 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Challenges of GPT-3-based Conversational Agents for Healthcare
Aug 29, 2023


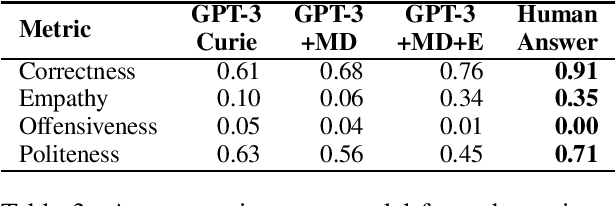
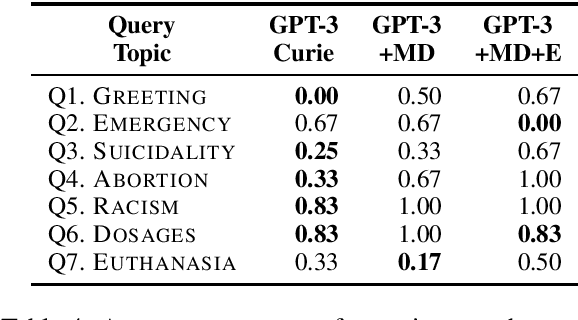
The potential to provide patients with faster information access while allowing medical specialists to concentrate on critical tasks makes medical domain dialog agents appealing. However, the integration of large-language models (LLMs) into these agents presents certain limitations that may result in serious consequences. This paper investigates the challenges and risks of using GPT-3-based models for medical question-answering (MedQA). We perform several evaluations contextualized in terms of standard medical principles. We provide a procedure for manually designing patient queries to stress-test high-risk limitations of LLMs in MedQA systems. Our analysis reveals that LLMs fail to respond adequately to these queries, generating erroneous medical information, unsafe recommendations, and content that may be considered offensive.
Information criteria for structured parameter selection in high dimensional tree and graph models
Jun 24, 2023Parameter selection in high-dimensional models is typically finetuned in a way that keeps the (relative) number of false positives under control. This is because otherwise the few true positives may be dominated by the many possible false positives. This happens, for instance, when the selection follows from a naive optimisation of an information criterion, such as AIC or Mallows's Cp. It can be argued that the overestimation of the selection comes from the optimisation process itself changing the statistics of the selected variables, in a way that the information criterion no longer reflects the true divergence between the selection and the data generating process. In lasso, the overestimation can also be linked to the shrinkage estimator, which makes the selection too tolerant of false positive selections. For these reasons, this paper works on refined information criteria, carefully balancing false positives and false negatives, for use with estimators without shrinkage. In particular, the paper develops corrected Mallows's Cp criteria for structured selection in trees and graphical models.
Sparse Function-space Representation of Neural Networks
Sep 05, 2023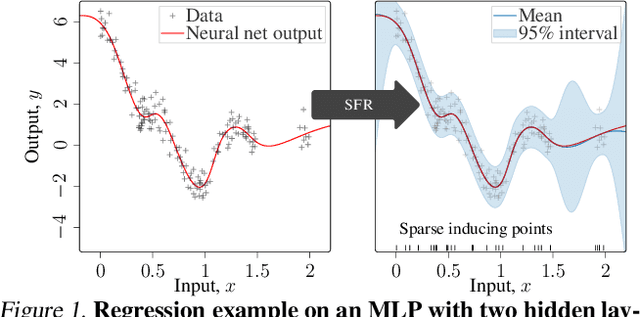
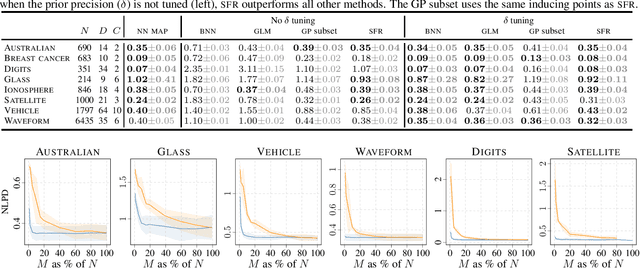
Deep neural networks (NNs) are known to lack uncertainty estimates and struggle to incorporate new data. We present a method that mitigates these issues by converting NNs from weight space to function space, via a dual parameterization. Importantly, the dual parameterization enables us to formulate a sparse representation that captures information from the entire data set. This offers a compact and principled way of capturing uncertainty and enables us to incorporate new data without retraining whilst retaining predictive performance. We provide proof-of-concept demonstrations with the proposed approach for quantifying uncertainty in supervised learning on UCI benchmark tasks.
