 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FedDIP: Federated Learning with Extreme Dynamic Pruning and Incremental Regularization
Sep 13, 2023
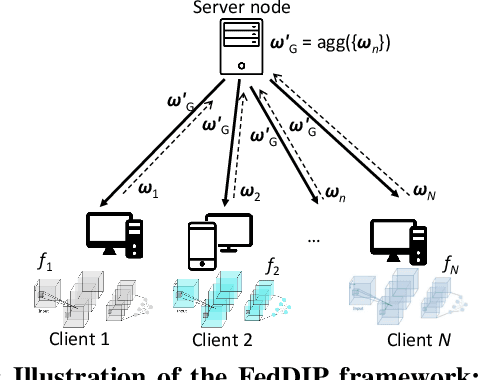
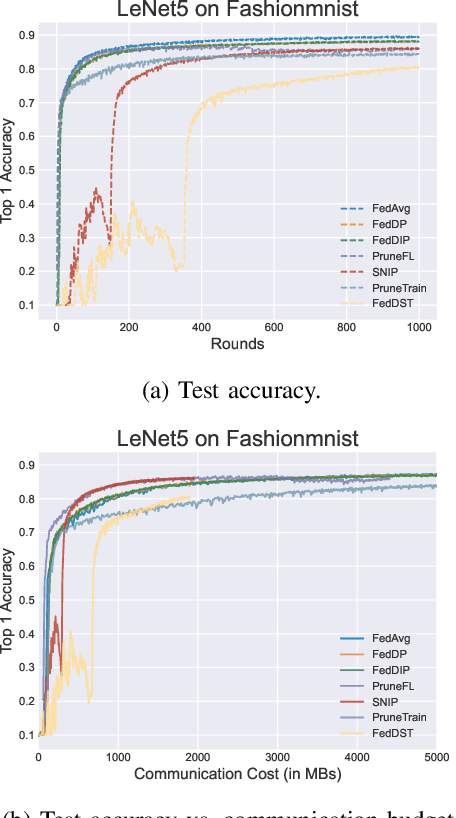
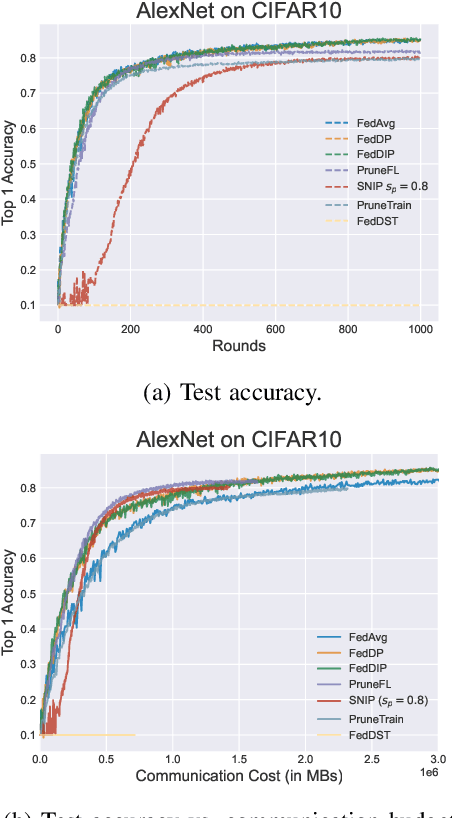
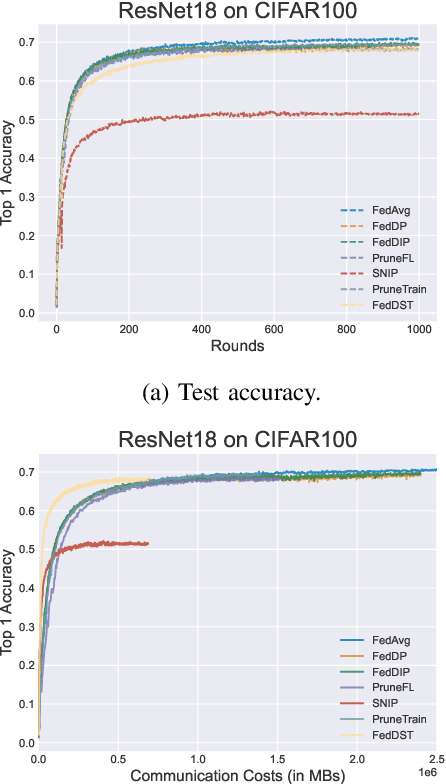
Federated Learning (FL) has been successfully adopted for distributed training and inference of large-scale Deep Neural Networks (DNNs). However, DNNs are characterized by an extremely large number of parameters, thus, yielding significant challenges in exchanging these parameters among distributed nodes and managing the memory. Although recent DNN compression methods (e.g., sparsification, pruning) tackle such challenges, they do not holistically consider an adaptively controlled reduction of parameter exchange while maintaining high accuracy levels. We, therefore, contribute with a novel FL framework (coined FedDIP), which combines (i) dynamic model pruning with error feedback to eliminate redundant information exchange, which contributes to significant performance improvement, with (ii) incremental regularization that can achieve \textit{extreme} sparsity of models. We provide convergence analysis of FedDIP and report on a comprehensive performance and comparative assessment against state-of-the-art methods using benchmark data sets and DNN models. Our results showcase that FedDIP not only controls the model sparsity but efficiently achieves similar or better performance compared to other model pruning methods adopting incremental regularization during distributed model training. The code is available at: https://github.com/EricLoong/feddip.
Interactively Robot Action Planning with Uncertainty Analysis and Active Questioning by Large Language Model
Aug 30, 2023The application of the Large Language Model (LLM) to robot action planning has been actively studied. The instructions given to the LLM by natural language may include ambiguity and lack of information depending on the task context. It is possible to adjust the output of LLM by making the instruction input more detailed; however, the design cost is high. In this paper, we propose the interactive robot action planning method that allows the LLM to analyze and gather missing information by asking questions to humans. The method can minimize the design cost