 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPELL: Synthesis of Programmatic Edits using LLMs
Feb 01, 2026Library migration is a common but error-prone task in software development. Developers may need to replace one library with another due to reasons like changing requirements or licensing changes. Migration typically entails updating and rewriting source code manually. While automated migration tools exist, most rely on mining examples from real-world projects that have already undergone similar migrations. However, these data are scarce, and collecting them for arbitrary pairs of libraries is difficult. Moreover, these migration tools often miss out on leveraging modern code transformation infrastructure. In this paper, we present a new approach to automated API migration that sidesteps the limitations described above. Instead of relying on existing migration data or using LLMs directly for transformation, we use LLMs to extract migration examples. Next, we use an Agent to generalize those examples to reusable transformation scripts in PolyglotPiranha, a modern code transformation tool. Our method distills latent migration knowledge from LLMs into structured, testable, and repeatable migration logic, without requiring preexisting corpora or manual engineering effort. Experimental results across Python libraries show that our system can generate diverse migration examples and synthesize transformation scripts that generalize to real-world codebases.
Exploring Large Protein Language Models in Constrained Evaluation Scenarios within the FLIP Benchmark
Jan 30, 2025



In this study, we expand upon the FLIP benchmark-designed for evaluating protein fitness prediction models in small, specialized prediction tasks-by assessing the performance of state-of-the-art large protein language models, including ESM-2 and SaProt on the FLIP dataset. Unlike larger, more diverse benchmarks such as ProteinGym, which cover a broad spectrum of tasks, FLIP focuses on constrained settings where data availability is limited. This makes it an ideal framework to evaluate model performance in scenarios with scarce task-specific data. We investigate whether recent advances in protein language models lead to significant improvements in such settings. Our findings provide valuable insights into the performance of large-scale models in specialized protein prediction tasks.
Are Large Language Models Memorizing Bug Benchmarks?
Nov 20, 2024



Large Language Models (LLMs) have become integral to various software engineering tasks, including code generation, bug detection, and repair. To evaluate model performance in these domains, numerous bug benchmarks containing real-world bugs from software projects have been developed. However, a growing concern within the software engineering community is that these benchmarks may not reliably reflect true LLM performance due to the risk of data leakage. Despite this concern, limited research has been conducted to quantify the impact of potential leakage. In this paper, we systematically evaluate popular LLMs to assess their susceptibility to data leakage from widely used bug benchmarks. To identify potential leakage, we use multiple metrics, including a study of benchmark membership within commonly used training datasets, as well as analyses of negative log-likelihood and n-gram accuracy. Our findings show that certain models, in particular codegen-multi, exhibit significant evidence of memorization in widely used benchmarks like Defects4J, while newer models trained on larger datasets like LLaMa 3.1 exhibit limited signs of leakage. These results highlight the need for careful benchmark selection and the adoption of robust metrics to adequately assess models capabilities.
Evaluating Posterior Probabilities: Decision Theory, Proper Scoring Rules, and Calibration
Aug 05, 2024



Most machine learning classifiers are designed to output posterior probabilities for the classes given the input sample. These probabilities may be used to make the categorical decision on the class of the sample; provided as input to a downstream system; or provided to a human for interpretation. Evaluating the quality of the posteriors generated by these system is an essential problem which was addressed decades ago with the invention of proper scoring rules (PSRs). Unfortunately, much of the recent machine learning literature uses calibration metrics -- most commonly, the expected calibration error (ECE) -- as a proxy to assess posterior performance. The problem with this approach is that calibration metrics reflect only one aspect of the quality of the posteriors, ignoring the discrimination performance. For this reason, we argue that calibration metrics should play no role in the assessment of posterior quality. Expected PSRs should instead be used for this job, preferably normalized for ease of interpretation. In this work, we first give a brief review of PSRs from a practical perspective, motivating their definition using Bayes decision theory. We discuss why expected PSRs provide a principled measure of the quality of a system's posteriors and why calibration metrics are not the right tool for this job. We argue that calibration metrics, while not useful for performance assessment, may be used as diagnostic tools during system development. With this purpose in mind, we discuss a simple and practical calibration metric, called calibration loss, derived from a decomposition of expected PSRs. We compare this metric with the ECE and with the expected score divergence calibration metric from the PSR literature and argue, using theoretical and empirical evidence, that calibration loss is superior to these two metrics.
