 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated CVE Analysis for Threat Prioritization and Impact Prediction
Sep 06, 2023The Common Vulnerabilities and Exposures (CVE) are pivotal information for proactive cybersecurity measures, including service patching, security hardening, and more. However, CVEs typically offer low-level, product-oriented descriptions of publicly disclosed cybersecurity vulnerabilities, often lacking the essential attack semantic information required for comprehensive weakness characterization and threat impact estimation. This critical insight is essential for CVE prioritization and the identification of potential countermeasures, particularly when dealing with a large number of CVEs. Current industry practices involve manual evaluation of CVEs to assess their attack severities using the Common Vulnerability Scoring System (CVSS) and mapping them to Common Weakness Enumeration (CWE) for potential mitigation identification. Unfortunately, this manual analysis presents a major bottleneck in the vulnerability analysis process, leading to slowdowns in proactive cybersecurity efforts and the potential for inaccuracies due to human errors. In this research, we introduce our novel predictive model and tool (called CVEDrill) which revolutionizes CVE analysis and threat prioritization. CVEDrill accurately estimates the CVSS vector for precise threat mitigation and priority ranking and seamlessly automates the classification of CVEs into the appropriate CWE hierarchy classes. By harnessing CVEDrill, organizations can now implement cybersecurity countermeasure mitigation with unparalleled accuracy and timeliness, surpassing in this domain the capabilities of state-of-the-art tools like ChaptGPT.
Language Model for Text Analytic in Cybersecurity
Apr 06, 2022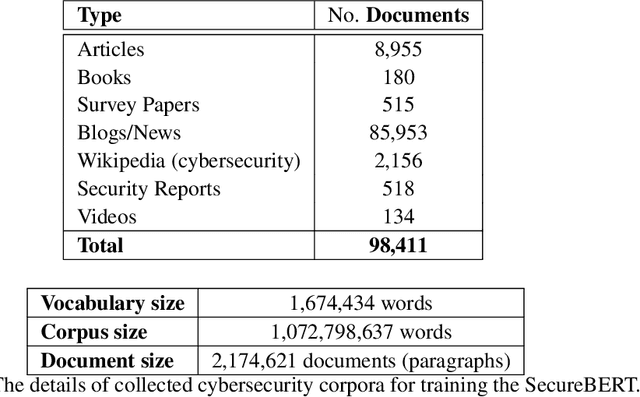
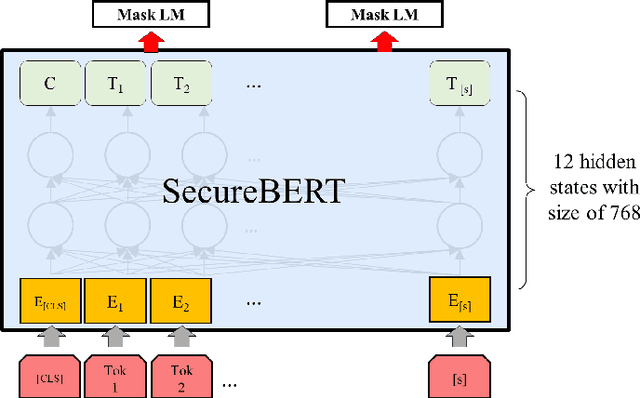
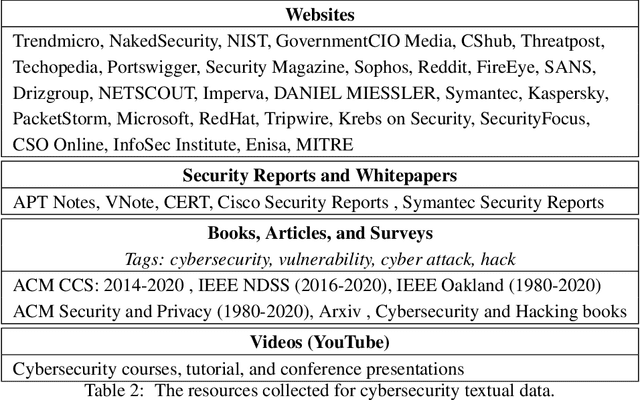
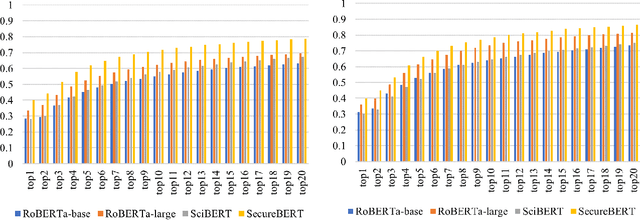
NLP is a form of artificial intelligence and machine learning concerned with a computer or machine's ability to understand and interpret human language. Language models are crucial in text analytics and NLP since they allow computers to interpret qualitative input and convert it to quantitative data that they can use in other tasks. In essence, in the context of transfer learning, language models are typically trained on a large generic corpus, referred to as the pre-training