 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated CVE Analysis for Threat Prioritization and Impact Prediction
Sep 06, 2023The Common Vulnerabilities and Exposures (CVE) are pivotal information for proactive cybersecurity measures, including service patching, security hardening, and more. However, CVEs typically offer low-level, product-oriented descriptions of publicly disclosed cybersecurity vulnerabilities, often lacking the essential attack semantic information required for comprehensive weakness characterization and threat impact estimation. This critical insight is essential for CVE prioritization and the identification of potential countermeasures, particularly when dealing with a large number of CVEs. Current industry practices involve manual evaluation of CVEs to assess their attack severities using the Common Vulnerability Scoring System (CVSS) and mapping them to Common Weakness Enumeration (CWE) for potential mitigation identification. Unfortunately, this manual analysis presents a major bottleneck in the vulnerability analysis process, leading to slowdowns in proactive cybersecurity efforts and the potential for inaccuracies due to human errors. In this research, we introduce our novel predictive model and tool (called CVEDrill) which revolutionizes CVE analysis and threat prioritization. CVEDrill accurately estimates the CVSS vector for precise threat mitigation and priority ranking and seamlessly automates the classification of CVEs into the appropriate CWE hierarchy classes. By harnessing CVEDrill, organizations can now implement cybersecurity countermeasure mitigation with unparalleled accuracy and timeliness, surpassing in this domain the capabilities of state-of-the-art tools like ChaptGPT.
CVE-driven Attack Technique Prediction with Semantic Information Extraction and a Domain-specific Language Model
Sep 06, 2023This paper addresses a critical challenge in cybersecurity: the gap between vulnerability information represented by Common Vulnerabilities and Exposures (CVEs) and the resulting cyberattack actions. CVEs provide insights into vulnerabilities, but often lack details on potential threat actions (tactics, techniques, and procedures, or TTPs) within the ATT&CK framework. This gap hinders accurate CVE categorization and proactive countermeasure initiation. The paper introduces the TTPpredictor tool, which uses innovative techniques to analyze CVE descriptions and infer plausible TTP attacks resulting from CVE exploitation. TTPpredictor overcomes challenges posed by limited labeled data and semantic disparities between CVE and TTP descriptions. It initially extracts threat actions from unstructured cyber threat reports using Semantic Role Labeling (SRL) techniques. These actions, along with their contextual attributes, are correlated with MITRE's attack functionality classes. This automated correlation facilitates the creation of labeled data, essential for categorizing novel threat actions into threat functionality classes and TTPs. The paper presents an empirical assessment, demonstrating TTPpredictor's effectiveness with accuracy rates of approximately 98% and F1-scores ranging from 95% to 98% in precise CVE classification to ATT&CK techniques. TTPpredictor outperforms state-of-the-art language model tools like ChatGPT. Overall, this paper offers a robust solution for linking CVEs to potential attack techniques, enhancing cybersecurity practitioners' ability to proactively identify and mitigate threats.
