 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponential quantum advantage in processing massive classical data
Apr 08, 2026Broadly applicable quantum advantage, particularly in classical data processing and machine learning, has been a fundamental open problem. In this work, we prove that a small quantum computer of polylogarithmic size can perform large-scale classification and dimension reduction on massive classical data by processing samples on the fly, whereas any classical machine achieving the same prediction performance requires exponentially larger size. Furthermore, classical machines that are exponentially larger yet below the required size need superpolynomially more samples and time. We validate these quantum advantages in real-world applications, including single-cell RNA sequencing and movie review sentiment analysis, demonstrating four to six orders of magnitude reduction in size with fewer than 60 logical qubits. These quantum advantages are enabled by quantum oracle sketching, an algorithm for accessing the classical world in quantum superposition using only random classical data samples. Combined with classical shadows, our algorithm circumvents the data loading and readout bottleneck to construct succinct classical models from massive classical data, a task provably impossible for any classical machine that is not exponentially larger than the quantum machine. These quantum advantages persist even when classical machines are granted unlimited time or if BPP=BQP, and rely only on the correctness of quantum mechanics. Together, our results establish machine learning on classical data as a broad and natural domain of quantum advantage and a fundamental test of quantum mechanics at the complexity frontier.
Generative quantum advantage for classical and quantum problems
Sep 10, 2025Recent breakthroughs in generative machine learning, powered by massive computational resources, have demonstrated unprecedented human-like capabilities. While beyond-classical quantum experiments can generate samples from classically intractable distributions, their complexity has thwarted all efforts toward efficient learning. This challenge has hindered demonstrations of generative quantum advantage: the ability of quantum computers to learn and generate desired outputs substantially better than classical computers. We resolve this challenge by introducing families of generative quantum models that are hard to simulate classically, are efficiently trainable, exhibit no barren plateaus or proliferating local minima, and can learn to generate distributions beyond the reach of classical computers. Using a $68$-qubit superconducting quantum processor, we demonstrate these capabilities in two scenarios: learning classically intractable probability distributions and learning quantum circuits for accelerated physical simulation. Our results establish that both learning and sampling can be performed efficiently in the beyond-classical regime, opening new possibilities for quantum-enhanced generative models with provable advantage.
Quantum advantage for learning shallow neural networks with natural data distributions
Mar 26, 2025The application of quantum computers to machine learning tasks is an exciting potential direction to explore in search of quantum advantage. In the absence of large quantum computers to empirically evaluate performance, theoretical frameworks such as the quantum probably approximately correct (PAC) and quantum statistical query (QSQ) models have been proposed to study quantum algorithms for learning classical functions. Despite numerous works investigating quantum advantage in these models, we nevertheless only understand it at two extremes: either exponential quantum advantages for uniform input distributions or no advantage for potentially adversarial distributions. In this work, we study the gap between these two regimes by designing an efficient quantum algorithm for learning periodic neurons in the QSQ model over a broad range of non-uniform distributions, which includes Gaussian, generalized Gaussian, and logistic distributions. To our knowledge, our work is also the first result in quantum learning theory for classical functions that explicitly considers real-valued functions. Recent advances in classical learning theory prove that learning periodic neurons is hard for any classical gradient-based algorithm, giving us an exponential quantum advantage over such algorithms, which are the standard workhorses of machine learning. Moreover, in some parameter regimes, the problem remains hard for classical statistical query algorithms and even general classical algorithms learning under small amounts of noise.
A Review of Barren Plateaus in Variational Quantum Computing
May 01, 2024Variational quantum computing offers a flexible computational paradigm with applications in diverse areas. However, a key obstacle to realizing their potential is the Barren Plateau (BP) phenomenon. When a model exhibits a BP, its parameter optimization landscape becomes exponentially flat and featureless as the problem size increases. Importantly, all the moving pieces of an algorithm -- choices of ansatz, initial state, observable, loss function and hardware noise -- can lead to BPs when ill-suited. Due to the significant impact of BPs on trainability, researchers have dedicated considerable effort to develop theoretical and heuristic methods to understand and mitigate their effects. As a result, the study of BPs has become a thriving area of research, influencing and cross-fertilizing other fields such as quantum optimal control, tensor networks, and learning theory. This article provides a comprehensive review of the current understanding of the BP phenomenon.
Learning shallow quantum circuits
Jan 18, 2024



Despite fundamental interests in learning quantum circuits, the existence of a computationally efficient algorithm for learning shallow quantum circuits remains an open question. Because shallow quantum circuits can generate distributions that are classically hard to sample from, existing learning algorithms do not apply. In this work, we present a polynomial-time classical algorithm for learning the description of any unknown $n$-qubit shallow quantum circuit $U$ (with arbitrary unknown architecture) within a small diamond distance using single-qubit measurement data on the output states of $U$. We also provide a polynomial-time classical algorithm for learning the description of any unknown $n$-qubit state $\lvert \psi \rangle = U \lvert 0^n \rangle$ prepared by a shallow quantum circuit $U$ (on a 2D lattice) within a small trace distance using single-qubit measurements on copies of $\lvert \psi \rangle$. Our approach uses a quantum circuit representation based on local inversions and a technique to combine these inversions. This circuit representation yields an optimization landscape that can be efficiently navigated and enables efficient learning of quantum circuits that are classically hard to simulate.