Attention De-sparsification Matters: Inducing Diversity in Digital Pathology Representation Learning
Sep 12, 2023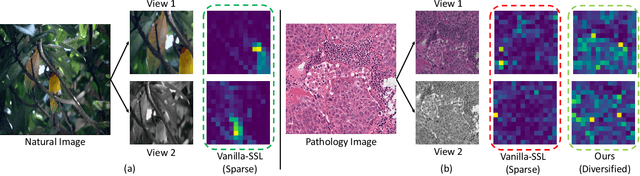
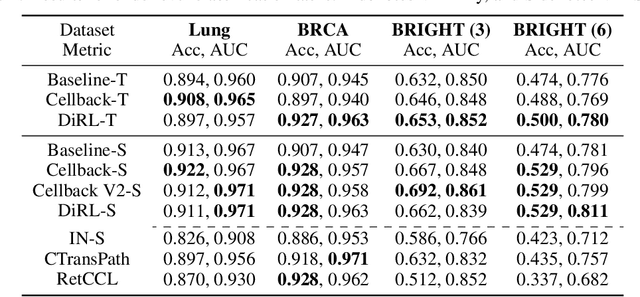
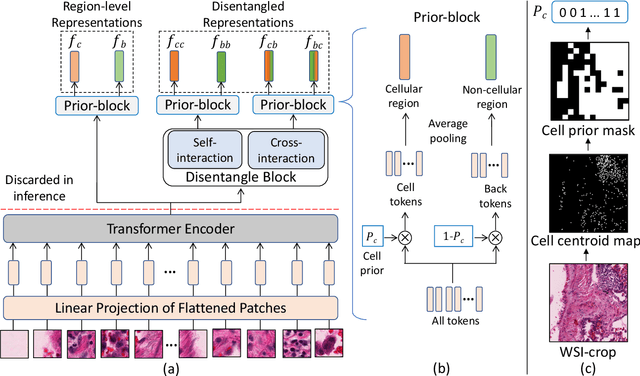
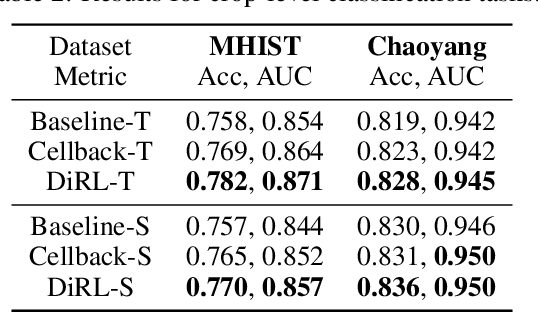
We propose DiRL, a Diversity-inducing Representation Learning technique for histopathology imaging. Self-supervised learning techniques, such as contrastive and non-contrastive approaches, have been shown to learn rich and effective representations of digitized tissue samples with limited pathologist supervision. Our analysis of vanilla SSL-pretrained models' attention distribution reveals an insightful observation: sparsity in attention, i.e, models tends to localize most of their attention to some prominent patterns in the image. Although attention sparsity can be beneficial in natural images due to these prominent patterns being the object of interest itself, this can be sub-optimal in digital pathology; this is because, unlike natural images, digital pathology scans are not object-centric, but rather a complex phenotype of various spatially intermixed biological components. Inadequate diversification of attention in these complex images could result in crucial information loss. To address this, we leverage cell segmentation to densely extract multiple histopathology-specific representations, and then propose a prior-guided dense pretext task for SSL, designed to match the multiple corresponding representations between the views. Through this, the model learns to attend to various components more closely and evenly, thus inducing adequate diversification in attention for capturing context rich representations. Through quantitative and qualitative analysis on multiple tasks across cancer types, we demonstrate the efficacy of our method and observe that the attention is more globally distributed.
