 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Learning Models for Classification of COVID-19 Cases by Medical Images
Oct 24, 2023
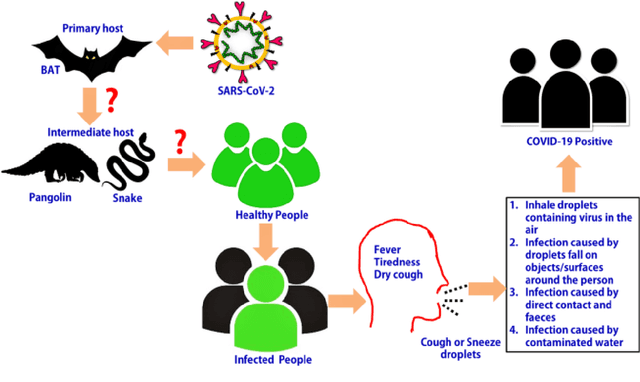
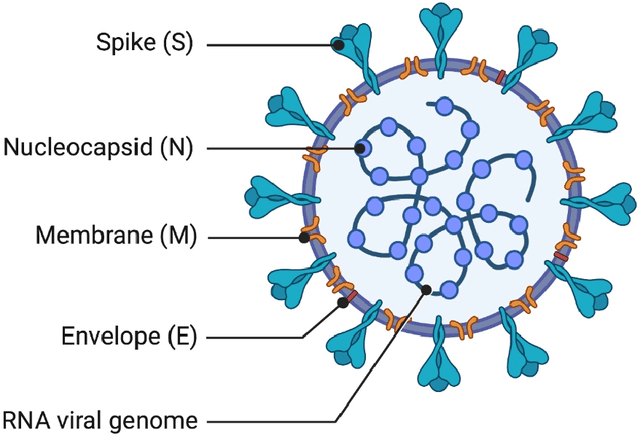
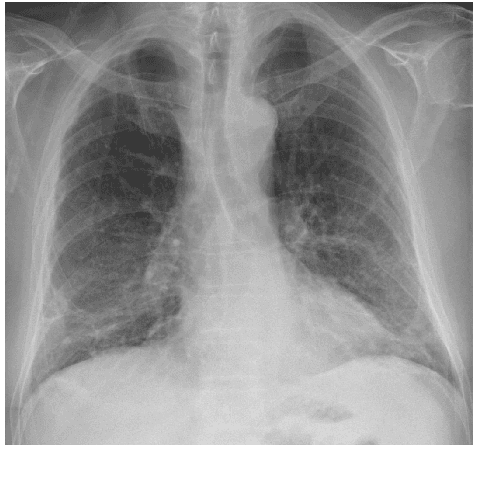
In recent times, the use of chest Computed Tomography (CT) images for detecting coronavirus infections has gained significant attention, owing to their ability to reveal bilateral changes in affected individuals. However, classifying patients from medical images presents a formidable challenge, particularly in identifying such bilateral changes. To tackle this challenge, our study harnesses the power of deep learning models for the precise classification of infected patients. Our research involves a comparative analysis of deep transfer learning-based classification models, including DenseNet201, GoogleNet, and AlexNet, against carefully chosen supervised learning models. Additionally, our work encompasses Covid-19 classification, which involves the identification and differentiation of medical images, such as X-rays and electrocardiograms, that exhibit telltale signs of Covid-19 infection. This comprehensive approach ensures that our models can handle a wide range of medical image types and effectively identify characteristic patterns indicative of Covid-19. By conducting meticulous research and employing advanced deep learning techniques, we have made significant strides in enhancing the accuracy and speed of Covid-19 diagnosis. Our results demonstrate the effectiveness of these models and their potential to make substantial contributions to the global effort to combat COVID-19.
