 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extracting Relational Triples Based on Graph Recursive Neural Network via Dynamic Feedback Forest Algorithm
Aug 22, 2023
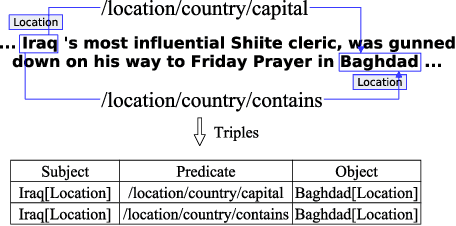
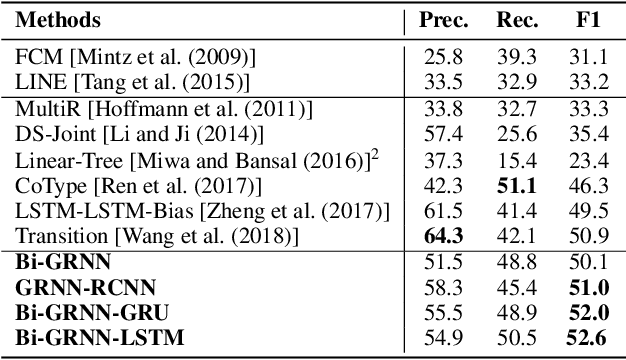
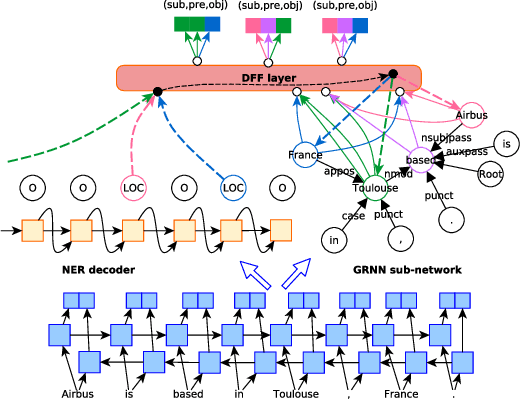
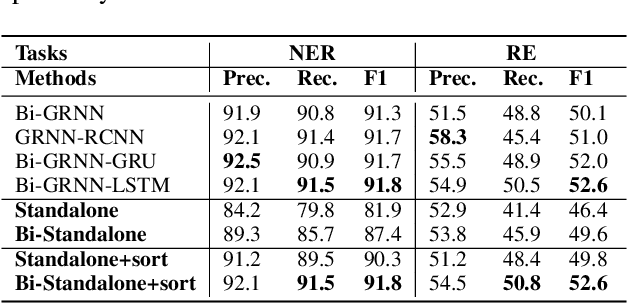
Extracting relational triples (subject, predicate, object) from text enables the transformation of unstructured text data into structured knowledge. The named entity recognition (NER) and the relation extraction (RE) are two foundational subtasks in this knowledge generation pipeline. The integration of subtasks poses a considerable challenge due to their disparate nature. This paper presents a novel approach that converts the triple extraction task into a graph labeling problem, capitalizing on the structural information of dependency parsing and graph recursive neural networks (GRNNs). To integrate subtasks, this paper proposes a dynamic feedback forest algorithm that connects the representations of subtasks by inference operations during model training. Experimental results demonstrate the effectiveness of the proposed method.