Exponential Quantum Communication Advantage in Distributed Learning
Oct 11, 2023



Training and inference with large machine learning models that far exceed the memory capacity of individual devices necessitates the design of distributed architectures, forcing one to contend with communication constraints. We present a framework for distributed computation over a quantum network in which data is encoded into specialized quantum states. We prove that for certain models within this framework, inference and training using gradient descent can be performed with exponentially less communication compared to their classical analogs, and with relatively modest time and space complexity overheads relative to standard gradient-based methods. To our knowledge, this is the first example of exponential quantum advantage for a generic class of machine learning problems with dense classical data that holds regardless of the data encoding cost. Moreover, we show that models in this class can encode highly nonlinear features of their inputs, and their expressivity increases exponentially with model depth. We also find that, interestingly, the communication advantage nearly vanishes for simpler linear classifiers. These results can be combined with natural privacy advantages in the communicated quantum states that limit the amount of information that can be extracted from them about the data and model parameters. Taken as a whole, these findings form a promising foundation for distributed machine learning over quantum networks.
On quantum backpropagation, information reuse, and cheating measurement collapse
May 22, 2023

The success of modern deep learning hinges on the ability to train neural networks at scale. Through clever reuse of intermediate information, backpropagation facilitates training through gradient computation at a total cost roughly proportional to running the function, rather than incurring an additional factor proportional to the number of parameters - which can now be in the trillions. Naively, one expects that quantum measurement collapse entirely rules out the reuse of quantum information as in backpropagation. But recent developments in shadow tomography, which assumes access to multiple copies of a quantum state, have challenged that notion. Here, we investigate whether parameterized quantum models can train as efficiently as classical neural networks. We show that achieving backpropagation scaling is impossible without access to multiple copies of a state. With this added ability, we introduce an algorithm with foundations in shadow tomography that matches backpropagation scaling in quantum resources while reducing classical auxiliary computational costs to open problems in shadow tomography. These results highlight the nuance of reusing quantum information for practical purposes and clarify the unique difficulties in training large quantum models, which could alter the course of quantum machine learning.
Revisiting dequantization and quantum advantage in learning tasks
Dec 06, 2021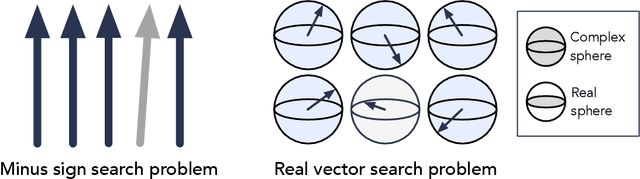
It has been shown that the apparent advantage of some quantum machine learning algorithms may be efficiently replicated using classical algorithms with suitable data access -- a process known as dequantization. Existing works on dequantization compare quantum algorithms which take copies of an n-qubit quantum state $|x\rangle = \sum_{i} x_i |i\rangle$ as input to classical algorithms which have sample and query (SQ) access to the vector $x$. In this note, we prove that classical algorithms with SQ access can accomplish some learning tasks exponentially faster than quantum algorithms with quantum state inputs. Because classical algorithms are a subset of quantum algorithms, this demonstrates that SQ access can sometimes be significantly more powerful than quantum state inputs. Our findings suggest that the absence of exponential quantum advantage in some learning tasks may be due to SQ access being too powerful relative to quantum state inputs. If we compare quantum algorithms with quantum state inputs to classical algorithms with access to measurement data on quantum states, the landscape of quantum advantage can be dramatically different. We remark that when the quantum states are constructed from exponential-size classical data, comparing SQ access and quantum state inputs is appropriate since both require exponential time to prepare.
Quantum advantage in learning from experiments
Dec 01, 2021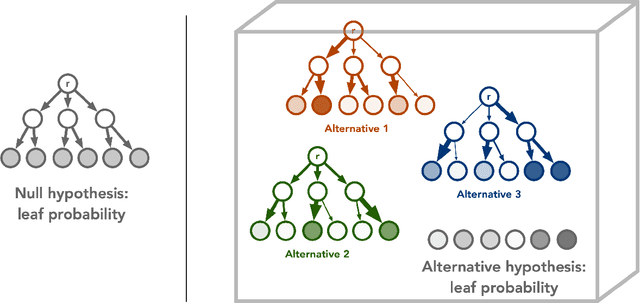

Quantum technology has the potential to revolutionize how we acquire and process experimental data to learn about the physical world. An experimental setup that transduces data from a physical system to a stable quantum memory, and processes that data using a quantum computer, could have significant advantages over conventional experiments in which the physical system is measured and the outcomes are processed using a classical computer. We prove that, in various tasks, quantum machines can learn from exponentially fewer experiments than those required in conventional experiments. The exponential advantage holds in predicting properties of physical systems, performing quantum principal component analysis on noisy states, and learning approximate models of physical dynamics. In some tasks, the quantum processing needed to achieve the exponential advantage can be modest; for example, one can simultaneously learn about many noncommuting observables by processing only two copies of the system. Conducting experiments with up to 40 superconducting qubits and 1300 quantum gates, we demonstrate that a substantial quantum advantage can be realized using today's relatively noisy quantum processors. Our results highlight how quantum technology can enable powerful new strategies to learn about nature.