Hierarchical Randomized Smoothing
Oct 24, 2023Real-world data is complex and often consists of objects that can be decomposed into multiple entities (e.g. images into pixels, graphs into interconnected nodes). Randomized smoothing is a powerful framework for making models provably robust against small changes to their inputs - by guaranteeing robustness of the majority vote when randomly adding noise before classification. Yet, certifying robustness on such complex data via randomized smoothing is challenging when adversaries do not arbitrarily perturb entire objects (e.g. images) but only a subset of their entities (e.g. pixels). As a solution, we introduce hierarchical randomized smoothing: We partially smooth objects by adding random noise only on a randomly selected subset of their entities. By adding noise in a more targeted manner than existing methods we obtain stronger robustness guarantees while maintaining high accuracy. We initialize hierarchical smoothing using different noising distributions, yielding novel robustness certificates for discrete and continuous domains. We experimentally demonstrate the importance of hierarchical smoothing in image and node classification, where it yields superior robustness-accuracy trade-offs. Overall, hierarchical smoothing is an important contribution towards models that are both - certifiably robust to perturbations and accurate.
ShadowSense: Unsupervised Domain Adaptation and Feature Fusion for Shadow-Agnostic Tree Crown Detection from RGB-Thermal Drone Imagery
Oct 24, 2023Accurate detection of individual tree crowns from remote sensing data poses a significant challenge due to the dense nature of forest canopy and the presence of diverse environmental variations, e.g., overlapping canopies, occlusions, and varying lighting conditions. Additionally, the lack of data for training robust models adds another limitation in effectively studying complex forest conditions. This paper presents a novel method for detecting shadowed tree crowns and provides a challenging dataset comprising roughly 50k paired RGB-thermal images to facilitate future research for illumination-invariant detection. The proposed method (ShadowSense) is entirely self-supervised, leveraging domain adversarial training without source domain annotations for feature extraction and foreground feature alignment for feature pyramid networks to adapt domain-invariant representations by focusing on visible foreground regions, respectively. It then fuses complementary information of both modalities to effectively improve upon the predictions of an RGB-trained detector and boost the overall accuracy. Extensive experiments demonstrate the superiority of the proposed method over both the baseline RGB-trained detector and state-of-the-art techniques that rely on unsupervised domain adaptation or early image fusion. Our code and data are available: https://github.com/rudrakshkapil/ShadowSense
Brainchop: Next Generation Web-Based Neuroimaging Application
Oct 24, 2023Performing volumetric image processing directly within the browser, particularly with medical data, presents unprecedented challenges compared to conventional backend tools. These challenges arise from limitations inherent in browser environments, such as constrained computational resources and the availability of frontend machine learning libraries. Consequently, there is a shortage of neuroimaging frontend tools capable of providing comprehensive end-to-end solutions for whole brain preprocessing and segmentation while preserving end-user data privacy and residency. In light of this context, we introduce Brainchop (http://www.brainchop.org) as a groundbreaking in-browser neuroimaging tool that enables volumetric analysis of structural MRI using pre-trained full-brain deep learning models, all without requiring technical expertise or intricate setup procedures. Beyond its commitment to data privacy, this frontend tool offers multiple features, including scalability, low latency, user-friendly operation, cross-platform compatibility, and enhanced accessibility. This paper outlines the processing pipeline of Brainchop and evaluates the performance of models across various software and hardware configurations. The results demonstrate the practicality of client-side processing for volumetric data, owing to the robust MeshNet architecture, even within the resource-constrained environment of web browsers.