On quantum backpropagation, information reuse, and cheating measurement collapse
May 22, 2023
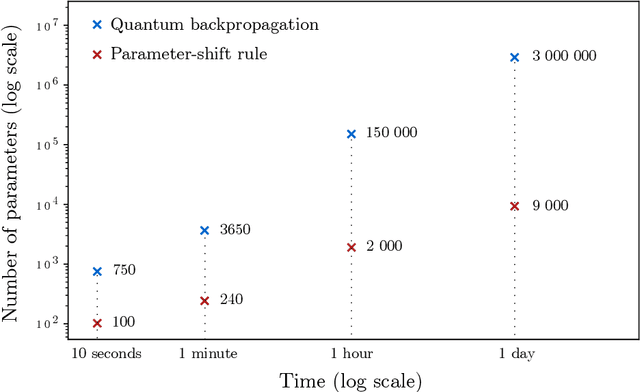
The success of modern deep learning hinges on the ability to train neural networks at scale. Through clever reuse of intermediate information, backpropagation facilitates training through gradient computation at a total cost roughly proportional to running the function, rather than incurring an additional factor proportional to the number of parameters - which can now be in the trillions. Naively, one expects that quantum measurement collapse entirely rules out the reuse of quantum information as in backpropagation. But recent developments in shadow tomography, which assumes access to multiple copies of a quantum state, have challenged that notion. Here, we investigate whether parameterized quantum models can train as efficiently as classical neural networks. We show that achieving backpropagation scaling is impossible without access to multiple copies of a state. With this added ability, we introduce an algorithm with foundations in shadow tomography that matches backpropagation scaling in quantum resources while reducing classical auxiliary computational costs to open problems in shadow tomography. These results highlight the nuance of reusing quantum information for practical purposes and clarify the unique difficulties in training large quantum models, which could alter the course of quantum machine learning.
NevIR: Negation in Neural Information Retrieval
May 12, 2023
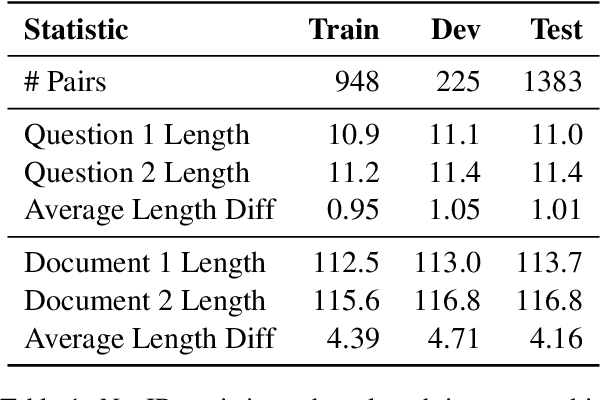
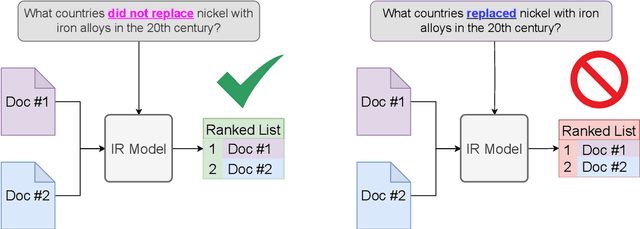
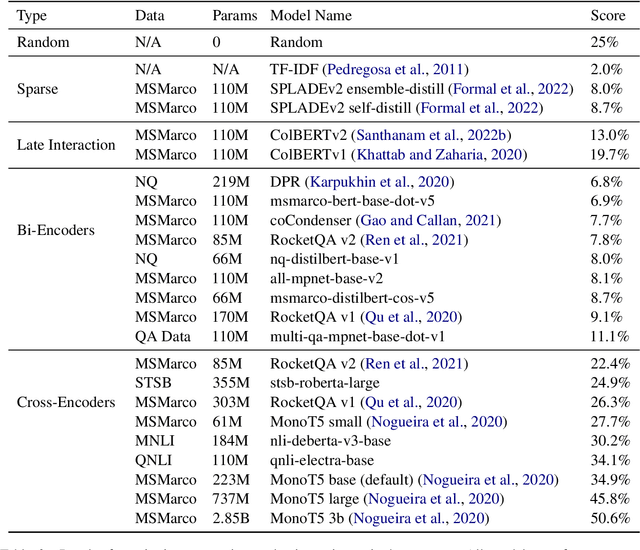
Negation is a common everyday phenomena and has been a consistent area of weakness for language models (LMs). Although the Information Retrieval (IR) community has adopted LMs as the backbone of modern IR architectures, there has been little to no research in understanding how negation impacts neural IR. We therefore construct a straightforward benchmark on this theme: asking IR models to rank two documents that differ only by negation. We show that the results vary widely according to the type of IR architecture: cross-encoders perform best, followed by late-interaction models, and in last place are bi-encoder and sparse neural architectures. We find that most current information retrieval models do not consider negation, performing similarly or worse than randomly ranking. We show that although the obvious approach of continued fine-tuning on a dataset of contrastive documents containing negations increases performance (as does model size), there is still a large gap between machine and human performance.