of generating precise robot instructions. We demonstrated the effectiveness of our method through concrete examples in cooking tasks. However, our experiments also revealed challenges in robot action planning with LLM, such as asking unimportant questions and assuming crucial information without asking. Shedding light on these issues provides valuable insights for future research on utilizing LLM for robotics.
MOVIN: Real-time Motion Capture using a Single LiDAR
Sep 17, 2023Recent advancements in technology have brought forth new forms of interactive applications, such as the social metaverse, where end users interact with each other through their virtual avatars. In such applications, precise full-body tracking is essential for an immersive experience and a sense of embodiment with the virtual avatar. However, current motion capture systems are not easily accessible to end users due to their high cost, the requirement for special skills to operate them, or the discomfort associated with wearable devices. In this paper, we present MOVIN, the data-driven generative method for real-time motion capture with global tracking, using a single LiDAR sensor. Our autoregressive conditional variational autoencoder (CVAE) model learns the distribution of pose variations conditioned on the given 3D point cloud from LiDAR.As a central factor for high-accuracy motion capture, we propose a novel feature encoder to learn the correlation between the historical 3D point cloud data and global, local pose features, resulting in effective learning of the pose prior. Global pose features include root translation, rotation, and foot contacts, while local features comprise joint positions and rotations. Subsequently, a pose generator takes into account the sampled latent variable along with the features from the previous frame to generate a plausible current pose. Our framework accurately predicts the performer's 3D global information and local joint details while effectively considering temporally coherent movements across frames. We demonstrate the effectiveness of our architecture through quantitative and qualitative evaluations, comparing it against state-of-the-art methods. Additionally, we implement a real-time application to showcase our method in real-world scenarios. MOVIN dataset is available at \url{https://movin3d.github.io/movin_pg2023/}.
