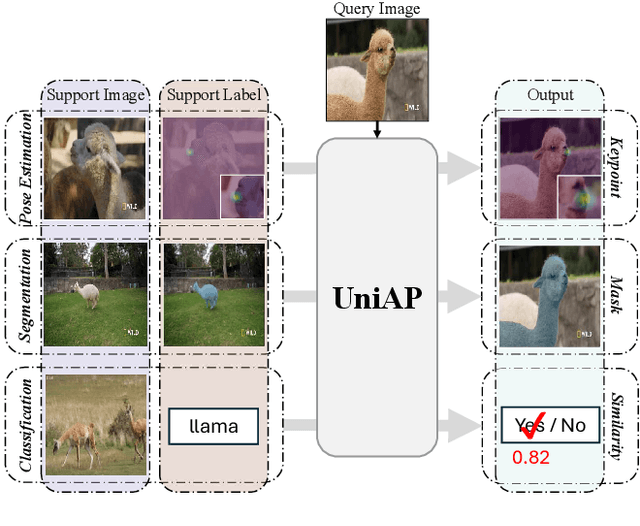
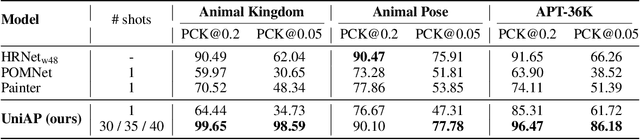
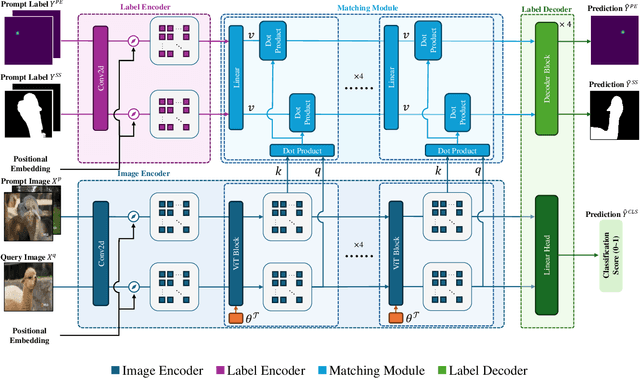
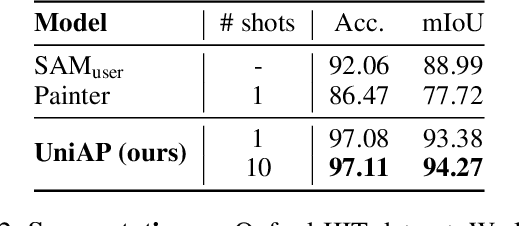
Animal visual perception is an important technique for automatically monitoring animal health, understanding animal behaviors, and assisting animal-related research. However, it is challenging to design a deep learning-based perception model that can freely adapt to different animals across various perception tasks, due to the varying poses of a large diversity of animals, lacking data on rare species, and the semantic inconsistency of different tasks. We introduce UniAP, a novel Universal Animal Perception model that leverages few-shot learning to enable cross-species perception among various visual tasks. Our proposed model takes support images and labels as prompt guidance for a query image. Images and labels are processed through a Transformer-based encoder and a lightweight label encoder, respectively. Then a matching module is designed for aggregating information between prompt guidance and the query image, followed by a multi-head label decoder to generate outputs for various tasks. By capitalizing on the shared visual characteristics among different animals and tasks, UniAP enables the transfer of knowledge from well-studied species to those with limited labeled data or even unseen species. We demonstrate the effectiveness of UniAP through comprehensive experiments in pose estimation, segmentation, and classification tasks on diverse animal species, showcasing its ability to generalize and adapt to new classes with minimal labeled examples.