Fair Information Spread on Social Networks with Community Structure
May 15, 2023
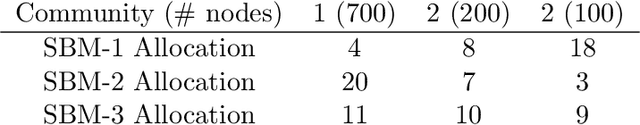
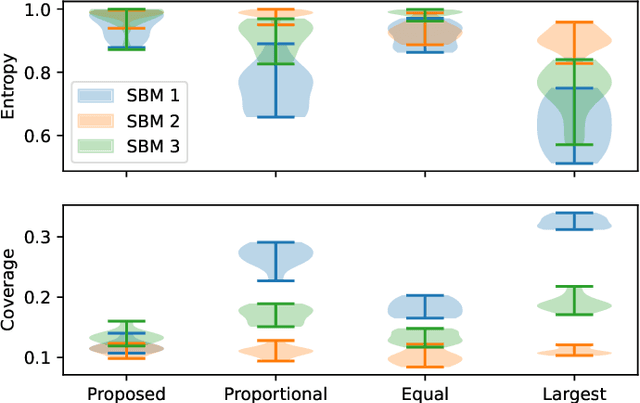

Information spread through social networks is ubiquitous. Influence maximiza- tion (IM) algorithms aim to identify individuals who will generate the greatest spread through the social network if provided with information, and have been largely devel- oped with marketing in mind. In social networks with community structure, which are very common, IM algorithms focused solely on maximizing spread may yield signifi- cant disparities in information coverage between communities, which is problematic in settings such as public health messaging. While some IM algorithms aim to remedy disparity in information coverage using node attributes, none use the empirical com- munity structure within the network itself, which may be beneficial since communities directly affect the spread of information. Further, the use of empirical network struc- ture allows us to leverage community detection techniques, making it possible to run fair-aware algorithms when there are no relevant node attributes available, or when node attributes do not accurately capture network community structure. In contrast to other fair IM algorithms, this work relies on fitting a model to the social network which is then used to determine a seed allocation strategy for optimal fair information spread. We develop an algorithm to determine optimal seed allocations for expected fair coverage, defined through maximum entropy, provide some theoretical guarantees under appropriate conditions, and demonstrate its empirical accuracy on both simu- lated and real networks. Because this algorithm relies on a fitted network model and not on the network directly, it is well-suited for partially observed and noisy social networks.
Measure of Uncertainty in Human Emotions
Aug 08, 2023
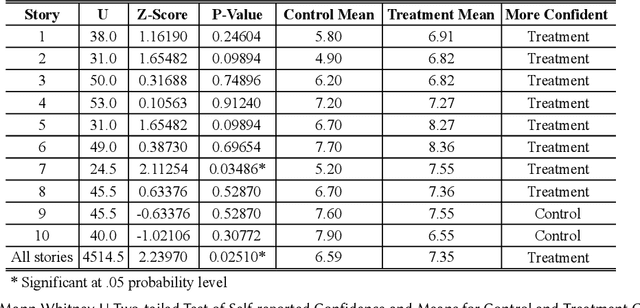


Many research explore how well computers are able to examine emotions displayed by humans and use that data to perform different tasks. However, there have been very few research which evaluate the computers ability to generate emotion classification information in an attempt to help the user make decisions or perform tasks. This is a crucial area to explore as it is paramount to the two way communication between humans and computers. This research conducted an experiment to investigate the impact of different uncertainty information displays of emotion classification on the human decision making process. Results show that displaying more uncertainty information can help users to be more confident when making decisions.
