 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information Extraction": models, code, and papers
CAW-coref: Conjunction-Aware Word-level Coreference Resolution
Oct 09, 2023
State-of-the-art coreference resolutions systems depend on multiple LLM calls per document and are thus prohibitively expensive for many use cases (e.g., information extraction with large corpora). The leading word-level coreference system (WL-coref) attains 96.6% of these SOTA systems' performance while being much more efficient. In this work, we identify a routine yet important failure case of WL-coref: dealing with conjoined mentions such as 'Tom and Mary'. We offer a simple yet effective solution that improves the performance on the OntoNotes test set by 0.9% F1, shrinking the gap between efficient word-level coreference resolution and expensive SOTA approaches by 34.6%. Our Conjunction-Aware Word-level coreference model (CAW-coref) and code is available at https://github.com/KarelDO/wl-coref.
Less is More: Learning Reference Knowledge Using No-Reference Image Quality Assessment
Dec 01, 2023Image Quality Assessment (IQA) with reference images have achieved great success by imitating the human vision system, in which the image quality is effectively assessed by comparing the query image with its pristine reference image. However, for the images in the wild, it is quite difficult to access accurate reference images. We argue that it is possible to learn reference knowledge under the No-Reference Image Quality Assessment (NR-IQA) setting, which is effective and efficient empirically. Concretely, by innovatively introducing a novel feature distillation method in IQA, we propose a new framework to learn comparative knowledge from non-aligned reference images. And then, to achieve fast convergence and avoid overfitting, we further propose an inductive bias regularization. Such a framework not only solves the congenital defects of NR-IQA but also improves the feature extraction framework, enabling it to express more abundant quality information. Surprisingly, our method utilizes less input while obtaining a more significant improvement compared to the teacher models. Extensive experiments on eight standard NR-IQA datasets demonstrate the superior performance to the state-of-the-art NR-IQA methods, i.e., achieving the PLCC values of 0.917 (vs. 0.884 in LIVEC) and 0.686 (vs. 0.661 in LIVEFB).
Key-value information extraction from full handwritten pages
Apr 26, 2023
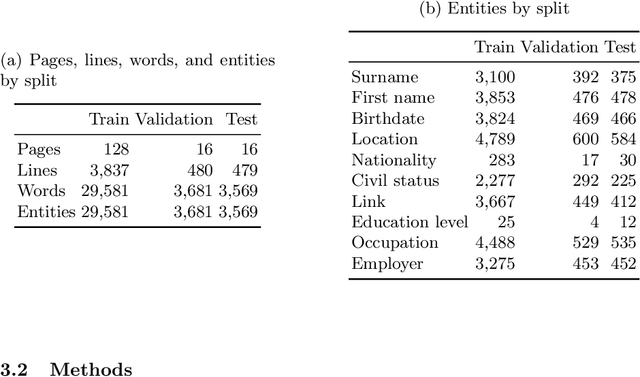

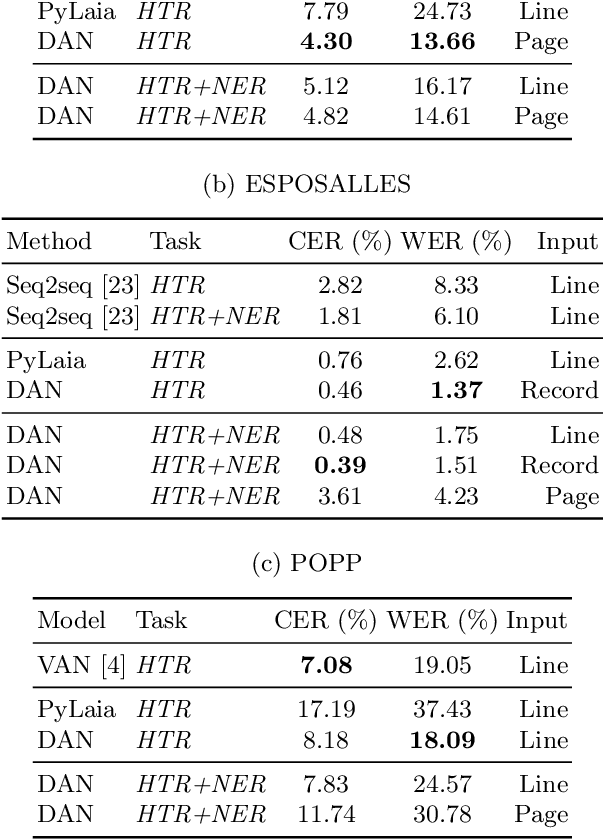
We propose a Transformer-based approach for information extraction from digitized handwritten documents. Our approach combines, in a single model, the different steps that were so far performed by separate models: feature extraction, handwriting recognition and named entity recognition. We compare this integrated approach with traditional two-stage methods that perform handwriting recognition before named entity recognition, and present results at different levels: line, paragraph, and page. Our experiments show that attention-based models are especially interesting when applied on full pages, as they do not require any prior segmentation step. Finally, we show that they are able to learn from key-value annotations: a list of important words with their corresponding named entities. We compare our models to state-of-the-art methods on three public databases (IAM, ESPOSALLES, and POPP) and outperform previous performances on all three datasets.