Prototypical Cross-domain Knowledge Transfer for Cervical Dysplasia Visual Inspection
Aug 19, 2023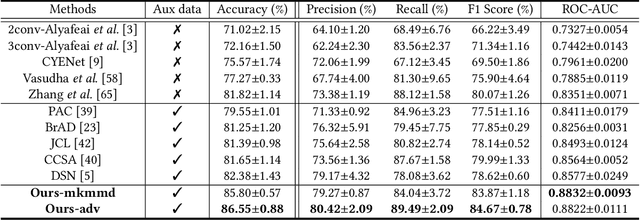
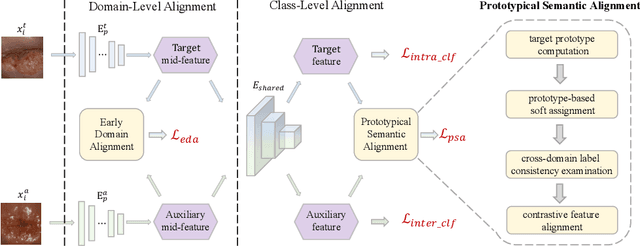
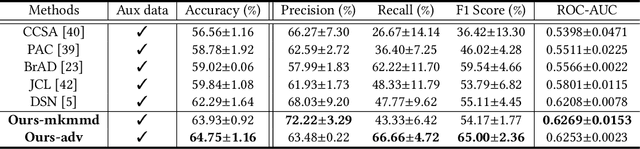
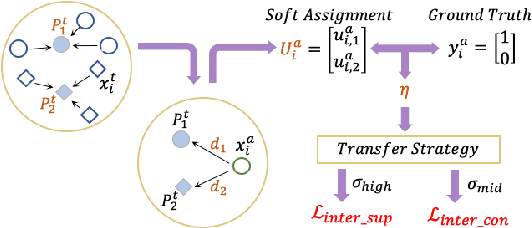
Early detection of dysplasia of the cervix is critical for cervical cancer treatment. However, automatic cervical dysplasia diagnosis via visual inspection, which is more appropriate in low-resource settings, remains a challenging problem. Though promising results have been obtained by recent deep learning models, their performance is significantly hindered by the limited scale of the available cervix datasets. Distinct from previous methods that learn from a single dataset, we propose to leverage cross-domain cervical images that were collected in different but related clinical studies to improve the model's performance on the targeted cervix dataset. To robustly learn the transferable information across datasets, we propose a novel prototype-based knowledge filtering method to estimate the transferability of cross-domain samples. We further optimize the shared feature space by aligning the cross-domain image representations simultaneously on domain level with early alignment and class level with supervised contrastive learning, which endows model training and knowledge transfer with stronger robustness. The empirical results on three real-world benchmark cervical image datasets show that our proposed method outperforms the state-of-the-art cervical dysplasia visual inspection by an absolute improvement of 4.7% in top-1 accuracy, 7.0% in precision, 1.4% in recall, 4.6% in F1 score, and 0.05 in ROC-AUC.
Practical Anomaly Detection over Multivariate Monitoring Metrics for Online Services
Aug 19, 2023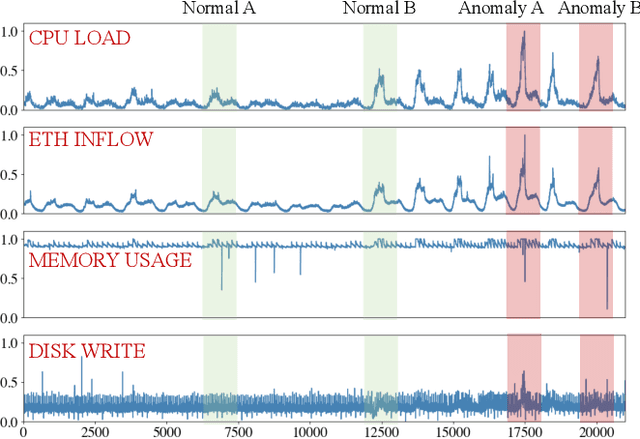
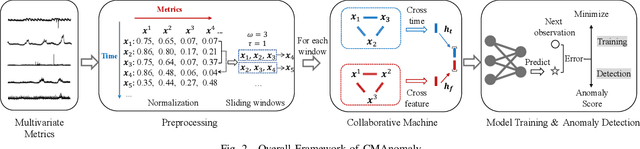
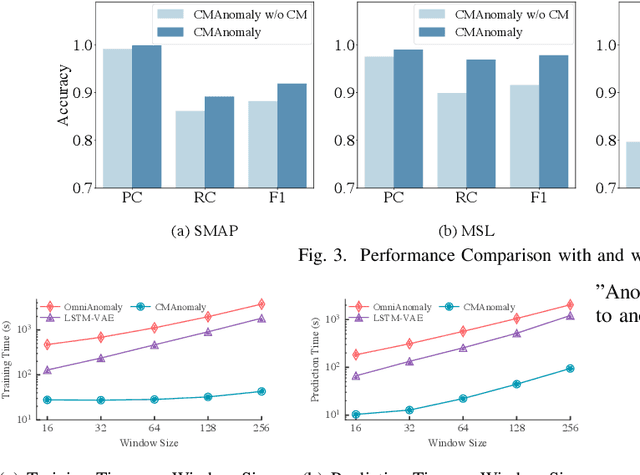
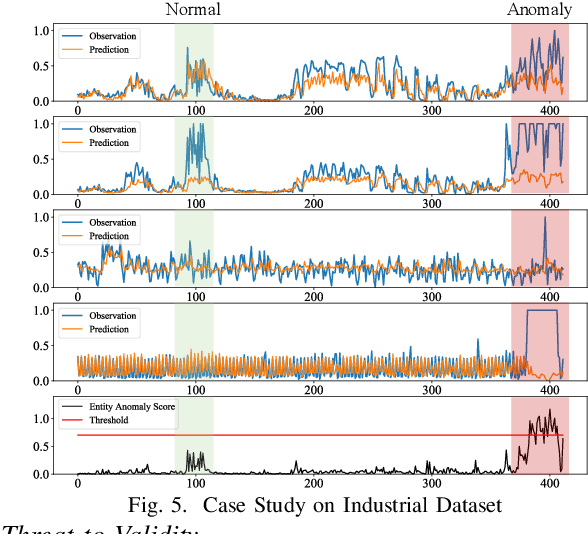
As modern software systems continue to grow in terms of complexity and volume, anomaly detection on multivariate monitoring metrics, which profile systems' health status, becomes more and more critical and challenging. In particular, the dependency between different metrics and their historical patterns plays a critical role in pursuing prompt and accurate anomaly detection. Existing approaches fall short of industrial needs for being unable to capture such information efficiently. To fill this significant