MELT: Mining Effective Lightweight Transformations from Pull Requests
Aug 28, 2023



Software developers often struggle to update APIs, leading to manual, time-consuming, and error-prone processes. We introduce MELT, a new approach that generates lightweight API migration rules directly from pull requests in popular library repositories. Our key insight is that pull requests merged into open-source libraries are a rich source of information sufficient to mine API migration rules. By leveraging code examples mined from the library source and automatically generated code examples based on the pull requests, we infer transformation rules in \comby, a language for structural code search and replace. Since inferred rules from single code examples may be too specific, we propose a generalization procedure to make the rules more applicable to client projects. MELT rules are syntax-driven, interpretable, and easily adaptable. Moreover, unlike previous work, our approach enables rule inference to seamlessly integrate into the library workflow, removing the need to wait for client code migrations. We evaluated MELT on pull requests from four popular libraries, successfully mining 461 migration rules from code examples in pull requests and 114 rules from auto-generated code examples. Our generalization procedure increases the number of matches for mined rules by 9x. We applied these rules to client projects and ran their tests, which led to an overall decrease in the number of warnings and fixing some test cases demonstrating MELT's effectiveness in real-world scenarios.
Quality-Based Conditional Processing in Multi-Biometrics: Application to Sensor Interoperability
Nov 24, 2022



As biometric technology is increasingly deployed, it will be common to replace parts of operational systems with newer designs. The cost and inconvenience of reacquiring enrolled users when a new vendor solution is incorporated makes this approach difficult and many applications will require to deal with information from different sources regularly. These interoperability problems can dramatically affect the performance of biometric systems and thus, they need to be overcome. Here, we describe and evaluate the ATVS-UAM fusion