 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Reliability of Medical AI through Expert-guided Uncertainty Modeling
Apr 02, 2026Artificial intelligence (AI) systems accelerate medical workflows and improve diagnostic accuracy in healthcare, serving as second-opinion systems. However, the unpredictability of AI errors poses a significant challenge, particularly in healthcare contexts, where mistakes can have severe consequences. A widely adopted safeguard is to pair predictions with uncertainty estimation, enabling human experts to focus on high-risk cases while streamlining routine verification. Current uncertainty estimation methods, however, remain limited, particularly in quantifying aleatoric uncertainty, which arises from data ambiguity and noise. To address this, we propose a novel approach that leverages disagreement in expert responses to generate targets for training machine learning models. These targets are used in conjunction with standard data labels to estimate two components of uncertainty separately, as given by the law of total variance, via a two-ensemble approach, as well as its lightweight variant. We validate our method on binary image classification, binary and multi-class image segmentation, and multiple-choice question answering. Our experiments demonstrate that incorporating expert knowledge can enhance uncertainty estimation quality by $9\%$ to $50\%$ depending on the task, making this source of information invaluable for the construction of risk-aware AI systems in healthcare applications.
INTRYGUE: Induction-Aware Entropy Gating for Reliable RAG Uncertainty Estimation
Mar 23, 2026While retrieval-augmented generation (RAG) significantly improves the factual reliability of LLMs, it does not eliminate hallucinations, so robust uncertainty quantification (UQ) remains essential. In this paper, we reveal that standard entropy-based UQ methods often fail in RAG settings due to a mechanistic paradox. An internal "tug-of-war" inherent to context utilization appears: while induction heads promote grounded responses by copying the correct answer, they collaterally trigger the previously established "entropy neurons". This interaction inflates predictive entropy, causing the model to signal false uncertainty on accurate outputs. To address this, we propose INTRYGUE (Induction-Aware Entropy Gating for Uncertainty Estimation), a mechanistically grounded method that gates predictive entropy based on the activation patterns of induction heads. Evaluated across four RAG benchmarks and six open-source LLMs (4B to 13B parameters), INTRYGUE consistently matches or outperforms a wide range of UQ baselines. Our findings demonstrate that hallucination detection in RAG benefits from combining predictive uncertainty with interpretable, internal signals of context utilization.
U-Former ODE: Fast Probabilistic Forecasting of Irregular Time Series
Feb 12, 2026Probabilistic forecasting of irregularly sampled time series is crucial in domains such as healthcare and finance, yet it remains a formidable challenge. Existing Neural Controlled Differential Equation (Neural CDE) approaches, while effective at modelling continuous dynamics, suffer from slow, inherently sequential computation, which restricts scalability and limits access to global context. We introduce UFO (U-Former ODE), a novel architecture that seamlessly integrates the parallelizable, multiscale feature extraction of U-Nets, the powerful global modelling of Transformers, and the continuous-time dynamics of Neural CDEs. By constructing a fully causal, parallelizable model, UFO achieves a global receptive field while retaining strong sensitivity to local temporal dynamics. Extensive experiments on five standard benchmarks -- covering both regularly and irregularly sampled time series -- demonstrate that UFO consistently outperforms ten state-of-the-art neural baselines in predictive accuracy. Moreover, UFO delivers up to 15$\times$ faster inference compared to conventional Neural CDEs, with consistently strong performance on long and highly multivariate sequences.
Efficient Neural Controlled Differential Equations via Attentive Kernel Smoothing
Feb 02, 2026Neural Controlled Differential Equations (Neural CDEs) provide a powerful continuous-time framework for sequence modeling, yet the roughness of the driving control path often restricts their efficiency. Standard splines introduce high-frequency variations that force adaptive solvers to take excessively small steps, driving up the Number of Function Evaluations (NFE). We propose a novel approach to Neural CDE path construction that replaces exact interpolation with Kernel and Gaussian Process (GP) smoothing, enabling explicit control over trajectory regularity. To recover details lost during smoothing, we propose an attention-based Multi-View CDE (MV-CDE) and its convolutional extension (MVC-CDE), which employ learnable queries to inform path reconstruction. This framework allows the model to distribute representational capacity across multiple trajectories, each capturing distinct temporal patterns. Empirical results demonstrate that our method, MVC-CDE with GP, achieves state-of-the-art accuracy while significantly reducing NFEs and total inference time compared to spline-based baselines.