stage, and then fine-tuned to a specific underlying task. As a result, pre-trained language models are mostly used as a baseline model that incorporates a broad grasp of the context and may be further customized to be used in a new NLP task. The majority of pre-trained models are trained on corpora from general domains, such as Twitter, newswire, Wikipedia, and Web. Such off-the-shelf NLP models trained on general text may be inefficient and inaccurate in specialized fields. In this paper, we propose a cybersecurity language model called SecureBERT, which is able to capture the text connotations in the cybersecurity domain, and therefore could further be used in automation for many important cybersecurity tasks that would otherwise rely on human expertise and tedious manual efforts. SecureBERT is trained on a large corpus of cybersecurity text collected and preprocessed by us from a variety of sources in cybersecurity and the general computing domain. Using our proposed methods for tokenization and model weights adjustment, SecureBERT is not only able to preserve the understanding of general English as most pre-trained language models can do, but also effective when applied to text that has cybersecurity implications.
A System for 3D Reconstruction Of Comminuted Tibial Plafond Bone Fractures
Feb 23, 2021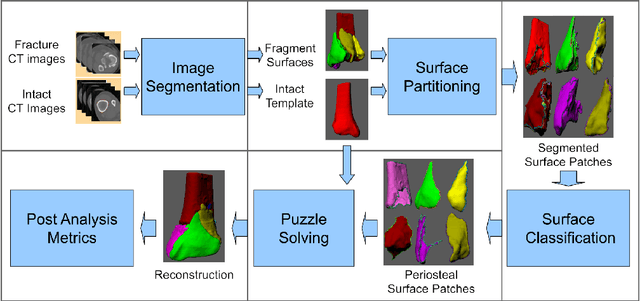
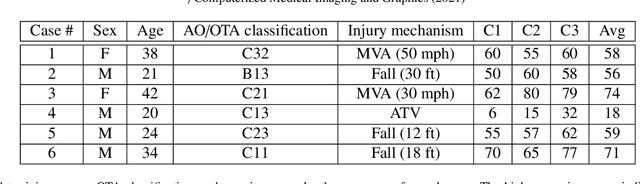
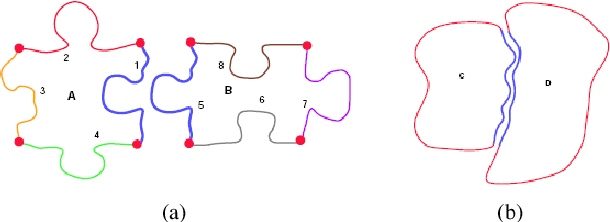
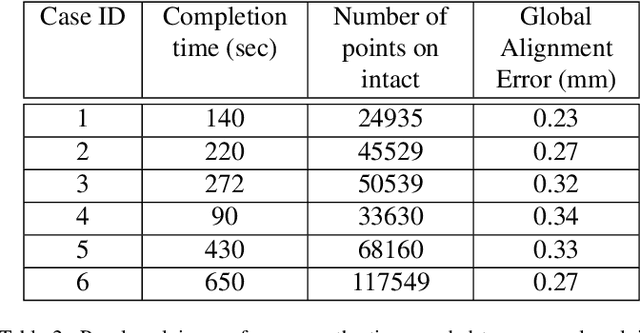
High energy impacts at joint locations often generate highly fragmented, or comminuted, bone fractures. Current approaches for treatment require physicians to decide how to classify the fracture within a hierarchy fracture severity categories. Each category then provides a best-practice treatment scenario to obtain the best possible prognosis for the patient. This article identifies shortcomings associated with qualitative-only evaluation of fracture severity and provides new quantitative metrics that serve to address these shortcomings. We propose a system to semi-automatically extract quantitative metrics that are major indicators of fracture severity. These include: (i) fracture surface area, i.e., how much surface area was generated when the bone broke apart, and (ii) dispersion, i.e., how far the fragments have rotated and translated from their original anatomic positions. This article describes new computational tools to extract these