Language-Oriented Communication with Semantic Coding and Knowledge Distillation for Text-to-Image Generation
Sep 20, 2023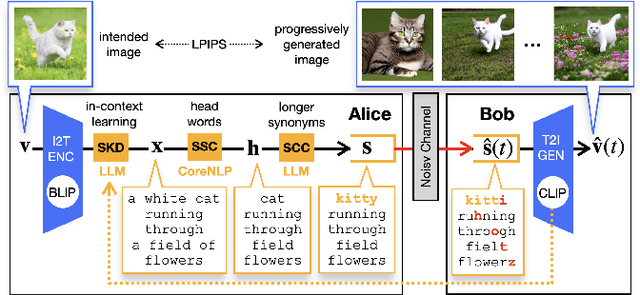


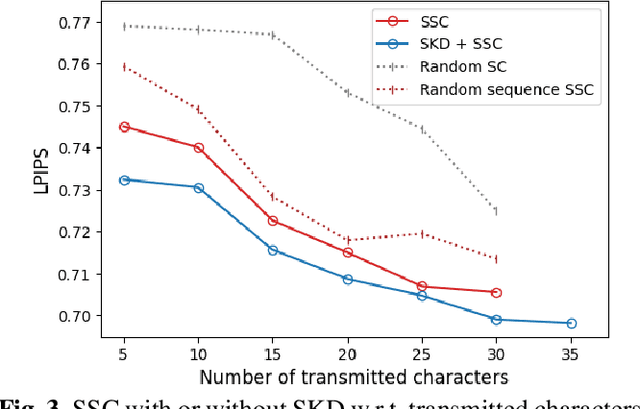
By integrating recent advances in large language models (LLMs) and generative models into the emerging semantic communication (SC) paradigm, in this article we put forward to a novel framework of language-oriented semantic communication (LSC). In LSC, machines communicate using human language messages that can be interpreted and manipulated via natural language processing (NLP) techniques for SC efficiency. To demonstrate LSC's potential, we introduce three innovative algorithms: 1) semantic source coding (SSC) which compresses a text prompt into its key head words capturing the prompt's syntactic essence while maintaining their appearance order to keep the prompt's context; 2) semantic channel coding (SCC) that improves robustness against errors by substituting head words with their lenghthier synonyms; and 3) semantic knowledge distillation (SKD) that produces listener-customized prompts via in-context learning the listener's language style. In a communication task for progressive text-to-image generation, the proposed methods achieve higher perceptual similarities with fewer transmissions while enhancing robustness in noisy communication channels.
Mutual-Guided Dynamic Network for Image Fusion
Aug 24, 2023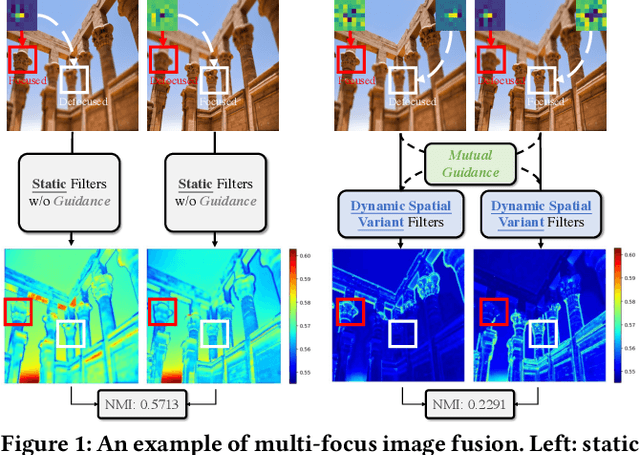

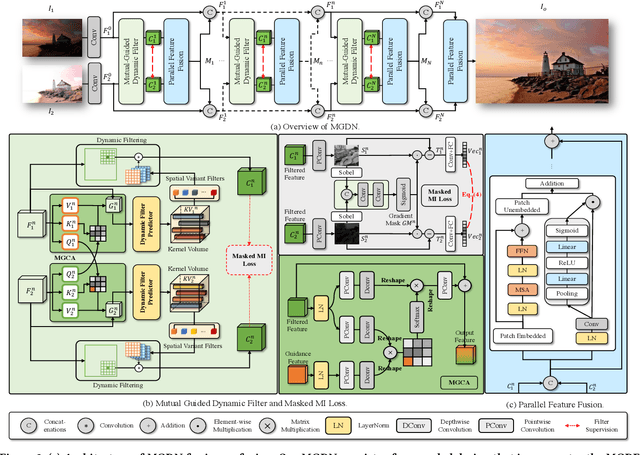
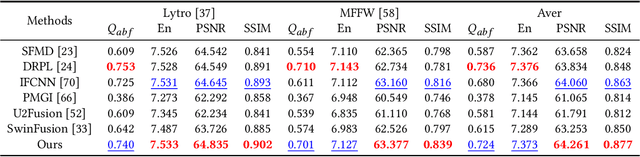
Image fusion aims to generate a high-quality image from multiple images captured under varying conditions. The key problem of this task is to preserve complementary information while filtering out irrelevant information for the fused result. However, existing methods address this problem by leveraging static convolutional neural networks (CNNs), suffering two inherent limitations during feature extraction, i.e., being unable to handle spatial-variant contents and lacking guidance from multiple inputs. In this paper, we propose a novel mutual-guided dynamic network (MGDN) for image fusion, which allows for effective information utilization across different locations and inputs. Specifically, we design a mutual-guided dynamic filter (MGDF) for adaptive feature extraction, composed of a mutual-guided cross-attention (MGCA) module and a dynamic filter predictor, where the former incorporates additional guidance from different inputs and the latter generates spatial-variant kernels for different locations. In addition, we introduce a parallel feature fusion (PFF) module to effectively fuse local and global information of the extracted features. To further reduce the redundancy among the extracted features while simultaneously preserving their shared structural information, we devise a novel loss function that combines the minimization of normalized mutual information (NMI) with an estimated gradient mask. Experimental results on five benchmark datasets demonstrate that our proposed method outperforms existing methods on four image fusion tasks. The code and model are publicly available at: https://github.com/Guanys-dar/MGDN.