Strong Linear Baselines Strike Back: Closed-Form Linear Models as Gaussian Process Conditional Density Estimators for TSAD
Jan 31, 2026Research in time series anomaly detection (TSAD) has largely focused on developing increasingly sophisticated, hard-to-train, and expensive-to-infer neural architectures. We revisit this paradigm and show that a simple linear autoregressive anomaly score with the closed-form solution provided by ordinary least squares (OLS) regression consistently matches or outperforms state-of-the-art deep detectors. From a theoretical perspective, we show that linear models capture a broad class of anomaly types, estimating a finite-history Gaussian process conditional density. From a practical side, across extensive univariate and multivariate benchmarks, the proposed approach achieves superior accuracy while requiring orders of magnitude fewer computational resources. Thus, future research should consistently include strong linear baselines and, more importantly, develop new benchmarks with richer temporal structures pinpointing the advantages of deep learning models.
PINE: Pipeline for Important Node Exploration in Attributed Networks
Dec 08, 2025
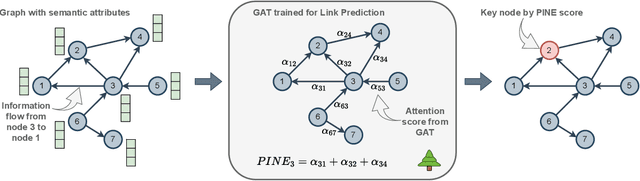
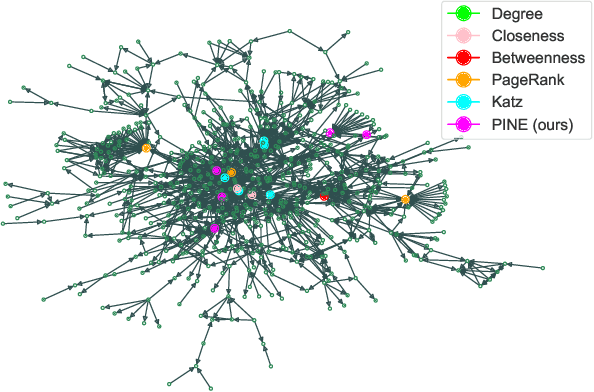
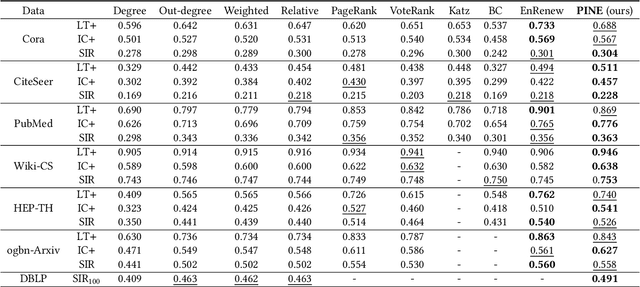
A graph with semantically attributed nodes are a common data structure in a wide range of domains. It could be interlinked web data or citation networks of scientific publications. The essential problem for such a data type is to determine nodes that carry greater importance than all the others, a task that markedly enhances system monitoring and management. Traditional methods to identify important nodes in networks introduce centrality measures, such as node degree or more complex PageRank. However, they consider only the network structure, neglecting the rich node attributes. Recent methods adopt neural networks capable of handling node features, but they require supervision. This work addresses the identified gap--the absence of approaches that are both unsupervised and attribute-aware--by introducing a Pipeline for Important Node Exploration (PINE). At the core of the proposed framework is an attention-based graph model that incorporates node semantic features in the learning process of identifying the structural graph properties. The PINE's node importance scores leverage the obtained attention distribution. We demonstrate the superior performance of the proposed PINE method on various homogeneous and heterogeneous attributed networks. As an industry-implemented system, PINE tackles the real-world challenge of unsupervised identification of key entities within large-scale enterprise graphs.