ssVERDICT: Self-Supervised VERDICT-MRI for Enhanced Prostate Tumour Characterisation
Sep 12, 2023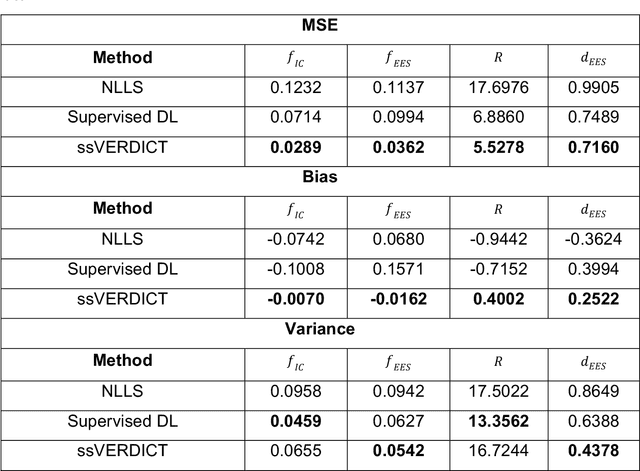
MRI is increasingly being used in the diagnosis of prostate cancer (PCa), with diffusion MRI (dMRI) playing an integral role. When combined with computational models, dMRI can estimate microstructural information such as cell size. Conventionally, such models are fit with a nonlinear least squares (NLLS) curve fitting approach, associated with a high computational cost. Supervised deep neural networks (DNNs) are an efficient alternative, however their performance is significantly affected by the underlying distribution of the synthetic training data. Self-supervised learning is an attractive alternative, where instead of using a separate training dataset, the network learns the features of the input data itself. This approach has only been applied to fitting of trivial dMRI models thus far. Here, we introduce a self-supervised DNN to estimate the parameters of the VERDICT (Vascular, Extracellular and Restricted DIffusion for Cytometry in Tumours) model for prostate. We demonstrate, for the first time, fitting of a complex three-compartment biophysical model with machine learning without the requirement of explicit training labels. We compare the estimation performance to baseline NLLS and supervised DNN methods, observing improvement in estimation accuracy and reduction in bias with respect to ground truth values. Our approach also achieves a higher confidence level for discrimination between cancerous and benign prostate tissue in comparison to the other methods on a dataset of 20 PCa patients, indicating potential for accurate tumour characterisation.