Rebuild City Buildings from Off-Nadir Aerial Images with Offset-Building Model (OBM)
Oct 25, 2023Accurate measurement of the offset from roof-to-footprint in very-high-resolution remote sensing imagery is crucial for urban information extraction tasks. With the help of deep learning, existing methods typically rely on two-stage CNN models to extract regions of interest on building feature maps. At the first stage, a Region Proposal Network (RPN) is applied to extract thousands of ROIs (Region of Interests) which will post-imported into a Region-based Convolutional Neural Networks (RCNN) to extract wanted information. However, because of inflexible RPN, these methods often lack effective user interaction, encounter difficulties in instance correspondence, and struggle to keep up with the advancements in general artificial intelligence. This paper introduces an interactive Transformer model combined with a prompt encoder to precisely extract building segmentation as well as the offset vectors from roofs to footprints. In our model, a powerful module, namely ROAM, was tailored for common problems in predicting roof-to-footprint offsets. We tested our model's feasibility on the publicly available BONAI dataset, achieving a significant reduction in Prompt-Instance-Level offset errors ranging from 14.6% to 16.3%. Additionally, we developed a Distance-NMS algorithm tailored for large-scale building offsets, significantly enhancing the accuracy of predicted building offset angles and lengths in a straightforward and efficient manner. To further validate the model's robustness, we created a new test set using 0.5m remote sensing imagery from Huizhou, China, for inference testing. Our code, training methods, and the updated dataset will be accessable at https://github.com/likaiucas.
Cooperative Dual Attention for Audio-Visual Speech Enhancement with Facial Cues
Nov 24, 2023In this work, we focus on leveraging facial cues beyond the lip region for robust Audio-Visual Speech Enhancement (AVSE). The facial region, encompassing the lip region, reflects additional speech-related attributes such as gender, skin color, nationality, etc., which contribute to the effectiveness of AVSE. However, static and dynamic speech-unrelated attributes also exist, causing appearance changes during speech. To address these challenges, we propose a Dual Attention Cooperative Framework, DualAVSE, to ignore speech-unrelated information, capture speech-related information with facial cues, and dynamically integrate it with the audio signal for AVSE. Specifically, we introduce a spatial attention-based visual encoder to capture and enhance visual speech information beyond the lip region, incorporating global facial context and automatically ignoring speech-unrelated information for robust visual feature extraction. Additionally, a dynamic visual feature fusion strategy is introduced by integrating a temporal-dimensional self-attention module, enabling the model to robustly handle facial variations. The acoustic noise in the speaking process is variable, impacting audio quality. Therefore, a dynamic fusion strategy for both audio and visual features is introduced to address this issue. By integrating cooperative dual attention in the visual encoder and audio-visual fusion strategy, our model effectively extracts beneficial speech information from both audio and visual cues for AVSE. Thorough analysis and comparison on different datasets, including normal and challenging cases with unreliable or absent visual information, consistently show our model outperforming existing methods across multiple metrics.