A theoretical framework for self-supervised contrastive learning for continuous dependent data
Jun 11, 2025Self-supervised learning (SSL) has emerged as a powerful approach to learning representations, particularly in the field of computer vision. However, its application to dependent data, such as temporal and spatio-temporal domains, remains underexplored. Besides, traditional contrastive SSL methods often assume \emph{semantic independence between samples}, which does not hold for dependent data exhibiting complex correlations. We propose a novel theoretical framework for contrastive SSL tailored to \emph{continuous dependent data}, which allows the nearest samples to be semantically close to each other. In particular, we propose two possible \textit{ground truth similarity measures} between objects -- \emph{hard} and \emph{soft} closeness. Under it, we derive an analytical form for the \textit{estimated similarity matrix} that accommodates both types of closeness between samples, thereby introducing dependency-aware loss functions. We validate our approach, \emph{Dependent TS2Vec}, on temporal and spatio-temporal downstream problems. Given the dependency patterns presented in the data, our approach surpasses modern ones for dependent data, highlighting the effectiveness of our theoretically grounded loss functions for SSL in capturing spatio-temporal dependencies. Specifically, we outperform TS2Vec on the standard UEA and UCR benchmarks, with accuracy improvements of $4.17$\% and $2.08$\%, respectively. Furthermore, on the drought classification task, which involves complex spatio-temporal patterns, our method achieves a $7$\% higher ROC-AUC score.
Attention Head Embeddings with Trainable Deep Kernels for Hallucination Detection in LLMs
Jun 11, 2025We present a novel approach for detecting hallucinations in large language models (LLMs) by analyzing the probabilistic divergence between prompt and response hidden-state distributions. Counterintuitively, we find that hallucinated responses exhibit smaller deviations from their prompts compared to grounded responses, suggesting that hallucinations often arise from superficial rephrasing rather than substantive reasoning. Leveraging this insight, we propose a model-intrinsic detection method that uses distributional distances as principled hallucination scores, eliminating the need for external knowledge or auxiliary models. To enhance sensitivity, we employ deep learnable kernels that automatically adapt to capture nuanced geometric differences between distributions. Our approach outperforms existing baselines, demonstrating state-of-the-art performance on several benchmarks. The method remains competitive even without kernel training, offering a robust, scalable solution for hallucination detection.
WWAggr: A Window Wasserstein-based Aggregation for Ensemble Change Point Detection
Jun 09, 2025



Change Point Detection (CPD) aims to identify moments of abrupt distribution shifts in data streams. Real-world high-dimensional CPD remains challenging due to data pattern complexity and violation of common assumptions. Resorting to standalone deep neural networks, the current state-of-the-art detectors have yet to achieve perfect quality. Concurrently, ensembling provides more robust solutions, boosting the performance. In this paper, we investigate ensembles of deep change point detectors and realize that standard prediction aggregation techniques, e.g., averaging, are suboptimal and fail to account for problem peculiarities. Alternatively, we introduce WWAggr -- a novel task-specific method of ensemble aggregation based on the Wasserstein distance. Our procedure is versatile, working effectively with various ensembles of deep CPD models. Moreover, unlike existing solutions, we practically lift a long-standing problem of the decision threshold selection for CPD.
AdUE: Improving uncertainty estimation head for LoRA adapters in LLMs
May 21, 2025



Uncertainty estimation remains a critical challenge in adapting pre-trained language models to classification tasks, particularly under parameter-efficient fine-tuning approaches such as adapters. We introduce AdUE1, an efficient post-hoc uncertainty estimation (UE) method, to enhance softmax-based estimates. Our approach (1) uses a differentiable approximation of the maximum function and (2) applies additional regularization through L2-SP, anchoring the fine-tuned head weights and regularizing the model. Evaluations on five NLP classification datasets across four language models (RoBERTa, ELECTRA, LLaMA-2, Qwen) demonstrate that our method consistently outperforms established baselines such as Mahalanobis distance and softmax response. Our approach is lightweight (no base-model changes) and produces better-calibrated confidence.