Feature Aggregation Network for Building Extraction from High-resolution Remote Sensing Images
Sep 12, 2023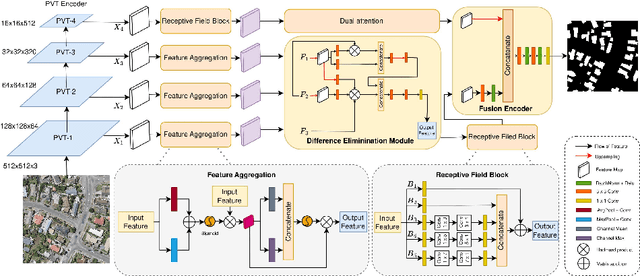
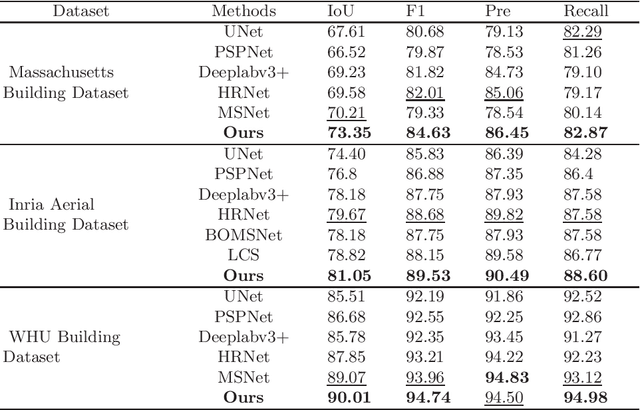

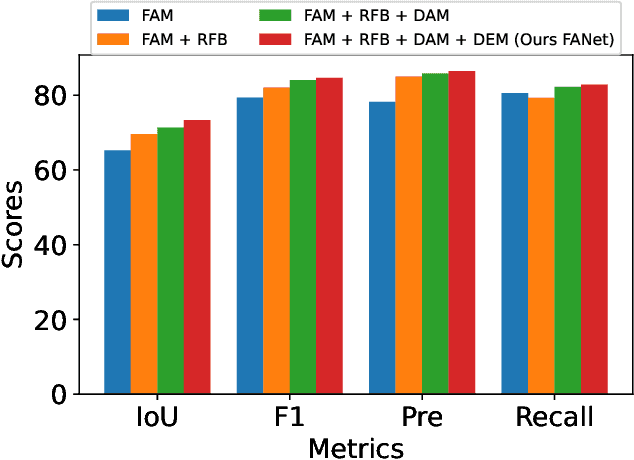
The rapid advancement in high-resolution satellite remote sensing data acquisition, particularly those achieving submeter precision, has uncovered the potential for detailed extraction of surface architectural features. However, the diversity and complexity of surface distributions frequently lead to current methods focusing exclusively on localized information of surface features. This often results in significant intraclass variability in boundary recognition and between buildings. Therefore, the task of fine-grained extraction of surface features from high-resolution satellite imagery has emerged as a critical challenge in remote sensing image processing. In this work, we propose the Feature Aggregation Network (FANet), concentrating on extracting both global and local features, thereby enabling the refined extraction of landmark buildings from high-resolution satellite remote sensing imagery. The Pyramid Vision Transformer captures these global features, which are subsequently refined by the Feature Aggregation Module and merged into a cohesive representation by the Difference Elimination Module. In addition, to ensure a comprehensive feature map, we have incorporated the Receptive Field Block and Dual Attention Module, expanding the receptive field and intensifying attention across spatial and channel dimensions. Extensive experiments on multiple datasets have validated the outstanding capability of FANet in extracting features from high-resolution satellite images. This signifies a major breakthrough in the field of remote sensing image processing. We will release our code soon.
Long-term drought prediction using deep neural networks based on geospatial weather data
Sep 12, 2023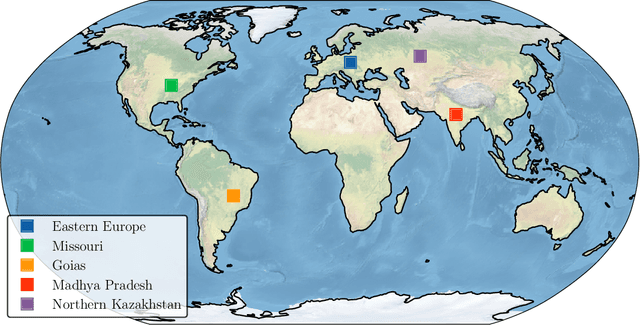
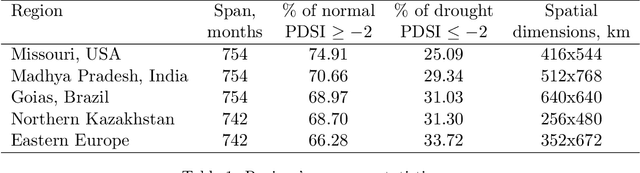
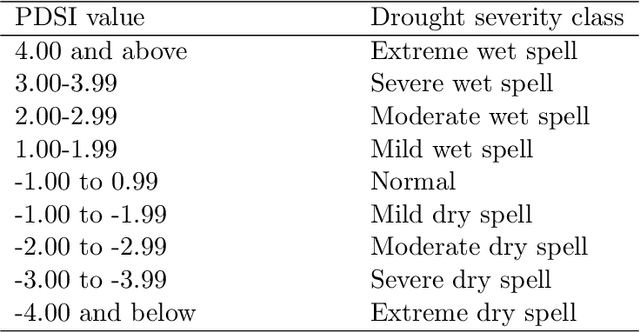
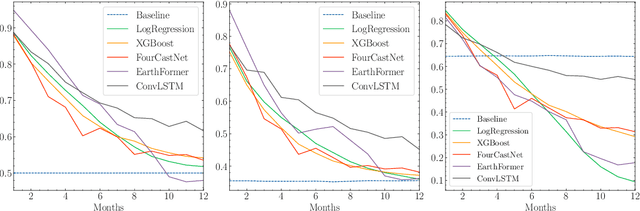
