 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Towards More Accurate Diffusion Model Acceleration with A Timestep Aligner
Oct 14, 2023
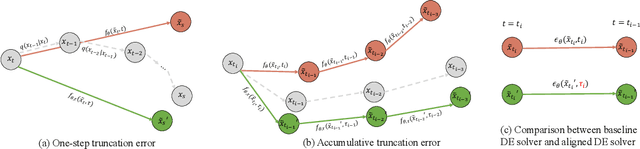
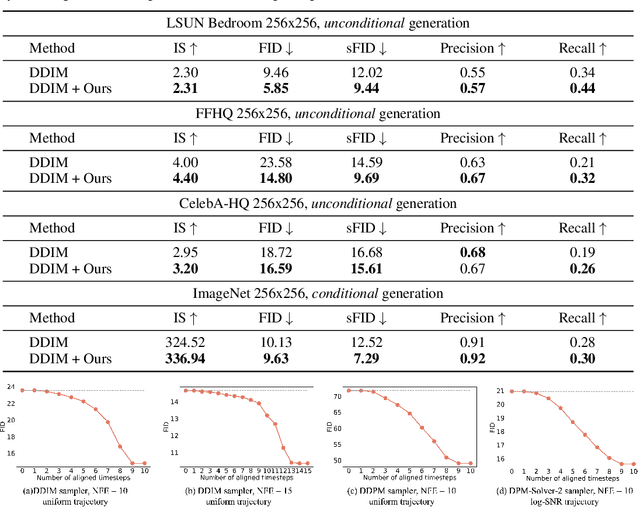
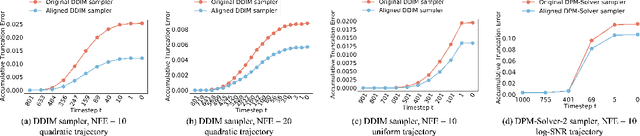

A diffusion model, which is formulated to produce an image using thousands of denoising steps, usually suffers from a slow inference speed. Existing acceleration algorithms simplify the sampling by skipping most steps yet exhibit considerable performance degradation. By viewing the generation of diffusion models as a discretized integrating process, we argue that the quality drop is partly caused by applying an inaccurate integral direction to a timestep interval. To rectify this issue, we propose a timestep aligner that helps find a more accurate integral direction for a particular interval at the minimum cost. Specifically, at each denoising step, we replace the original parameterization by conditioning the network on a new timestep, which is obtained by aligning the sampling distribution to the real distribution. Extensive experiments show that our plug-in design can be trained efficiently and boost the inference performance of various state-of-the-art acceleration methods, especially when there are few denoising steps. For example, when using 10 denoising steps on the popular LSUN Bedroom dataset, we improve the FID of DDIM from 9.65 to 6.07, simply by adopting our method for a more appropriate set of timesteps. Code will be made publicly available.
PaintHuman: Towards High-fidelity Text-to-3D Human Texturing via Denoised Score Distillation
Oct 14, 2023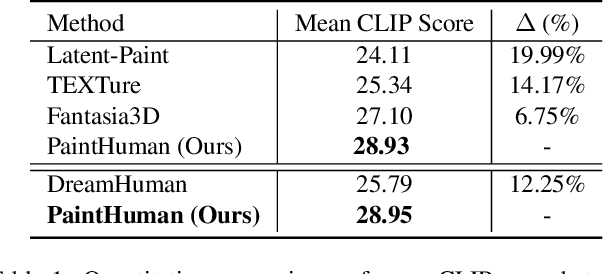
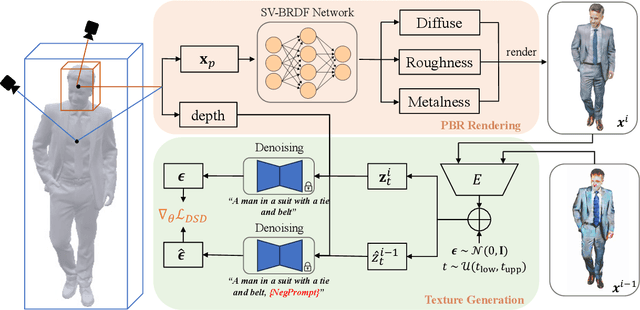
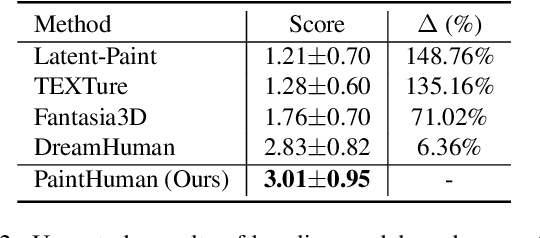
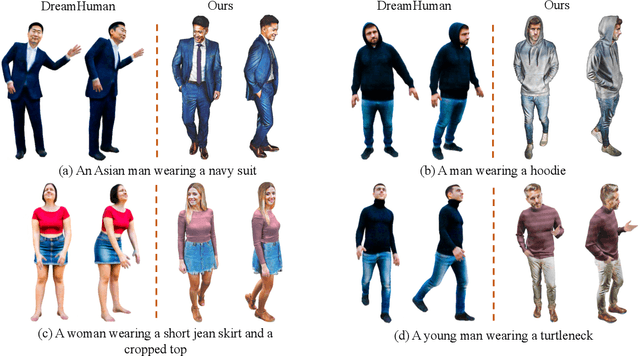
Recent advances in zero-shot text-to-3D human generation, which employ the human model prior (eg, SMPL) or Score Distillation Sampling (SDS) with pre-trained text-to-image diffusion models, have been groundbreaking. However, SDS may provide inaccurate gradient directions under the weak diffusion guidance, as it tends to produce over-smoothed results and generate body textures that are inconsistent with the detailed mesh geometry. Therefore, directly leverage existing