HAMUR: Hyper Adapter for Multi-Domain Recommendation
Sep 12, 2023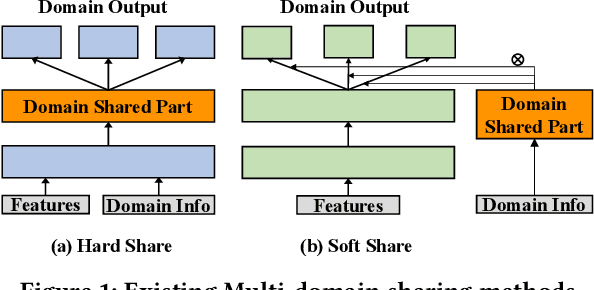
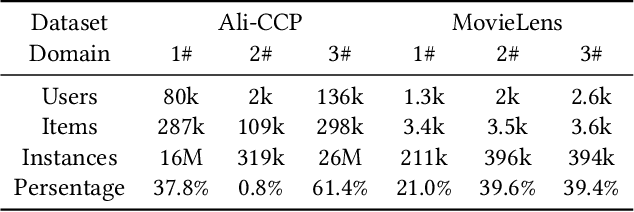
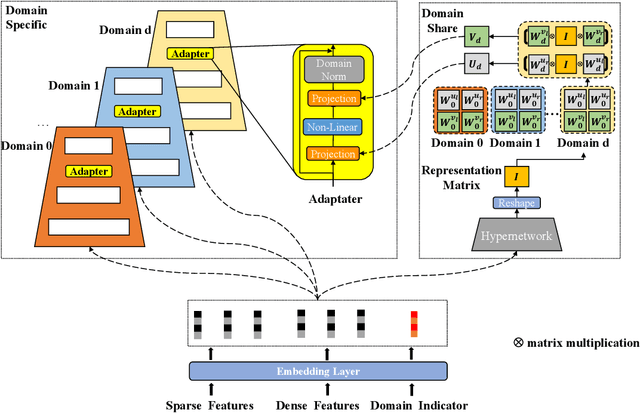
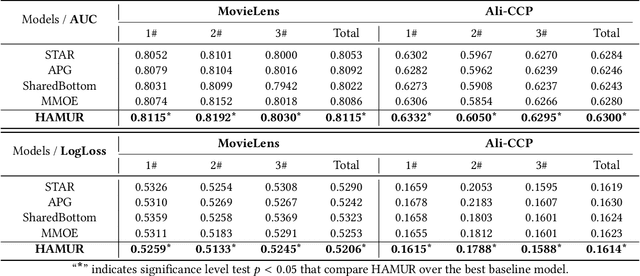
Multi-Domain Recommendation (MDR) has gained significant attention in recent years, which leverages data from multiple domains to enhance their performance concurrently.However, current MDR models are confronted with two limitations. Firstly, the majority of these models adopt an approach that explicitly shares parameters between domains, leading to mutual interference among them. Secondly, due to the distribution differences among domains, the utilization of static parameters in existing methods limits their flexibility to adapt to diverse domains. To address these challenges, we propose a novel model Hyper Adapter for Multi-Domain Recommendation (HAMUR). Specifically, HAMUR consists of two components: (1). Domain-specific adapter, designed as a pluggable module that can be seamlessly integrated into various existing multi-domain backbone models, and (2). Domain-shared hyper-network, which implicitly captures shared information among domains and dynamically generates the parameters for the adapter. We conduct extensive experiments on two public datasets using various backbone networks. The experimental results validate the effectiveness and scalability of the proposed model.