Active Learning for Fine-Grained Sketch-Based Image Retrieval
Sep 15, 2023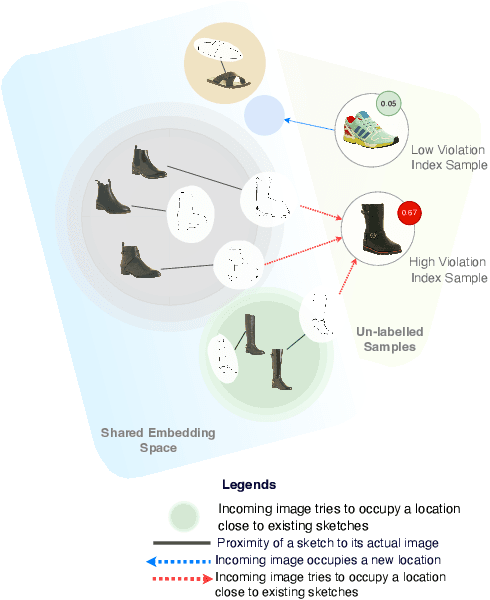
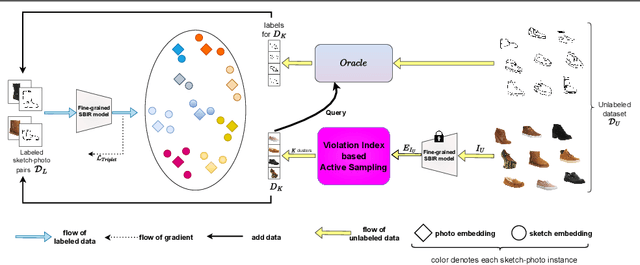
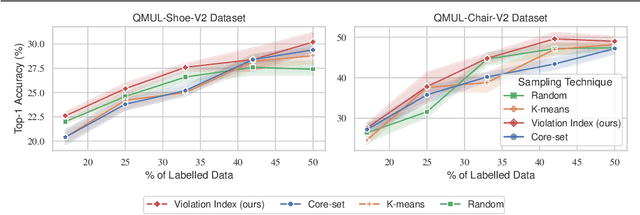
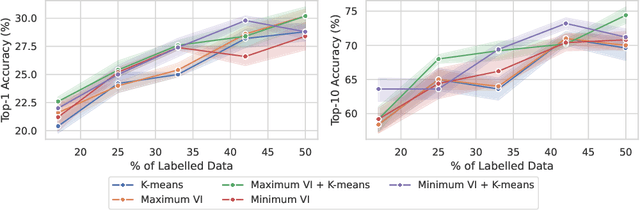
The ability to retrieve a photo by mere free-hand sketching highlights the immense potential of Fine-grained sketch-based image retrieval (FG-SBIR). However, its rapid practical adoption, as well as scalability, is limited by the expense of acquiring faithful sketches for easily available photo counterparts. A solution to this problem is Active Learning, which could minimise the need for labeled sketches while maximising performance. Despite extensive studies in the field, there exists no work that utilises it for reducing sketching effort in FG-SBIR tasks. To this end, we propose a novel active learning sampling technique that drastically minimises the need for drawing photo sketches. Our proposed approach tackles the trade-off between uncertainty and diversity by utilising the relationship between the existing photo-sketch pair to a photo that does not have its sketch and augmenting this relation with its intermediate representations. Since our approach relies only on the underlying data distribution, it is agnostic of the modelling approach and hence is applicable to other cross-modal instance-level retrieval tasks as well. With experimentation over two publicly available fine-grained SBIR datasets ChairV2 and ShoeV2, we validate our approach and reveal its superiority over adapted baselines.