Leveraging deep active learning to identify low-resource mobility functioning information in public clinical notes
Nov 27, 2023Function is increasingly recognized as an important indicator of whole-person health, although it receives little attention in clinical natural language processing research. We introduce the first public annotated dataset specifically on the Mobility domain of the International Classification of Functioning, Disability and Health (ICF), aiming to facilitate automatic extraction and analysis of functioning information from free-text clinical notes. We utilize the National NLP Clinical Challenges (n2c2) research dataset to construct a pool of candidate sentences using keyword expansion. Our active learning approach, using query-by-committee sampling weighted by density representativeness, selects informative sentences for human annotation. We train BERT and CRF models, and use predictions from these models to guide the selection of new sentences for subsequent annotation iterations. Our final dataset consists of 4,265 sentences with a total of 11,784 entities, including 5,511 Action entities, 5,328 Mobility entities, 306 Assistance entities, and 639 Quantification entities. The inter-annotator agreement (IAA), averaged over all entity types, is 0.72 for exact matching and 0.91 for partial matching. We also train and evaluate common BERT models and state-of-the-art Nested NER models. The best F1 scores are 0.84 for Action, 0.7 for Mobility, 0.62 for Assistance, and 0.71 for Quantification. Empirical results demonstrate promising potential of NER models to accurately extract mobility functioning information from clinical text. The public availability of our annotated dataset will facilitate further research to comprehensively capture functioning information in electronic health records (EHRs).
Extracting individual variable information for their decoupling, direct mutual information and multi-feature Granger causality
Nov 22, 2023Working with multiple variables they usually contain difficult to control complex dependencies. This article proposes extraction of their individual information, e.g. $\overline{X|Y}$ as random variable containing information from $X$, but with removed information about $Y$, by using $(x,y) \leftrightarrow (\bar{x}=\textrm{CDF}_{X|Y=y}(x),y)$ reversible normalization. One application can be decoupling of individual information of variables: reversibly transform $(X_1,\ldots,X_n)\leftrightarrow(\tilde{X}_1,\ldots \tilde{X}_n)$ together containing the same information, but being independent: $\forall_{i\neq j} \tilde{X}_i\perp \tilde{X}_j, \tilde{X}_i\perp X_j$. It requires detailed models of complex conditional probability distributions - it is generally a difficult task, but here can be done through multiple dependency reducing iterations, using imperfect methods (here HCR: Hierarchical Correlation Reconstruction). It could be also used for direct mutual information - evaluating direct information transfer: without use of intermediate variables. For causality direction there is discussed multi-feature Granger causality, e.g. to trace various types of individual information transfers between such decoupled variables, including propagation time (delay).
Empirical Study of Zero-Shot NER with ChatGPT
Oct 16, 2023Large language models (LLMs) exhibited powerful capability in various natural language processing tasks. This work focuses on exploring LLM performance on zero-shot information extraction, with a focus on the ChatGPT and named entity recognition (NER) task. Inspired by the remarkable reasoning capability of LLM on symbolic and arithmetic reasoning, we adapt the prevalent reasoning methods to NER and propose reasoning strategies tailored for NER. First, we explore a decomposed question-answering paradigm by breaking down the NER task into simpler subproblems by labels. Second, we propose syntactic augmentation to stimulate the model's intermediate thinking in two ways: syntactic prompting, which encourages the model to analyze the syntactic structure itself, and tool augmentation, which provides the model with the syntactic information generated by a parsing tool. Besides, we adapt self-consistency to NER by proposing a two-stage majority voting strategy, which first votes for the most consistent mentions, then the most consistent types. The proposed methods achieve remarkable improvements for zero-shot NER across seven benchmarks, including Chinese and English datasets, and on both domain-specific and general-domain scenarios. In addition, we present a comprehensive analysis of the error types with suggestions for optimization directions. We also verify the effectiveness of the proposed methods on the few-shot setting and other LLMs.