Near-Field 3D Localization via MIMO Radar: Cramér-Rao Bound Analysis and Estimator Design
Aug 30, 2023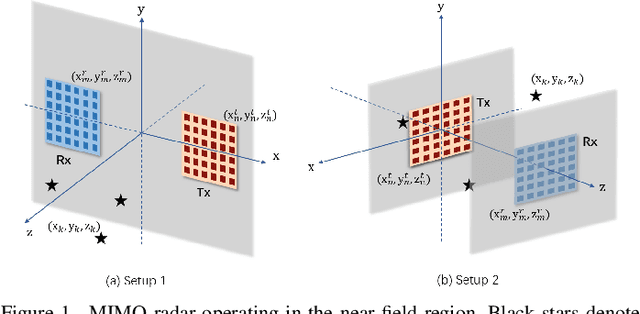
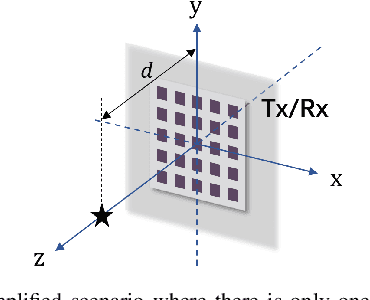
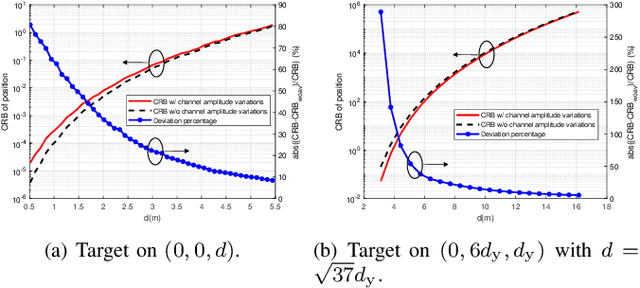
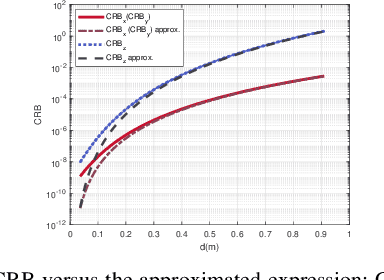
This paper studies a near-field multiple-input multiple-output (MIMO) radar sensing system, in which the transceivers with massive antennas aim to localize multiple near-field targets in the three-dimensional (3D) space over unknown cluttered environments. We consider a spherical wavefront propagation with both channel phase and amplitude variations over different antennas. Under this setup, the unknown parameters include the 3D coordinates and complex reflection coefficients of the targets, as well as the noise and interference covariance matrix. First, by considering general transmit signal waveforms, we derive the Fisher information matrix (FIM) corresponding to the 3D coordinates and the complex reflection coefficients of the targets and accordingly obtain the Cram\'er-Rao bound (CRB) for the 3D coordinates. This provides a performance bound for 3D near-field target localization. For the special single-target case, we obtain the CRB in an analytical form, and analyze its asymptotic scaling behaviors with respect to the target distance and antenna size of the transceiver. Next, to facilitate practical localization, we propose two estimators to localize targets based on the maximum likelihood (ML) criterion, namely the 3D approximate cyclic optimization (3D-ACO) and the 3D cyclic optimization with white Gaussian noise (3D-CO-WGN), respectively. Numerical results validate the asymptotic CRB analysis and show that the consideration of varying channel amplitudes is vital to achieve accurate CRB and localization when the targets are close to the transceivers. It is also shown that the proposed estimators achieve localization performance close to the derived CRB under various cluttered environments, thus validating their effectiveness in practical implementation. Furthermore, it is shown that transmit waveforms have a significant impact on CRB and the localization performance.