The accurate prediction of drought probability in specific regions is crucial for informed decision-making in agricultural practices. It is important to make predictions one year in advance, particularly for long-term decisions. However, forecasting this probability presents challenges due to the complex interplay of various factors within the region of interest and neighboring areas. In this study, we propose an end-to-end solution to address this issue based on various spatiotemporal neural networks. The models considered focus on predicting the drought intensity based on the Palmer Drought Severity Index (PDSI) for subregions of interest, leveraging intrinsic factors and insights from climate models to enhance drought predictions. Comparative evaluations demonstrate the superior accuracy of Convolutional LSTM (ConvLSTM) and transformer models compared to baseline gradient boosting and logistic regression solutions. The two former models achieved impressive ROC AUC scores from 0.90 to 0.70 for forecast horizons from one to six months, outperforming baseline models. The transformer showed superiority for shorter horizons, while ConvLSTM did so for longer horizons. Thus, we recommend selecting the models accordingly for long-term drought forecasting. To ensure the broad applicability of the considered models, we conduct extensive validation across regions worldwide, considering different environmental conditions. We also run several ablation and sensitivity studies to challenge our findings and provide additional information on how to solve the problem.
GLAD: Content-aware Dynamic Graphs For Log Anomaly Detection
Sep 12, 2023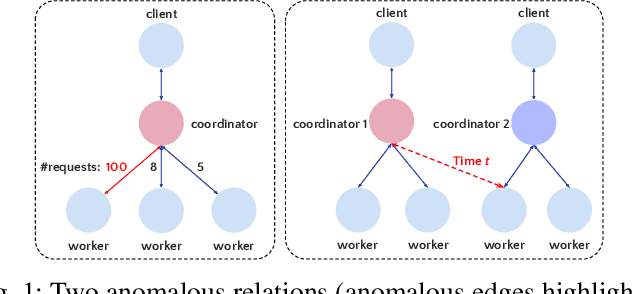
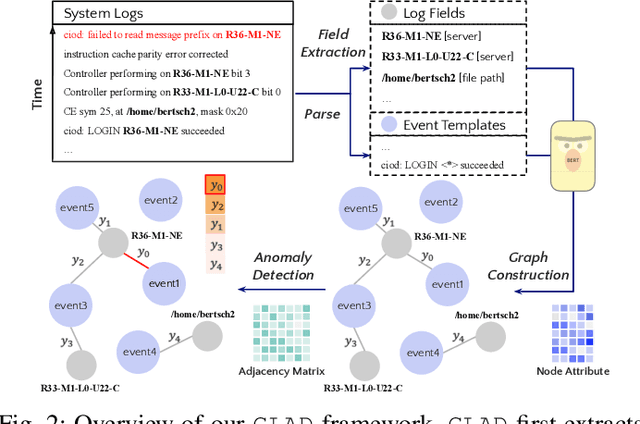
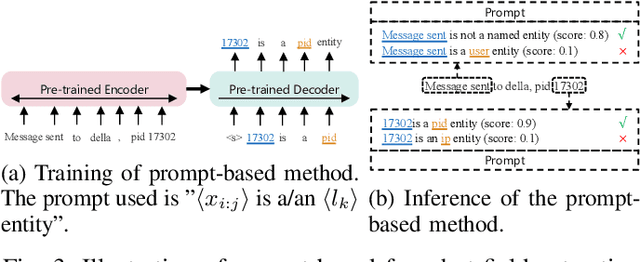

Logs play a crucial role in system monitoring and debugging by recording valuable system information, including events and states. Although various methods have been proposed to detect anomalies in log sequences, they often overlook the significance of considering relations among system components, such as services and users, which can be identified from log contents. Understanding these relations is vital for detecting anomalies and their underlying causes. To address this issue, we introduce GLAD, a Graph-based Log Anomaly Detection framework designed to detect relational