 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Address Matching Based On Hierarchical Information
May 10, 2023
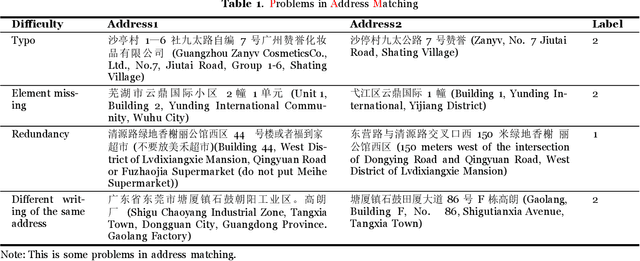
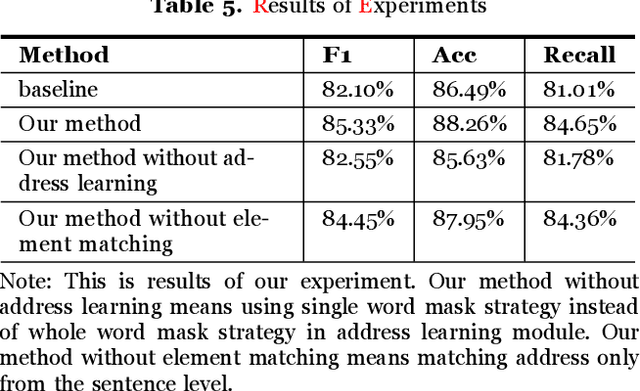
There is evidence that address matching plays a crucial role in many areas such as express delivery, online shopping and so on. Address has a hierarchical structure, in contrast to unstructured texts, which can contribute valuable information for address matching. Based on this idea, this paper proposes a novel method to leverage the hierarchical information in deep learning method that not only improves the ability of existing methods to handle irregular address, but also can pay closer attention to the special part of address. Experimental findings demonstrate that the proposed method improves the current approach by 3.2% points.
R-C-P Method: An Autonomous Volume Calculation Method Using Image Processing and Machine Vision
Aug 19, 2023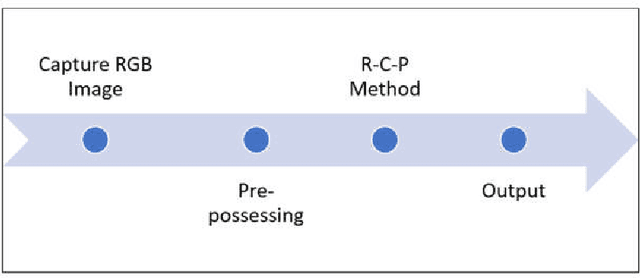
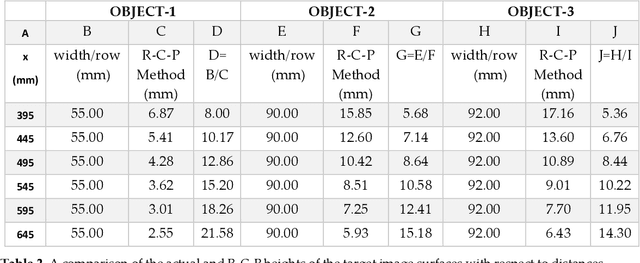

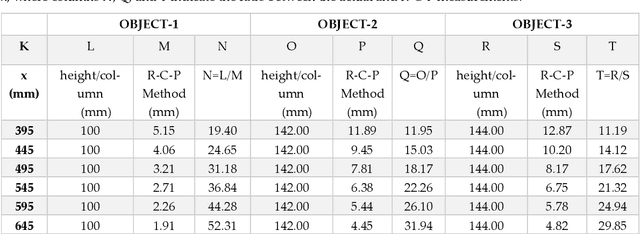
Machine vision and image processing are often used with sensors for situation awareness in autonomous systems, from industrial robots to self-driving cars. The 3D depth sensors, such as LiDAR (Light Detection and Ranging), Radar, are great invention for autonomous systems. Due to the complexity of the setup, LiDAR may not be suitable for some operational environments, for example, a space environment. This study was motivated by a desire to get real-time volumetric and change information with multiple 2D cameras instead of a depth camera. Two cameras were used to measure the dimensions of a rectangular object in real-time. The R-C-P (row-column-pixel) method is developed using image processing and edge detection. In addition to the surface areas, the R-C-P method also detects discontinuous edges or volumes. Lastly, experimental work is presented for illustration of the R-C-P method, which provides the equations for calculating surface area dimensions. Using the equations with given distance information between the object and the camera, the vision system provides the dimensions of actual objects.