approach submitted to the quality-based evaluation of the 2007 BioSecure Multimodal Evaluation Campaign, whose aim was to compare fusion algorithms when biometric signals were generated using several biometric devices in mismatched conditions. Quality measures from the raw biometric data are available to allow system adjustment to changing quality conditions due to device changes. This system adjustment is referred to as quality-based conditional processing. The proposed fusion approach is based on linear logistic regression, in which fused scores tend to be log-likelihood-ratios. This allows the easy and efficient combination of matching scores from different devices assuming low dependence among modalities. In our system, quality information is used to switch between different system modules depending on the data source (the sensor in our case) and to reject channels with low quality data during the fusion. We compare our fusion approach to a set of rule-based fusion schemes over normalized scores. Results show that the proposed approach outperforms all the rule-based fusion schemes. We also show that with the quality-based channel rejection scheme, an overall improvement of 25% in the equal error rate is obtained.
Adaptive Temperature Scaling for Robust Calibration of Deep Neural Networks
Jul 31, 2022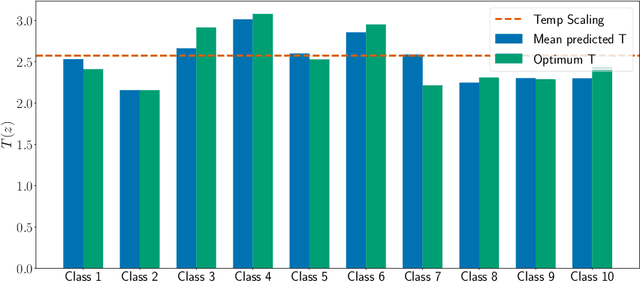
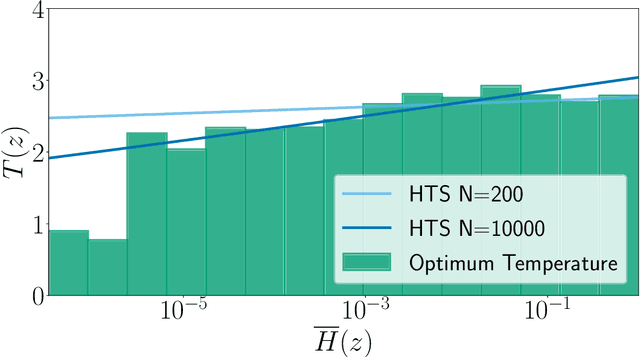
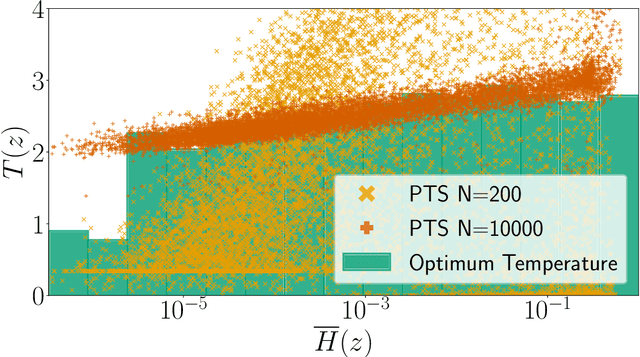
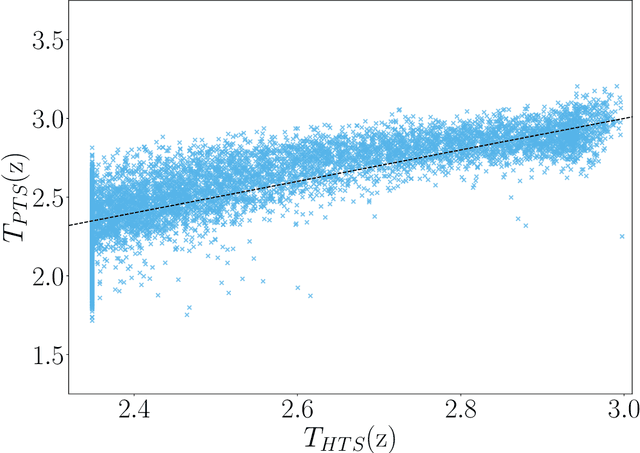
In this paper, we study the post-hoc calibration of modern neural networks, a problem that has drawn a lot of attention in recent years. Many calibration methods of varying complexity have been proposed for the task, but there is no consensus about how expressive these should be. We focus on the task of confidence scaling, specifically on post-hoc methods that generalize Temperature Scaling, we call these the Adaptive Temperature Scaling family. We analyse expressive functions that improve calibration and propose interpretable methods. We show that when there is plenty of data complex models like neural networks yield better performance, but are prone to fail when the amount of data is limited, a common situation in certain post-hoc