strategies for high-fidelity text-to-3D human texturing is challenging. In this work, we propose a model called PaintHuman to addresses the challenges from two aspects. We first propose a novel score function, Denoised Score Distillation (DSD), which directly modifies the SDS by introducing negative gradient components to iteratively correct the gradient direction and generate high-quality textures. In addition, we use the depth map as a geometric guidance to ensure the texture is semantically aligned to human mesh surfaces. To guarantee the quality of rendered results, we employ geometry-aware networks to predict surface materials and render realistic human textures. Extensive experiments, benchmarked against state-of-the-art methods, validate the efficacy of our approach.
Denoising Diffusion Bridge Models
Sep 29, 2023


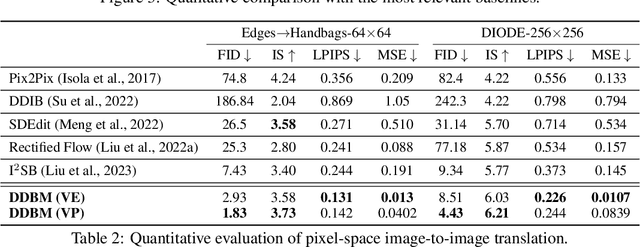
Diffusion models are powerful generative models that map noise to data using stochastic processes. However, for many applications such as image editing, the model input comes from a distribution that is not random noise. As such, diffusion models must rely on cumbersome methods like guidance or projected sampling to incorporate this information in the generative process. In our work, we propose Denoising Diffusion Bridge Models (DDBMs), a natural alternative to this paradigm based on diffusion bridges, a family of processes that interpolate between two paired distributions given as endpoints. Our method learns the score of the diffusion bridge from data and maps from one endpoint distribution to the other by solving a (stochastic) differential equation based on the learned score. Our method naturally unifies several classes of generative models, such as score-based diffusion models and OT-Flow-Matching, allowing us to adapt existing design and architectural choices to our more general problem. Empirically, we apply DDBMs to challenging image datasets in both pixel and latent space. On standard image translation problems, DDBMs achieve significant improvement over baseline methods, and, when we reduce the problem to image generation by setting the source distribution to random noise, DDBMs achieve comparable FID scores to state-of-the-art methods despite being built for a more general task.