Relay Diffusion: Unifying diffusion process across resolutions for image synthesis
Sep 04, 2023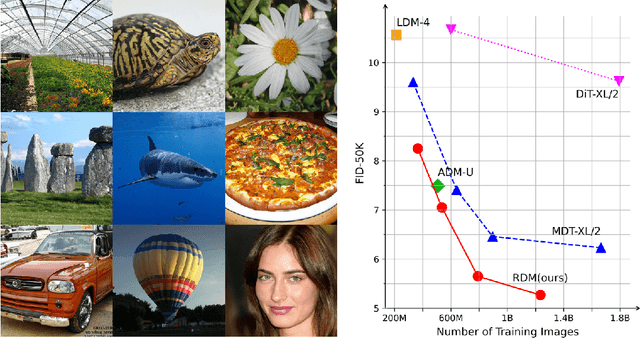
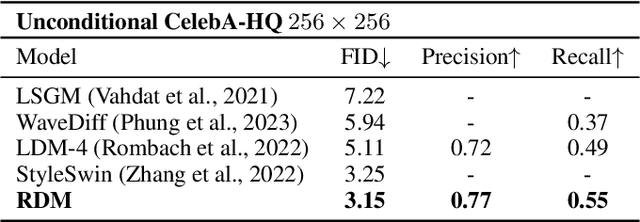
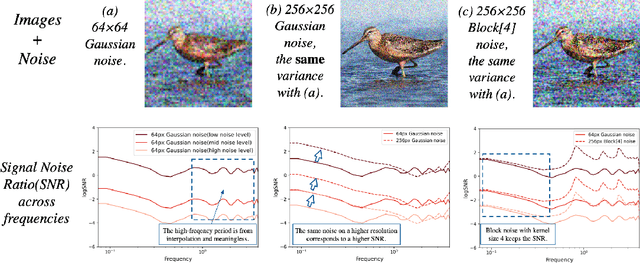
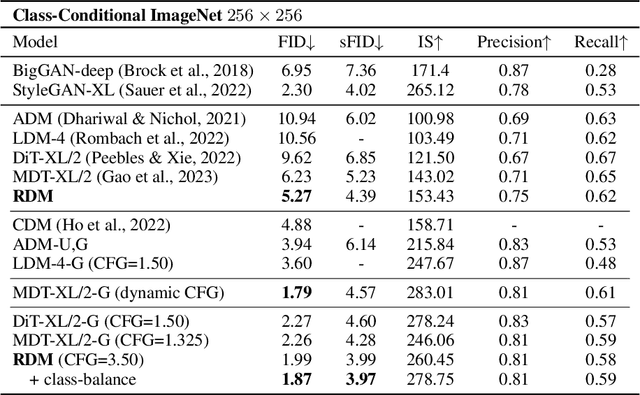
Diffusion models achieved great success in image synthesis, but still face challenges in high-resolution generation. Through the lens of discrete cosine transformation, we find the main reason is that \emph{the same noise level on a higher resolution results in a higher Signal-to-Noise Ratio in the frequency domain}. In this work, we present Relay Diffusion Model (RDM), which transfers a low-resolution image or noise into an equivalent high-resolution one for diffusion model via blurring diffusion and block noise. Therefore, the diffusion process can continue seamlessly in any new resolution or model without restarting from pure noise or low-resolution conditioning. RDM achieves state-of-the-art FID on CelebA-HQ and sFID on ImageNet 256$\times$256, surpassing previous works such as ADM, LDM and DiT by a large margin. All the codes and checkpoints are open-sourced at \url{https://github.com/THUDM/RelayDiffusion}.