Distributionally-Informed Recommender System Evaluation
Sep 12, 2023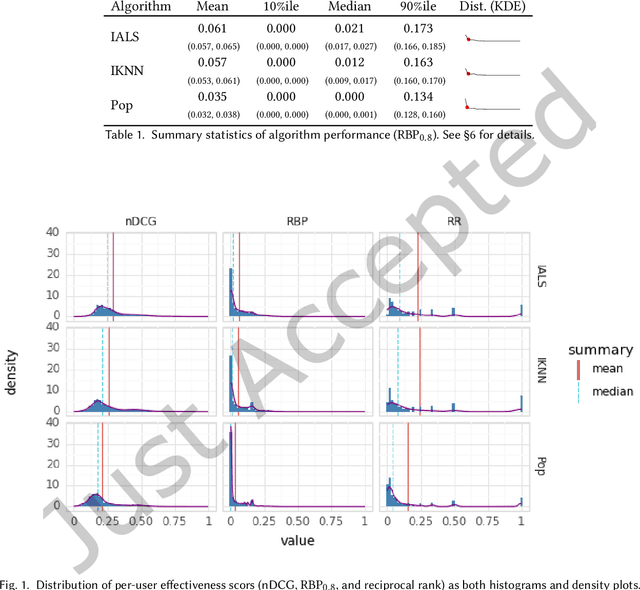
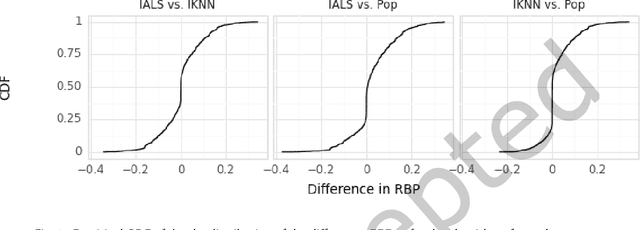
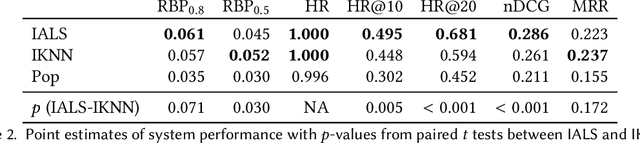
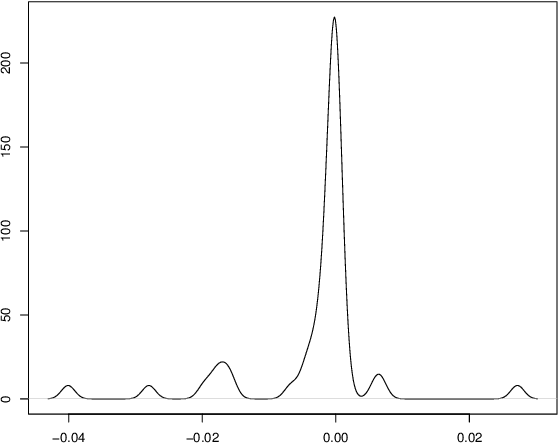
Current practice for evaluating recommender systems typically focuses on point estimates of user-oriented effectiveness metrics or business metrics, sometimes combined with additional metrics for considerations such as diversity and novelty. In this paper, we argue for the need for researchers and practitioners to attend more closely to various distributions that arise from a recommender system (or other information access system) and the sources of uncertainty that lead to these distributions. One immediate implication of our argument is that both researchers and practitioners must report and examine more thoroughly the distribution of utility between and within different stakeholder groups. However, distributions of various forms arise in many more aspects of the recommender systems experimental process, and distributional thinking has substantial ramifications for how we design, evaluate, and present recommender systems evaluation and research results. Leveraging and emphasizing distributions in the evaluation of recommender systems is a necessary step to ensure that the systems provide appropriate and equitably-distributed benefit to the people they affect.