Fine-grained Late-interaction Multi-modal Retrieval for Retrieval Augmented Visual Question Answering
Sep 29, 2023Knowledge-based Visual Question Answering (KB-VQA) requires VQA systems to utilize knowledge from existing knowledge bases to answer visually-grounded questions. Retrieval-Augmented Visual Question Answering (RA-VQA), a strong framework to tackle KB-VQA, first retrieves related documents with Dense Passage Retrieval (DPR) and then uses them to answer questions. This paper proposes Fine-grained Late-interaction Multi-modal Retrieval (FLMR) which significantly improves knowledge retrieval in RA-VQA. FLMR addresses two major limitations in RA-VQA's retriever: (1) the image representations obtained via image-to-text transforms can be incomplete and inaccurate and (2) relevance scores between queries and documents are computed with one-dimensional embeddings, which can be insensitive to finer-grained relevance. FLMR overcomes these limitations by obtaining image representations that complement those from the image-to-text transforms using a vision model aligned with an existing text-based retriever through a simple alignment network. FLMR also encodes images and questions using multi-dimensional embeddings to capture finer-grained relevance between queries and documents. FLMR significantly improves the original RA-VQA retriever's PRRecall@5 by approximately 8\%. Finally, we equipped RA-VQA with two state-of-the-art large multi-modal/language models to achieve $\sim61\%$ VQA score in the OK-VQA dataset.
Self-supervised Domain-agnostic Domain Adaptation for Satellite Images
Sep 25, 2023
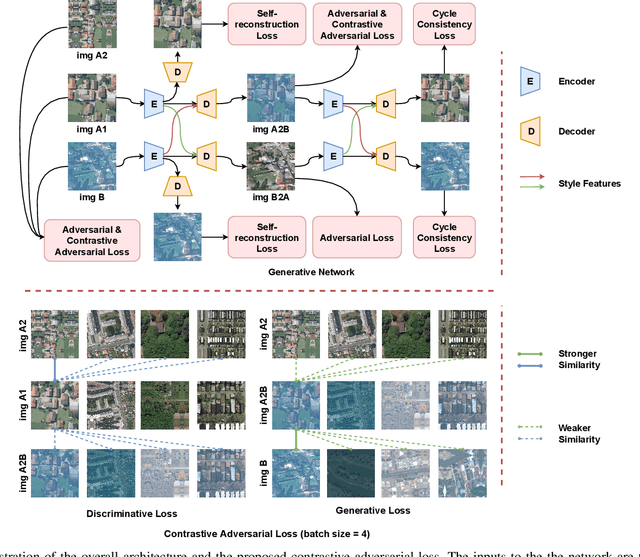

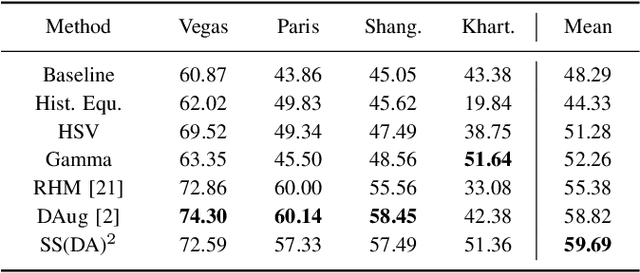
Domain shift caused by, e.g., different geographical regions or acquisition conditions is a common issue in machine learning for global scale satellite image processing. A promising method to address this problem is domain adaptation, where the training and the testing datasets are split into two or multiple domains according to their distributions, and an adaptation method is applied to improve the generalizability of the model on the testing dataset. However, defining the domain to which each satellite image belongs is not trivial, especially under large-scale multi-temporal and multi-sensory scenarios, where a single image mosaic could be generated from multiple data sources. In this paper, we propose an self-supervised domain-agnostic domain adaptation (SS(DA)2) method to perform domain adaptation without such a domain definition. To achieve this, we first design a contrastive generative adversarial loss to train a generative network to perform image-to-image translation between any two satellite image patches. Then, we improve the generalizability of the downstream models by augmenting the training data with different testing spectral characteristics. The experimental results on public benchmarks verify the effectiveness of SS(DA)2.