DLIP: Distilling Language-Image Pre-training
Aug 24, 2023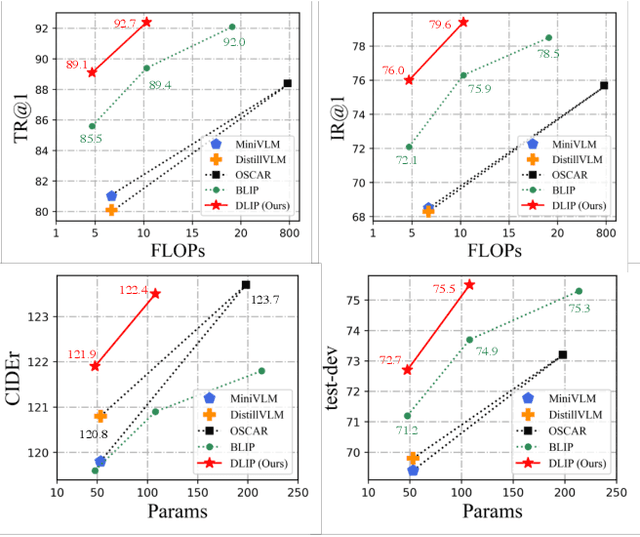
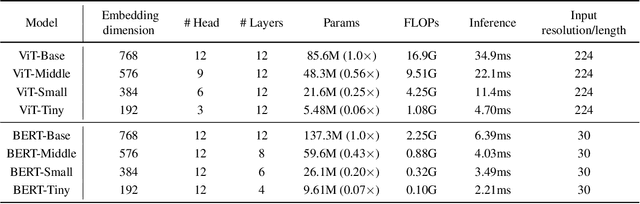
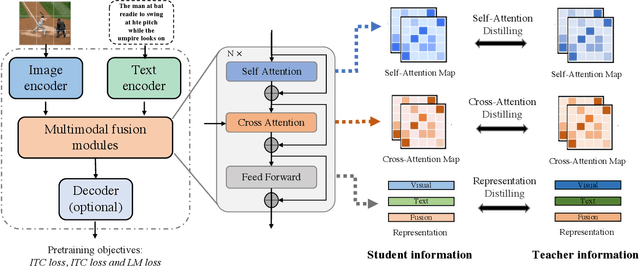
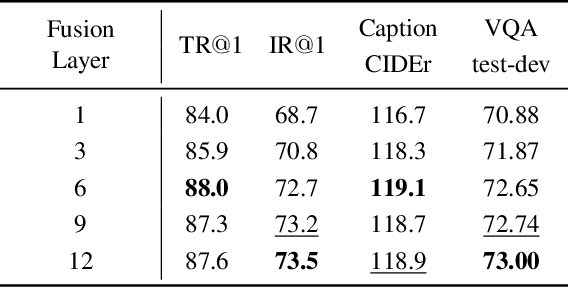
Vision-Language Pre-training (VLP) shows remarkable progress with the assistance of extremely heavy parameters, which challenges deployment in real applications. Knowledge distillation is well recognized as the essential procedure in model compression. However, existing knowledge distillation techniques lack an in-depth investigation and analysis of VLP, and practical guidelines for VLP-oriented distillation are still not yet explored. In this paper, we present DLIP, a simple yet efficient Distilling Language-Image Pre-training framework, through which we investigate how to distill a light VLP model. Specifically, we dissect the model distillation from multiple dimensions, such as the architecture characteristics of different modules and the information transfer of different modalities. We conduct comprehensive experiments and provide insights on distilling a light but performant VLP model. Experimental results reveal that DLIP can achieve a state-of-the-art accuracy/efficiency trade-off across diverse cross-modal tasks, e.g., image-text retrieval, image captioning and visual question answering. For example, DLIP compresses BLIP by 1.9x, from 213M to 108M parameters, while achieving comparable or better performance. Furthermore, DLIP succeeds in retaining more than 95% of the performance with 22.4% parameters and 24.8% FLOPs compared to the teacher model and accelerates inference speed by 2.7x.