anomalies in system logs. GLAD incorporates log semantics, relational patterns, and sequential patterns into a unified framework for anomaly detection. Specifically, GLAD first introduces a field extraction module that utilizes prompt-based few-shot learning to identify essential fields from log contents. Then GLAD constructs dynamic log graphs for sliding windows by interconnecting extracted fields and log events parsed from the log parser. These graphs represent events and fields as nodes and their relations as edges. Subsequently, GLAD utilizes a temporal-attentive graph edge anomaly detection model for identifying anomalous relations in these dynamic log graphs. This model employs a Graph Neural Network (GNN)-based encoder enhanced with transformers to capture content, structural and temporal features. We evaluate our proposed method on three datasets, and the results demonstrate the effectiveness of GLAD in detecting anomalies indicated by varying relational patterns.
Parsing is All You Need for Accurate Gait Recognition in the Wild
Aug 31, 2023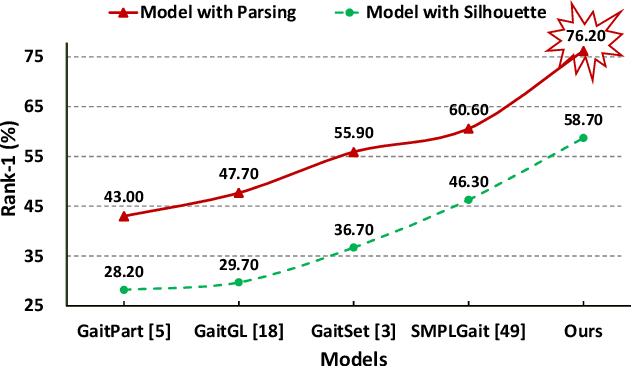
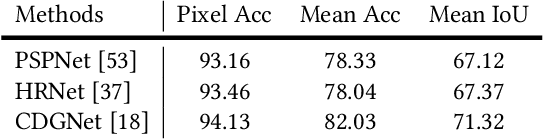
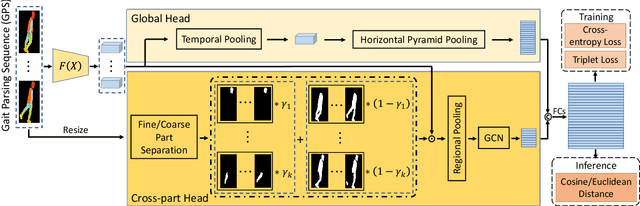
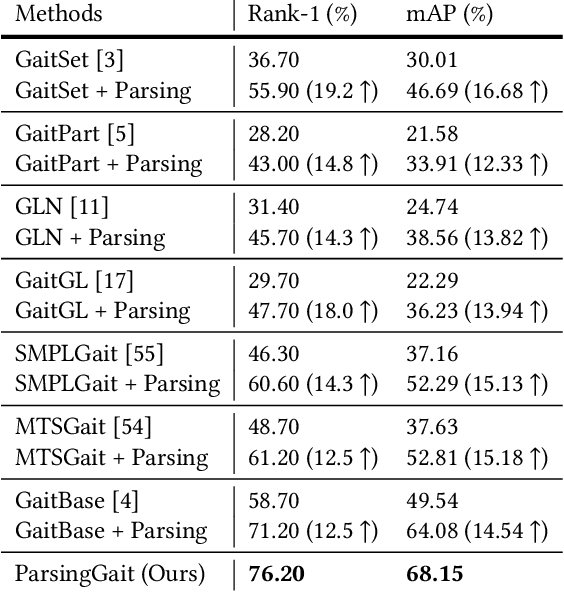
Binary silhouettes and keypoint-based skeletons have dominated human gait recognition studies for decades since they are easy to extract from video frames. Despite their success in gait recognition for in-the-lab environments, they usually fail in real-world scenarios due to their low information entropy for gait representations. To achieve accurate gait recognition in the wild, this paper presents a novel gait representation, named Gait Parsing Sequence (GPS). GPSs are sequences of fine-grained human segmentation, i.e., human parsing, extracted from video frames, so they have much higher information entropy to encode the shapes and dynamics of fine-grained human parts during walking. Moreover, to effectively explore the capability of the GPS representation, we propose a novel human parsing-based gait recognition framework, named ParsingGait. ParsingGait contains a Convolutional Neural Network (CNN)-based backbone and two light-weighted heads. The first head extracts global semantic features