gap, in this paper, we propose CMAnomaly, an anomaly detection framework on multivariate monitoring metrics based on collaborative machine. The proposed collaborative machine is a mechanism to capture the pairwise interactions along with feature and temporal dimensions with linear time complexity. Cost-effective models can then be employed to leverage both the dependency between monitoring metrics and their historical patterns for anomaly detection. The proposed framework is extensively evaluated with both public data and industrial data collected from a large-scale online service system of Huawei Cloud. The experimental results demonstrate that compared with state-of-the-art baseline models, CMAnomaly achieves an average F1 score of 0.9494, outperforming baselines by 6.77% to 10.68%, and runs 10X to 20X faster. Furthermore, we also share our experience of deploying CMAnomaly in Huawei Cloud.
Physics-Guided Human Motion Capture with Pose Probability Modeling
Aug 19, 2023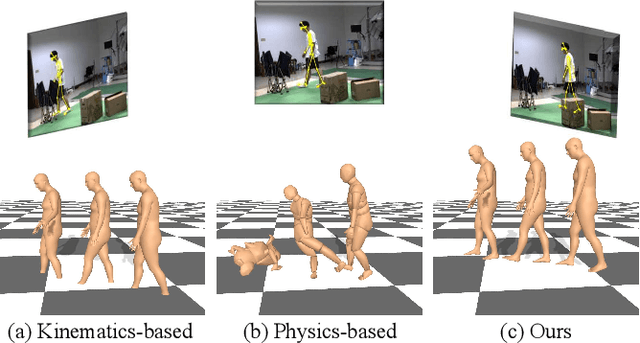

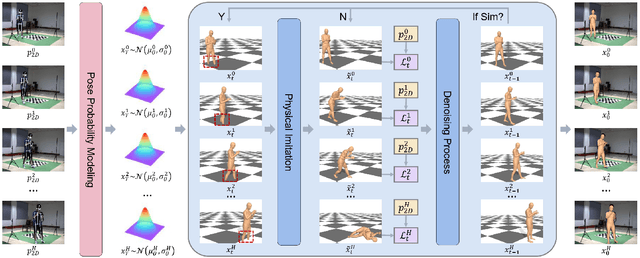

Incorporating physics in human motion capture to avoid artifacts like floating, foot sliding, and ground penetration is a promising direction. Existing solutions always adopt kinematic results as reference motions, and the physics is treated as a post-processing module. However, due to the depth ambiguity, monocular motion capture inevitably suffers from noises, and the noisy reference often leads to failure for physics-based tracking. To address the obstacles, our key-idea is to employ physics as denoising guidance in the reverse diffusion process to reconstruct physically plausible human motion from a modeled pose probability distribution. Specifically, we first train a latent gaussian model that encodes the uncertainty of 2D-to-3D lifting to facilitate reverse diffusion. Then, a physics module is constructed to track the motion sampled from the distribution. The discrepancies between the tracked motion and image observation are used to provide explicit guidance for the reverse diffusion model to refine the motion. With several iterations, the physics-based tracking and kinematic denoising promote each other to generate a physically plausible human motion. Experimental results show that our method outperforms previous physics-based methods in both joint accuracy and success rate. More information can be found at \url{https://github.com/Me-Ditto/Physics-Guided-Mocap}.