Twofold Structured Features-Based Siamese Network for Infrared Target Tracking
Aug 31, 2023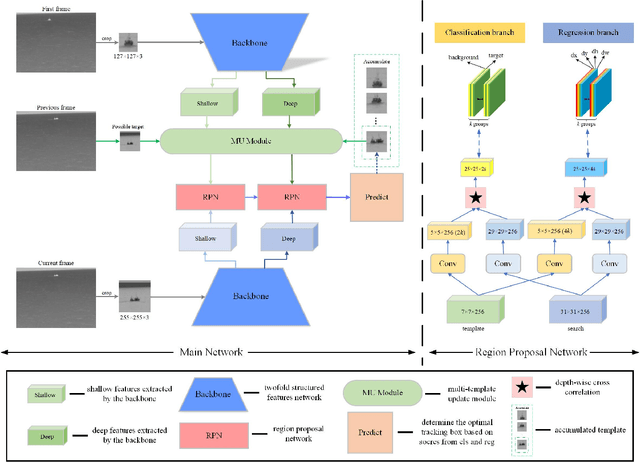
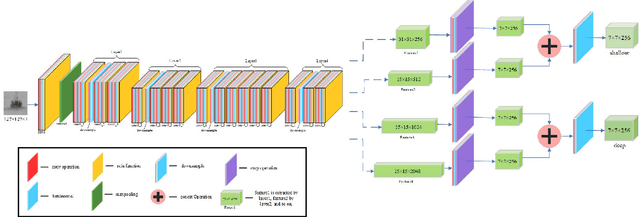
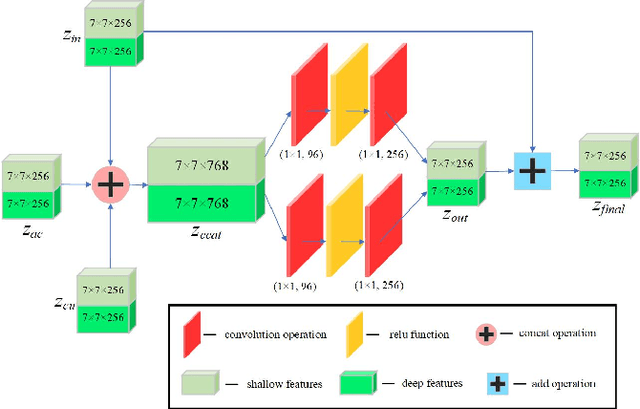

Nowadays, infrared target tracking has been a critical technology in the field of computer vision and has many applications, such as motion analysis, pedestrian surveillance, intelligent detection, and so forth. Unfortunately, due to the lack of color, texture and other detailed information, tracking drift often occurs when the tracker encounters infrared targets that vary in size or shape. To address this issue, we present a twofold structured features-based Siamese network for infrared target tracking. First of all, in order to improve the discriminative capacity for infrared targets, a novel feature fusion network is proposed to fuse both shallow spatial information and deep semantic information into the extracted features in a comprehensive manner. Then, a multi-template update module based on template update mechanism is designed to effectively deal with interferences from target appearance changes which are prone to cause early tracking failures. Finally, both qualitative and quantitative experiments are carried out on VOT-TIR 2016 dataset, which demonstrates that our method achieves the balance of promising tracking performance and real-time tracking speed against other out-of-the-art trackers.