LinkTransformer: A Unified Package for Record Linkage with Transformer Language Models
Sep 02, 2023Linking information across sources is fundamental to a variety of analyses in social science, business, and government. While large language models (LLMs) offer enormous promise for improving record linkage in noisy datasets, in many domains approximate string matching packages in popular softwares such as R and Stata remain predominant. These packages have clean, simple interfaces and can be easily extended to a diversity of languages. Our open-source package LinkTransformer aims to extend the familiarity and ease-of-use of popular string matching methods to deep learning. It is a general purpose package for record linkage with transformer LLMs that treats record linkage as a text retrieval problem. At its core is an off-the-shelf toolkit for applying transformer models to record linkage with four lines of code. LinkTransformer contains a rich repository of pre-trained transformer semantic similarity models for multiple languages and supports easy integration of any transformer language model from Hugging Face or OpenAI. It supports standard functionality such as blocking and linking on multiple noisy fields. LinkTransformer APIs also perform other common text data processing tasks, e.g., aggregation, noisy de-duplication, and translation-free cross-lingual linkage. Importantly, LinkTransformer also contains comprehensive tools for efficient model tuning, to facilitate different levels of customization when off-the-shelf models do not provide the required accuracy. Finally, to promote reusability, reproducibility, and extensibility, LinkTransformer makes it easy for users to contribute their custom-trained models to its model hub. By combining transformer language models with intuitive APIs that will be familiar to many users of popular string matching packages, LinkTransformer aims to democratize the benefits of LLMs among those who may be less familiar with deep learning frameworks.
Face Presentation Attack Detection by Excavating Causal Clues and Adapting Embedding Statistics
Aug 28, 2023

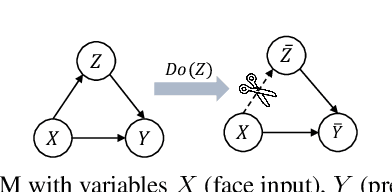

Recent face presentation attack detection (PAD) leverages domain adaptation (DA) and domain generalization (DG) techniques to address performance degradation on unknown domains. However, DA-based PAD methods require access to unlabeled target data, while most DG-based PAD solutions rely on a priori, i.e., known domain labels. Moreover, most DA-/DG-based methods are computationally intensive, demanding complex model architectures and/or multi-stage training processes. This paper proposes to model face PAD as a compound DG task from a causal perspective, linking it to model optimization. We excavate the causal factors hidden in the high-level representation via counterfactual intervention. Moreover, we introduce a class-guided MixStyle to enrich feature-level data distribution within classes instead of focusing on domain information. Both class-guided MixStyle and counterfactual intervention components introduce no extra trainable parameters and negligible computational resources. Extensive cross-dataset and analytic experiments demonstrate the effectiveness and efficiency of our method compared to state-of-the-art PADs. The implementation and the trained weights are publicly available.