Anti-Jamming Precoding Against Disco Intelligent Reflecting Surfaces Based Fully-Passive Jamming Attacks
Aug 30, 2023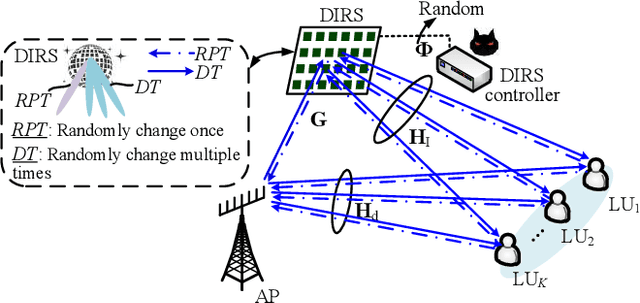
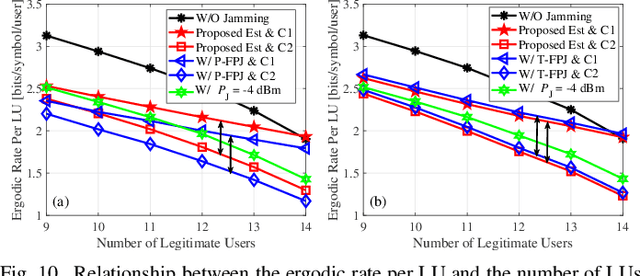
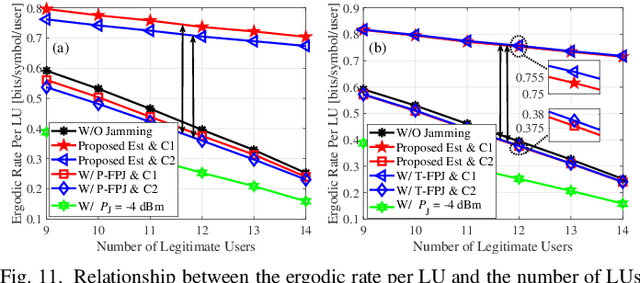
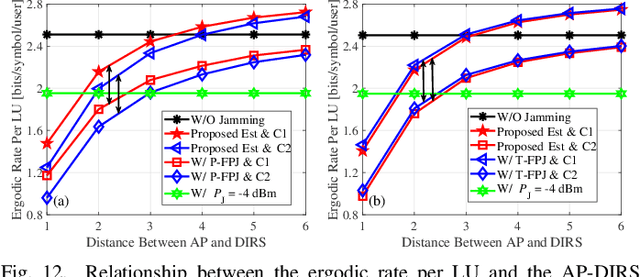
Emerging intelligent reflecting surfaces (IRSs) significantly improve system performance, but also pose a huge risk for physical layer security. Existing works have illustrated that a disco IRS (DIRS), i.e., an illegitimate IRS with random time-varying reflection properties (like a "disco ball"), can be employed by an attacker to actively age the channels of legitimate users (LUs). Such active channel aging (ACA) generated by the DIRS can be employed to jam multi-user multiple-input single-output (MU-MISO) systems without relying on either jamming power or LU channel state information (CSI). To address the significant threats posed by DIRS-based fully-passive jammers (FPJs), an anti-jamming precoder is proposed that requires only the statistical characteristics of the DIRS-based ACA channels instead of their CSI. The statistical characteristics of DIRS-jammed channels are first derived, and then the anti-jamming precoder is derived based on the statistical characteristics. Furthermore, we prove that the anti-jamming precoder can achieve the maximum signal-to-jamming-plus-noise ratio (SJNR). To acquire the ACA statistics without changing the system architecture or cooperating with the illegitimate DIRS, we design a data frame structure that the legitimate access point (AP) can use to estimate the statistical characteristics. During the designed data frame, the LUs only need to feed back their received power to the legitimate AP when they detect jamming attacks. Numerical results are also presented to evaluate the effectiveness of the proposed anti-jamming precoder against the DIRS-based FPJs and the feasibility of the designed data frame used by the legitimate AP to estimate the statistical characteristics.