Automated CVE Analysis for Threat Prioritization and Impact Prediction
Sep 06, 2023

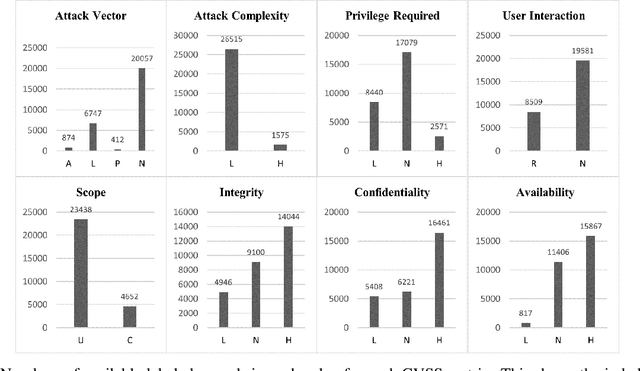
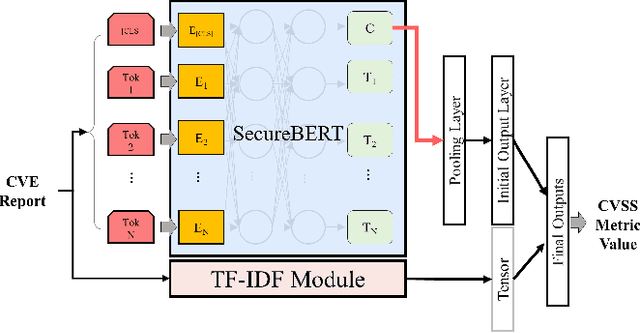
The Common Vulnerabilities and Exposures (CVE) are pivotal information for proactive cybersecurity measures, including service patching, security hardening, and more. However, CVEs typically offer low-level, product-oriented descriptions of publicly disclosed cybersecurity vulnerabilities, often lacking the essential attack semantic information required for comprehensive weakness characterization and threat impact estimation. This critical insight is essential for CVE prioritization and the identification of potential countermeasures, particularly when dealing with a large number of CVEs. Current industry practices involve manual evaluation of CVEs to assess their attack severities using the Common Vulnerability Scoring System (CVSS) and mapping them to Common Weakness Enumeration (CWE) for potential mitigation identification. Unfortunately, this manual analysis presents a major bottleneck in the vulnerability analysis process, leading to slowdowns in proactive cybersecurity efforts and the potential for inaccuracies due to human errors. In this research, we introduce our novel predictive model and tool (called CVEDrill) which revolutionizes CVE analysis and threat prioritization. CVEDrill accurately estimates the CVSS vector for precise threat mitigation and priority ranking and seamlessly automates the classification of CVEs into the appropriate CWE hierarchy classes. By harnessing CVEDrill, organizations can now implement cybersecurity countermeasure mitigation with unparalleled accuracy and timeliness, surpassing in this domain the capabilities of state-of-the-art tools like ChaptGPT.