GKGNet: Group K-Nearest Neighbor based Graph Convolutional Network for Multi-Label Image Recognition
Aug 28, 2023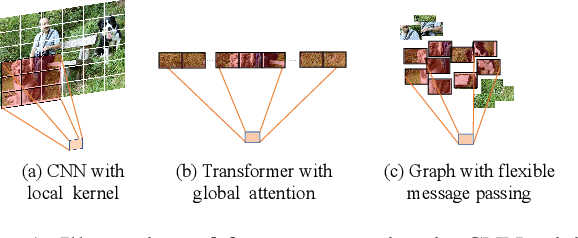
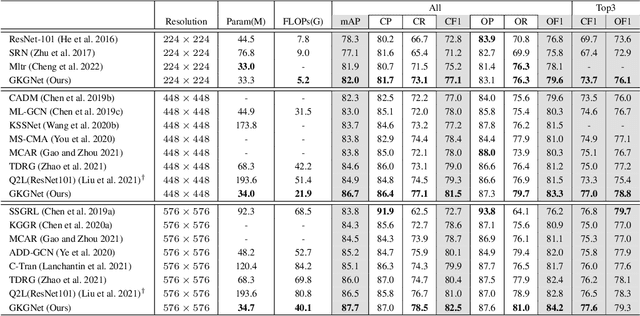
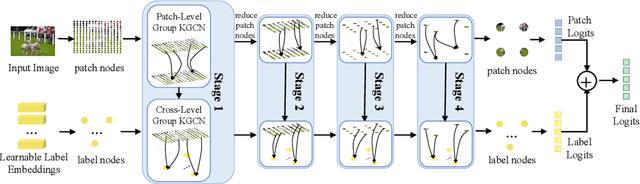

Multi-Label Image Recognition (MLIR) is a challenging task that aims to predict multiple object labels in a single image while modeling the complex relationships between labels and image regions. Although convolutional neural networks and vision transformers have succeeded in processing images as regular grids of pixels or patches, these representations are sub-optimal for capturing irregular and discontinuous regions of interest. In this work, we present the first fully graph convolutional model, Group K-nearest neighbor based Graph convolutional Network (GKGNet), which models the connections between semantic label embeddings and image patches in a flexible and unified graph structure. To address the scale variance of different objects and to capture information from multiple perspectives, we propose the Group KGCN module for dynamic graph construction and message passing. Our experiments demonstrate that GKGNet achieves state-of-the-art performance with significantly lower computational costs on the challenging multi-label datasets, \ie MS-COCO and VOC2007 datasets. We will release the code and models to facilitate future research in this area.
Buy when? Survival machine learning model comparison for purchase timing
Aug 28, 2023The value of raw data is unlocked by converting it into information and knowledge that drives decision-making. Machine Learning (ML) algorithms are capable of analysing large datasets and making accurate predictions. Market segmentation, client lifetime value, and marketing techniques have all made use of machine learning. This article examines marketing machine learning techniques such as Support Vector Machines, Genetic Algorithms, Deep Learning, and K-Means. ML is used to analyse consumer behaviour, propose