 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Fragile Are Training-Free AI-Generated Image Detectors? A Controlled Audit of Score Direction, Preprocessing, and Compression
Jun 18, 2026Training-free detectors of AI-generated images promise generator-agnostic deployment without classifier training, yet their reported numbers are rarely compared under a single controlled protocol. We audit two representative training-free scores -- an autoencoder-reconstruction score (AEROBLADE-style) and a noise-perturbation feature-similarity score (RIGID-style) -- plus a naive feature-kNN control, on a common 1,500-image GenImage-derived benchmark spanning seven generators and JPEG compression at quality 70 and 50. The audit yields three cautionary findings. (i) Implementation details masquerade as method differences: replacing the LPIPS backbone (AlexNet -> VGG-16) changes overall AUROC by +0.085, and switching between resize-to-512 and native-resolution preprocessing flips per-generator conclusions by up to 0.38 AUROC. (ii) Score direction is not a property of the method but of its hyperparameters: the RIGID-style score is inverted (AUROC < 0.5) on SD1.5 and Wukong at noise level sigma=0.05, recovers to >0.5 for every generator at sigma=0.01, and collapses to 0.15 at sigma=0.3. (iii) Dataset format bias inflates robustness claims: without unified re-encoding, AUROC under JPEG-50 exceeds the clean condition for the AlexNet-backbone reconstruction score; after bias correction the residual anomaly localizes to a single generator (BigGAN). The audited scores have complementary per-generator failure sets, but naive z-score fusion does not beat the best single score, indicating that exploiting complementarity requires direction-aware combination.
False Sense of Safety in Selective Signal Classification: Auditing Bound Tightness and Exchangeability for Risk Control
Jun 13, 2026Selective prediction with distribution-free risk control promises that, with confidence 1-delta over the calibration draw, the error rate of accepted inputs stays below a user budget alpha. We audit this promise on signal-domain detectors -- machine anomalous-sound detection (ASD) and AI-generated-image forensics -- for four calibration rules: uncertified empirical thresholding (NAIVE) and certified Hoeffding, Clopper-Pearson (CP), and betting (WSR) upper confidence bounds. We report three findings. (i) NAIVE thresholding, common in practice, exceeds its declared budget in 49-73% of synthetic trials (n=200 calibration points) and in up to 68% of real-data splits: a false sense of safety rather than a broken theorem, since the rule never had a certificate. (ii) Tightness matters: CP and WSR certify substantial coverage where Hoeffding certifies none, with zero observed budget overruns under exchangeable splits. (iii) Under grouped deployment (unseen machine types or generators), certified rules overrun in 9-30% of trials -- far above delta -- showing the failure lies in the broken exchangeability premise, not in the bounds; a conservative per-group threshold restores validity at a severe coverage cost.
WinFLoRA: Incentivizing Client-Adaptive Aggregation in Federated LoRA under Privacy Heterogeneity
Feb 01, 2026Large Language Models (LLMs) increasingly underpin intelligent web applications, from chatbots to search and recommendation, where efficient specialization is essential. Low-Rank Adaptation (LoRA) enables such adaptation with minimal overhead, while federated LoRA allows web service providers to fine-tune shared models without data sharing. However, in privacy-sensitive deployments, clients inject varying levels of differential privacy (DP) noise, creating privacy heterogeneity that misaligns individual incentives and global performance. In this paper, we propose WinFLoRA, a privacy-heterogeneous federated LoRA that utilizes aggregation weights as incentives with noise awareness. Specifically, the noises from clients are estimated based on the uploaded LoRA adapters. A larger weight indicates greater influence on the global model and better downstream task performance, rewarding lower-noise contributions. By up-weighting low-noise updates, WinFLoRA improves global accuracy while accommodating clients' heterogeneous privacy requirements. Consequently, WinFLoRA aligns heterogeneous client utility in terms of privacy and downstream performance with global model objectives without third-party involvement. Extensive evaluations demonstrate that across multiple LLMs and datasets, WinFLoRA achieves up to 52.58% higher global accuracy and up to 2.56x client utility than state-of-the-art benchmarks. Source code is publicly available at https://github.com/koums24/WinFLoRA.git.
Successive optimization of optics and post-processing with differentiable coherent PSF operator and field information
Dec 19, 2024



Recently, the joint design of optical systems and downstream algorithms is showing significant potential. However, existing rays-described methods are limited to optimizing geometric degradation, making it difficult to fully represent the optical characteristics of complex, miniaturized lenses constrained by wavefront aberration or diffraction effects. In this work, we introduce a precise optical simulation model, and every operation in pipeline is differentiable. This model employs a novel initial value strategy to enhance the reliability of intersection calculation on high aspherics. Moreover, it utilizes a differential operator to reduce memory consumption during coherent point spread function calculations. To efficiently address various degradation, we design a joint optimization procedure that leverages field information. Guided by a general restoration network, the proposed method not only enhances the image quality, but also successively improves the optical performance across multiple lenses that are already in professional level. This joint optimization pipeline offers innovative insights into the practical design of sophisticated optical systems and post-processing algorithms. The source code will be made publicly available at https://github.com/Zrr-ZJU/Successive-optimization
A Taxonomy of Architecture Options for Foundation Model-based Agents: Analysis and Decision Model
Aug 06, 2024


The rapid advancement of AI technology has led to widespread applications of agent systems across various domains. However, the need for detailed architecture design poses significant challenges in designing and operating these systems. This paper introduces a taxonomy focused on the architectures of foundation-model-based agents, addressing critical aspects such as functional capabilities and non-functional qualities. We also discuss the operations involved in both design-time and run-time phases, providing a comprehensive view of architectural design and operational characteristics. By unifying and detailing these classifications, our taxonomy aims to improve the design of foundation-model-based agents. Additionally, the paper establishes a decision model that guides critical design and runtime decisions, offering a structured approach to enhance the development of foundation-model-based agents. Our contributions include providing a structured architecture design option and guiding the development process of foundation-model-based agents, thereby addressing current fragmentation in the field.