Investigating Online Financial Misinformation and Its Consequences: A Computational Perspective
Sep 06, 2023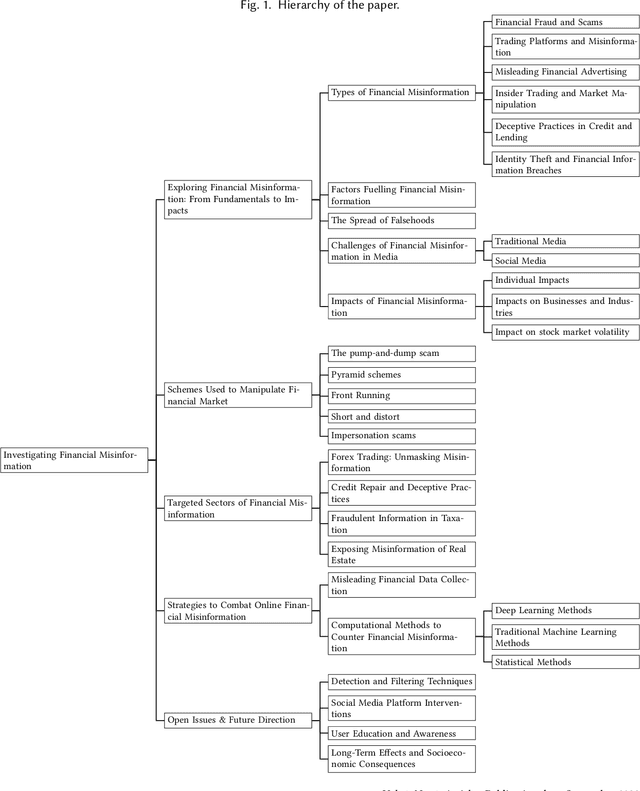
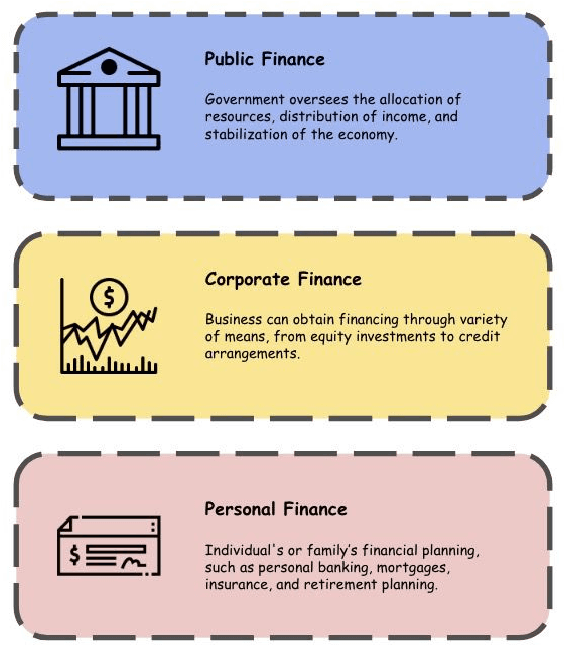
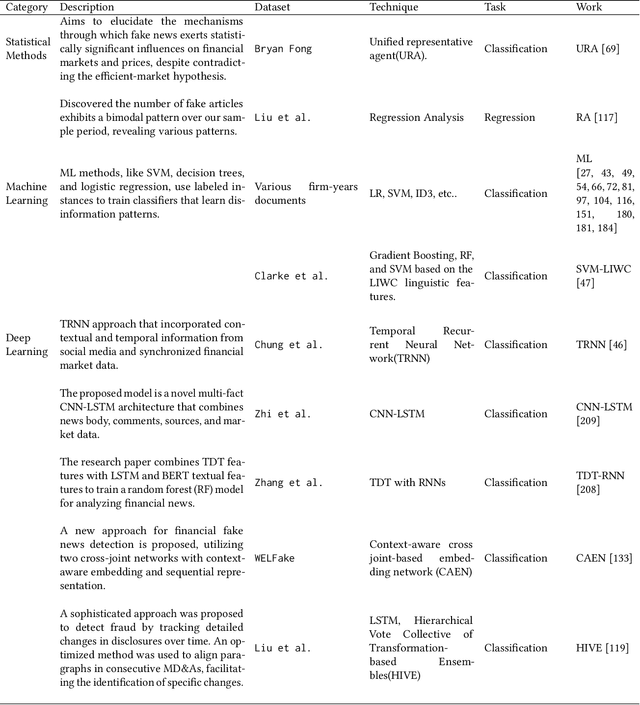
The rapid dissemination of information through digital platforms has revolutionized the way we access and consume news and information, particularly in the realm of finance. However, this digital age has also given rise to an alarming proliferation of financial misinformation, which can have detrimental effects on individuals, markets, and the overall economy. This research paper aims to provide a comprehensive survey of online financial misinformation, including its types, sources, and impacts. We first discuss the characteristics and manifestations of financial misinformation, encompassing false claims and misleading content. We explore various case studies that illustrate the detrimental consequences of financial misinformation on the economy. Finally, we highlight the potential impact and implications of detecting financial misinformation. Early detection and mitigation strategies can help protect investors, enhance market transparency, and preserve financial stability. We emphasize the importance of greater awareness, education, and regulation to address the issue of online financial misinformation and safeguard individuals and businesses from its harmful effects. In conclusion, this research paper sheds light on the pervasive issue of online financial misinformation and its wide-ranging consequences. By understanding the types, sources, and impacts of misinformation, stakeholders can work towards implementing effective detection and prevention measures to foster a more informed and resilient financial ecosystem.