items, and make other customer choices about whether or not to purchase a product or service, but it is seldom used to predict when a person will buy a product or a basket of products. In this paper, the survival models Kernel SVM, DeepSurv, Survival Random Forest, and MTLR are examined to predict tine-purchase individual decisions. Gender, Income, Location, PurchaseHistory, OnlineBehavior, Interests, PromotionsDiscounts and CustomerExperience all have an influence on purchasing time, according to the analysis. The study shows that the DeepSurv model predicted purchase completion the best. These insights assist marketers in increasing conversion rates.
EcomGPT: Instruction-tuning Large Language Models with Chain-of-Task Tasks for E-commerce
Aug 28, 2023
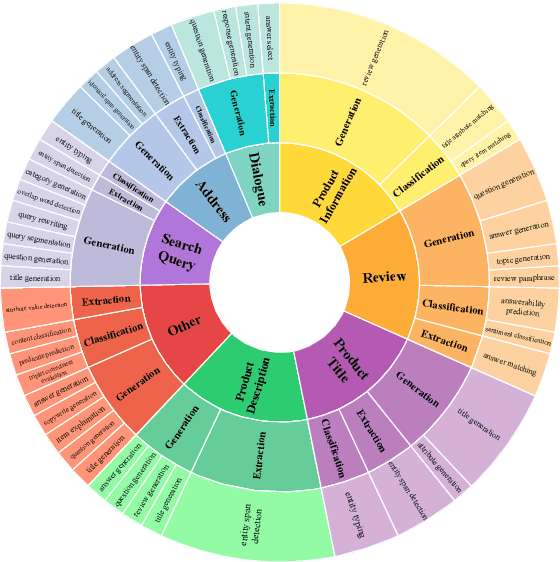
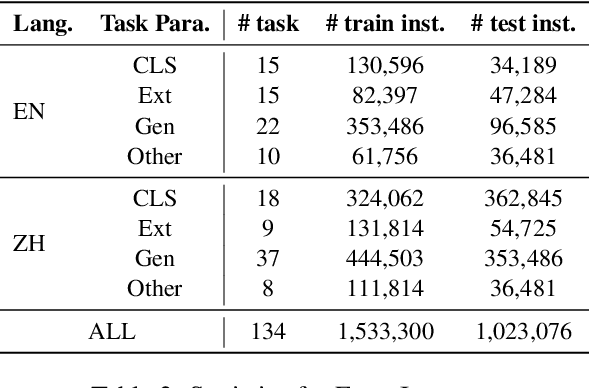
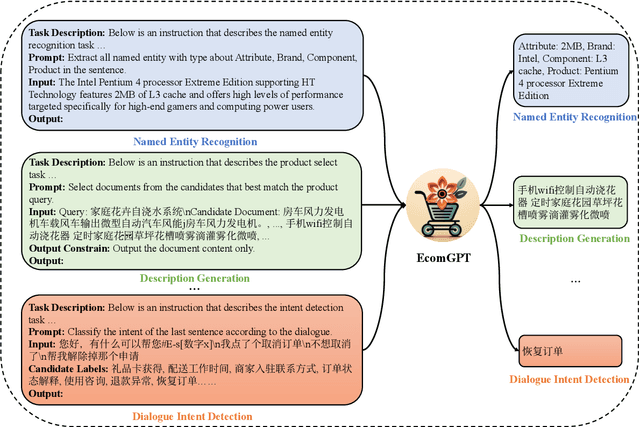
Recently, instruction-following Large Language Models (LLMs) , represented by ChatGPT, have exhibited exceptional performance in general Natural Language Processing (NLP) tasks. However, the unique characteristics of E-commerce data pose significant challenges to general LLMs. An LLM tailored specifically for E-commerce scenarios, possessing robust cross-dataset/task generalization capabilities, is a pressing necessity. To solve this issue, in this work, we proposed the first e-commerce instruction dataset EcomInstruct, with a total of 2.5 million instruction data. EcomInstruct scales up the data size and task diversity by constructing atomic tasks with E-commerce basic data types, such as product information, user reviews. Atomic tasks are defined as intermediate tasks implicitly involved in solving a final task, which we also call Chain-of-Task tasks. We developed EcomGPT with different parameter scales by training the backbone model BLOOMZ with the EcomInstruct. Benefiting from the fundamental semantic understanding capabilities acquired from the Chain-of-Task tasks, EcomGPT exhibits excellent zero-shot generalization capabilities. Extensive experiments and human evaluations demonstrate that EcomGPT outperforms ChatGPT in term of cross-dataset/task generalization on E-commerce tasks.