LFSRDiff: Light Field Image Super-Resolution via Diffusion Models
Nov 27, 2023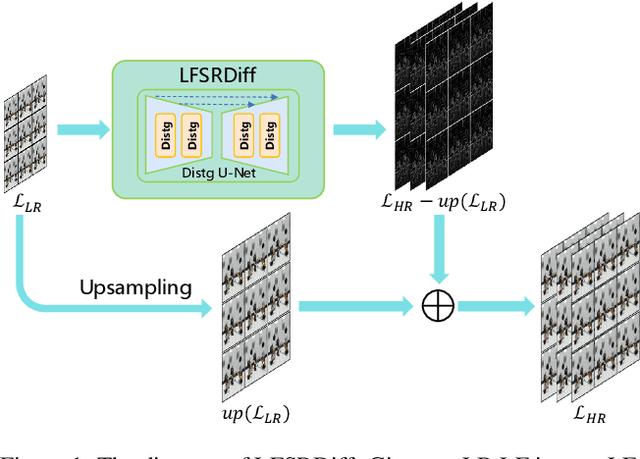
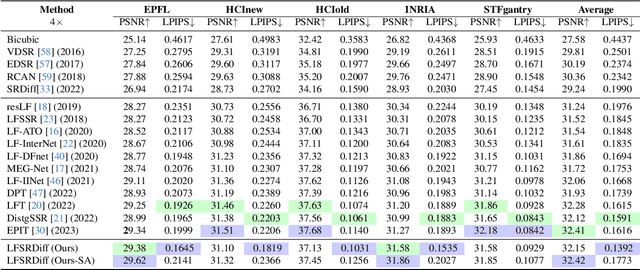

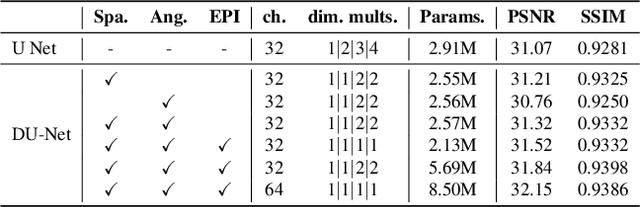
Light field (LF) image super-resolution (SR) is a challenging problem due to its inherent ill-posed nature, where a single low-resolution (LR) input LF image can correspond to multiple potential super-resolved outcomes. Despite this complexity, mainstream LF image SR methods typically adopt a deterministic approach, generating only a single output supervised by pixel-wise loss functions. This tendency often results in blurry and unrealistic results. Although diffusion models can capture the distribution of potential SR results by iteratively predicting Gaussian noise during the denoising process, they are primarily designed for general images and struggle to effectively handle the unique characteristics and information present in LF images. To address these limitations, we introduce LFSRDiff, the first diffusion-based LF image SR model, by incorporating the LF disentanglement mechanism. Our novel contribution includes the introduction of a disentangled U-Net for diffusion models, enabling more effective extraction and fusion of both spatial and angular information within LF images. Through comprehensive experimental evaluations and comparisons with the state-of-the-art LF image SR methods, the proposed approach consistently produces diverse and realistic SR results. It achieves the highest perceptual metric in terms of LPIPS. It also demonstrates the ability to effectively control the trade-off between perception and distortion. The code is available at \url{https://github.com/chaowentao/LFSRDiff}.
Multi-scale Semantic Correlation Mining for Visible-Infrared Person Re-Identification
Nov 24, 2023The main challenge in the Visible-Infrared Person Re-Identification (VI-ReID) task lies in how to extract discriminative features from different modalities for matching purposes. While the existing well works primarily focus on minimizing the modal discrepancies, the modality information can not thoroughly be leveraged. To solve this problem, a Multi-scale Semantic Correlation Mining network (MSCMNet) is proposed to comprehensively exploit semantic features at multiple scales and simultaneously reduce modality information loss as small as possible in feature extraction. The proposed network contains three novel components. Firstly, after taking into account the effective utilization of modality information, the Multi-scale Information Correlation Mining Block (MIMB) is designed to explore semantic correlations across multiple scales. Secondly, in order to enrich the semantic information that MIMB can utilize, a quadruple-stream feature extractor (QFE) with non-shared parameters is specifically designed to extract information from different dimensions of the dataset. Finally, the Quadruple Center Triplet Loss (QCT) is further proposed to address the information discrepancy in the comprehensive features. Extensive experiments on the SYSU-MM01, RegDB, and LLCM datasets demonstrate that the proposed MSCMNet achieves the greatest accuracy.