Evading Detection Actively: Toward Anti-Forensics against Forgery Localization
Oct 16, 2023Anti-forensics seeks to eliminate or conceal traces of tampering artifacts. Typically, anti-forensic methods are designed to deceive binary detectors and persuade them to misjudge the authenticity of an image. However, to the best of our knowledge, no attempts have been made to deceive forgery detectors at the pixel level and mis-locate forged regions. Traditional adversarial attack methods cannot be directly used against forgery localization due to the following defects: 1) they tend to just naively induce the target forensic models to flip their pixel-level pristine or forged decisions; 2) their anti-forensics performance tends to be severely degraded when faced with the unseen forensic models; 3) they lose validity once the target forensic models are retrained with the anti-forensics images generated by them. To tackle the three defects, we propose SEAR (Self-supErvised Anti-foRensics), a novel self-supervised and adversarial training algorithm that effectively trains deep-learning anti-forensic models against forgery localization. SEAR sets a pretext task to reconstruct perturbation for self-supervised learning. In adversarial training, SEAR employs a forgery localization model as a supervisor to explore tampering features and constructs a deep-learning concealer to erase corresponding traces. We have conducted largescale experiments across diverse datasets. The experimental results demonstrate that, through the combination of self-supervised learning and adversarial learning, SEAR successfully deceives the state-of-the-art forgery localization methods, as well as tackle the three defects regarding traditional adversarial attack methods mentioned above.
Prior-Free Continual Learning with Unlabeled Data in the Wild
Oct 16, 2023Continual Learning (CL) aims to incrementally update a trained model on new tasks without forgetting the acquired knowledge of old ones. Existing CL methods usually reduce forgetting with task priors, \ie using task identity or a subset of previously seen samples for model training. However, these methods would be infeasible when such priors are unknown in real-world applications. To address this fundamental but seldom-studied problem, we propose a Prior-Free Continual Learning (PFCL) method, which learns new tasks without knowing the task identity or any previous data. First, based on a fixed single-head architecture, we eliminate the need for task identity to select the task-specific output head. Second, we employ a regularization-based strategy for consistent predictions between the new and old models, avoiding revisiting previous samples. However, using this strategy alone often performs poorly in class-incremental scenarios, particularly for a long sequence of tasks. By analyzing the effectiveness and limitations of conventional regularization-based methods, we propose enhancing model consistency with an auxiliary unlabeled dataset additionally. Moreover, since some auxiliary data may degrade the performance, we further develop a reliable sample selection strategy to obtain consistent performance improvement. Extensive experiments on multiple image classification benchmark datasets show that our PFCL method significantly mitigates forgetting in all three learning scenarios. Furthermore, when compared to the most recent rehearsal-based methods that replay a limited number of previous samples, PFCL achieves competitive accuracy. Our code is available at: https://github.com/visiontao/pfcl
On the Transferability of Learning Models for Semantic Segmentation for Remote Sensing Data