Voice Conversion with Denoising Diffusion Probabilistic GAN Models
Aug 28, 2023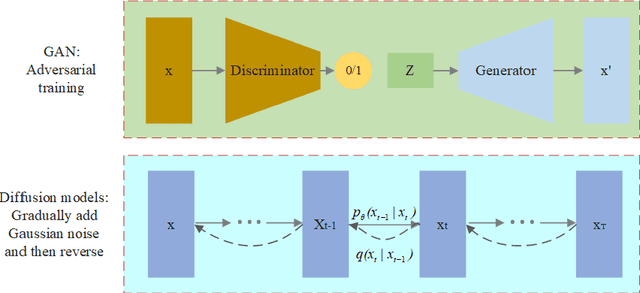
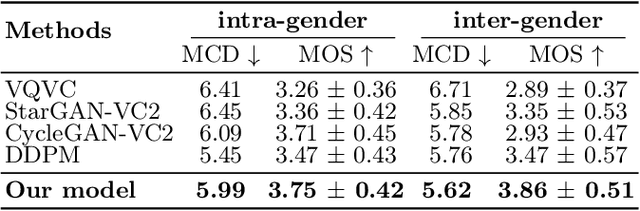
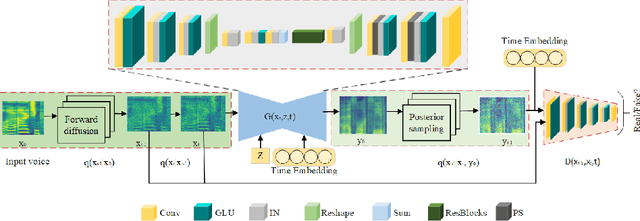
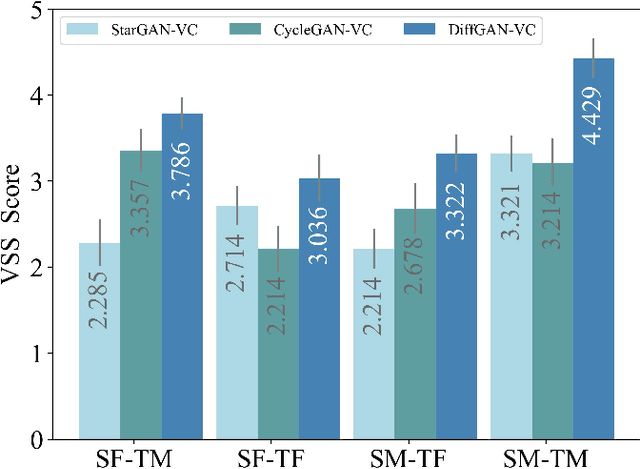
Voice conversion is a method that allows for the transformation of speaking style while maintaining the integrity of linguistic information. There are many researchers using deep generative models for voice conversion tasks. Generative Adversarial Networks (GANs) can quickly generate high-quality samples, but the generated samples lack diversity. The samples generated by the Denoising Diffusion Probabilistic Models (DDPMs) are better than GANs in terms of mode coverage and sample diversity. But the DDPMs have high computational costs and the inference speed is slower than GANs. In order to make GANs and DDPMs more practical we proposes DiffGAN-VC, a variant of GANs and DDPMS, to achieve non-parallel many-to-many voice conversion (VC). We use large steps to achieve denoising, and also introduce a multimodal conditional GANs to model the denoising diffusion generative adversarial network. According to both objective and subjective evaluation experiments, DiffGAN-VC has been shown to achieve high voice quality on non-parallel data sets. Compared with the CycleGAN-VC method, DiffGAN-VC achieves speaker similarity, naturalness and higher sound quality.
Sparse Recovery with Attention: A Hybrid Data/Model Driven Solution for High Accuracy Position and Channel Tracking at mmWave
Aug 26, 2023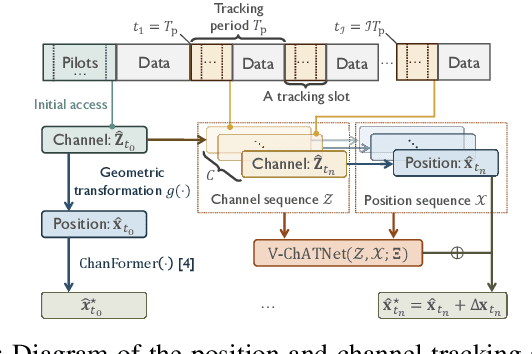
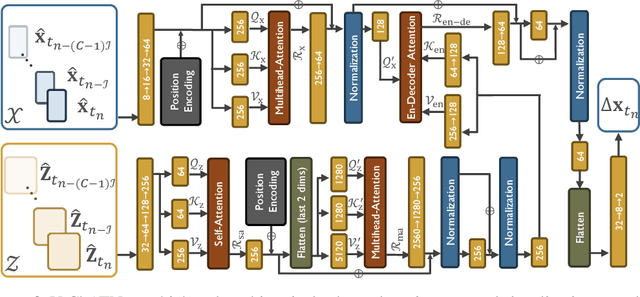
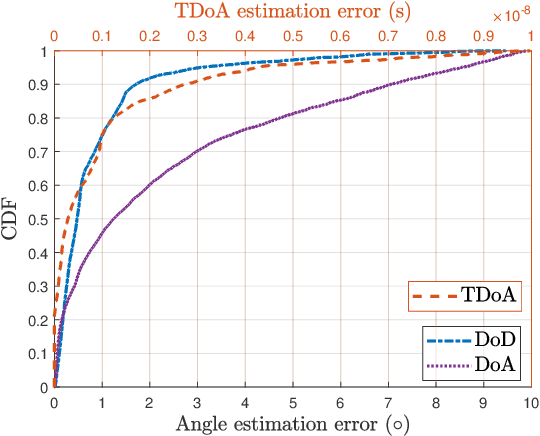
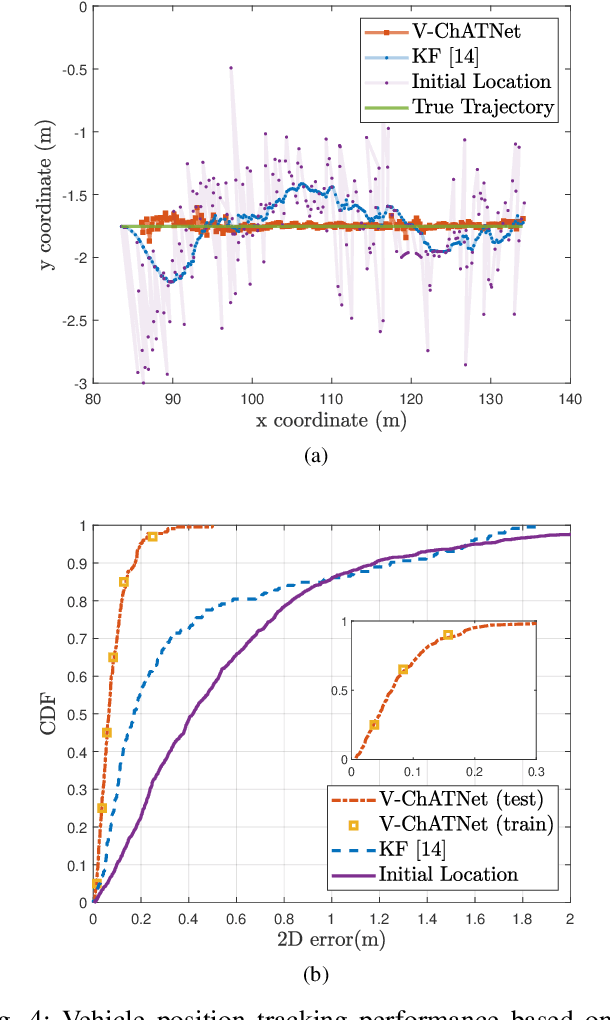