Language Model for Text Analytic in Cybersecurity
Apr 06, 2022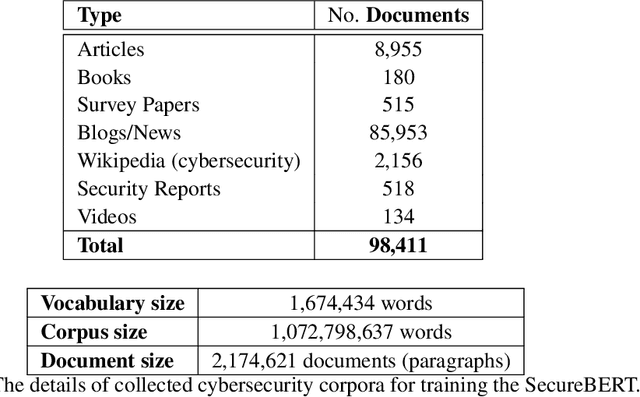
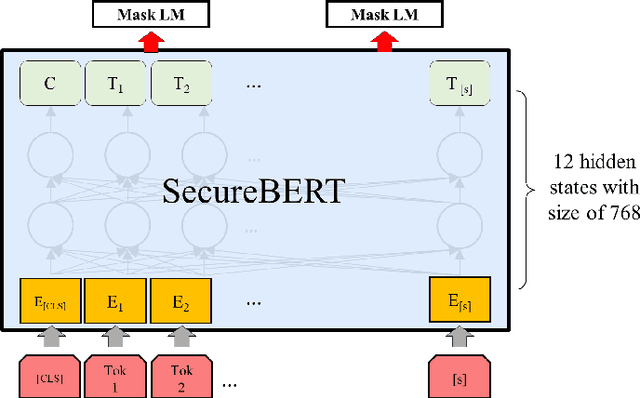
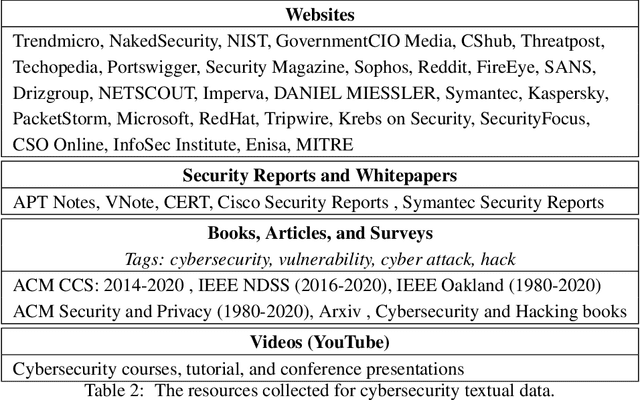
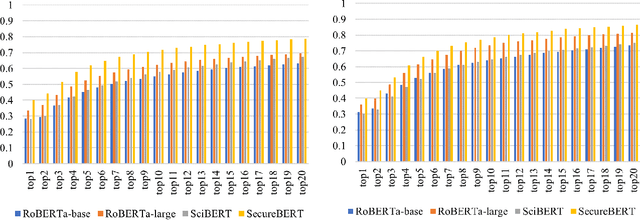
NLP is a form of artificial intelligence and machine learning concerned with a computer or machine's ability to understand and interpret human language. Language models are crucial in text analytics and NLP since they allow computers to interpret qualitative input and convert it to quantitative data that they can use in other tasks. In essence, in the context of transfer learning, language models are typically trained on a large generic corpus, referred to as the pre-training stage, and then fine-tuned to a specific underlying task. As a result, pre-trained language models are mostly used as a baseline model that incorporates a broad grasp of the context and may be further customized to be used in a new NLP task. The majority of pre-trained models are trained on corpora from general domains, such as Twitter, newswire, Wikipedia, and Web. Such off-the-shelf NLP models trained on general text may be inefficient and inaccurate in specialized fields. In this paper, we propose a cybersecurity language model called SecureBERT, which is able to capture the text connotations in the cybersecurity domain, and therefore could further be used in automation for many important cybersecurity tasks that would otherwise rely on human expertise and tedious manual efforts. SecureBERT is trained on a large corpus of cybersecurity text collected and preprocessed by us from a variety of sources in cybersecurity and the general computing domain. Using our proposed methods for tokenization and model weights adjustment, SecureBERT is not only able to preserve the understanding of general English as most pre-trained language models can do, but also effective when applied to text that has cybersecurity implications.
ThreatZoom: CVE2CWE using Hierarchical Neural Network
Sep 24, 2020
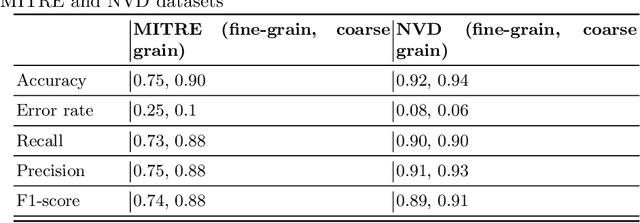

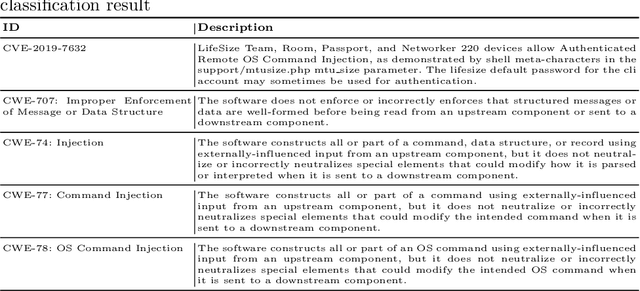
The Common Vulnerabilities and Exposures (CVE) represent standard means for sharing publicly known information security vulnerabilities. One or more CVEs are grouped into the Common Weakness Enumeration (CWE) classes for the purpose of understanding the software or configuration flaws and potential impacts enabled by these vulnerabilities and identifying means to detect or prevent exploitation. As the CVE-to-CWE classification is mostly performed manually by domain experts, thousands of critical and new CVEs remain unclassified, yet they are unpatchable. This significantly limits the utility of CVEs and slows down proactive threat mitigation. This paper presents the first automatic tool to classify CVEs to CWEs. ThreatZoom uses a novel learning algorithm that employs an adaptive hierarchical neural network which adjusts its weights based on text analytic scores and classification errors. It automatically estimates the CWE classes corresponding to a CVE instance using both statistical and semantic features extracted from the description of a CVE. This tool is rigorously tested by various datasets provided by MITRE and the National Vulnerability Database (NVD). The accuracy of classifying CVE instances to their correct CWE classes are 92% (fine-grain) and 94% (coarse-grain) for NVD dataset, and 75% (fine-grain) and 90% (coarse-grain) for MITRE dataset, despite the small corpus.