Oct 16, 2023Recent deep learning-based methods outperform traditional learning methods on remote sensing (RS) semantic segmentation/classification tasks. However, they require large training datasets and are generally known for lack of transferability due to the highly disparate RS image content across different geographical regions. Yet, there is no comprehensive analysis of their transferability, i.e., to which extent a model trained on a source domain can be readily applicable to a target domain. Therefore, in this paper, we aim to investigate the raw transferability of traditional and deep learning (DL) models, as well as the effectiveness of domain adaptation (DA) approaches in enhancing the transferability of the DL models (adapted transferability). By utilizing four highly diverse RS datasets, we train six models with and without three DA approaches to analyze their transferability between these datasets quantitatively. Furthermore, we developed a straightforward method to quantify the transferability of a model using the spectral indices as a medium and have demonstrated its effectiveness in evaluating the model transferability at the target domain when the labels are unavailable. Our experiments yield several generally important yet not well-reported observations regarding the raw and adapted transferability. Moreover, our proposed label-free transferability assessment method is validated to be better than posterior model confidence. The findings can guide the future development of generalized RS learning models. The trained models are released under this link: https://github.com/GDAOSU/Transferability-Remote-Sensing
Revealing the preference for correcting separated aberrations in joint optic-image design
Sep 08, 2023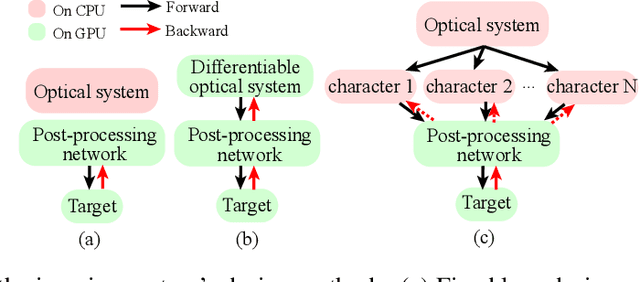
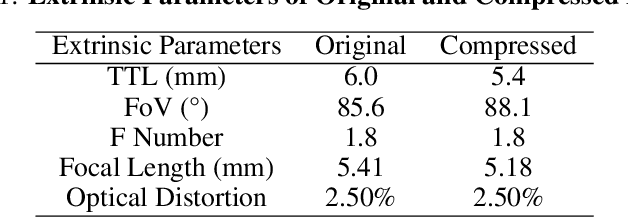
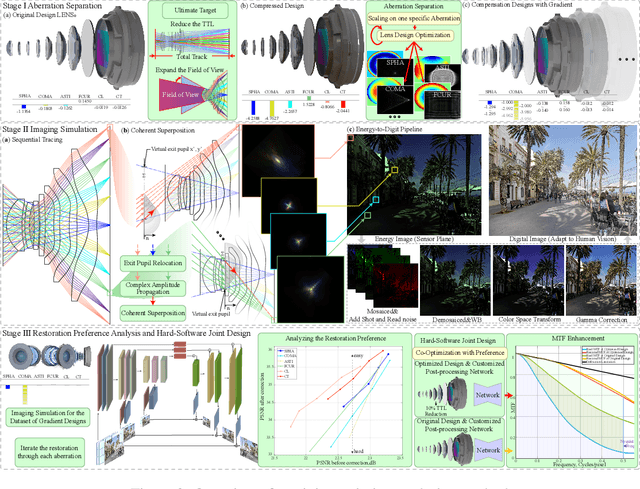

The joint design of the optical system and the downstream algorithm is a challenging and promising task. Due to the demand for balancing the global optimal of imaging systems and the computational cost of physical simulation, existing methods cannot achieve efficient joint design of complex systems such as smartphones and drones. In this work, starting from the perspective of the optical design, we characterize the optics with separated aberrations. Additionally, to bridge the hardware and software without gradients, an image simulation system is presented to reproduce the genuine imaging procedure of lenses with large field-of-views. As for aberration correction, we propose a network to perceive and correct the spatially varying aberrations and validate its superiority over state-of-the-art methods. Comprehensive experiments reveal that the preference for correcting separated aberrations in joint design is as follows: longitudinal chromatic aberration, lateral chromatic aberration, spherical aberration, field curvature, and coma, with astigmatism coming last. Drawing from the preference, a 10% reduction in the total track length of the consumer-level mobile phone lens module is accomplished. Moreover, this procedure spares more space for manufacturing deviations, realizing extreme-quality enhancement of computational photography. The optimization paradigm provides innovative insight into the practical joint design of sophisticated optical systems and post-processing algorithms.
Condition numbers in multiview geometry, instability in relative pose estimation, and RANSAC
Oct 04, 2023In this paper we introduce a general framework for analyzing the numerical conditioning of minimal problems in multiple view geometry, using tools from computational algebra and Riemannian geometry. Special motivation comes from the fact that relative pose estimation, based on standard 5-point or 7-point Random Sample Consensus (RANSAC) algorithms, can fail even when no outliers are present and there is enough data to support a hypothesis. We argue that these cases arise due to the intrinsic instability of the 5- and 7-point minimal problems. We apply our framework to characterize the instabilities, both in terms of the world scenes that lead to infinite condition number, and directly in terms of ill-conditioned image data. The approach produces computational tests for assessing the condition number before solving the minimal problem. Lastly synthetic and real data experiments suggest that RANSAC serves not only to remove outliers, but also to select for well-conditioned image data, as predicted by our theory.