MELT: Mining Effective Lightweight Transformations from Pull Requests
Aug 28, 2023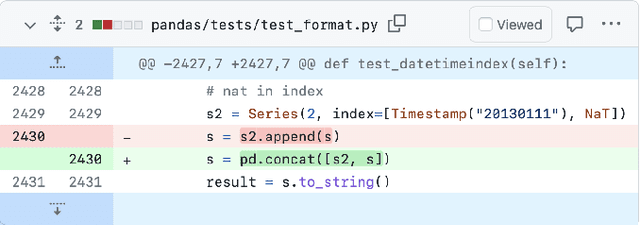
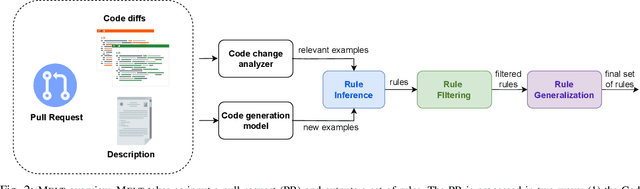

Software developers often struggle to update APIs, leading to manual, time-consuming, and error-prone processes. We introduce MELT, a new approach that generates lightweight API migration rules directly from pull requests in popular library repositories. Our key insight is that pull requests merged into open-source libraries are a rich source of information sufficient to mine API migration rules. By leveraging code examples mined from the library source and automatically generated code examples based on the pull requests, we infer transformation rules in \comby, a language for structural code search and replace. Since inferred rules from single code examples may be too specific, we propose a generalization procedure to make the rules more applicable to client projects. MELT rules are syntax-driven, interpretable, and easily adaptable. Moreover, unlike previous work, our approach enables rule inference to seamlessly integrate into the library workflow, removing the need to wait for client code migrations. We evaluated MELT on pull requests from four popular libraries, successfully mining 461 migration rules from code examples in pull requests and 114 rules from auto-generated code examples. Our generalization procedure increases the number of matches for mined rules by 9x. We applied these rules to client projects and ran their tests, which led to an overall decrease in the number of warnings and fixing some test cases demonstrating MELT's effectiveness in real-world scenarios.
ANER: Arabic and Arabizi Named Entity Recognition using Transformer-Based Approach
Aug 28, 2023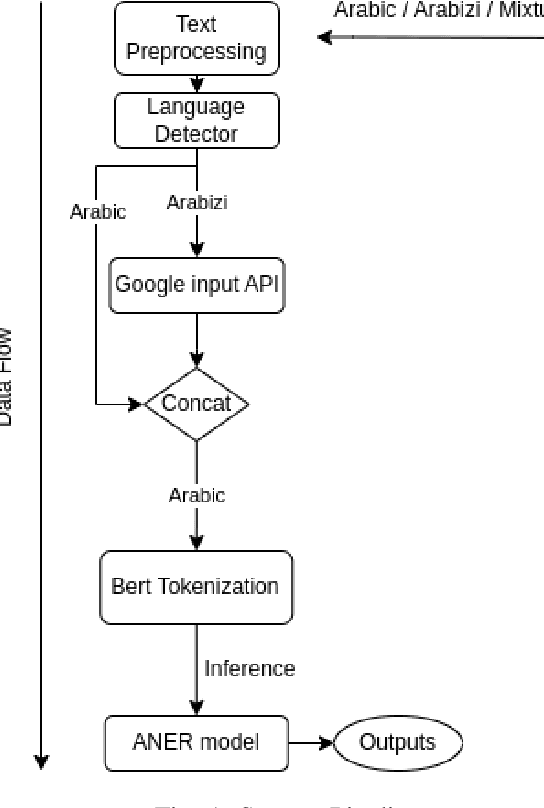
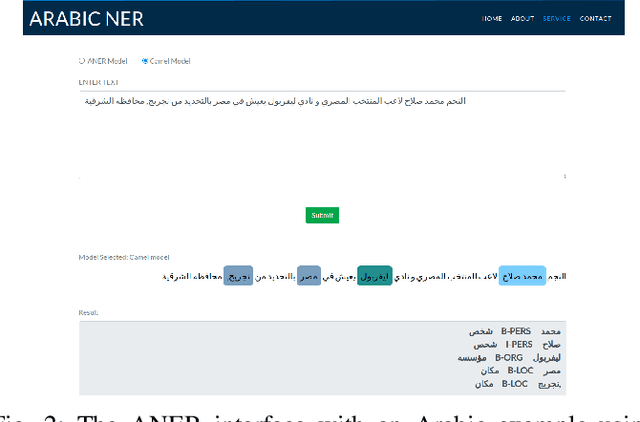
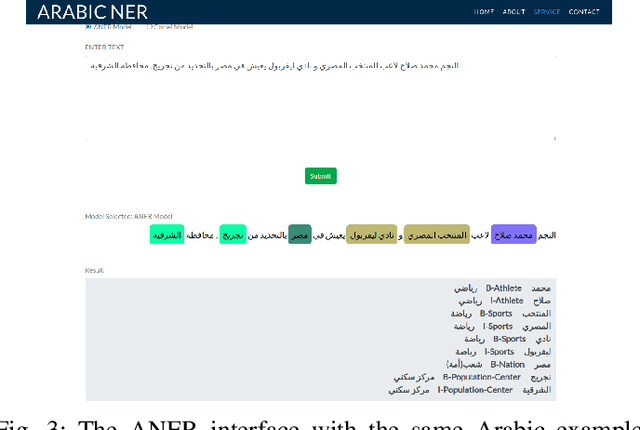
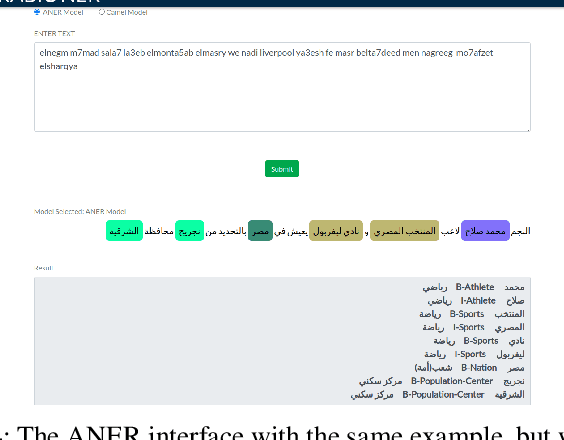
One of the main tasks of Natural Language Processing (NLP), is Named Entity Recognition (NER). It is used in many applications and also can be used as an intermediate step for other tasks. We present ANER, a web-based named entity recognizer for the Arabic, and Arabizi languages. The model is built upon BERT, which is a transformer-based encoder. It can recognize 50 different entity classes, covering various fields. We