In this paper, we propose first a mmWave channel tracking algorithm based on multidimensional orthogonal matching pursuit algorithm (MOMP) using reduced sparsifying dictionaries, which exploits information from channel estimates in previous frames. Then, we present an algorithm to obtain the vehicle's initial location for the current frame by solving a system of geometric equations that leverage the estimated path parameters. Next, we design an attention network that analyzes the series of channel estimates, the vehicle's trajectory, and the initial estimate of the position associated with the current frame, to generate a refined, high accuracy position estimate. The proposed system is evaluated through numerical experiments using realistic mmWave channel series generated by ray-tracing. The experimental results show that our system provides a 2D position tracking error below 20 cm, significantly outperforming previous work based on Bayesian filtering.
VoiceBank-2023: A Multi-Speaker Mandarin Speech Corpus for Constructing Personalized TTS Systems for the Speech Impaired
Aug 27, 2023Services of personalized TTS systems for the Mandarin-speaking speech impaired are rarely mentioned. Taiwan started the VoiceBanking project in 2020, aiming to build a complete set of services to deliver personalized Mandarin TTS systems to amyotrophic lateral sclerosis patients. This paper reports the corpus design, corpus recording, data purging and correction for the corpus, and evaluations of the developed personalized TTS systems, for the VoiceBanking project. The developed corpus is named after the VoiceBank-2023 speech corpus because of its release year. The corpus contains 29.78 hours of utterances with prompts of short paragraphs and common phrases spoken by 111 native Mandarin speakers. The corpus is labeled with information about gender, degree of speech impairment, types of users, transcription, SNRs, and speaking rates. The VoiceBank-2023 is available by request for non-commercial use and welcomes all parties to join the VoiceBanking project to improve the services for the speech impaired.