DealMVC: Dual Contrastive Calibration for Multi-view Clustering
Sep 02, 2023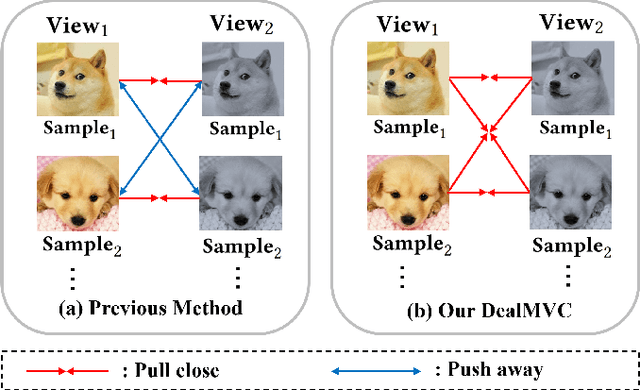

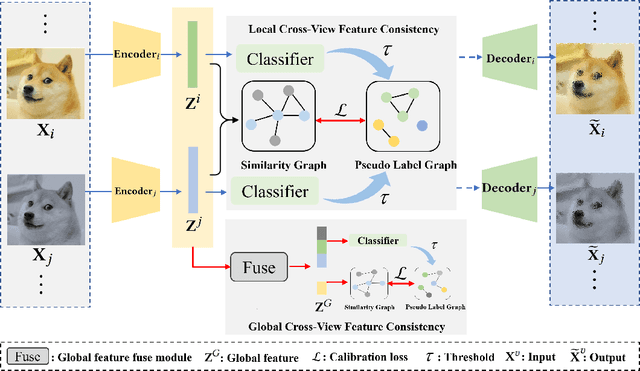
Benefiting from the strong view-consistent information mining capacity, multi-view contrastive clustering has attracted plenty of attention in recent years. However, we observe the following drawback, which limits the clustering performance from further improvement. The existing multi-view models mainly focus on the consistency of the same samples in different views while ignoring the circumstance of similar but different samples in cross-view scenarios. To solve this problem, we propose a novel Dual contrastive calibration network for Multi-View Clustering (DealMVC). Specifically, we first design a fusion mechanism to obtain a global cross-view feature. Then, a global contrastive calibration loss is proposed by aligning the view feature similarity graph and the high-confidence pseudo-label graph. Moreover, to utilize the diversity of multi-view information, we propose a local contrastive calibration loss to constrain the consistency of pair-wise view features. The feature structure is regularized by reliable class information, thus guaranteeing similar samples have similar features in different views. During the training procedure, the interacted cross-view feature is jointly optimized at both local and global levels. In comparison with other state-of-the-art approaches, the comprehensive experimental results obtained from eight benchmark datasets provide substantial validation of the effectiveness and superiority of our algorithm. We release the code of DealMVC at https://github.com/xihongyang1999/DealMVC on GitHub.
FedJudge: Federated Legal Large Language Model
Sep 15, 2023
Large Language Models (LLMs) have gained prominence in the field of Legal Intelligence, offering potential applications in assisting legal professionals and laymen. However, the centralized training of these Legal LLMs raises data privacy concerns, as legal data is distributed among various institutions containing sensitive individual information. This paper addresses this challenge by exploring the integration of Legal LLMs with Federated Learning (FL) methodologies. By employing FL, Legal LLMs can be fine-tuned locally on devices or clients, and their parameters are aggregated and distributed on a central server, ensuring data privacy without directly sharing raw data. However, computation and communication overheads hinder the full fine-tuning of LLMs under the FL setting. Moreover, the distribution shift of legal data reduces the effectiveness of FL methods. To this end, in this paper, we propose the first Federated Legal Large Language Model (FedJudge) framework, which fine-tunes Legal LLMs efficiently and effectively. Specifically, FedJudge utilizes parameter-efficient fine-tuning methods to update only a few additional parameters during the FL training. Besides, we explore the continual learning methods to preserve the global model's important parameters when training local clients to mitigate the problem of data shifts. Extensive experimental results on three real-world datasets clearly validate the effectiveness of FedJudge. Code is released at https://github.com/yuelinan/FedJudge.