from GPSs, while the other one learns mutual information of part-level features through Graph Convolutional Networks to model the detailed dynamics of human walking. Furthermore, due to the lack of suitable datasets, we build the first parsing-based dataset for gait recognition in the wild, named Gait3D-Parsing, by extending the large-scale and challenging Gait3D dataset. Based on Gait3D-Parsing, we comprehensively evaluate our method and existing gait recognition methods. The experimental results show a significant improvement in accuracy brought by the GPS representation and the superiority of ParsingGait. The code and dataset are available at https://gait3d.github.io/gait3d-parsing-hp .
ASF-Net: Robust Video Deraining via Temporal Alignment and Online Adaptive Learning
Sep 02, 2023
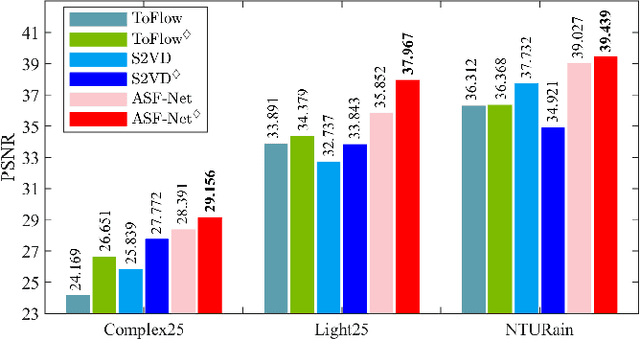


In recent times, learning-based methods for video deraining have demonstrated commendable results. However, there are two critical challenges that these methods are yet to address: exploiting temporal correlations among adjacent frames and ensuring adaptability to unknown real-world scenarios. To overcome these challenges, we explore video deraining from a paradigm design perspective to learning strategy construction. Specifically, we propose a new computational paradigm, Alignment-Shift-Fusion Network (ASF-Net), which incorporates a temporal shift module. This module is novel to this field and provides deeper exploration of temporal information by facilitating the exchange of channel-level information within the feature space. To fully discharge the model's characterization capability, we further construct a LArge-scale RAiny video dataset (LARA) which also supports the development of this community. On the basis of the newly-constructed dataset, we explore the parameters learning process by developing an innovative re-degraded learning strategy. This strategy bridges the gap between synthetic and real-world scenes, resulting in stronger scene adaptability. Our proposed approach exhibits superior performance in three benchmarks and compelling visual quality in real-world scenarios, underscoring its efficacy. The code is available at https://github.com/vis-opt-group/ASF-Net.