calibration applications like medical diagnosis. We study the functions that expressive methods learn under ideal conditions and design simpler methods but with a strong inductive bias towards these well-performing functions. Concretely, we propose Entropy-based Temperature Scaling, a simple method that scales the confidence of a prediction according to its entropy. Results show that our method obtains state-of-the-art performance when compared to others and, unlike complex models, it is robust against data scarcity. Moreover, our proposed model enables a deeper interpretation of the calibration process.
BiosecurID: a multimodal biometric database
Nov 02, 2021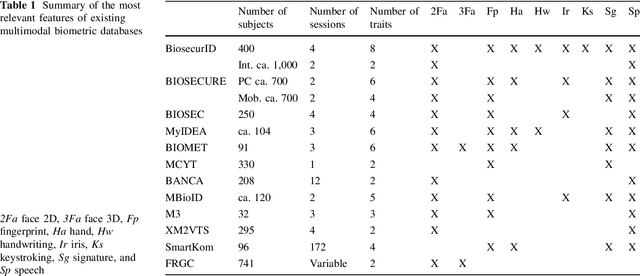

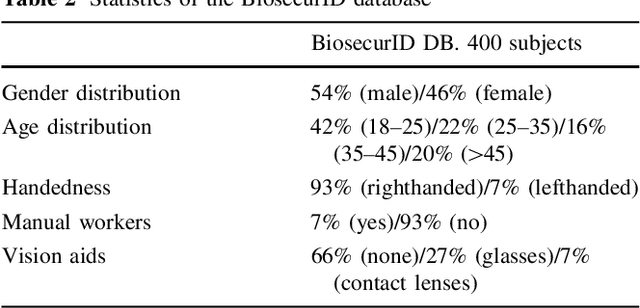
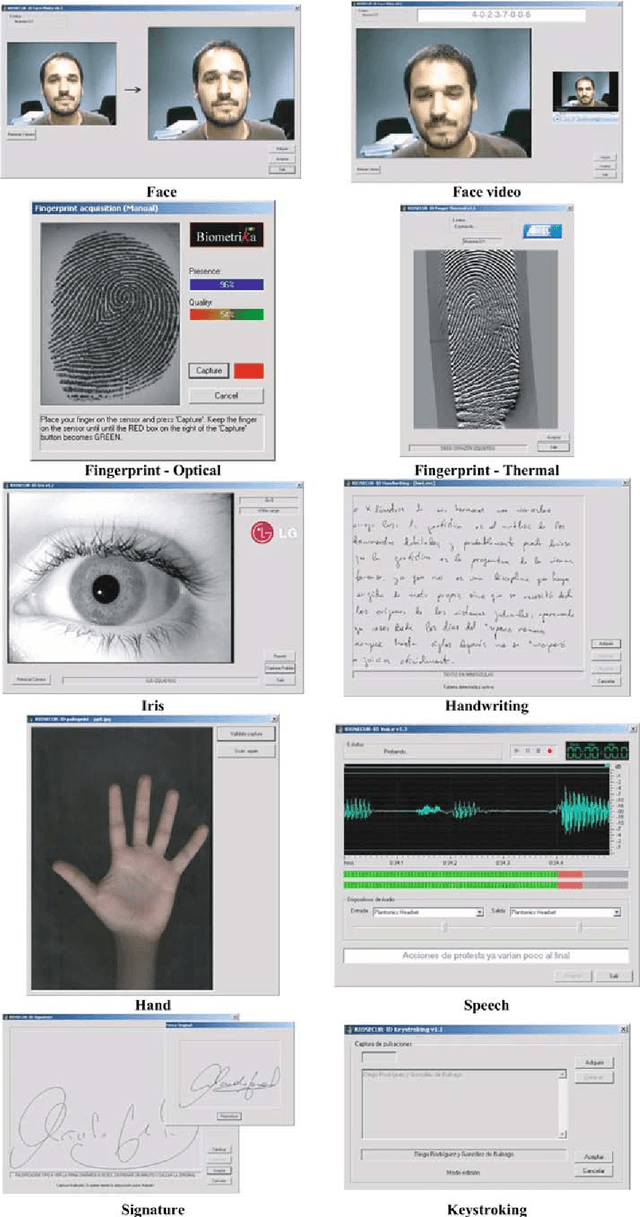
A new multimodal biometric database, acquired in the framework of the BiosecurID project, is presented together with the description of the acquisition setup and protocol. The database includes eight unimodal biometric traits, namely: speech, iris, face (still images, videos of talking faces), handwritten signature and handwritten text (on-line dynamic signals, off-line scanned images), fingerprints (acquired with two different sensors), hand (palmprint, contour-geometry) and keystroking. The database comprises 400 subjects and presents features such as: realistic acquisition scenario, balanced gender and population distributions, availability of information about particular demographic groups (age, gender, handedness), acquisition of replay attacks for speech and keystroking, skilled forgeries for signatures, and compatibility with other existing databases. All these characteristics make it very useful in research and development of unimodal and multimodal biometric systems.
Improving Calibration in Mixup-trained Deep Neural Networks through Confidence-Based Loss Functions
Apr 12, 2020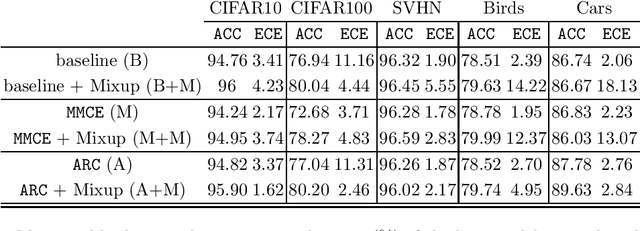
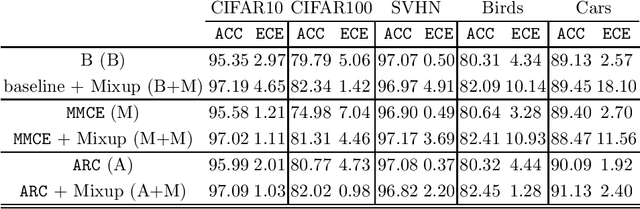
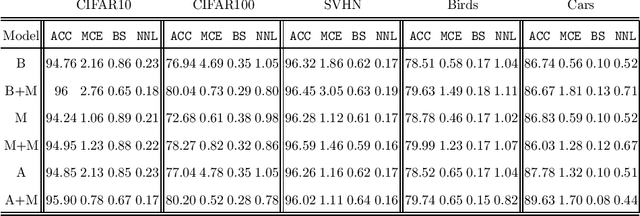
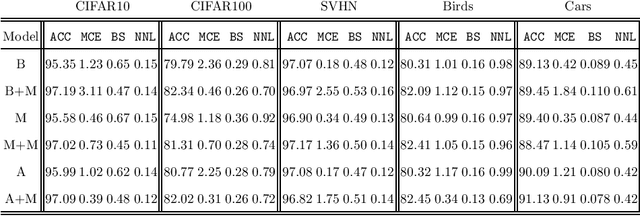