Variational Quantum Algorithms
Dec 16, 2020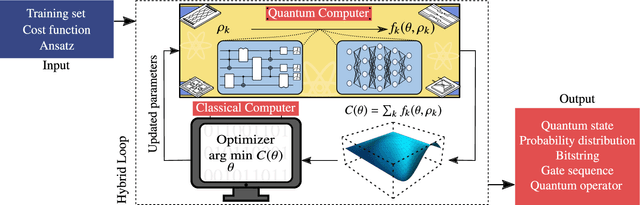
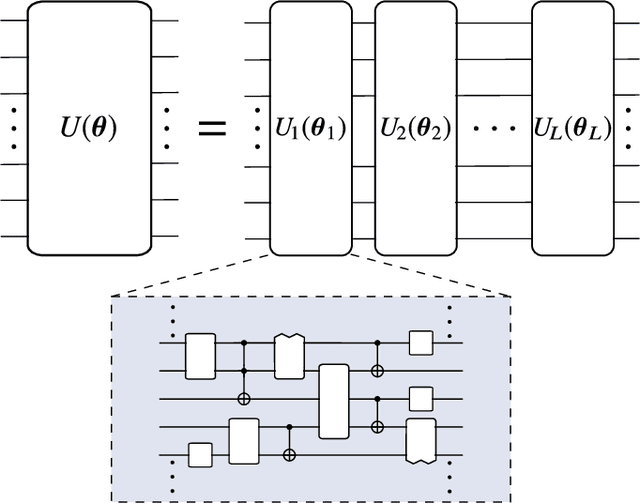
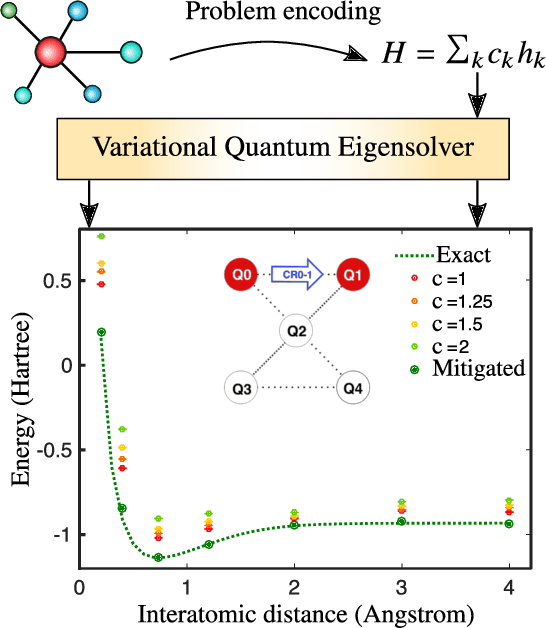
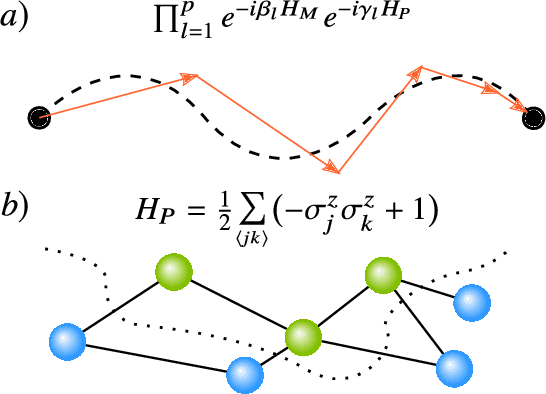
Applications such as simulating large quantum systems or solving large-scale linear algebra problems are immensely challenging for classical computers due their extremely high computational cost. Quantum computers promise to unlock these applications, although fault-tolerant quantum computers will likely not be available for several years. Currently available quantum devices have serious constraints, including limited qubit numbers and noise processes that limit circuit depth. Variational Quantum Algorithms (VQAs), which employ a classical optimizer to train a parametrized quantum circuit, have emerged as a leading strategy to address these constraints. VQAs have now been proposed for essentially all applications that researchers have envisioned for quantum computers, and they appear to the best hope for obtaining quantum advantage. Nevertheless, challenges remain including the trainability, accuracy, and efficiency of VQAs. In this review article we present an overview of the field of VQAs. Furthermore, we discuss strategies to overcome their challenges as well as the exciting prospects for using them as a means to obtain quantum advantage.