CorrEmbed: Evaluating Pre-trained Model Image Similarity Efficacy with a Novel Metric
Aug 30, 2023
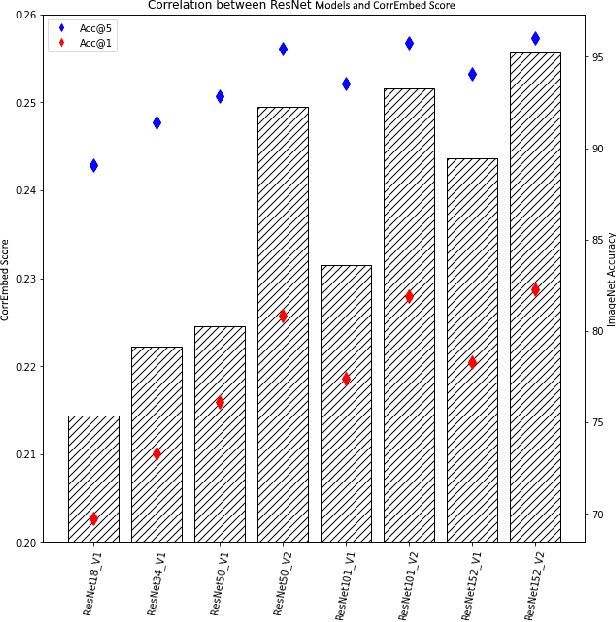
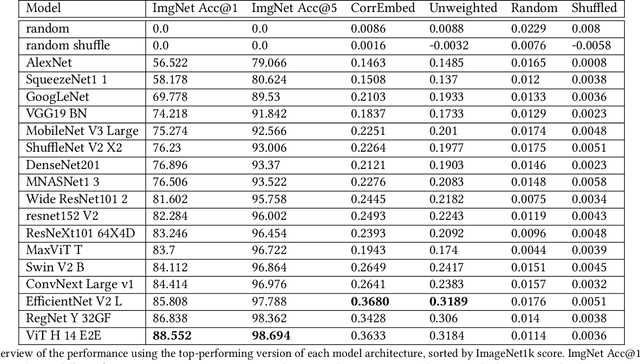
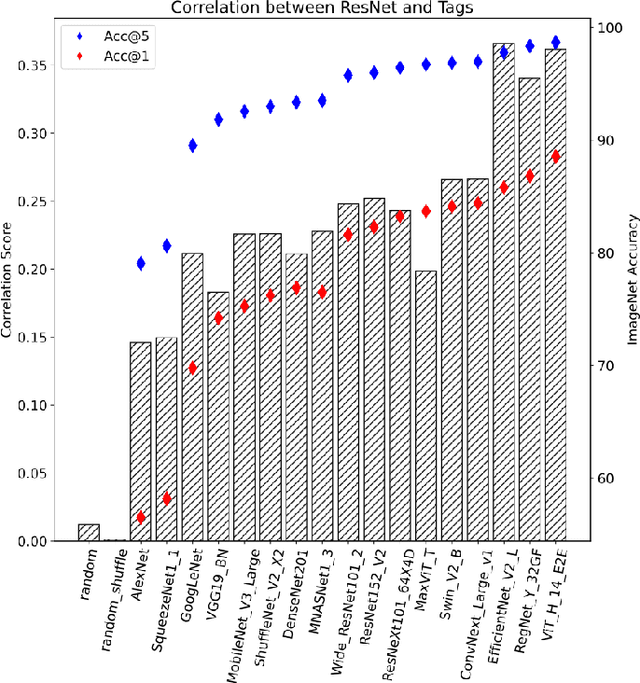
Detecting visually similar images is a particularly useful attribute to look to when calculating product recommendations. Embedding similarity, which utilizes pre-trained computer vision models to extract high-level image features, has demonstrated remarkable efficacy in identifying images with similar compositions. However, there is a lack of methods for evaluating the embeddings generated by these models, as conventional loss and performance metrics do not adequately capture their performance in image similarity search tasks. In this paper, we evaluate the viability of the image embeddings from numerous pre-trained computer vision models using a novel approach named CorrEmbed. Our approach computes the correlation between distances in image embeddings and distances in human-generated tag vectors. We extensively evaluate numerous pre-trained Torchvision models using this metric, revealing an intuitive relationship of linear scaling between ImageNet1k accuracy scores and tag-correlation scores. Importantly, our method also identifies deviations from this pattern, providing insights into how different models capture high-level image features. By offering a robust performance evaluation of these pre-trained models, CorrEmbed serves as a valuable tool for researchers and practitioners seeking to develop effective, data-driven approaches to similar item recommendations in fashion retail.