Revealing the preference for correcting separated aberrations in joint optic-image design
Sep 12, 2023The joint design of the optical system and the downstream algorithm is a challenging and promising task. Due to the demand for balancing the global optimal of imaging systems and the computational cost of physical simulation, existing methods cannot achieve efficient joint design of complex systems such as smartphones and drones. In this work, starting from the perspective of the optical design, we characterize the optics with separated aberrations. Additionally, to bridge the hardware and software without gradients, an image simulation system is presented to reproduce the genuine imaging procedure of lenses with large field-of-views. As for aberration correction, we propose a network to perceive and correct the spatially varying aberrations and validate its superiority over state-of-the-art methods. Comprehensive experiments reveal that the preference for correcting separated aberrations in joint design is as follows: longitudinal chromatic aberration, lateral chromatic aberration, spherical aberration, field curvature, and coma, with astigmatism coming last. Drawing from the preference, a 10% reduction in the total track length of the consumer-level mobile phone lens module is accomplished. Moreover, this procedure spares more space for manufacturing deviations, realizing extreme-quality enhancement of computational photography. The optimization paradigm provides innovative insight into the practical joint design of sophisticated optical systems and post-processing algorithms.
Heterogeneous Graph Learning for Visual Commonsense Reasoning
Oct 25, 2019
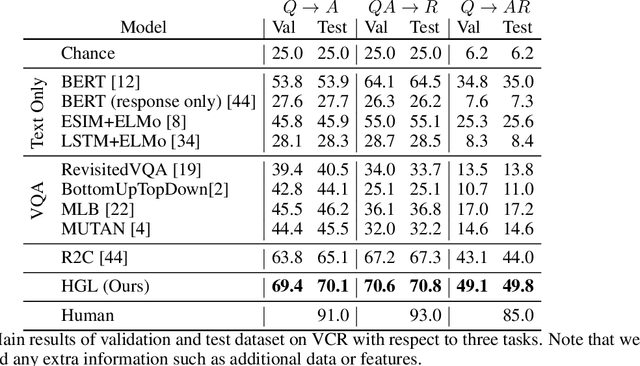
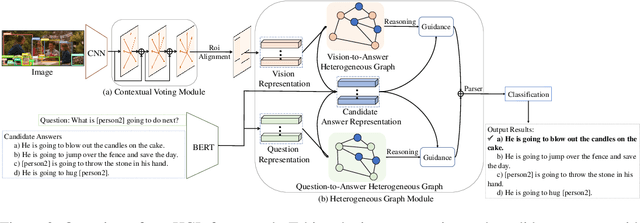
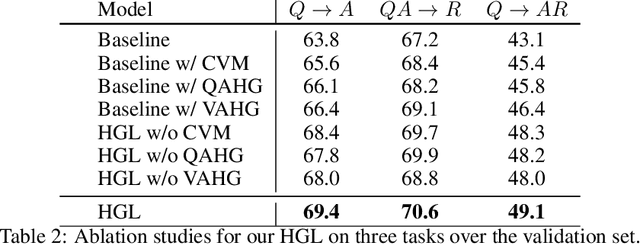
Visual commonsense reasoning task aims at leading the research field into solving cognition-level reasoning with the ability of predicting correct answers and meanwhile providing convincing reasoning paths, resulting in three sub-tasks i.e., Q->A, QA->R and Q->AR. It poses great challenges over the proper semantic alignment between vision and linguistic domains and knowledge reasoning to generate persuasive reasoning paths. Existing works either resort to a powerful end-to-end network that cannot produce interpretable reasoning paths or solely explore intra-relationship of visual objects (homogeneous graph) while ignoring the cross-domain semantic alignment among visual concepts and linguistic words. In this paper, we propose a new Heterogeneous Graph Learning (HGL) framework for seamlessly integrating the intra-graph and inter-graph reasoning in order to bridge vision and language domain. Our HGL consists of a primal vision-to-answer heterogeneous graph (VAHG) module and a dual question-to-answer heterogeneous graph (QAHG) module to interactively refine reasoning paths for semantic agreement. Moreover, our HGL integrates a contextual voting module to exploit a long-range visual context for better global reasoning. Experiments on the large-scale Visual Commonsense Reasoning benchmark demonstrate the superior performance of our proposed modules on three tasks (improving 5% accuracy on Q->A, 3.5% on QA->R, 5.8% on Q->AR)