trained our model on the WikiFANE\_Gold dataset which consists of Wikipedia articles. We achieved an F1 score of 88.7\%, which beats CAMeL Tools' F1 score of 83\% on the ANERcorp dataset, which has only 4 classes. We also got an F1 score of 77.7\% on the NewsFANE\_Gold dataset which contains out-of-domain data from News articles. The system is deployed on a user-friendly web interface that accepts users' inputs in Arabic, or Arabizi. It allows users to explore the entities in the text by highlighting them. It can also direct users to get information about entities through Wikipedia directly. We added the ability to do NER using our model, or CAMeL Tools' model through our website. ANER is publicly accessible at \url{http://www.aner.online}. We also deployed our model on HuggingFace at https://huggingface.co/boda/ANER, to allow developers to test and use it.
Direct initial orbit determination
Aug 28, 2023Initial orbit determination (IOD) is an important early step in the processing chain that makes sense of and reconciles the multiple optical observations of a resident space object. IOD methods generally operate on line-of-sight (LOS) vectors extracted from images of the object, hence the LOS vectors can be seen as discrete point samples of the raw optical measurements. Typically, the number of LOS vectors used by an IOD method is much smaller than the available measurements (\ie, the set of pixel intensity values), hence current IOD methods arguably under-utilize the rich information present in the data. In this paper, we propose a \emph{direct} IOD method called D-IOD that fits the orbital parameters directly on the observed streak images, without requiring LOS extraction. Since it does not utilize LOS vectors, D-IOD avoids potential inaccuracies or errors due to an imperfect LOS extraction step. Two innovations underpin our novel orbit-fitting paradigm: first, we introduce a novel non-linear least-squares objective function that computes the loss between the candidate-orbit-generated streak images and the observed streak images. Second, the objective function is minimized with a gradient descent approach that is embedded in our proposed optimization strategies designed for streak images. We demonstrate the effectiveness of D-IOD on a variety of simulated scenarios and challenging real streak images.