metrics by computationally reconstructing 3D bone anatomy from CT images with a focus on tibial plafond fracture cases where difficult qualitative fracture severity cases are more prevalent. Reconstruction is accomplished within a single system that integrates several novel algorithms that identify, extract and piece-together fractured fragments in a virtual environment. Doing so provides objective quantitative measures for these fracture severity indicators. The availability of such measures provides new tools for fracture severity assessment which may lead to improved fracture treatment. This paper describes the system, the underlying algorithms and the metrics of the reconstruction results by quantitatively analyzing six clinical tibial plafond fracture cases.
ThreatZoom: CVE2CWE using Hierarchical Neural Network
Sep 24, 2020
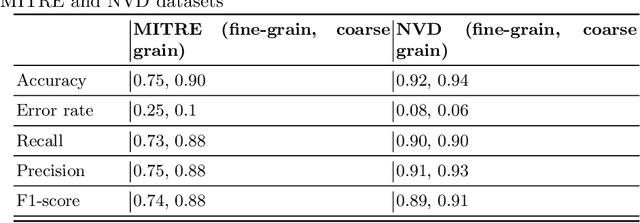

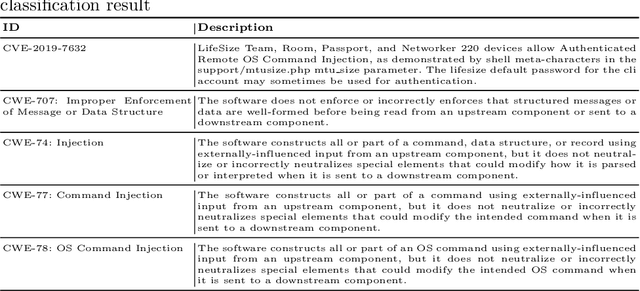
The Common Vulnerabilities and Exposures (CVE) represent standard means for sharing publicly known information security vulnerabilities. One or more CVEs are grouped into the Common Weakness Enumeration (CWE) classes for the purpose of understanding the software or configuration flaws and potential impacts enabled by these vulnerabilities and identifying means to detect or prevent exploitation. As the CVE-to-CWE classification is mostly performed manually by domain experts, thousands of critical and new CVEs remain unclassified, yet they are unpatchable. This significantly limits the utility of CVEs and slows down proactive threat mitigation. This paper presents the first automatic tool to classify CVEs to CWEs. ThreatZoom uses a novel learning algorithm that employs an adaptive hierarchical neural network which adjusts its weights based on text analytic scores and classification errors. It automatically estimates the CWE classes corresponding to a CVE instance using both statistical and semantic features extracted from the description of a CVE. This tool is rigorously tested by various datasets provided by MITRE and the National Vulnerability Database (NVD). The accuracy of classifying CVE instances to their correct CWE classes are 92% (fine-grain) and 94% (coarse-grain) for NVD dataset, and 75% (fine-grain) and 90% (coarse-grain) for MITRE dataset, despite the small corpus.
* This is accepted paper in EAI SecureComm 2020, 16th EAI International Conference on Security and Privacy in Communication Networks