* This is accepted paper in EAI SecureComm 2020, 16th EAI International Conference on Security and Privacy in Communication Networks
The Panacea Threat Intelligence and Active Defense Platform
Apr 20, 2020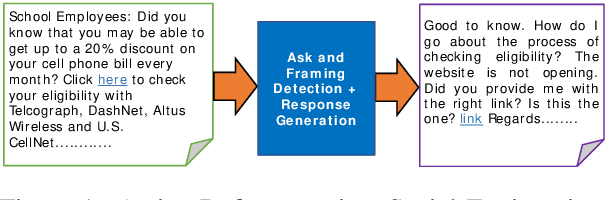
We describe Panacea, a system that supports natural language processing (NLP) components for active defenses against social engineering attacks. We deploy a pipeline of human language technology, including Ask and Framing Detection, Named Entity Recognition, Dialogue Engineering, and Stylometry. Panacea processes modern message formats through a plug-in architecture to accommodate innovative approaches for message analysis, knowledge representation and dialogue generation. The novelty of the Panacea system is that uses NLP for cyber defense and engages the attacker using bots to elicit evidence to attribute to the attacker and to waste the attacker's time and resources.
Host-based anomaly detection using Eigentraces feature extraction and one-class classification on system call trace data
Nov 25, 2019
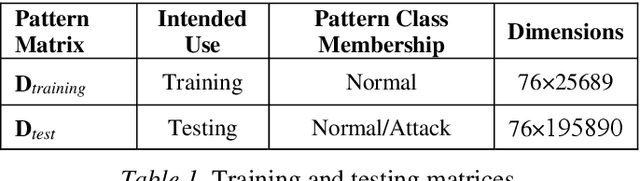
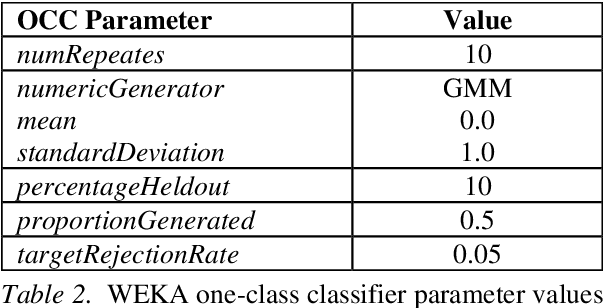
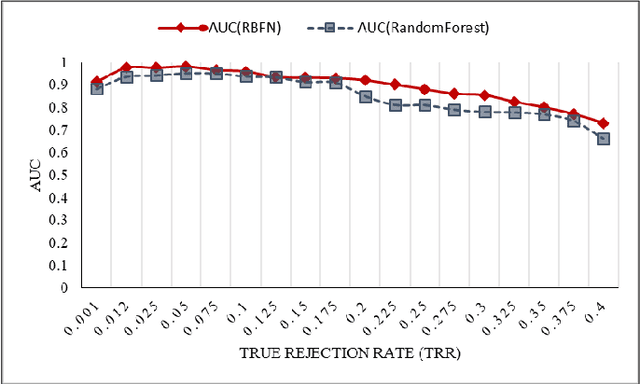
This paper proposes a methodology for host-based anomaly detection using a semi-supervised algorithm namely one-class classifier combined with a PCA-based feature extraction technique called Eigentraces on system call trace data. The one-class classification is based on generating a set of artificial data using a reference distribution and combining the target class probability function with artificial class density function to estimate the target class density function through the Bayes formulation. The benchmark dataset, ADFA-LD, is employed for the simulation study. ADFA-LD dataset contains thousands of system call traces collected during various normal and attack processes for the Linux operating system environment. In order to pre-process and to extract features, windowing on the system call trace data followed by the principal component analysis which is named as Eigentraces is implemented. The target class probability function is modeled separately by Radial Basis Function neural network and Random Forest machine learners for performance comparison purposes. The simulation study showed that the proposed intrusion detection system offers high performance for detecting anomalies and normal activities with respect to a set of well-accepted metrics including detection rate, accuracy, and missed and false alarm rates.