Deep Neural Networks (DNN) represent the state of the art in many tasks. However, due to their overparameterization, their generalization capabilities are in doubt and are still under study. Consequently, DNN can overfit and assign overconfident predictions, as they tend to learn highly oscillating decision thresholds. This has been shown to affect the calibration of the confidences assigned to unseen data. Data Augmentation (DA) strategies have been proposed to overcome some of these limitations. One of the most popular is Mixup, which has shown a great ability to improve the accuracy of these models. Recent work has provided evidence that Mixup also improves the uncertainty quantification and calibration of DNN. In this work, we argue and provide empirical evidence that, due to its fundamentals, Mixup does not necessarily improve calibration. Based on our observations we propose a new loss function that improves the calibration, and also sometimes the accuracy. Our loss is inspired by Bayes decision theory and introduces a new training framework for designing losses for probabilistic modelling. We provide state-of-the-art accuracy with consistent improvements in calibration performance.
Calibration of Deep Probabilistic Models with Decoupled Bayesian Neural Networks
Sep 25, 2019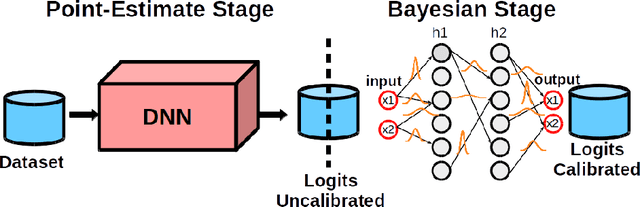
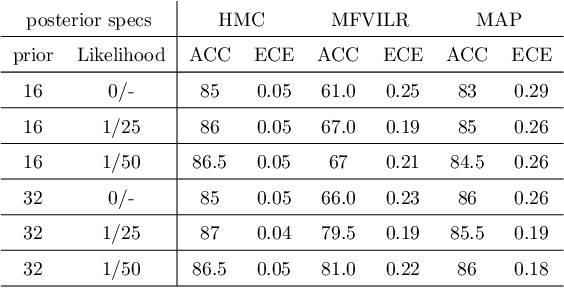
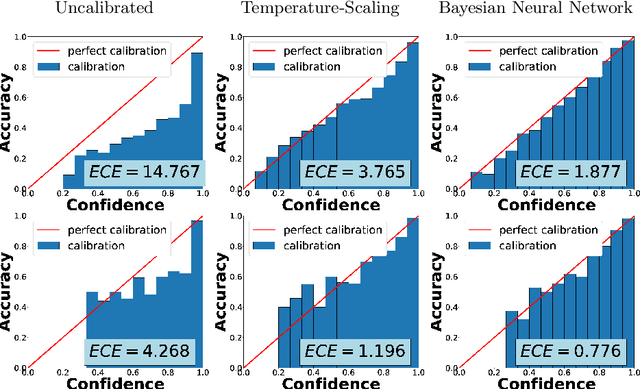
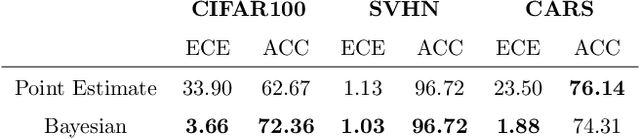
Deep Neural Networks (DNNs) have achieved state-of-the-art accuracy performance in many tasks. However, recent works have pointed out that the outputs provided by these models are not well-calibrated, seriously limiting their use in critical decision scenarios. In this work, we propose to use a decoupled Bayesian stage, implemented with a Bayesian Neural Network (BNN), to map the uncalibrated probabilities provided by a DNN to calibrated ones, consistently improving calibration. Our results evidence that incorporating uncertainty provides more reliable probabilistic models, a critical condition for achieving good calibration. We report a generous collection of experimental results using high-accuracy DNNs in standardized image classification benchmarks, showing the good performance, flexibility and robust behavior of our approach with respect to several state-of-the-art calibration methods. Code for reproducibility is provided.